







需要全套改进代码请私信留言。
目录
🔔🔔5.如何添加CBAM模块到YOLO11工程(含代码修改)
快速通道:CBAM论文讲解请移步这里
🐸🐸1.CBAM模块简介
CBAM(ConvolutionalBlockAttentionModule)模块不是特别新的Attention创新,最开始的Attention大火就是从CBAM开始,可以说CBAM是最经典的注意力模块之一,现在将即插即用的CBAM引入到YOLO11中,仍然能很好的涨点,这也是它结实耐用,经典永流传的原因吧。
🌷1.1模块特点
CBAM模块的
主要目标是:通过在CNN中引入通道注意力和空间注意力来提高模型的感知能力,从而在不增加网络复杂性的情况下改善性能。
操作过程是: 给定一个中间特征图,我们的模块自动沿着两个独立的维度:通道和空间,潜在地推断注意力图,然后将注意力图乘以输入特征用于自适应特征细化的特征图。 因为 CBAM 是一种轻量级的通用模块.
即插即用模块:CBAM模块的输入就是隐层特征图,输出的是同样尺寸大小的隐层特征图,在不改变网络结构的情况下,这种即插即用的模块是最方便使用的。
🌷1.2模块组成
CBAM模块主要由通道注意力机制和空间注意力机制组合而成,其中:
通道注意力聚焦在输入图像“什么”是有意义的。采用平均池化层和最大池化层压缩了输入特征图的空间维度,然后前向传给一个共享多层感知机网络,最后将两个输入加起来,通过一个激活函数,产生了通道注意力图Mc。
空间注意力模块:与通道注意力不同,空间注意力集中于“何处”这一信息性部分,与通道注意力互补。
🌷1.3模块结构
CBAM网络结构图如下所示。
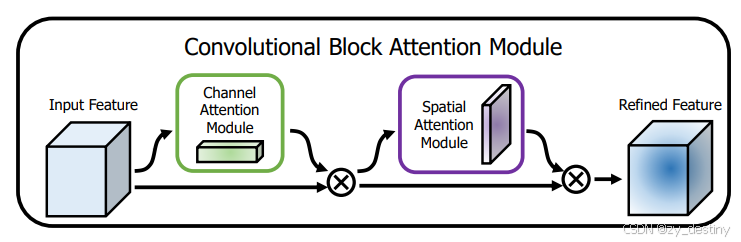
CBAM的计算过程如下:
设特征图F为输入,1D通道注意图Mc ,2D空间注意图Ms,注意力计算过程如下:
![]()
![]()
![]()
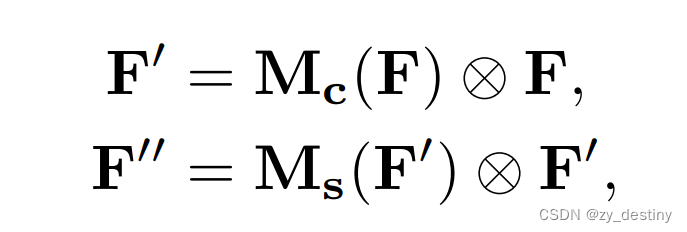
🙋🙋2.CBAM模块优点
CBAM模块的主要优点有:
-
轻量级且通用性强:CBAM是一个轻量级的模块,可以集成到任何卷积神经网络(CNN)架构中,且不会显著增加网络的计算复杂性。这种即插即用的特性使得它非常方便应用于各种现有的CNN模型,而无需对网络结构进行大规模修改。
-
提升模型性能:通过在CNN中引入通道注意力(Channel Attention)和空间注意力(Spatial Attention),CBAM能够自适应地细化特征图,从而在图像分类、目标检测等任务中显著提升模型的性能。实验表明,添加CBAM模块后,各种模型的分类和检测性能均得到了一致改进。
-
多维度注意力机制:CBAM同时考虑了通道维度和空间维度的注意力,能够更全面地捕捉特征图中的重要信息。通道注意力聚焦于“什么”是有意义的,而空间注意力则关注“何处”是重要的,两者相互补充,进一步增强了特征图的表示能力。
-
端到端训练:CBAM模块可以与CNN网络一起进行端到端的训练,无需额外的训练步骤或复杂的优化过程,这使得它在实际应用中更加便捷高效。
-
适用性广泛:CBAM不仅适用于图像分类任务,还在目标检测等多任务上表现出良好的性能提升,证明了其广泛的适用性。
💖💖3.CBAM模块的适用场景
CBAM模块(Convolutional Block Attention Module)作为一种即插即用的注意力机制模块,适用于多种计算机视觉任务和网络架构,以下是其主要适用场景:
👍3.1图像分类
在图像分类任务中,CBAM模块可以显著提升模型的分类准确率。通过在经典网络(如ResNet、VGG、MobileNet等)中加入CBAM模块,模型能够更准确地捕捉到图像中的关键信息。例如,在ImageNet-1K数据集上,将CBAM集成到ResNet-50中,分类准确率从75.0%提升到76.5%。
👍3.2目标检测
在目标检测任务中,CBAM模块能够帮助模型更准确地定位目标物体。通过增强特征图中关键区域的信息,模型能够更准确地预测目标的边界框和类别。例如,在MS COCO和VOC 2007数据集上,集成CBAM模块后,目标检测的平均精度均值(mAP)显著提升。
👍3.3语义分割
在语义分割任务中,CBAM模块通过对特征图进行通道和空间上的注意力增强,能够更精确地分割出图像中的不同区域,从而实现更准确的语义分割。
👍3.4多任务学习
CBAM模块不仅适用于单一任务,还可以在多任务学习中发挥作用。例如,在YOLOv5网络中,CBAM模块被集成到主干网络(backbone)和检测头(head)中,用于提升小目标检测的性能。
👍3.5 轻量级网络优化
由于CBAM模块设计轻量,计算开销小,因此可以无缝集成到各种轻量级网络(如MobileNet)中,提升模型性能的同时保持较低的资源消耗。
👍3.6 特征可视化
通过Grad-CAM等可视化工具,可以观察到CBAM增强的网络比基线网络更准确地聚焦于目标对象,进一步验证了其在特征提取上的优势。
🍌🍌4.创新点CBAM模块python代码
CBAM模块python代码定义如下:
import torch
import torch.nn as nn
# 通道注意力模块
class ChannelAttention(nn.Module):
def __init__(self, in_planes, reduction=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.mlp = nn.Sequential(
nn.Conv2d(in_planes, in_planes // reduction, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_planes // reduction, in_planes, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.mlp(self.avg_pool(x))
max_out = self.mlp(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
# 空间注意力模块
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7, padding=3):
super(SpatialAttention, self).__init__()
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
# CBAM模块
class CBAM(nn.Module):
def __init__(self, in_planes, reduction=16, kernel_size=7):
super(CBAM, self).__init__()
self.ca = ChannelAttention(in_planes, reduction)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
out = x * self.ca(x) # 通道注意力
result = out * self.sa(out) # 空间注意力
return result
# # 测试代码
# if __name__ == '__main__':
# block = CBAM(16)
# input = torch.rand(1, 16, 8, 8)
# output = block(input)
# print(output.shape)🔔🔔5.如何添加CBAM模块到YOLO11工程(含代码修改)
- 新增CBAM.py文件
- 修改ultralytics/nn/tasks.py
新增定义引入,python代码如下:
from ultralytics.nn.CBAM import CBAM
然后,修改def parse_model(d,ch,verbose=True)函数,在1040行新增条件判断,修改后python代码如下:
elif m is AIFI:
args = [ch[f], *args]
###### attention ######
elif m is CBAM:
c2 = ch[f]
args = [c2, *args]
###### attention ######- 修改模型定义yaml文件
例如,在YOLO11的backbone的最后一个环节C2PSA之后添加CBAM模块,yolo_CBAMAttention.yaml的示例如下:
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
- [-1, 1, CBAM, []] # 11
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)开始训练后的YOLO-N模型结构如下:
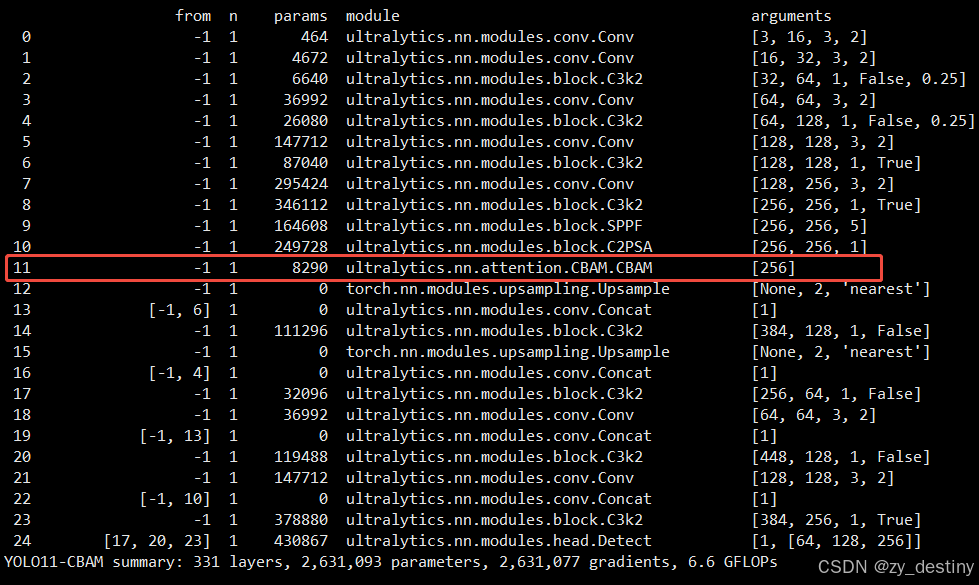
其他位置添加CBAMAttention模块的用法也是一样的,只需在模型定义yaml文件中新增模块就行了。
至此YOLO11工程修改就完成了,可以愉快的开始你的炼丹之旅了。
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











