







2024年2月16日,OpenAI发布首个视频生成模型Sora。Sora继承DALL•E3的画质和遵循指令能力,能生成长达1分钟的高清视频。Sora的出现对AI行业的发展具有里程碑意义。从中短期看Sora作为一款具有强劲性能的视频生成模型,将提升视频生成的质量和效率,对影视和游戏等相关行业具有变革作用;从长期看Sora有望成为一款世界模拟器的视频生成模型,为未来发展理解和模拟真实世界的模型奠定基础。
围绕Sora,下面我们从其实现功能、技术路径、算法实现等基本信息入手,了解Sora功能优势及局限;梳理文本视频大模型发展历程及当前代表性文生模型并与其对比,对Sora进行算力预估并对其未来发展影响进行展望,方便读者深入了解这一大模型。
01Sora概述
1.OpenAI发布首个视频生成模型Sora
2月16日,OpenAI发布了推出了一款能根据文字指令即时生成短视频的模型,命名为Sora。
根据介绍,Sora使用扩散模型技术,完美继承了DALL•E3的画质和遵循指令能力,能够从文本说明中生成长达60秒的视频,并能够提供具有多个角色、特定类型的动作和详细背景细节的场景。借助GPT的能力,Sora能够实现对语言的深入理解,使其能够准确地解释提示词,并生成引人注目的字符来表达充满活力的情感。Sora还能在一个生成的视频中创建多个镜头,体现人物和视觉风格。

2.实现功能
OpenAI表示,通过让模型一次生成多帧画面,Sora解决了一个具有挑战性的问题,即:即使生成的主体暂时离开视线内,也能确保主体不变。

除文生视频外,Sora还具有更多功能:1)根据图像生成动画;2)在时间上向前或向后扩展视频;3)编辑输入的视频;4)在两个输入视频之间逐渐进行插值,从而在具有完全不同主题和场景构成的视频之间创建无缝过渡;5)根据文字生成图像。

3.技术路径
Sora取法Tokens文本特征标记,是基于Patches视觉特征标记的Diffusion Transformer模型。OpenAI研究团队从LLM中汲取灵感,认为LLM范式的成功在一定程度上得益于Tokens的使用,Tokens统一了代码、数学和各种自然语言的文本模式。类似于LLM范式下的Tokens文本标记,Sora创新性地使用了Patches(apart of something marked out from the rest by a particular characteristic;视觉特征标记)。
鉴于Patches之前已被证明是视觉数据模型的有效表示,OpenAI研究团队进一步研发发现Patches是一种高度可扩展且有效的表示,可以被用于在不同类型的视频和图像上训练生成模型:
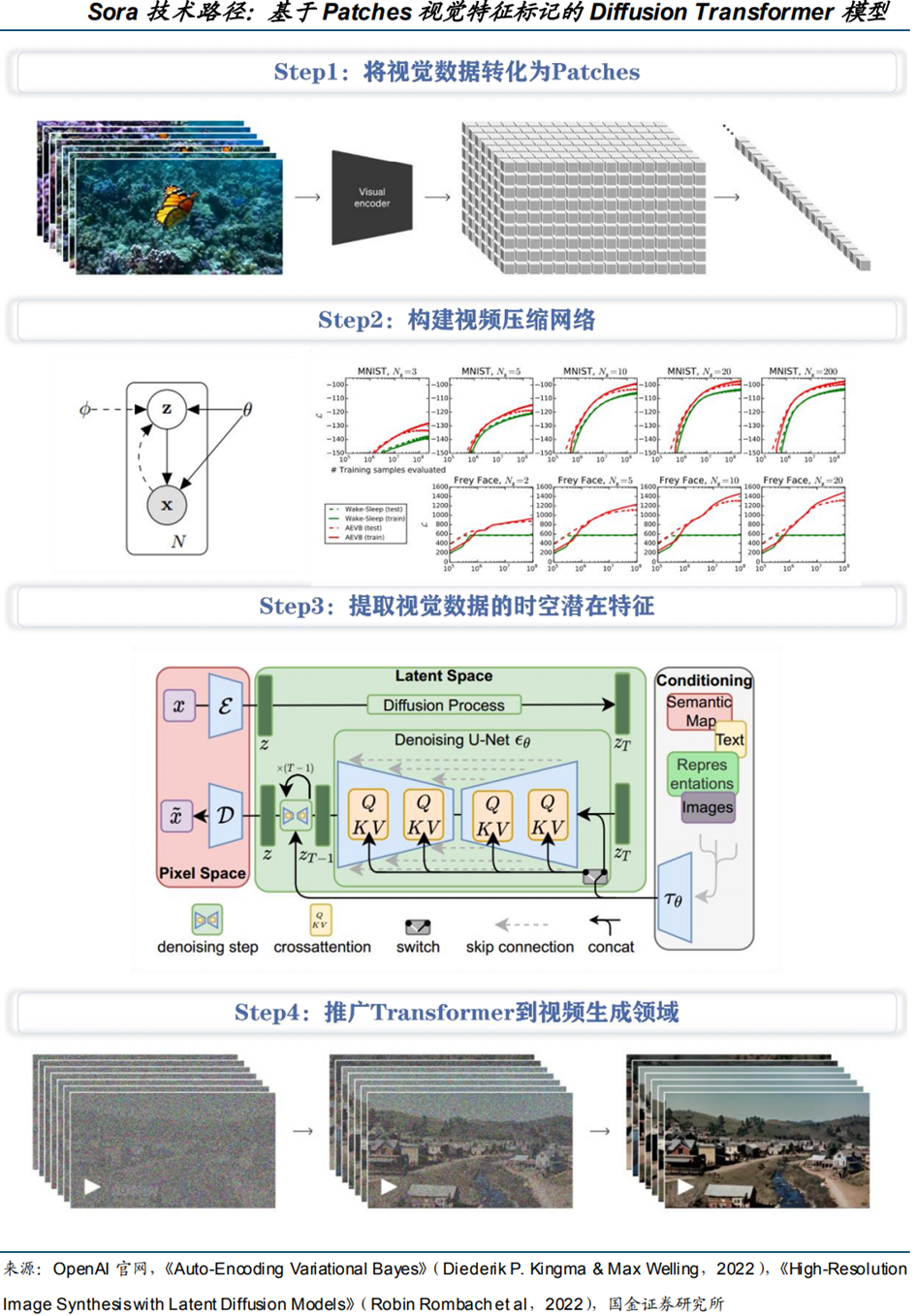
(1)将视觉数据转化为Patches(Turning visual data into patches)
将视频、图像等视觉数据压缩至低维的潜在空间中,并将其分解为带有时空(Spacetime)特征的Patches(若为图像,则对空间特征进行分解),从而将视觉数据转换为Patches。
(2)构建视频压缩网络(Video compression network)
OpenAI训练的视频压缩网络将原始视频作为输入,并输出在时间和空间上都经过压缩的潜在特征。Sora在这个压缩的潜在空间中接受训练并生成视频。OpenAI还训练了一个相应的解码器模型,该模型将生成的潜在对象映射回像素空间。
(3)提取视觉数据的时空潜在特征(Space time Latent Patches)
给定一个压缩的输入视频,提取一系列时空特征Patches(此方案也适用于图像,因为图像只是单帧视频)。基于Patches的表示使Sora能够利用不同分辨率、视频时间和宽高比的视频和图像进行训练。在推理时,可以通过在适当大小的网格中排列随机初始化的Patches来控制生成的视频的大小。
(4)Transformer模型到视频生成领域(Scaling transformers for video generation)
Sora是一个Diffusion Transformer模型,给定输入的嘈杂(noisy)Patches(以及文本提示等条件信息),它被训练来预测原始的干净(clean)Patches,继而生成高清视频。随着训练计算量的提高,样本质量也明显提高。
4.算法实现
为什么选择Patches呢?这是因为Patches实现更灵活的采样+更优化的构图。
从训练角度而言,基于Patches视觉特征标记对原生视频进行采样扩大了可用样本的规模且省去了标准化样本的步骤。对于不同分辨率、视频长度和宽高比的视频,以往常见的做法是将视频剪辑、调整大小或修剪到标准格式(例如:分辨率为256x256的4秒视频),而Sora则基于Patches视觉特征标记对原生视频进行采样(Sora可对宽屏1920x1080p视频、垂直1080x1920p视频以及介于两者之间的所有视频进行采样)。
从推理角度而言,基于原生视频训练的模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2784
2784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









