







1 概述
torch.optim.lr_scheduler模块提供了一些根据epoch训练次数来调整学习率(learning rate)的方法。一般情况下我们会设置随着epoch的增大而逐渐减小学习率从而达到更好的训练效果。
2 lr_scheduler调整策略举例
2.1 torch.optim.lr_scheduler.LambdaLR
torch.optim.lr_scheduler.LambdaLR(
optimizer,
lr_lambda,
last_epoch=-1)- optimizer (Optimizer):要更改学习率的优化器
- lr_lambda(function or list):根据epoch计算λ的函数
- last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
更新策略![]()
- new_lr是得到的新的学习率
- initial_lr是初始的学习率
- λ是通过参数lr_lambda和epoch得到的
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
import matplotlib.pyplot as plt
initial_lr = 0.1
net_1=nn.Sequential(
nn.Linear(1,10)
)
optimizer_1 = torch.optim.Adam(
net_1.parameters(),
lr = initial_lr)
scheduler_1 = LambdaLR(
optimizer_1,
lr_lambda=lambda epoch: 1/(epoch+1))
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
'''
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.050000
第3个epoch的学习率:0.033333
第4个epoch的学习率:0.025000
第5个epoch的学习率:0.020000
第6个epoch的学习率:0.016667
第7个epoch的学习率:0.014286
第8个epoch的学习率:0.012500
第9个epoch的学习率:0.011111
第10个epoch的学习率:0.010000
'''
plt.plot(lst)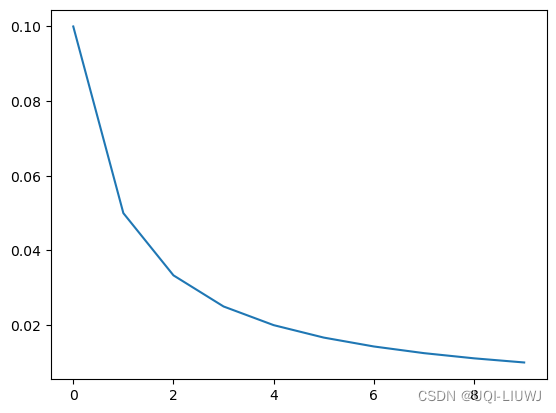
2.2 torch.optim.lr_scheduler.StepLR
torch.optim.lr_scheduler.StepLR(
optimizer,
step_size,
gamma=0.1,
last_epoch=-1)- optimizer (Optimizer):要更改学习率的优化器;
- step_size(int):每训练step_size个epoch,更新一次参数;
- gamma(float):更新lr的乘法因子;
- last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
更新策略:
每过step_size个epoch,更新一次
![]()
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import StepLR
initial_lr = 0.1
net_1=nn.Sequential(
nn.Linear(1,10)
)
optimizer_1 = torch.optim.Adam(
net_1.parameters(),
lr = initial_lr)
scheduler_1 = StepLR(
optimizer_1,
step_size=3,
gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
lst=[]
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
lst.append( optimizer_1.param_groups[0]['lr'])
scheduler_1.step()
'''
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.010000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.001000
第8个epoch的学习率:0.001000
第9个epoch的学习率:0.001000
第10个epoch的学习率:0.000100
'''
plt.plot(lst)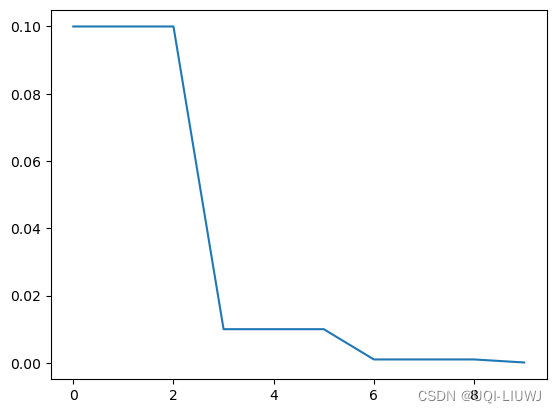
2.3 torch.optim.lr_scheduler.MultiStepLR
torch.optim.lr_scheduler.MultiStepLR(
optimizer,
milestones,
gamma=0.1,
last_epoch=-1)- optimizer (Optimizer):要更改学习率的优化器;
- milestones(list):递增的list,存放要更新lr的epoch;
- 在milestones里面的这几个点时相继乘以gamma系数
- gamma(float):更新lr的乘法因子;
- last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
更新策略:
每次遇到milestones中的epoch,做一次更新:
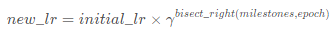
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import *
import matplotlib.pyplot as plt
lst=[]
initial_lr = 0.1
net_1=nn.Sequential(
nn.Linear(1,10)
)
optimizer_1 = torch.optim.Adam(
net_1.parameters(),
lr = initial_lr)
scheduler_1 = MultiStepLR(
optimizer_1,
milestones=[3,9],
gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
lst.append( optimizer_1.param_groups[0]['lr'])
scheduler_1.step()
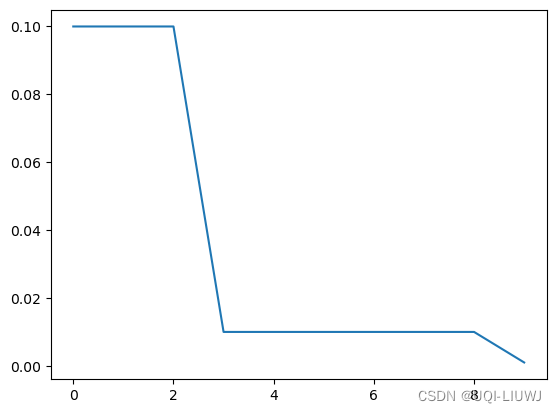
'''
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.010000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.010000
第8个epoch的学习率:0.010000
第9个epoch的学习率:0.010000
第10个epoch的学习率:0.001000
'''
plt.plot(lst)第三个和第九个epoch之后,学习率发生改变
2.4 torch.optim.lr_scheduler.ExponentialLR
torch.optim.lr_scheduler.ExponentialLR(
optimizer,
gamma,
last_epoch=-1)- optimizer (Optimizer):要更改学习率的优化器;
- gamma(float):更新lr的乘法因子;
- last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
更新策略:
每个epoch更新一次
![]()
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import *
import matplotlib.pyplot as plt
lst=[]
initial_lr = 0.1
net_1=nn.Sequential(
nn.Linear(1,10)
)
optimizer_1 = torch.optim.Adam(
net_1.parameters(),
lr = initial_lr)
scheduler_1 =ExponentialLR(
optimizer_1,
gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
lst.append( optimizer_1.param_groups[0]['lr'])
scheduler_1.step()
plt.plot(lst)
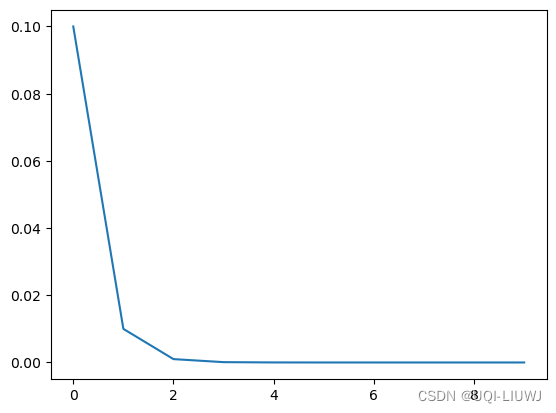
'''
初始化的学习率: 0.1
第1个epoch的学习率:0.100000000
第2个epoch的学习率:0.010000000
第3个epoch的学习率:0.001000000
第4个epoch的学习率:0.000100000
第5个epoch的学习率:0.000010000
第6个epoch的学习率:0.000001000
第7个epoch的学习率:0.000000100
第8个epoch的学习率:0.000000010
第9个epoch的学习率:0.000000001
第10个epoch的学习率:0.000000000
'''
2.5 torch.optim.lr_scheduler.CosineAnnealingLR
采用周期变化的策略调整学习率,能够使模型跳出在训练过程中遇到的局部最低点和鞍点
torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max,
eta_min=0,
last_epoch=-1)- optimizer (Optimizer):要更改学习率的优化器;
- T_max(int):lr的变化是周期性的,T_max是周期的1/2
- eta_min(float):lr的最小值,默认为0;
- last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
更新策略:

这时候learning rate的取值范围是[eta_min,initial_lr]
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import CosineAnnealingLR
import matplotlib.pyplot as plt
initial_lr = 0.1
net_1=nn.Sequential(
nn.Linear(1,10)
)
optimizer_1 = torch.optim.Adam(
net_1.parameters(),
lr = initial_lr)
scheduler_1 = CosineAnnealingLR(
optimizer_1,
T_max=20)
print("初始化的学习率:", optimizer_1.defaults['lr'])
lst=[]
for epoch in range(1, 101):
# train
optimizer_1.zero_grad()
optimizer_1.step()
lst.append(optimizer_1.param_groups[0]['lr'])
#print("第%d个epoch的学习率:%.9f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
plt.plot(lst)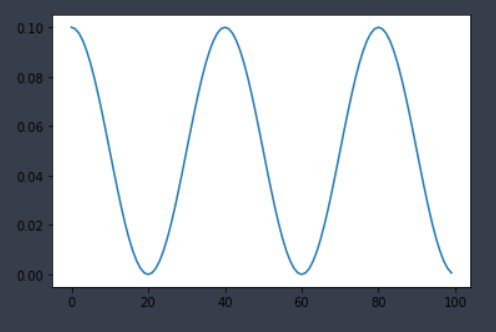
2.6 MultiplicativeLR
torch.optim.lr_scheduler.MultiplicativeLR(optimizer,
lr_lambda,
last_epoch=-1,
verbose=False,) 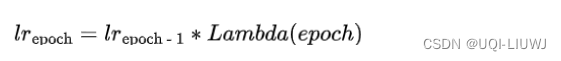
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import MultiplicativeLR
initial_lr = 0.1
net_1=nn.Sequential(
nn.Linear(1,10)
)
optimizer_1 = torch.optim.Adam(
net_1.parameters(),
lr = initial_lr)
scheduler_1 = MultiplicativeLR(
optimizer_1,
lr_lambda=lambda epoch: 1/(epoch+1))
print("初始化的学习率:", optimizer_1.defaults['lr'])
lst=[]
for epoch in range(1, 11):
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
lst.append( optimizer_1.param_groups[0]['lr'])
scheduler_1.step()
'''
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.050000
第3个epoch的学习率:0.016667
第4个epoch的学习率:0.004167
第5个epoch的学习率:0.000833
第6个epoch的学习率:0.000139
第7个epoch的学习率:0.000020
第8个epoch的学习率:0.000002
第9个epoch的学习率:0.000000
第10个epoch的学习率:0.000000
'''
plt.plot(lst)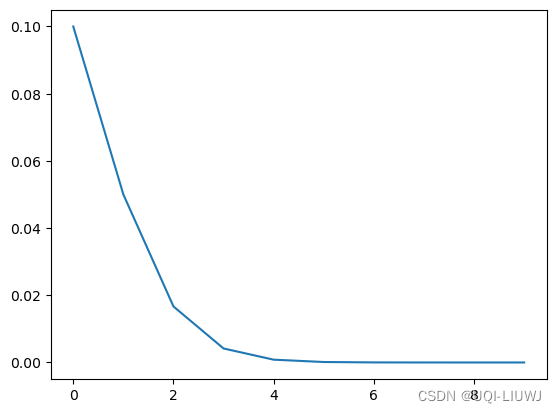
2.7 CyclicLR
学习率周期性变化。
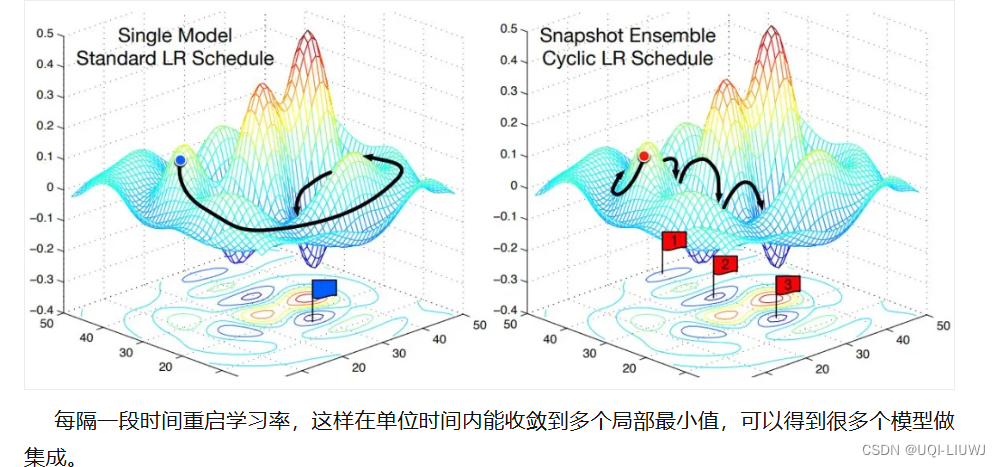
| base_lr | 循环中学习率的下边界 |
| max_lr | 循环中学习率的上边界 |
| step_size_up | 学习率上升的步数 |
| step_size_down | 学习率下降的步数 |
| mode | {triangular, triangular2, exp_range}中的一个。默认: 'triangular' |
gamma (float) | 在mode='exp_range'时,gamma**(cycle iterations), 默认:1.0 |
2.7.1 triangular
最基本的模式,学习率会在base_lr(最小学习率)和max_lr(最大学习率)之间周期性地进行线性往返变化
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import *
import matplotlib.pyplot as plt
initial_lr = 0.1
net_1=nn.Sequential(
nn.Linear(1,10)
)
optimizer_1 = torch.optim.SGD(
net_1.parameters(),
lr = initial_lr)
scheduler_1 =CyclicLR(
optimizer_1,
base_lr=0.1,
max_lr=10,
step_size_up=10,
step_size_down=5,
mode='triangular')
lst=[]
for epoch in range(1, 101):
# train
optimizer_1.zero_grad()
optimizer_1.step()
lst.append( optimizer_1.param_groups[0]['lr'])
scheduler_1.step()
plt.plot(lst)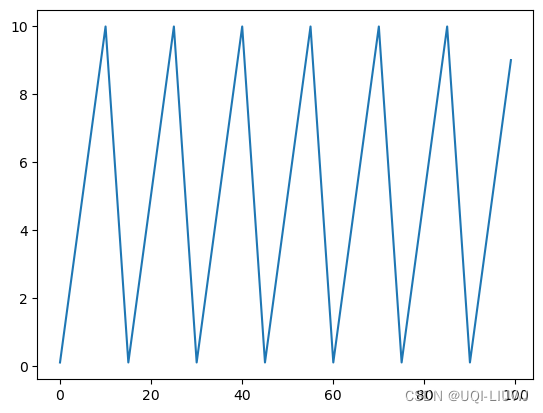
2.7.2 triangular2
每个循环的最大学习率会比前一个循环的最大学习率低一半,从而使学习率的变化范围随着时间的推移而收缩
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import *
import matplotlib.pyplot as plt
initial_lr = 0.1
net_1=nn.Sequential(
nn.Linear(1,10)
)
optimizer_1 = torch.optim.SGD(
net_1.parameters(),
lr = initial_lr)
scheduler_1 =CyclicLR(
optimizer_1,
base_lr=0.1,
max_lr=10,
step_size_up=10,
step_size_down=5,
mode='triangular2')
lst=[]
for epoch in range(1, 101):
# train
optimizer_1.zero_grad()
optimizer_1.step()
lst.append( optimizer_1.param_groups[0]['lr'])
scheduler_1.step()
plt.plot(lst)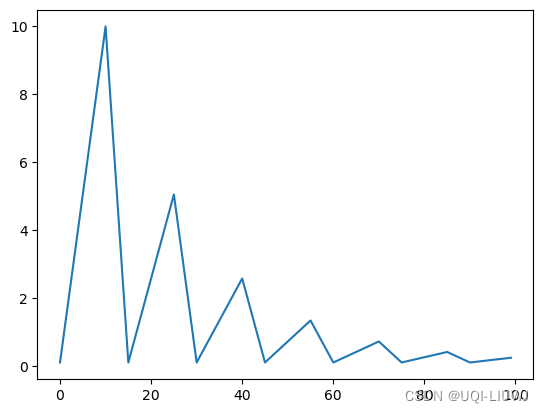
2.7.3 exp_range
学习率随着时间的推移而减小,最大学习率会根据gamma参数指数减少
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import *
import matplotlib.pyplot as plt
initial_lr = 0.1
net_1=nn.Sequential(
nn.Linear(1,10)
)
optimizer_1 = torch.optim.SGD(
net_1.parameters(),
lr = initial_lr)
scheduler_1 =CyclicLR(
optimizer_1,
base_lr=0.1,
max_lr=10,
step_size_up=10,
step_size_down=5,
mode='exp_range',
gamma=0.9)
lst=[]
for epoch in range(1, 101):
# train
optimizer_1.zero_grad()
optimizer_1.step()
lst.append( optimizer_1.param_groups[0]['lr'])
scheduler_1.step()
plt.plot(lst) 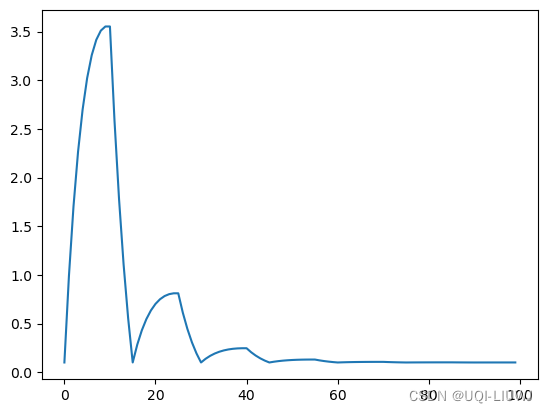
2.8 CosineAnnealingWarmRestarts
使用余弦退火计划设置每个参数组的学习速率,并在 Ti epoch 后重启

| T_0 | 第一次restart时epoch的数值 |
| T_mult | 每次restart后,学习率restart周期增加因子 |
| eta_min | 最小的学习率,默认值为0 |
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import *
import matplotlib.pyplot as plt
initial_lr = 0.1
net_1=nn.Sequential(
nn.Linear(1,10)
)
optimizer_1 = torch.optim.SGD(
net_1.parameters(),
lr = initial_lr)
scheduler_1 =CosineAnnealingWarmRestarts(
optimizer_1,
T_0=10,
T_mult=2,
eta_min=1)
lst=[]
for epoch in range(1, 101):
# train
optimizer_1.zero_grad()
optimizer_1.step()
lst.append( optimizer_1.param_groups[0]['lr'])
scheduler_1.step()
plt.plot(lst) 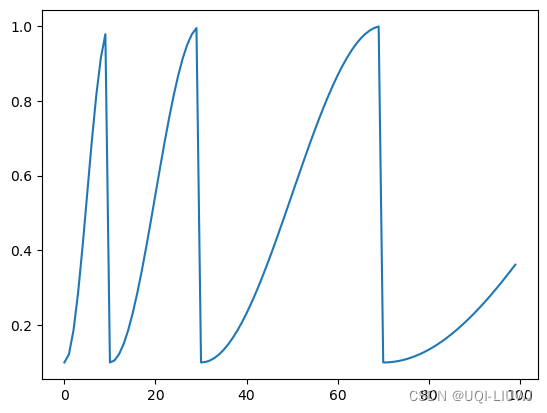
2.9 optim.lr_scheduler.ReduceLROnPlateau
- 根据训练过程中的一些度量(通常是验证集上的损失)来动态地调整学习率
- 监视一个指标(例如验证损失),如果在一定数量的 epoch(由
patience参数定义)中该指标没有改善,那么将学习率乘以一个事先定义的因子(由factor参数定义,通常小于 1),即降低学习率
2.9.1 主要参数
| optimizer | 被封装的优化器 |
| mode |
如果设置为 如果设置为 |
| factor | 学习率降低的因子,新的学习率将是原学习率乘以这个因子。通常设为 0.1 |
| patience | 在学习率下降之前,等待指标改善的 epoch 数 例如,如果设置为 10,那么如果监测的指标在 10 个 epoch 内没有改善,学习率将会降低 |
| threshold | 用于衡量新的最佳值的阈值,仅在 这个阈值定义了什么程度的变化被认为是真正的改善 |
| cooldown | 减少学习率后增加等待几个 epoch 的“冷却时间”,在此期间调度器不会执行任何动作。 |
| min_lr | 学习率下限 |
| eps | 学习率衰减的最小值,如果新旧学习率之间的差异小于 eps,更新将不会执行。 |
import torch
import torch.optim as optim
from torch.optim.lr_scheduler import ReduceLROnPlateau
model = ... # Your model
optimizer = optim.Adam(model.parameters(), lr=0.01)
scheduler = ReduceLROnPlateau(optimizer, 'min', factor=0.1, patience=10)
for epoch in range(num_epochs):
train(...)
val_loss = validate(...)
# Step with validation loss
scheduler.step(val_loss)
参考文献:torch.optim.lr_scheduler:调整学习率_qyhaill的博客-CSDN博客_lr_scheduler


















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











