







论文
论文题目:MLP-Mixer: An all-MLP Architecture for Vision
论文地址:https://arxiv.org/pdf/2105.01601.pdf
最近看了下这篇论文,很受启发,这里写一写,另外也感谢这位博主的分享:https://blog.csdn.net/guzhao9901/article/details/116494592,在这里也学到了很多
论文噱头
一个纯MLP架构
详解
看到论文的第一反应就是:这不就是Transformer的框架图吗
的确,Patch和Per-patch Fully-connected基本就是Transformer中的Patch和feature embedding操作。重点在于Mixer Layer,这里采用两种不同类型的 MLP 层:token-mixing MLP 和 channel-mixing MLP。token-mixing MLP 允许不同空间位置(token)之间进行通信,具有跨patches应用的MLP(即“混合”空间信息);channel-mixing MLP 允许不同通道之间进行通信,具有独立应用于图像patches的MLP(即“混合”每个位置特征)。token-mixing MLP block作用在每个patche的列上,即先对patches部分进行转置,并且所有列参数共享MLP1,得到的输出再重新转置一下。channel-mixing MLP block作用在每个patche的行上,所有行参数共享MLP2。这两种类型的层交替执行以促进两个维度间的信息交互。
上图中,绿色框部分是token-mixing MLP,蓝色框部分是channel-mixing MLP。除了 MLP 层,Mixer 还使用其他标准架构组件:跳跃连接(Skip-connection)和层归一化(Layer Norm)。心声:何凯明大神恐怖如斯。
吐槽
记得当时有一位推主吐槽

其实除了这点,在读论文的过程中我也发现了
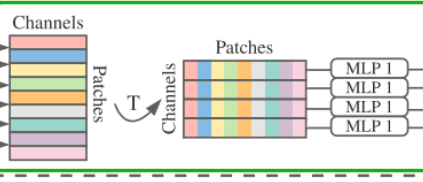
patch的转置+MLP ,这个操作也非常“形似”于卷积,可能这也是它取得高准确率的原因之一。
总结
最后应用那位博主的原话:“本文的研究我认为还是挺有创造性的,至少他提供了CV领域的一种可行方案。但是总体感觉网络结构的发展是被算力牵着走。MLP(Multi-Layer Perceptron,多层感知机)最先出来,由于当时算力跟不上才提出了图像的CNN,想想本文中的Fully-connected。最近又开始从CNN走回头路,先是VIT再是MLP,只要算力和数据够,一切就都有可能。” MLP本质上就是可以拟合任何一种函数的存在,受算力影响才使用的CNN,所以算力提升的当下环境,重回MLP也不是一件什么特别值得惊讶的事。
但我会继续关注这个方向的,部分人对于MLP-Mixer的评价甚高,并称这是MLP-CNN-Attention-MLP循环的开始。之后看到好点子我会继续写在这里。
参考链接:https://baijiahao.baidu.com/s?id=1698992972535694806&wfr=spider&for=pc
















 1816
1816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











