








Abstract
作者探索了普通的、无层次的视觉转换器(ViT)作为目标检测的骨干网络,这个方法叫做 ViTDet
https://arxiv.org/abs/2203.16527
Introduction
当前的目标检测器通常由一个与检测任务无关的主干特征提取器和一组包含检测专用先验知识的颈部和头部组成。从经验上看,目标检测研究受益于对通用主干和检测专用模块的大量独立探索。长期以来,由于卷积网络的实际设计,这些主干一直是多尺度、分层的架构,这严重影响了用于多尺度(如 FPN)目标检测的颈 / 头的设计。
不用重新设计层次结构进行预训练
FPN不是必须的,从最后单个特征图构建一个简单特征金字塔非常有效
不带 shifting 的窗口注意力,加上很少的跨窗口块非常有效。
使用 Masked Autoencoder (MAE) 进行预训练 ViT,能够在 COCO 上取得很好的结果。
普通主干检测器可能是有前途的,这挑战了分层主干在目标检测中的根深蒂固的地位
Method
SFP简单特征金字塔
使用主干网络中的最后一张特征图,因为它应该具有最强大的特征。
仅对最后一张特征图并行应用一组卷积或反卷积来生成多尺度特征图,而不需要任何融合
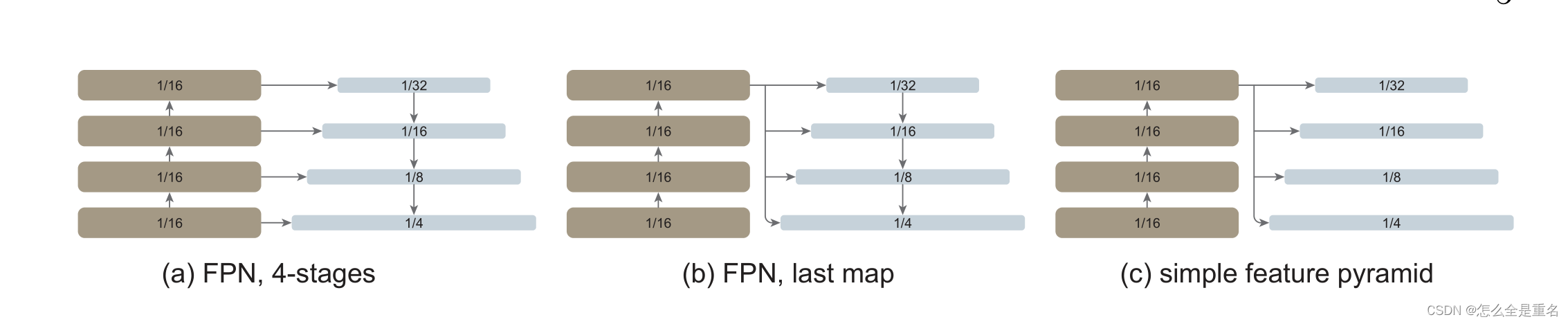
(a):为了模拟分层主干,将普通主干人为地划分为多个阶段。(b)只使用最后一个特征图,不进行阶段划分。(c)没有FPN的简单特征金字塔。在这三种情况下,只要尺度改变,就会使用跨行卷积/反卷积。
Backbone adaptation主干适应(跨窗口信息传递)
与Swin不同,不需要“移动”窗口。为了允许信息传播,仅使用非常少的(默认情况下,4个)可以跨窗口的块。将预训练好的主干均匀地分成4个块子集(例如,24块viti - l的每个子集中有6个),在每个子集的最后一个块中应用传播策略。
(i)全球传播。我们在每个子集的最后一个块执行全局自关注。由于全局块的数量较少,内存和计算成本是可行的。这类似于中与FPN联合使用的混合窗口注意
(ii)卷积传播。作为一种选择,我们在每个子集之后添加一个额外的卷积块。卷积块是由一个或多个卷积和一个单位捷径组成的残差块。该块的最后一层初始化为0,使该块的初始状态为id。将一个块初始化为id允许我们将其插入到预训练主干的任何位置,而不会破坏主干的初始状态。
Discussion
1.一个简单的特征金字塔就足够了
2.在少量传播块的帮助下,窗口注意力就够了
Experiment
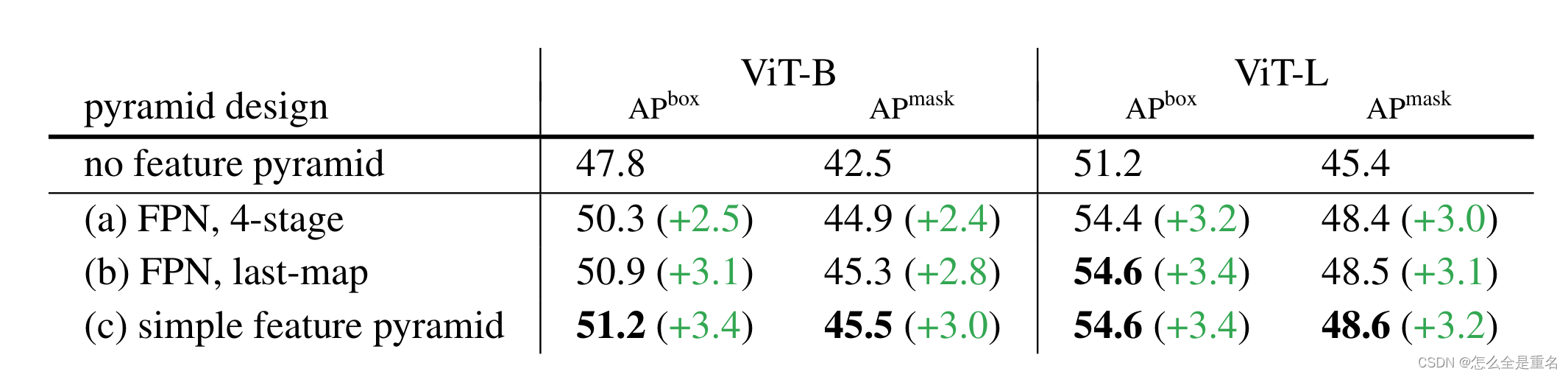
1.简单金字塔已经足够了
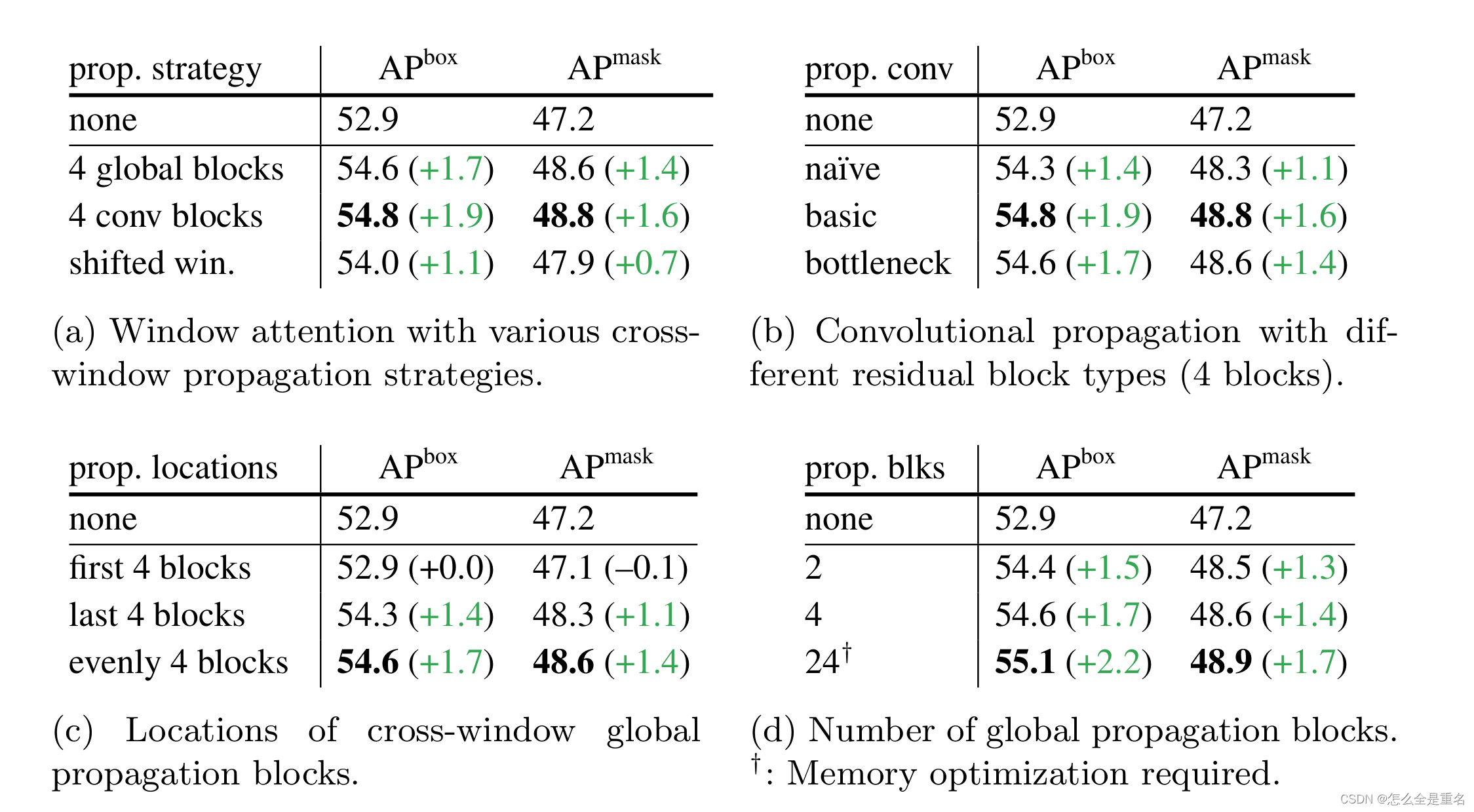
2.在少量传播块的帮助下,窗口注意力是足够的。
 3.与分层主干的比较
3.与分层主干的比较
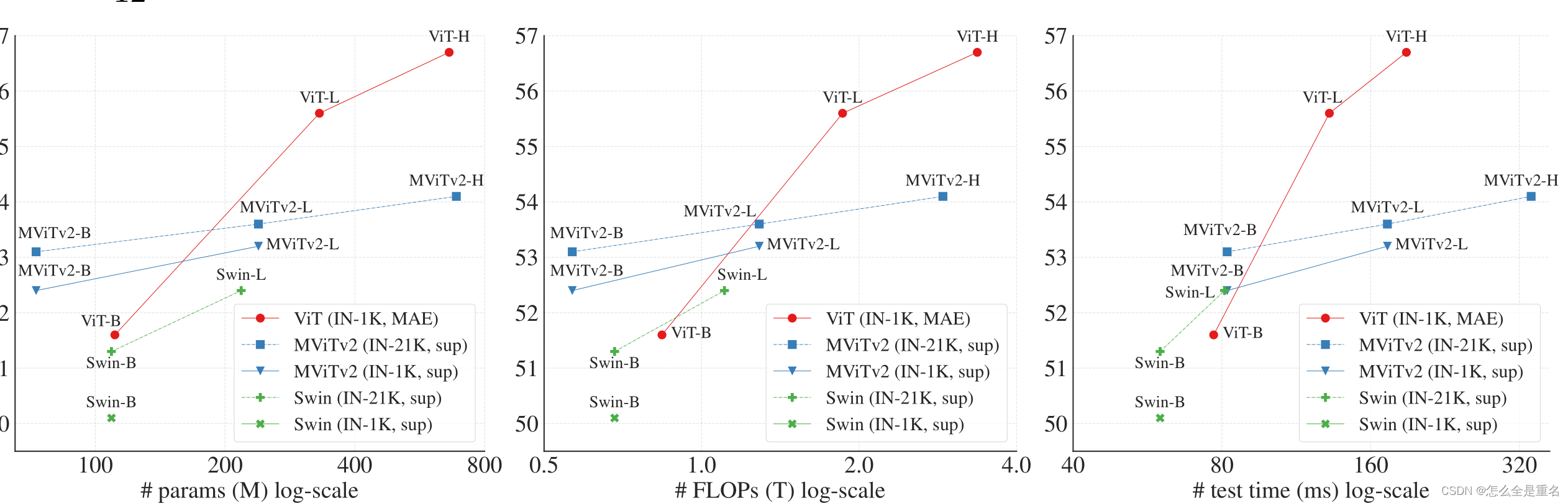 在精度和模型大小,FLOP和wallclock testing time 方面 ViT (IN-1K, MAE) 都表现出了优越性。+
在精度和模型大小,FLOP和wallclock testing time 方面 ViT (IN-1K, MAE) 都表现出了优越性。+
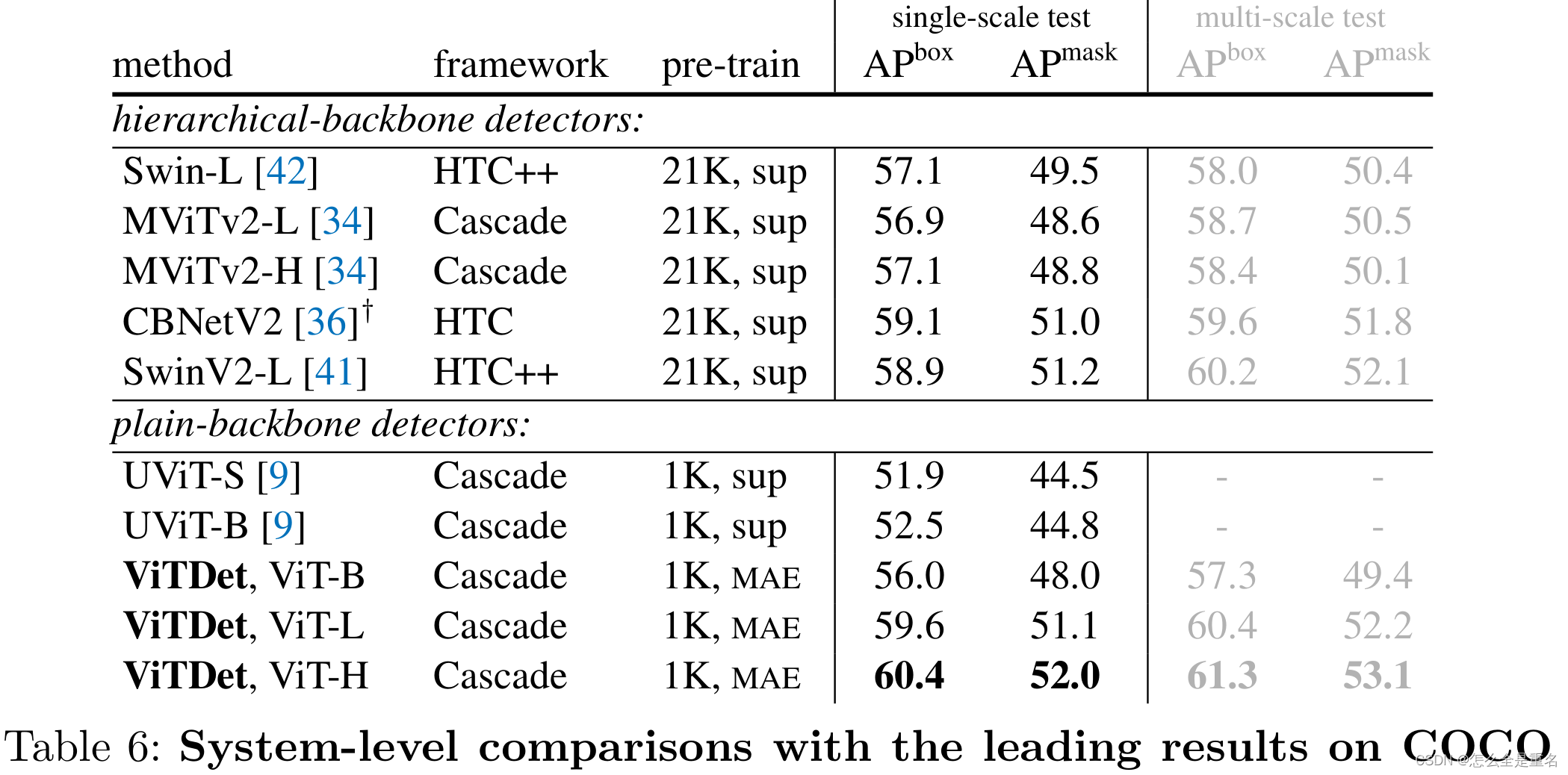
4.与以往系统对比
在COCO和LVIS数据集上都取得了出色的结果
















 3505
3505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









