







卷积神经网络由卷积核来提取特征,通过池化层对显著特征进行提取,经过多次的堆叠,得到比较高级的特征,最后可以用分类器来分类。这是CNN的一个大概流程,其具体实现的结构是丰富多样的,但总的思想是统一的。
一个图像分类模型的流程大概是:输入image->卷积和池化->最后一层的feature map->全连接层->损失函数层softmax loss
同样VGG也是由conv、pool、fc、softmax层组成。VGG网络的卷积层,没有缩小图片,每层padding都是有值的,图片缩小都是由pool来实现的。
(一)VGG简介
VGG块的组成规律是:连续使用数个相同的填充为1、窗口形状为3×3 的卷积层后接上一个步幅为2、窗口形状为2×2 的最大池化层。可以看出卷积层保持输入的高和宽不变,而池化层则对其减半。
那么VGG的优势是什么呢?
- VGG提出了可以通过重复使用简单的基础块来构建深度模型的思路。
- VGG还指出了卷积神经网络的深度增加和小卷积核的使用对网络的最终分类识别效果有很大的作用。
(二)VGG网络结构特点
- 多个卷积层与非线性的激活层交替的结构,比单一卷积层的结构更能提取出深层的更好的特征。
- VGG使用的是3×3的小卷积,我们知道在之前的网络用的一般是大卷积,如AlexNet里面使用的11×11,5×5之类的卷积核尺寸。VGG证明了小卷积更多的好处,我们先看看小卷积和大卷积的区别:
3×3的小卷积为了与5×5的大卷积有相同大小的输出和感受野,所以2个3×3的卷积才能代替1个5×5的卷积,怎么理解呢?
假设图像大小为n×n,5×5卷积核输出图像大小为(n-5+1)/1=n-4
第一次3×3卷积核输出图像大小为(n-3+1)/1=n-2,第二次(n-2-3+1)/2=n-4
同理三个3×3的卷积才能代替一个7×7的卷积,以此类推。 但是在相同的输出和感受野下,3×3的小卷积有更多的好处:
1 . 网络层数增加,非线性激活函数变多,增加了非线性表达能力,使得分割平面更具有可分性
2 . 参数变少,两个3×3和一个5×5的参数比例为3×3×2/(5×5)=0.72,同样三个3×3×3/(7×7)=0.52,参数大大减少
3 . 能捕捉到各个方向的最小尺寸 - 关于最大池化层和全局池化层的选择:
在CNN中池化是为了降低特征的维度,同时提取更好的,具有强烈的语义信息的特征。比如在VGG中使用MaxPooling来对特征进行降维,同时提取出特征中响应最大,最强烈的部分来输入下一阶段的模块。
但是当特征中的信息都具有一定贡献的时候使用AvgPooling,比如网络走到较深的地方,这时候特征图中的H,W都比较小,包含的语义信息较多,这个时候再使用MaxPooling就不太合适了。比如ResNet在输入全连接层之前使用kernel
size=7的AvgPooling来降维。
(三)VGG的简单实现
(1)VGG块
定义vgg_block()函数,通过制定卷积核个数num_convs和输出通道数num_channels来实现上述VGG块。
import d2lzh as d2l
from mxnet import gluon, init, nd
from mxnet.gluon import nn
def vgg_block(num_convs, num_channels):
blk = nn.Sequential()
for _ in range(num_convs): # 根据卷积核个数循环增加ConvD卷积层
blk.add(nn.Conv2D(num_channels, kernel_size=3,
padding=1, activation='relu'))
# 卷积时采用填充保证卷积后空间分辨率不变
blk.add(nn.MaxPool2D(pool_size=2, strides=2)) # 在卷积层后接上最大池化层
return blk
(2)VGG网络
卷积层模块串联多个vgg_block块,超参数由变量conv_arch定义。该变量指定了每个VGG块里卷积层个数和输出通道数。
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
# 构造五个卷积块,前两块使用单卷积层,后三块使用双卷积层。
def vgg(conv_arch):
net = nn.Sequential()
for (num_convs, num_channels) in conv_arch:
net.add(vgg_block(num_convs, num_channels))
# 卷积层部分
net.add(nn.Dense(4096, activation='relu'), nn.Dropout(0.5),
nn.Dense(4096, activation='relu'), nn.Dropout(0.5),
nn.Dense(10))
# 全连接层
return net
net = vgg(conv_arch)
net.initialize()
X = nd.random.uniform(shape=(1, 1, 224, 224)) # 构造一个高和宽均为224的单通道数据样本
for blk in net:
X = blk(X)
print(blk.name, 'output shape:\t', X.shape) # 观察每一层的输出
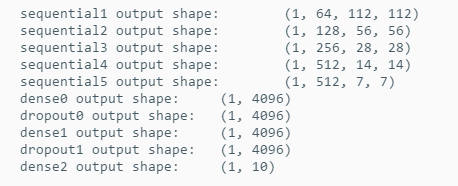
可以看到,每次我们将输入的高和宽减半,直到最终高和宽变成7后传入全连接层。与此同时,输出通道数每次翻倍,直到变成512。所以网络从原始输入为1×224×244经过一系列的卷积核和5次池化后,输入全连接时的特征图大小为512×7×7,然后第一个全连接层神经单元个数为4096,所以这一层的参数W的大小即(7×7×512×4096)。将全连接层化成卷积的意思来看,可以将W看作是4096个7×7×512的卷积核,卷积后特征图就变成了4096×1×1,同理,第二个全连接层的权重也可以看作是4096个1×1×4096的卷积核。
(3)获取数据和训练模型
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
# 出于测试的目的我们构造一个通道数更小,或者说更窄的网络
# 采用双斜杠(地板除法),向下取整
net = vgg(small_conv_arch)
lr, num_epochs, batch_size, ctx = 0.05, 5, 128, d2l.try_gpu()
net.initialize(ctx=ctx, init=init.Xavier())
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx,
num_epochs)















 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









