






YOLO-MS 顶刊一区TPAMI期刊|理论部分解析
博客 包括 一区顶刊TPAMI期刊|YOLO-MS论文 - 论文解析部分
文章末尾部分 包含 YOLO11、YOLOv8、YOLOv10、RT-DETR、YOLOv7、YOLOv5 等模型 结合 + 一区顶刊TPAMI期刊|YOLO-MS 原创改进核心内容
该论文提出基于经验发现的HKS协议,在不同阶段采用不同核大小的卷积层,借助大卷积核在速度和精度之间实现良好的权衡。
论文信息:YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-time Object Detection
论文链接:https://arxiv.org/pdf/2308.05480
YOLO-MS: Rethinking Multi-Scale Representation Learning for Real-time Object Detection核心内容总结
一、研究背景与目标
实时目标检测在工业领域,特别是边缘设备(如无人机和机器人)中有着广泛应用。与传统的重型目标检测器不同,实时目标检测器需要在速度和精度之间寻求最佳平衡。尽管现有实时目标检测器性能不断提升,但识别不同尺度的物体仍然是一个挑战。
本文旨在为目标检测领域提供一种高效且性能优越的目标检测器——YOLO-MS。通过从全局和局部两个新视角研究不同卷积核大小对不同尺度物体检测性能的影响,设计出能够有效学习多尺度特征表示的编码器架构,进而提升实时目标检测器的多尺度特征表示能力。
二、相关工作
2.1 实时目标检测
目标检测任务是在特定场景中检测物体。多阶段检测器和端到端检测器性能出色,但结构复杂,难以实现实时性能。为了在速度和精度之间进行权衡,许多研究致力于开发高效的检测器,其中大多数实时目标检测网络采用单阶段框架,YOLO系列是最典型的代表。
在YOLO的发展过程中,网络架构不断演变。YOLOv1是YOLO系列的开端,之后YOLOv4引入CSPNet对DarkNet进行改进以提升性能;YOLOv6和PPYOLOE探索了重参数化技术;YOLOv7提出E - ELAN以有效学习和收敛;RTMDet则引入大卷积核(5×5)增强特征提取能力。本文聚焦于通过学习更具表现力的多尺度特征表示来改进实时目标检测器,与以往工作不同。
2.2 多尺度特征表示
多尺度特征表示学习在计算机视觉领域历史悠久,强大的多尺度特征表示能力能有效提升模型性能,在实时目标检测等众多任务中得到验证。
在实时目标检测中,许多方法通过在颈部集成不同特征层的特征来提取多尺度特征,如YOLOv3和后续的YOLO系列分别引入FPN和PAFPN,SPP模块也被广泛用于扩大感受野,多尺度数据增强也是常用的训练技巧。然而,主流的基本构建块在关注检测效率或引入新训练技术时,忽视了多尺度特征表示的重要性,而本文方法专注于学习更丰富的多尺度特征。
大卷积核在构建强大的多尺度特征表示方面具有潜力,RTMDet首次尝试在网络中采用大卷积核,但受速度限制,其核大小仅达到5×5,且不同阶段的同质块设计限制了大卷积核的应用。本文提出基于经验发现的HKS协议,在不同阶段采用不同核大小的卷积层,借助大卷积核在速度和精度之间实现良好的权衡。
三、方法
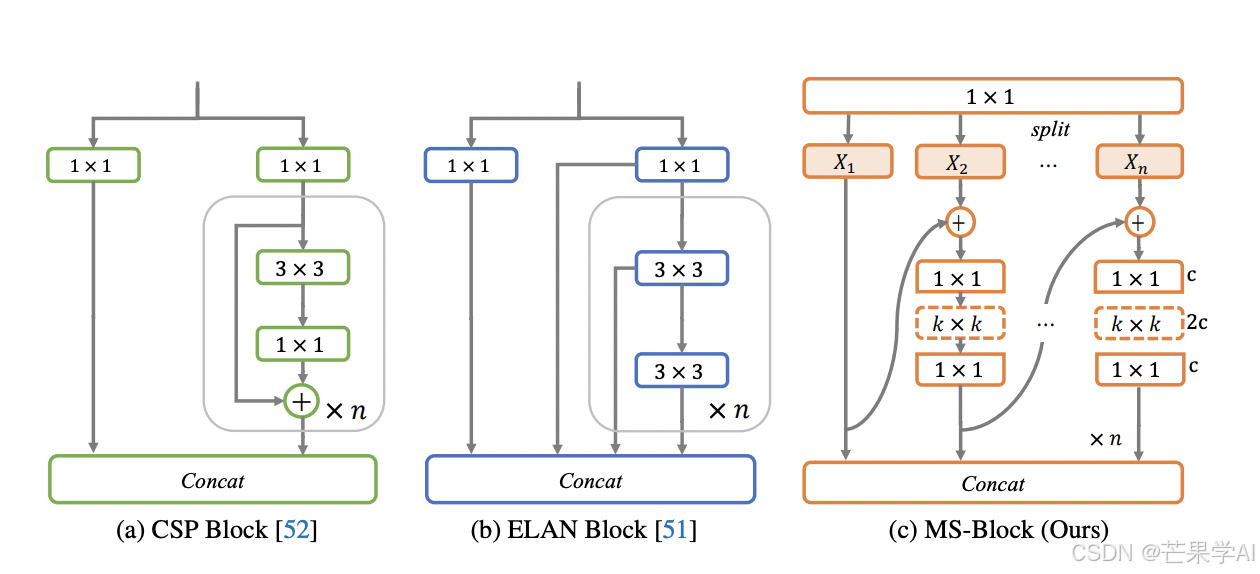
3.1 多尺度构建块设计
CSP Block是基于阶段级梯度路径的网络,用于平衡梯度组合和计算成本,是YOLO系列中广泛使用的基本构建块,有多种变体。但上述实时检测器忽略了在基本构建块中编码多尺度特征的问题。Res2Net聚合不同层次的特征以增强多尺度表示,但未充分探索大卷积核的作用,且其采用标准卷积,引入大卷积核会带来计算负担。
本文提出MS - Block,基于层次特征融合策略,旨在增强实时目标检测器在保持快速推理速度的同时提取多尺度特征的能力。假设输入特征
X
∈
R
H
×
W
~
×
C
X \in R^{H ×\tilde{W} ×C}
X∈RH×W~×C ,经过1×1卷积后,通道维度增加到
n
×
C
n ×C
n×C ,将
X
X
X 拆分为
n
n
n个不同的组
{
X
i
}
\{X_i\}
{Xi} ,
i
∈
1
,
2
,
3
,
.
.
.
,
n
i \in 1,2,3, ..., n
i∈1,2,3,...,n ,这里选择
n
=
3
n = 3
n=3以降低计算成本。除
X
1
X_1
X1外,其他组经过倒置瓶颈层
I
B
k
×
k
(
⋅
)
IB_{k ×k}(\cdot)
IBk×k(⋅)(
k
k
k为核大小)得到
Y
i
Y_i
Yi ,其数学表示为:
Y
i
=
{
X
i
,
i
=
1
I
B
k
×
k
(
Y
i
−
1
+
X
i
)
,
i
>
1
Y_{i}= \begin{cases}X_{i}, & i=1 \\ IB_{k × k}\left(Y_{i-1}+X_{i}\right), & i>1\end{cases}
Yi={Xi,IBk×k(Yi−1+Xi),i=1i>1
X
1
X_1
X1作为跨阶段连接保留前层信息。最后,将所有拆分的特征连接起来,并应用1×1卷积在不同尺度的特征之间进行交互,同时在网络加深时调整通道数。
3.2 异构核选择协议
以往实时目标检测器在不同编码器阶段采用同质卷积(即相同核大小的卷积),但这并非提取多尺度语义信息的最优选择。在金字塔架构中,浅层的高分辨率特征用于捕获细粒度语义以检测小物体,深层的低分辨率特征用于捕获高级语义以检测大物体。若所有阶段都采用统一的小卷积核,深层的有效感受野会受限,影响对大物体的检测性能;而在各阶段都采用大卷积核,虽能扩大感受野,但会增加包含小物体外部污染信息的概率,降低推理速度。
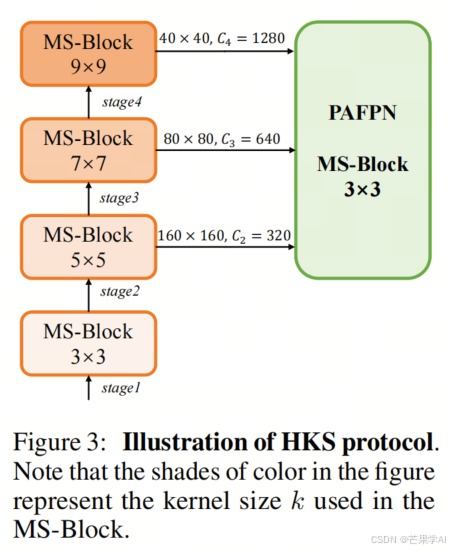
本文提出在不同阶段利用异构卷积来捕获更丰富的多尺度特征。具体来说,在编码器的第一阶段使用最小核卷积,最后一阶段使用最大核卷积,中间阶段逐渐增大核大小,使其与特征分辨率的增加保持一致。如图3所示,从浅层到深层,将 k k k的值分别设为3、5、7和9,这种策略称为异构核选择(HKS)协议。HKS协议能在不影响浅层的情况下扩大深层的感受野,有助于编码更丰富的多尺度特征,同时确保高效推理。
实验表明,在网络的不同阶段应用不同核大小的卷积,在低分辨率特征上采用大卷积核,与仅使用大卷积核相比,可大幅降低计算成本。实际上,采用HKS协议的YOLO - MS与仅使用深度可分离3×3卷积的模型推理速度相近。
3.3 架构
如图3所示,YOLO - MS的骨干网络由四个阶段组成,每个阶段后接一个步长为2的3×3卷积进行下采样。在第三阶段后添加SPP块,采用PAFPN作为颈部构建特征金字塔,颈部的基本构建块为MS - Block,使用3×3深度可分离卷积以实现快速推理。
为在速度和精度之间实现更好的权衡,将骨干网络中多级特征的通道深度减半。提出YOLO - MS的三个变体,即YOLO - MS - XS、YOLO - MS - S和YOLO - MS,不同尺度的详细配置如下表所示:
| Model | { C 1 C_1 C1, C 2 C_2 C2, C 3 C_3 C3, C 4 C_4 C4} | Channel Expansion Ratio | Params(M) | FLOPs(G) |
|---|---|---|---|---|
| YOLO-MS-XS | {32, 64, 128, 256} | c → 2 c c \to 2c c→2c | 4.54 | 8.74 |
| YOLO-MS-S | {43, 86, 172, 344} | c → 2 c c \to 2c c→2c | 8.13 | 15.58 |
| YOLO-MS | {64, 128, 256, 512} | c → 2 c c \to 2c c→2c | 22.17 | 40.09 |
四、实验
4.1 实验设置
- 实现细节:基于MMDetection框架和PyTorch进行实现。在拥有8个V100 GPU的机器上进行实验,每个GPU的批量大小设为8以保证公正性。所有尺度的YOLO - MS均从头开始训练300个epoch,不依赖其他大规模数据集(如ImageNet)或预训练权重,更多实现细节见补充材料。
- 数据集:在广泛使用的MS COCO基准上评估所提出的检测器,遵循以往工作的标准做法。使用train2017集(包含115K图像)进行训练,val2017集(包含5K图像)进行验证。采用标准的COCO风格测量指标,即平均精度(AP)作为主要评估指标,同时报告IoU阈值为0.5和0.75时的mAP,以及小、中、大物体的AP作为辅助指标。
- 基准设置:使用NVIDIA 3090 GPU以全精度浮点格式(FP32)测量所有模型的每秒帧数(FPS)。在测试时,使用TensorRT 8.4.3和cuDNN 8.2.0进行推理,不进行NMS后处理步骤,推理过程的批量大小设为1。使用MMDetection框架,基于640×640的输入大小计算FLOPs。
4.2 对MS - Block的分析
以YOLO - MS - XS为默认实验模型,对MS - Block进行一系列消融分析。
- 倒置瓶颈:对MS - Block中倒置瓶颈的通道扩展比 r r r进行消融研究,结果表明当 r = 2 r = 2 r=2时,检测器实现了最佳的权衡。 r = 1 r = 1 r=1时AP比 r = 2 r = 2 r=2低1.2, r = 3 r = 3 r=3时比 r = 2 r = 2 r=2高1,但计算成本更高。因此,后续实验默认使用 r = 2 r = 2 r=2以保持高计算效率。
- 特征融合策略:MS - Block通常通过加法逐步融合相邻分支的特征。对特征融合策略进行消融研究,结果表明分支之间的特征融合操作对提高模型性能至关重要,为YOLO - MS带来了1.2%的AP显著提升。
- MS - Layers的数量:分析不同数量的MS - Layers(用 N t N_t Nt表示)对计算成本和推理速度的影响。以YOLO - MS - XS为例,当 N t N_t Nt从1增加到2再到3时,参数数量分别增加25.8%和51.5%,FLOPs分别增加18.1%和36.2%,推理过程的FPS在 N l = 2 N_l = 2 Nl=2和 N l = 3 N_l = 3 Nl=3时分别下降9.2%和16.6%。因此,后续实验默认使用 N l = 1 N_l = 1 Nl=1。
- 注意力机制:按照RTMDet的做法,在最后一个1×1卷积后使用SE注意力机制来捕获通道间的相关性。实验表明,注意力机制只能略微提升性能,但会减慢推理时间,用户可根据自身情况选择性使用。
- 分支数量:MS - Block对输入特征进行分区并通过多个分支传播,但增加分支数量会导致MS - Layers增加和每个分支通道数减少。对分支数量 N b N_b Nb进行消融研究,结果表明直接增加分支数量并不总是能提高性能,当 N b = 3 N_b = 3 Nb=3时,YOLO - MS达到最佳性能43.4% AP,分别比 N b = 2 N_b = 2 Nb=2和 N b = 4 N_b = 4 Nb=4高1.2%和0.2%。因此,后续实验默认使用 N b = 3 N_b = 3 Nb=3。
- PAFPN模块的消融研究:对PAFPN模块进行消融研究,结果表明本文提出的方法在计算成本较低的情况下,性能与无预训练权重的PAFPN相近,且优于无PAFPN的基线。此外,本文方法与FPN模块是正交的,带有PAFPN - MS(含MS - Block的PAFPN)的检测器在仅使用约60%的参数和约80%的FLOPs的情况下,性能提升了0.2% AP。
- 图像分辨率分析:研究图像分辨率与多尺度构建块设计之间的相关性。在推理时应用测试时增强(Test Time Augmentation),对图像进行多尺度变换(320×320、640×640和1280×1280),并分别使用这些分辨率进行测试。训练时使用的图像分辨率为640×640。实验结果表明,随着图像分辨率的增加, A P s AP_s APs也增加,但低分辨率图像可实现更高的 A P l AP_l APl,这也验证了HKS协议的有效性。
- 应用于其他YOLO模型:本文提出的方法可作为其他YOLO模型的即插即用模块。将其应用于其他YOLO模型并在MS COCO上进行综合比较,结果表明YOLOv6和YOLOv8的AP分数可显著提高,分别达到43.5%(提高2.5%)和40.3%(提高3.1%),且参数和FLOPs更少。
4.3 对HKS协议的分析
通过探索不同的卷积核大小设置来评估HKS协议的有效性,使用格式 [ k 1 , k 2 , k 3 , k 4 ] [k_1, k_2, k_3, k_4] [k1,k2,k3,k4]表示不同阶段的卷积核大小,研究同质卷积核大小设置(3、5、7、9、11)以及HKS协议的反向设置 [ 9 , 7 , 5 , 3 ] [9, 7, 5, 3] [9,7,5,3]。
实验结果表明,简单增加卷积核大小并不总是能带来显著的性能提升,而采用HKS协议可实现性能的大幅提升(43.4% AP),优于所有同质卷积核大小设置。卷积核在各阶段的排列顺序也至关重要,在浅层使用大卷积核、深层使用小卷积核时,性能比HKS协议下降0.9% AP,这表明深层需要更大的感受野来有效捕获粗粒度信息。从计算成本来看,HKS协议的计算开销最小,通过在合适的位置战略性地放置不同核大小的卷积,可最大化卷积的有效利用。
利用有效感受野(ERF)的概念进一步研究HKS协议的有效性,测量编码器第2、3、4阶段中包含高贡献像素区域的边长。结果显示,随着卷积核大小的增加,所有阶段的ERF面积都变大,支持了卷积核大小与感受野之间的正相关关系。在浅层,HKS协议的ERF面积比大多数其他设置小,而在深层则相反,这表明该协议有效扩大了深层的感受野,同时不影响浅层。与其他实时检测器相比,HKS协议在深层实现了最大的ERF,有助于更好地检测大物体。
4.4 与现有方法的比较
- 可视化比较:使用Grad - CAM生成类激活映射,以评估检测器关注图像的哪些部分。对YOLOv6 - tiny、RTMDet - tiny、YOLOV7 - tiny和YOLO - MS - XS颈部生成的类激活映射进行可视化,从MS COCO数据集中选择不同大小(小、中、大)的典型图像。结果显示,YOLOv6 - tiny、RTMDet - tiny和YOLOV7 - tiny在检测小而密集的物体(如人群)时失败,并忽略了部分物体;而YOLO - MS - XS在类激活映射中对所有物体都有强烈响应,表明其具有出色的多尺度特征表示能力,在检测不同大小的物体和包含不同密度物体的图像时表现优异。
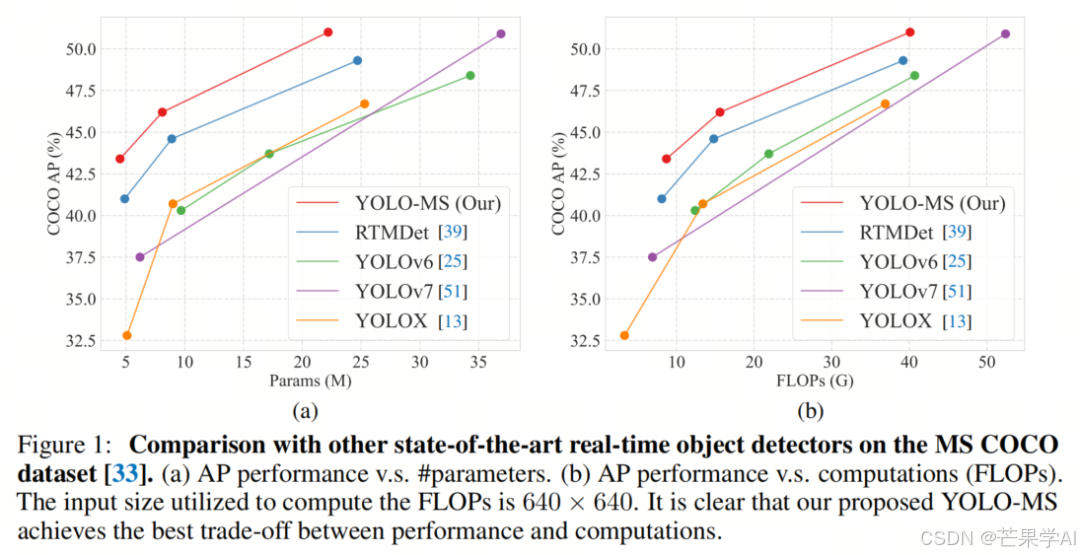
- 定量比较:将YOLO - MS与当前最先进的目标检测器进行比较。从结果表中可以看出,YOLO - MS在速度和精度之间实现了卓越的权衡。与第二好的tiny检测器RTMDet相比,YOLO - MS - XS的AP达到43.4%,比使用ImageNet预训练模型的RTMDet高2.3% AP。YOLO - MS - S的AP达到46.2%,与YOLOv6相比,在参数约为其一半的情况下,AP提升了5.7%。YOLO - MS的检测性能为51.0% AP,优于具有相似参数和计算复杂度的最先进目标检测器,甚至优于大规模模型(如YOLOv6 - M和YOLOv6 - L)。因此,YOLO - MS可作为实时目标检测的有前景的基线,提供强大的多尺度特征表示。
五、结论与讨论
本文提出了一种计算成本合理的高性能实时目标检测器YOLO - MS。通过从全局和局部视角研究不同卷积核大小的使用,构建了具有强大多尺度特征表示提取能力的编码器。实验研究发现,提出的HKS策略和MS - Block显著提升了检测器的速度 - 精度权衡,性能优于其他实时检测器,为目标检测领域带来了新的思路。
然而,YOLO - MS在推理速度上与最先进的实时检测器仍存在差距,主要原因是大卷积核的低效性和层次结构。这激励进一步优化大卷积核的使用并简化YOLO - MS的结构,以实现更快版本的YOLO - MS。
芒果YOLO系列改进:基于 MSBlock 原创改进内容🚀🚀🚀
5.1 将 MSBlock 改进到 YOLO11 中 - 基于 MSBlock 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLO11改进78:主干Backbone篇之MSBlock:即插即用 | 集成YOLO-MS论文SOTA核心结构,原汁原味YOLO11改进升级版,打破性能瓶颈
5.2 将 MSBlock 改进到 YOLOv8 中 - 基于 MSBlock 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLOv8改进83:主干Backbone篇之MSBlock:即插即用 | 集成YOLO-MS论文SOTA核心结构,原汁原味YOLOv8改进升级版,打破性能瓶颈
5.3 将 改进到 YOLOv10 中 - 基于 MSBlock 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLOv10改进69:主干Backbone篇之MSBlock:即插即用 | 集成YOLO-MS论文SOTA核心结构,原汁原味YOLOv8改进升级版,打破性能瓶颈
5.4 将 MSBlock 改进到 RT-DETR 中 - 基于 MSBlock 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLOv8改进83:主干Backbone篇之MSBlock:即插即用 | 集成YOLO-MS论文SOTA核心结构,原汁原味YOLOv8改进升级版,打破性能瓶颈 适用于 ultralytics 版本的 RT-DETR
5.5 将 MSBlock 改进到 YOLOv7 中 - 基于 MSBlock 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLOv7改进:主干Backbone篇之MSBlock:借鉴YOLO-MS论文SOTA核心结构,改进升级版,原始结构超越YOLOv8与RTMDet,即插即用打破性能瓶颈
5.6 将 MSBlock 改进到 YOLOv5 中 - 基于 MSBlock 原创改进核心内容
详情改进内容点击:🚀🚀🚀芒果YOLOv5改进78:主干Backbone篇之MSBlock:借鉴YOLO-MS论文SOTA核心结构,改进升级版,原始结构超越YOLOv8与RTMDet,即插即用打破性能瓶颈


















 697
697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











