








理解Region of Interest - ROI pooling
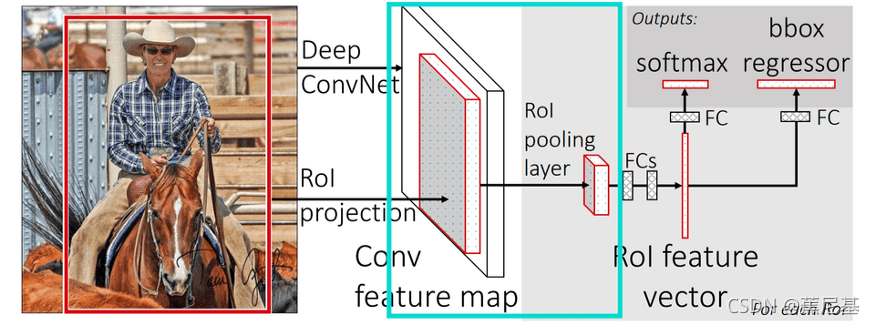
We’re going to discuss original RoI pooling described in Fast R-CNN paper (light blue rectangle on the image above). There is a second and a third version of that process called RoIAlign and RoIWarp.
我们将要讨论Fast R-CNN论文中原始的RoI pooling(如图中蓝框所示),当然有第二个和第三个版本的ROI,叫做RoI Align 和 RoiWarp,下一篇文章我们会讲到。
什么是RoI ?
RoI (Region of Interest) is a proposed region from the original image. We’re not going to describe how to extract those regions because there are multiple methods to do only that. The only thing we should know right now is there are multiple regions like that and all of them should be tested at the end.
Roi(Region of Interest) 是从原始图像中提取的一个区域。我们不会描述如何提取这些区域,因为有很多方法可以做到这一点。我们现在应该知道的唯一一件事是,有很多个像这样的区应该该在最后进行验证。
Fast R-CNN 是如何工作的?
Feature extraction 特征提取
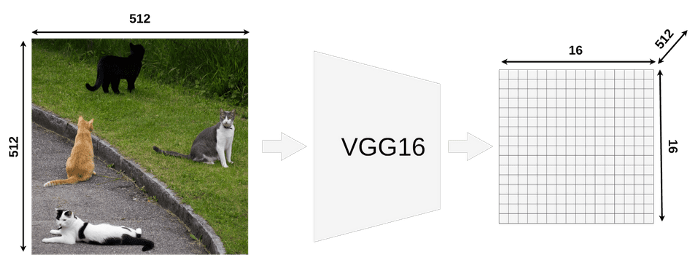
Fast R-CNN is different from the basic R-CNN network. It has only one convolutional feature extraction (in our example we’re going to use VGG16).
Fast R-CNN不同于基本的R-CNN网络。它只有一个卷积特征提取(例中,我们使用VGG16).
Our model takes an image input of size 512x512x3 (width x height x RGB) and VGG16 is mapping it into a 16x16x512 feature map. You could use different input sizes (usually it’s smaller, default input size for VGG16 in Keras is 224x224).
我们的模型采用尺寸为512x512x3((width x height x RGB)的图像输入,VGG16将其映射为16x16x512的feature map。你可以使用不同的输入尺寸(通常它更小,在Keras中,VGG16的默认输入尺寸是224x224)。
If you look at the output matrix you should notice that it’s width and height is exactly 32 times smaller than the input image (512/32 = 16). That’s important because all RoIs have to be scaled down by this factor.
如果你看一下输出矩阵,你应该注意到它的宽度和高度正好是输入图像的32倍(512/32 = 16)。这很重要,因为所有RoI都要按比例缩小。
Sample RoIs
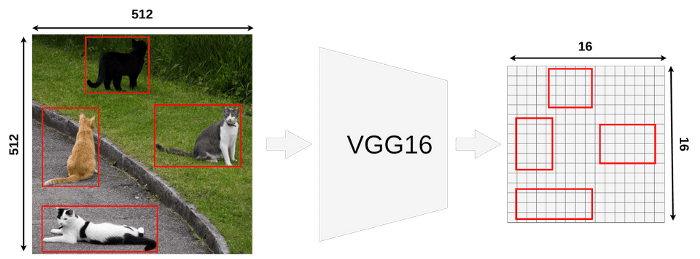
Here we have 4 different RoIs. In the actual Fast R-CNN you might have thousands of them but printing all of them would make image unreadable.
这里有4个不同的RoI。在实际的Fast R-CNN中,你可能有成千上万的图像,但打印所有的图像是不可能做到的。

It’s important to remember that RoI is NOT a bounding box. It might look like one but it’s just a proposal for further processing. Many people are assuming that because most of the papers and blog posts are creating proposals in place of actual objects. It’s just more convenient that way, I did it as well on my image. Here is an example of a different proposal area which also is going to be checked by Fast R-CNN (green box).
重要的是要记住RoI不是一个边界框。它可能看起来像一个进一步处理的提案。许多人之所以这么认为,是因为大多数论文和博客文章都是在创建提案,而不是实际的对象。这样更方便,我在我的图像上也这样做了。这里是一个不同的提案区域的例子,它也将被Fast R-CNN(绿色框)检查。

如何从Feature map 种获取RoI ?
Now when we know what RoI is we have to be able to map them onto VGG16’s output feature map.、现在,当我们知道RoI是什么时,我们必须能够将它们映射到VGG16的输出特征图上。
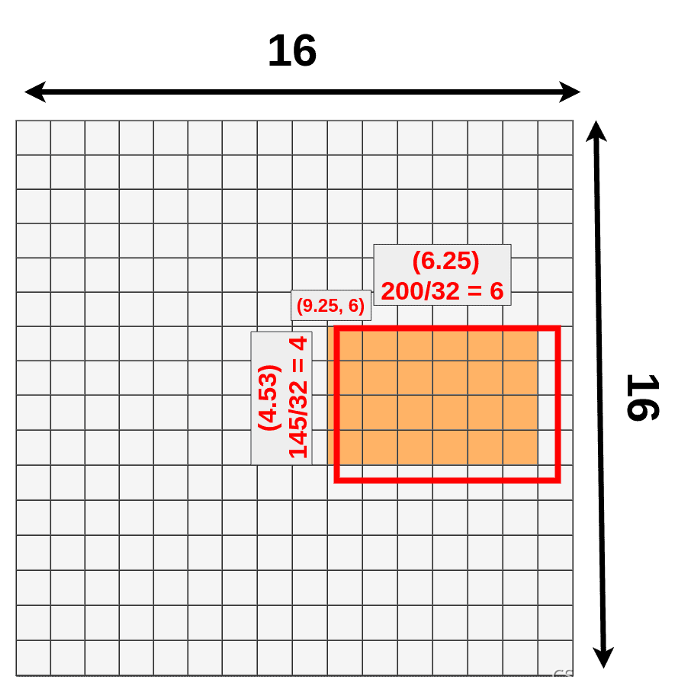
Every RoI has it’s original coordinates and size. From now we’re going to focus only on one of them:
每个RoI都有原始坐标和尺寸。从现在开始,我们只关注其中之一:

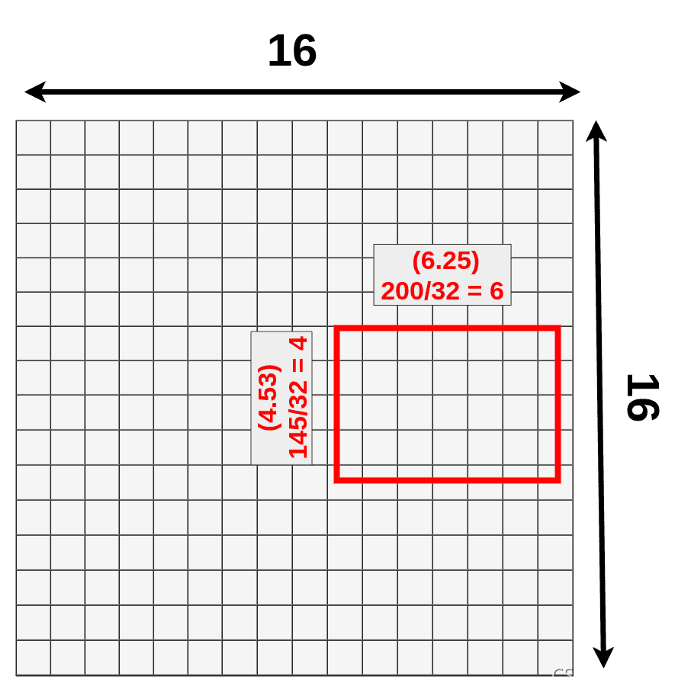
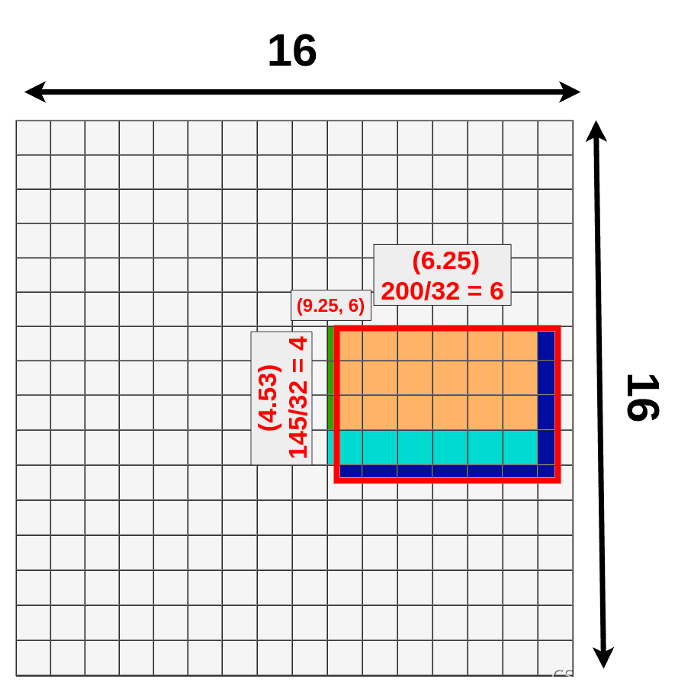
Its original size is 145x200 and the top left corner is set to be in (192,296). As you could probably tell, we’re not able to divide most of those numbers by 32 (scale factor).
- width: 200/32 = 6.25
- height: 145/32 = ~4.53
- x: 296/32 = 9.25
- y: 192/32 = 6
它的原始尺寸是145x200,左上角被设置为(192,296)。你可能知道,我们无法将这些数字除以32(比例因子)。
- width: 200/32 = 6.25
- height: 145/32 = ~4.53
- x: 296/32 = 9.25
- y: 192/32 = 6
Only the last number (Y coordinate of the top left corner) makes sense. That’s because we’re working on a 16x16 grid right now and only numbers we care about are integers (to be more precise: Natural Numbers).
只有最后一个数字(左上角的Y坐标)有意义。这是因为我们现在使用的是16x16的网格,我们只关心整数(更准确地说:自然数)。
feature map上坐标的量化
Quantization of coordinates on the feature map
Quantization is a process of constraining an input from a large set of values (like real numbers) to a discrete set (like integers)
量化是将输入从一组大值(如实数)约束为一组离散值(如整数)的过程。
If we put our original RoI on feature map it would look like this:
如果我们将原始RoI放到feature map上,它会是这样的:
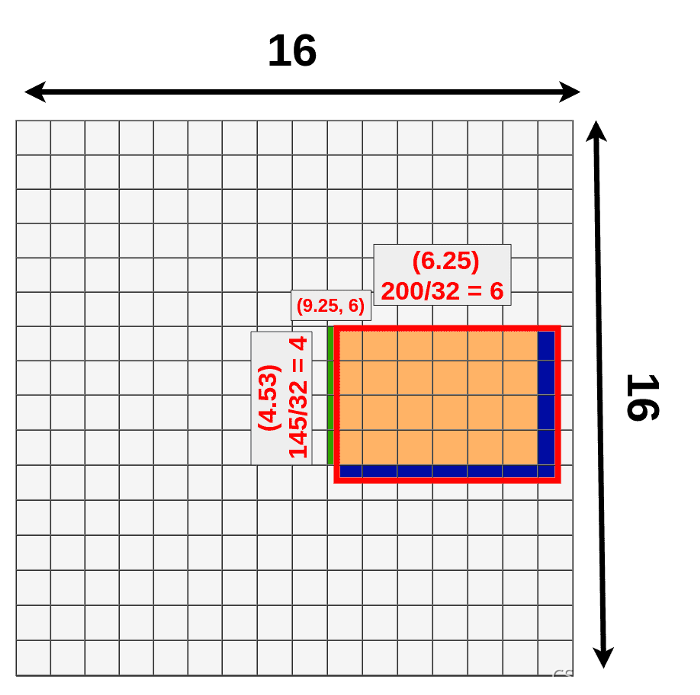
We cannot really apply the pooling layer on it because some of the “cells” are divided. What quantization is doing is that every result is rounded down before placing it on the matrix. 9.25 becomes 9, 4.53 becomes 4, etc.
因为有些“单元”是分裂的,所以我们不能真正应用池化层。量子化所做的是,每个结果都是四舍五入之前,把它放在矩阵上。9.25变成9,4.53变成4,等等。
You can notice that we’ve just lost a bunch of data (dark blue) and gain new data (green):
你可以注意到,我们刚刚丢失了一些数据(深蓝色),并获得了新的数据(绿色):
We don’t have to deal with it because it’s still going to work but there is a different version of this process called RoIAlign which fixes that.
我们不需要处理这个问题,因为它仍然可以工作,但是这个过程有一个不同的版本,叫做RoIAlign,它可以修复这个问题。
如果您基本上了解Roi Pooling ,可以直接去查阅理解Region of Interest - (RoI Align and RoI Warp)我的下一篇文章。
RoI Pooling
Now when we have our RoI mapped onto feature map we can apply pooling on it. Once again we’re going to choose the size of RoI Pooling layer just for our convenience, but remember the size might be different. You might ask “Why do we even apply RoI Pooling?” and that’s a good question. If you look at the original design of Fast R-CNN:
现在,当我们把RoI映射到feature map上时,我们可以在上面应用pooling。为了方便起见,我们还是要选择RoI Pooling层的大小,但记住,大小可能是不同的。你可能会问:“我们为什么要采用RoI Pooling?”这是个好问题。如果你看一下Fast R-CNN的原始设计:
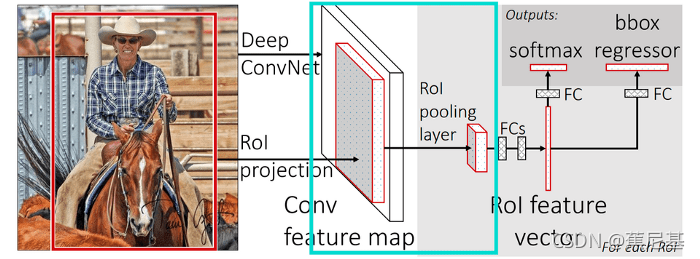
After RoI Pooling Layer there is a Fully Connected layer with a fixed size. Because our RoIs have different sizes we have to pool them into the same size ( 3x3x512 in our example). At this moment our mapped RoI is a size of 4x6x512 and as you can imagine we cannot divide 4 by 3 😦. That’s where quantization strikes again.
在RoI pooling 之后,有一个固定大小的完全连接层。因为RoI有不同的大小,所以我们必须将它们池化成相同的大小(在我们的示例中是3x3x512)。此时,我们映射的RoI是4x6x512的大小,你可以想象,我们不能将4除以3:(。这就是量子化再次发生的地方。
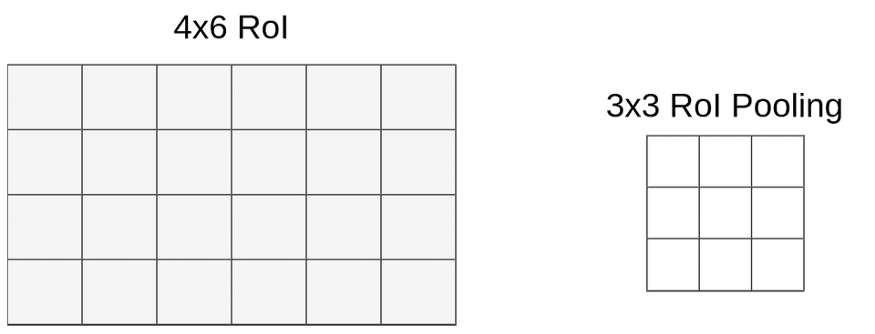
This time we don’t have to deal with coordinates, only with size. We’re lucky (or just convenient size of pooling layer) that 6 could be divided by 3 and it gives 2, but when you divide 4 by 3 we’re left with 1.33. After applying the same method (round down) we have a 1x2 vector. Our mapping looks like this:
这一次我们不需要处理坐标,只需要处理大小。我们很幸运(或者是池化层的方便大小)6可以除以3得到2,但4除以3得到1.33。在应用相同的方法(向下四舍五入)之后,我们得到了一个1x2向量。我们的映射是这样的:
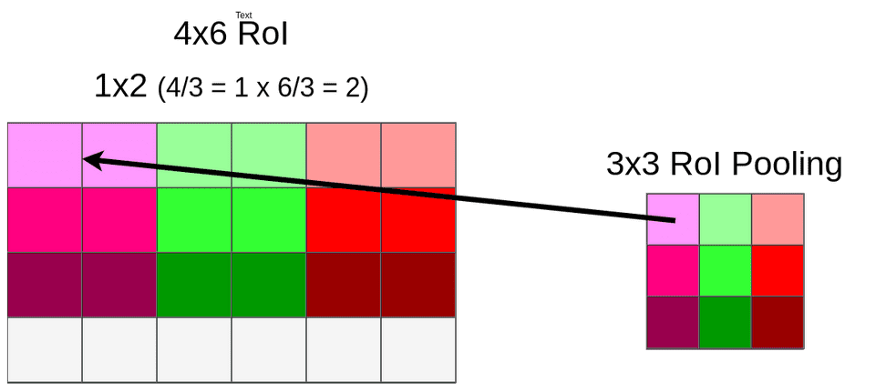
Because of quantization, we’re losing whole bottom row once again:
因为量化,我们又失去了整行:
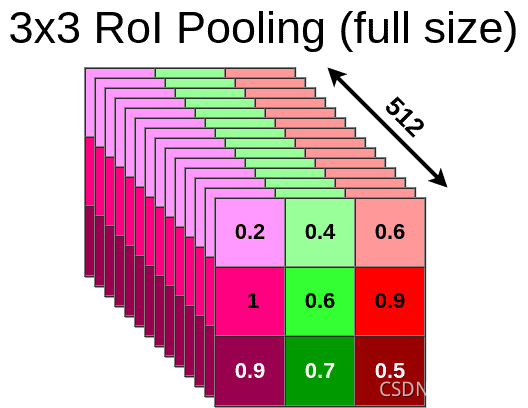
Now we can pool data into 3x3x512 matrix
现在我们可以将数据集合到3x3x512矩阵中

In this case, we’ve applied Max Pooling but it might be different in your model. Ofc. this process is done on the whole RoI matrix not only on the topmost layer. So the end result looks like this:
在这个例子中,我们应用了Max Pooling但是在你的模型中可能会有所不同。这个过程是在整个RoI矩阵上完成的,而不仅仅是在最上层。所以最终结果是这样的:
The same process is applied to every single RoI from our original image so in the end, we might have hundreds or even thousands of 3x3x512 matrixes. Every one of those matrixes has to be sent through the rest of the network (starting from the FC layer). For each of them, the model is generating bbox and class separately.
同样的过程适用于我们原始图像的每个RoI,所以最后,我们可能会有数百甚至数千个3x3x512矩阵。每一个矩阵都必须通过网络的其余部分发送(从FC层开始)。对于它们中的每一个,模型分别生成bbox和类。
最后
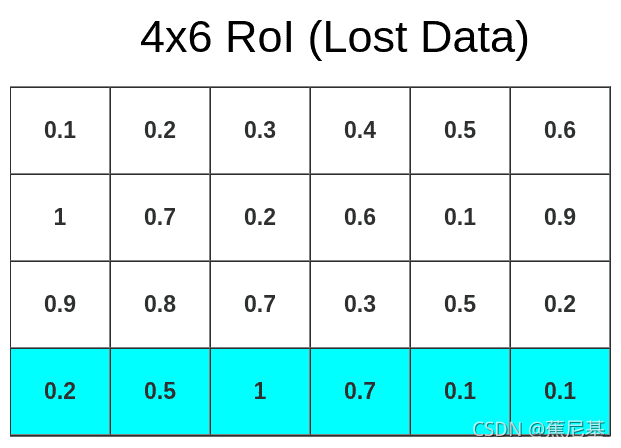
After pooling is done, we’re certain that our input is a size of 3x3x512 so we can feed it into FC layers for further processing. There is one more thing to discuss. We’ve lost a lot of data due to the quantization process. To be precise, that much:
池化处理完成后,我们确定输入的大小为3x3x512,这样我们就可以将其输入到FC层中进行进一步处理。还有一件事要讨论。由于量化过程,我们丢失了很多数据。准确地说,就是:
This might be a problem because each “cell” contains a huge amount of data (1x1x512 on feature map which loosely translates to 32x32x3 on an original image but please do not use that reference, because that’s not how convolutional layer works). There is a way to fix that (RoIAlign) and I’m going to write a second article about it soon.
这可能是个问题,因为每个“单元格”包含大量的数据(feature map上的1x1x512大致转换为32x32x3的原始图像,但请不要使用那个参考,因为这不是卷积层的工作方式)。有一种方法可以解决这个问题(RoIAlign),我很快就会写第二篇相关文章。

















 4304
4304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









