







个人感觉,可微DTW的主要优点作为一个损失函数,可以进行梯度反向传播,如果目标只是两个时间序列的相似度,可能不太需要?
1 Intro
1.1 背景
DTW 笔记: Dynamic Time Warping 动态时间规整 (&DTW的python实现) 【DDTW,WDTW】_UQI-LIUWJ的博客-CSDN博客

- 近年来,可微DTW被广泛地研究
- Soft-DTW使用技巧替代min ,使之可微
-
Learning Discriminative Prototypes with Dynamic Time Warping (CVPR 2021)观察到在固定warping路径后可以进行微分
1.2 本文思路
- 论文提出一种基于深度隐式层的新型可微DTW方法,名为DecDTW
- 采用之前论文提出的DTW问题的连续时间公式(GDTW),作为一个受不等式约束的非线性规划(non-linear program,NLP)
- 使用深度声明式网络(DDN)框架来定义DTW层的前向和后向传播
- 前向传播涉及求解最优(连续时间)规整路径
- 类似于原始DTW算法的自定义动态规划方法
- 后向传播通过在前向传播中计算的解来导出梯度,使用隐式微分
- 前向传播涉及求解最优(连续时间)规整路径
- ——>DecDTW在端到端学习设置中更有效、更高效地利用对齐路径信息
2 论文模型
2.1 Preliminary
2.1.1 时间变化信号
是一个随时间变化的矢量值函数
- 这里的[0,1]是 左闭右闭的区间
- 这个函数表示[0,1]的任意时刻,都是d维的观测信号
- 信号通常假设是可微的(至少是分段平滑的)
- 用一组观测时间
观测这个时变信号,得到相应的观察
- 【这个就是我们常见的时间序列】,只不过论文将时间序列的时间缩放到[0,1]
2.1.2 时间变形函数
- 一个时间变形函数
定义了一个信号中的时间到另一个信号中的时间的对应关系
- 变形函数通常带有约束条件
- 变形函数是非递减的
记为x的时间变形版本
2.1.3 GDTW(广义动态时间规整)

- GDTW问题可以如下形式化
- 给定两个时变信号x和y,找到一个变形函数ϕ,使得y ◦ ϕ ≈ x。
- 换句话说,希望通过扭曲y中的时间来使信号x和y接近。
- 在实验中发现,对于实际对齐任务,GDTW通常优于传统DTW。
- 论文将这归因于前者能够在任意观察之间进行对齐,从而实现更准确的对齐。
2.2 GDTW 优化方程
- GDTW 可以被明确地定义为一个受约束的优化问题,其中决策变量是时间变形函数Φ,输入参数是信号 x 和 y。

- 目标函数 f 可以分解为与特征误差有关的信号损失 L 和变形正则项 R
- 其中λ≥0 是一个超参数,用于控制正则化的强度。
- 此外,通常会对 ϕ 施加一些可能随时间变化的约束条件
- 论文将这些约束条件分为局部约束和全局约束
- 局部约束限制了变形函数的时间导数
- 随着时间的推移,变形函数的值不能减少,只能保持不变或者增加
- 全局约束限制了变形函数的值
- 局部约束限制了变形函数的时间导数
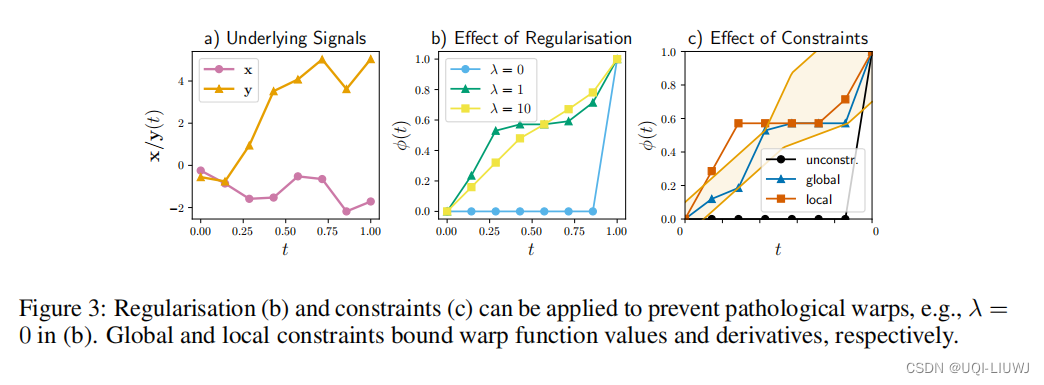
图 3 说明了如何使用约束来改变 GDTW 返回的结果变形。
2.2.1 损失函数L

-
是一个两次可微的惩罚函数。
- 论文使用
- 其他的惩罚函数(例如,1-范数,Huber 损失)也可以使用。
- Huber loss:
- Huber loss:
- 论文使用
- L量化了两个时间序列在进行时间变形后的相似度或差异度
- 通过最小化这个信号损失,能够找到一个更为准确地将两个时间序列对齐的时间变形函数
- 这在一系列的实际应用中是非常有用的,例如语音识别、动作捕捉等


2.2.2 Warp 正则化

- R:R→R 是一个关于从单位弯曲(ϕ′(t)=1)偏离的惩罚函数。
- 论文使用二次惩罚
。
- 论文使用二次惩罚
- 这个正则化项惩罚了具有大跳变的弯曲函数,一个足够高的 λ 会使 ϕ 接近单位函数。
- 正则化对于防止由GDTW(以及更一般地说,DTW)产生的嘈杂和/或病态弯曲至关重要,并且可能极大地影响对齐的准确性。
3 GDTW的简化 非线性规划
- 在这一节中,对ϕ提供了简化的假设。
- 将方程1中的无限维变分问题简化为有限维的非线性规划(NLP)问题。
- 这是通过首先假设ϕ是分段线性的来实现的
- 允许它完全由其在m个节点
上的值来定义。
- 节点可以均匀分布,或者只是y的观测时间
- 形式上,分段线性性允许我们将ϕ表示为
- 允许它完全由其在m个节点
- 这是通过首先假设ϕ是分段线性的来实现的
- 另一个简化方程1为非线性规划(NLP)的关键假设是用梯形法则给出的数值近似来替换信号损失和弯曲正则化中的连续积分。

4 DecDTW 前向传播
- DecDTW 层编码了一个隐函数
- 该函数根据输入信号x,y,正则化参数 λ 和约束
,
输出最优的弯曲路径
。
- 该弯曲路径
- 预测弯曲
间的误差
- 预测弯曲
- 该函数根据输入信号x,y,正则化参数 λ 和约束
- DecDTW 的前向传播解决了由方程 4 给出的 GDTW 问题,给定输入参数。我们使用动态规划(DP)方法解决方程 4,而不是调用通用的 NLP 求解器
- ——>这样做是为了最小化计算时间
-
求解器的工作机制如下
-
对于每一个 i,我们可以将 ϕi 离散化为 M 个值
-
这些值在全局界限
之间均匀分布
-
——>构成一个有mM个点的图
-
时序相邻的节点
用边连接
-
总共
条边
-
每个节点的成本就是公式5的后一项
-
边成本就是
-
-
违反局部约束
的边被赋予 ∞ 的成本
-
-
——>新的离散优化问题的全局最小值对应于图中的最小成本路径,并使用动态规划在
的时间复杂度下解决
-
-
一次求解完之后,对离散化和解进行迭代细化


5 DecDTW 反向传播
-
前向传播中获得的=ϕ⋆ 相对于输入
的梯度
-
-
与现有的可微分 DTW 方法不同,DecDTW 允许正则化权重 λ 和约束hi成为深度网络中的可学习参数
-
记
,每一个hi表示公式4中的一个不等式
-
根据 Gould et al. (2021)有
-

-

6 实验
mingu6/declarativedtw: Reference implementation of DecDTW in PyTorch (ICLR 2023) (github.com)
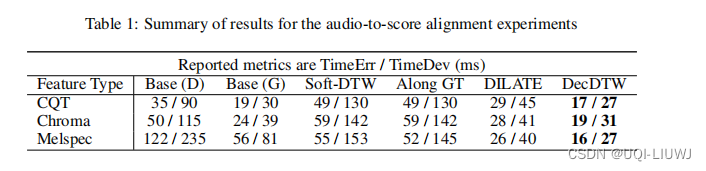
6.1 乐谱对齐
- 第一个实验涉及音频与乐谱的对齐,这是音乐信息检索中的一个基础问题,应用范围从乐谱跟随到音乐转录。
- 该任务的目标是将一段音乐表演的音频录音与其对应的乐谱/简谱进行对齐。
- 论文使用 Thickstun 等人(2020年)提出的数学形式化方法来评估预测的音频到乐谱的对齐与一个基准对齐,我们现在将对此进行总结。
时间平均误差(TimeErr)和时间标准偏差(TimeDev),具体地给出如下:


6.2 视觉位置识别

- 移动机器人和自动驾驶汽车导航系统的重要组成部分
















 5846
5846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











