







研究背景
当前最常用的方法通过两步法进行点云配准:1、先为点云中的每个点提取局部特征描述子,建立初始的匹配对;2、通过稳健的模型估计算法,滤除错误的匹配对,寻找正确匹配(内点)并估计刚体变换。本研究主要关注如何在粗匹配中含有大量错误匹配的情况下进行点云配准。
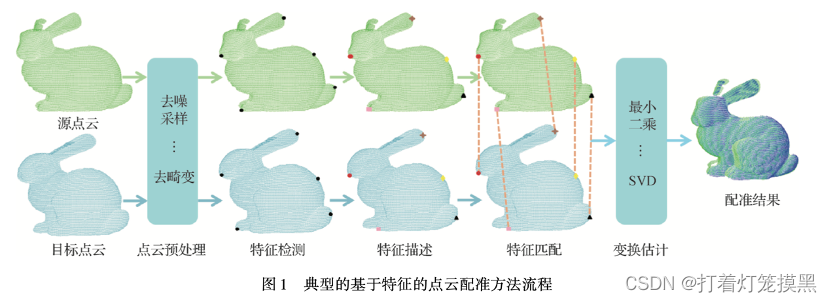
事实上,通过几何特征匹配得到的对应关系并不总是可靠的。造成这种情况的原因主要有 3 个: 1) 噪声和异常点。噪声和异常点会降低特征的辨识度。2) 部分重叠问题。位于重叠区域之外的点显然没有对应点与之匹配。 3) 局部点云不显著问题。某些点云局部区域非常“平坦”,显著性较低,容易导致特征的误匹配。通常,特征匹配后得到的点对包含较多离群值,很难用于直接求解刚性变换,因此需要对其进行去除。这一步称为点对离群值去除( outliers removal),是点云配准最关键的任务之一。
先前工作
RANSAC
思想:对于所有匹配的到的对应关系,不知道哪些对应关系计算变化矩阵得到的效果最好,因此我们通过随机采样一些对应关系来计算变换矩阵,然后从中选择出最好的变换矩阵作为最好的结果。
局限性:它需要大量的采样来保证算法的收敛,并且在内点率过低的情况下并不能保证一定能找到正确解。
兼容性特征(compatibility feature,CF)
思想:它利用刚体变换的一个性质:空间中任意两个点经过刚体变换之后长度不变。因此,正确匹配的点应该满足兼容性,即如果两组点对(a1,a1’,a2,a2’)都是正确匹配的,那么a1与a2的距离 和 a1’和a2’的距离应该相等。
因此通过点对的长度与角度进行兼容性检查, 得到点对的兼容性分数。 然后,聚合兼容性打分最高的点的信息,得到兼容性特征。 最后,将提取的兼容性特征输入到一个 MLPs中,进行密集的二分类, 将点对区分为内点(inlier)和离群点(outlier)。
局限性:将距离作为评判标准,外点和内点之间可能会存在着很高的相似性,这就是一阶兼容性的模糊性问题。
PointDSC
思想:由于长度一致性在很多场景下的辨别能力不够强,离群点较多时特征分析可能会失效。因此提出空间一致性的非局部特征提取方法SCnonlocal,同时利用MLP输出的置信度选择种子点,对于每个种子点在特征空间进行K近邻查找以提取满足空间一致性的点对集合,对每个点对集合利用neural spectral matching估计RT矩阵。最后从若干RT矩阵中中选择最优的一组。
方法
问题描述
对于给定的两个点云集合X和Y,首先提取出他们的局部特征。然后对于原始点云中每个点,通过在特征空间中进行最近邻搜寻找到目标点云中对应的点,然后推定出N对对应关系。所提出的方法是要找出转换关系R和T。
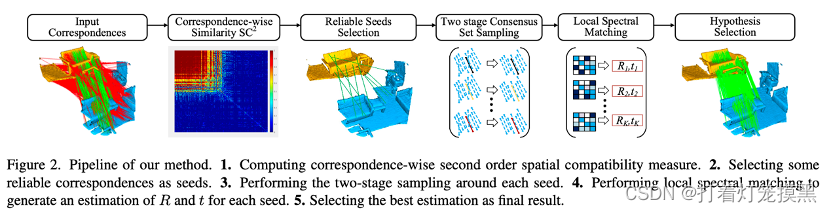
二阶空间兼容性
为了方便衡量度量方法的有效性,首次提出模糊时间的概率计算方式如下:
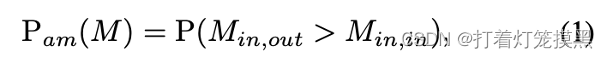
M
M
M代表着一种度量方式,
M
(
i
n
,
o
u
t
)
M_{(in,out)}
M(in,out)代表的是内点和外点的相似性,
M
(
i
n
,
i
n
)
M_{(in,in)}
M(in,in)代表内点之间的相似性。当
M
(
i
n
,
o
u
t
)
M_{(in,out)}
M(in,out)>
M
(
i
n
,
i
n
)
M_{(in,in)}
M(in,in),则说明在这种度量方式下,外点跟内点的相似度很高,这种基于采样的测量方式就不太合适。因此得到的概率值越小,这种度量方式就会越稳定。
对于一阶兼容性度量
S
C
SC
SC,它通常定义如下:
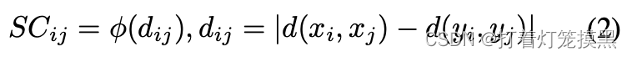
两个内点
d
i
j
d_{ij}
dij之间的距离差理论上为0,但是实际上由于噪声等的影响,两个内点的距离差一般会大于0但是小于一个阈值
d
t
h
r
d_{thr}
dthr,我们假设
d
(
i
n
,
i
n
)
d_{(in,in)}
d(in,in)在0到
d
t
h
r
d_{thr}
dthr之间均匀分布,那么概率密度函数为:
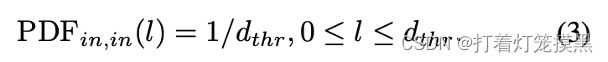
但是两个外点或者内点和外点之间是没有关系限制的,对于两个没有关联的点的距离差,认为是同分布的记为F(.):

d
t
h
r
d_{thr}
dthr是
d
(
i
n
,
o
u
t
)
d_{(in,out)}
d(in,out)和
d
(
o
u
t
,
o
u
t
)
d_{(out,out)}
d(out,out)的最大变化范围。
显然
d
r
d_r
dr远远大于
d
t
h
r
d_{thr}
dthr,因此我们可以近似F(.)在0到
d
t
h
r
d_{thr}
dthr区间是近似不变的,假设值为
f
0
f_0
f0。
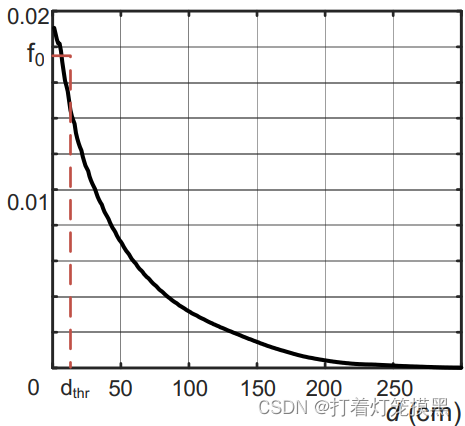
对于一阶兼容性度量
S
C
SC
SC,发生模糊事件的概率,利用二重积分计算:

以3DMatch数据集为例。近似为10cm,那么一阶兼容性的模糊性概率约为0.1。考虑到外点的数量一般十分庞大,这样的模糊概率在采样时不能被忽略。
对于所提出的二阶兼容性度量方式
S
C
2
{SC}^2
SC2,具体计算方式如下:
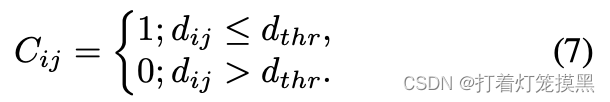
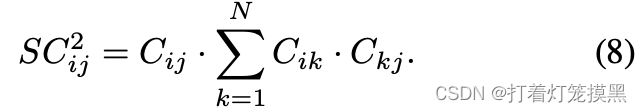
模糊事件发生的概率定义为:
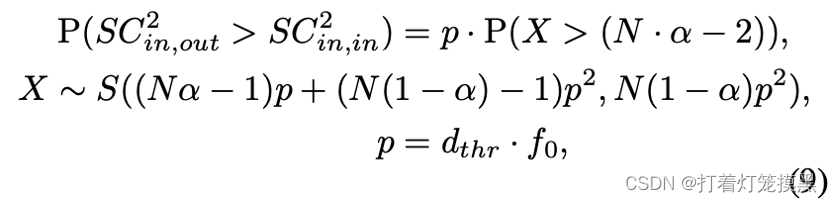
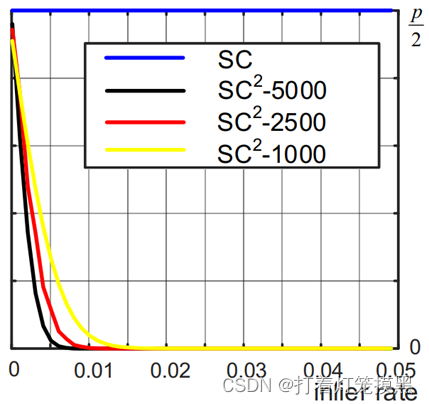
其中α为内点率,N为匹配对个数。S(.)为概率学中的Skellam分布。分别做出一阶和二阶度量的模糊性概率图:
种子点选取
利用Spectral matching(SM)算法进行种子点的选取。首先构建相似性矩阵,然后将矩阵的值归一化到0-1之间,利用power iteration algorithm得到特征向量,特征向量对应着对应关系的置信度。为了保证种子点的均匀分布,选择半径为R的局部最大置信度的点作为种子点。种子点个数Ns根据对应关系的个数,按照一定比例选定。
两阶段一致性采样
我们采用一个两阶段选择策略实现由粗到细的采样。在第一阶段,根据 S C 2 {SC}^2 SC2度量矩阵中对每个种子选择top-K1近邻,由于利用 S C 2 {SC}^2 SC2度量方法得到的模糊性事件概率很低,因此当种子是内点时,她的一致性集合里面也都是内点。作者认为通过 S C 2 {SC}^2 SC2度量,能更好关注全局信息而不是局部信息,同时利用 S C 2 {SC}^2 SC2度量选择的近邻在实际点云中分布的更加均匀而不是簇拥在一起。
第二个阶段进一步剔除第一步中可能存在的误匹配。我们重新再每个小集合中构建 S C 2 {SC}^2 SC2度量,然后选择每个种子点的Top-K2(K2<K1)近邻作为新的一致性集合。
注意到种子如果是外点,他也会形成局部的一致性集合,但是为了避免前期过于严格的种子筛选会漏掉一些内点,因此选择在后面处理这种情况。
模型的生成和选择
在这一步,对于每个种子的一致性集合,利用加权SVD得到刚性变化估计。传统的SM算法通过SC矩阵为每个对应关系分配权值,这里由于
S
C
2
{SC}^2
SC2对模糊事件更鲁棒,但是
S
C
2
{SC}^2
SC2不适合计算矩阵,因此改进如下:
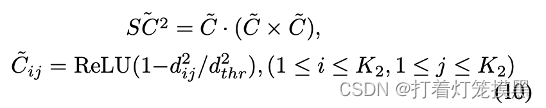
然后对其进行局部光谱分解得到权重
w
i
w_i
wi。
最好的RT选择
对于每个估计出来的变换,我们使用和RANSAC同样的内点计数准则来评价模型的质量:
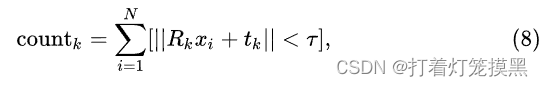
其中[]是艾弗森括号。最后选择得分最高的模型作为最终的刚体变换结果。
结论
本论文的核心是提出了 S C 2 {SC}^2 SC2度量方式,并且基于它进行点云配准。首先利用非极大值压缩的全局谱分解找到可靠的对应关系,将其作为种子。然后进行两阶段采样,将种子延展为一致性集合,然后利用局部谱匹配得到每个集合的刚体变换,最后找到最好的一种变换方式。














 4060
4060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









