







 本文介绍了如何在HuggingFace平台上部署Gemma模型,包括申请访问权限、添加个人HuggingFacetoken,并提供了在CPU和GPU上执行文本生成,以及使用chat格式进行对话的示例。
本文介绍了如何在HuggingFace平台上部署Gemma模型,包括申请访问权限、添加个人HuggingFacetoken,并提供了在CPU和GPU上执行文本生成,以及使用chat格式进行对话的示例。
1 部署
1.1 申请权限
在huggingface的gemma界面,点击“term”以申请gemma访问权限
https://huggingface.co/google/gemma-7b
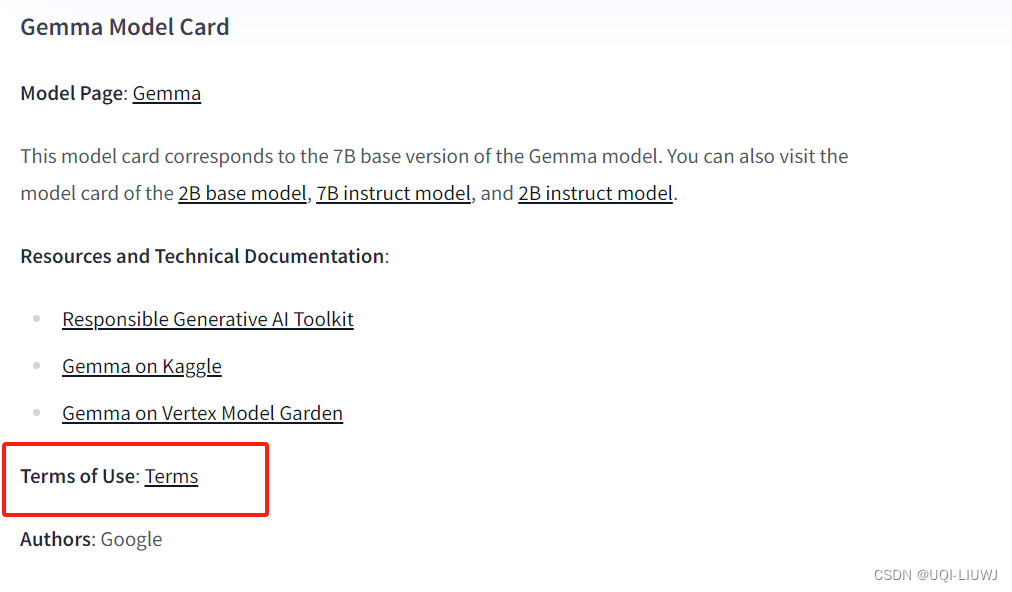
然后接受条款
1.2 添加hugging对应的token
如果直接用gemma提供的代码,会出现如下问题:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("google/gemma-7b")
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b")
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
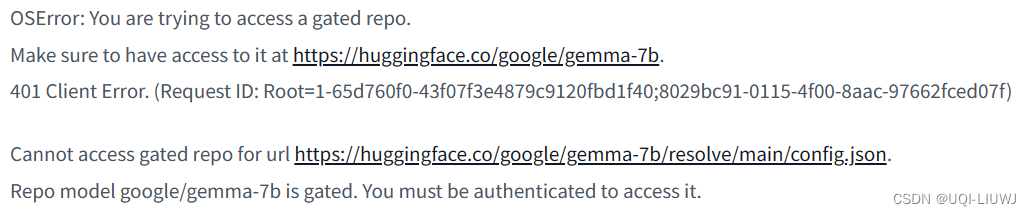
这时候就需要添加自己hugging的token了:
import os
os.environ["HF_TOKEN"] = '....'token的位置在:
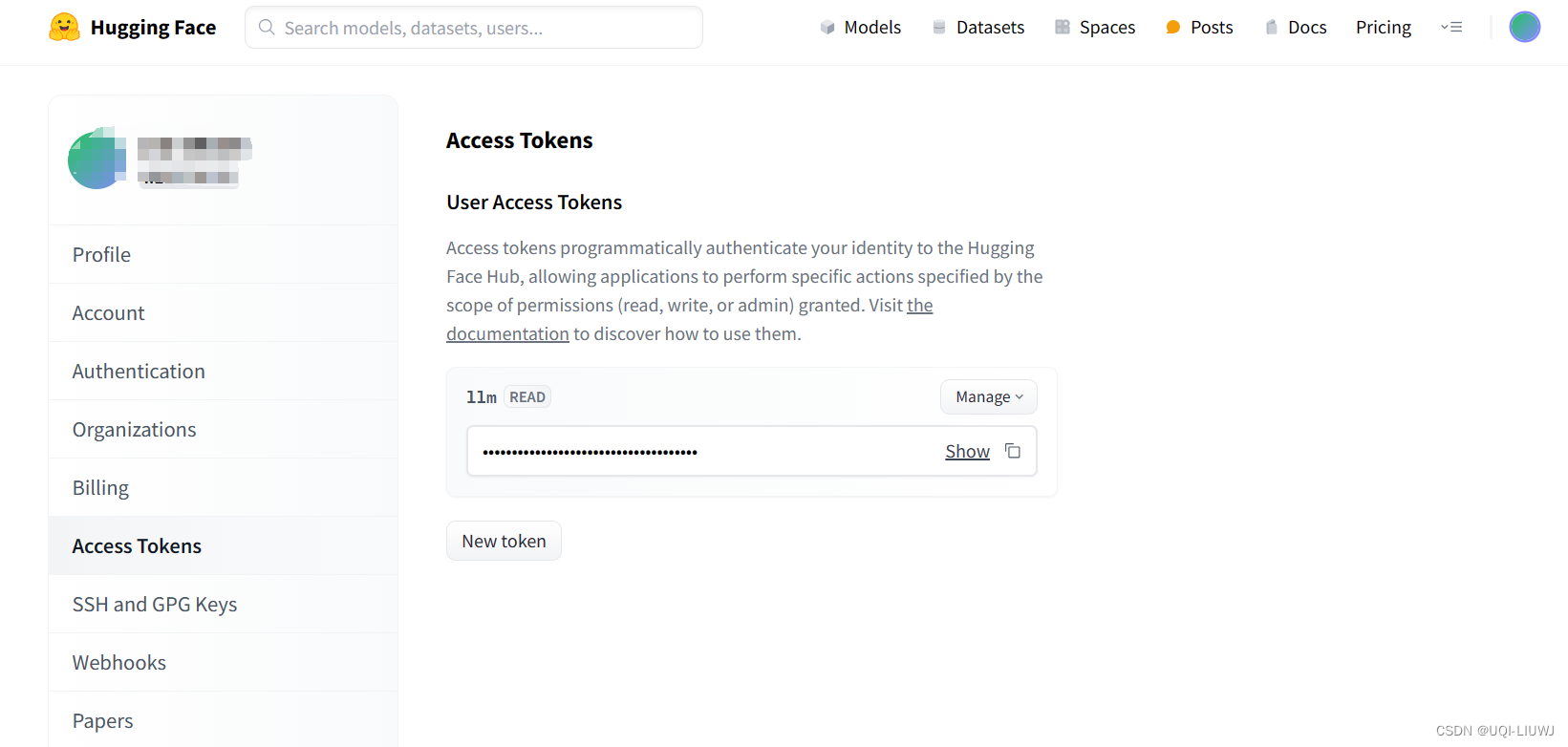
2 gemma 模型官方样例
2.0 gemma介绍
- Gemma是Google推出的一系列轻量级、最先进的开放模型,基于创建Gemini模型的相同研究和技术构建。
- 它们是文本到文本的、仅解码器的大型语言模型,提供英语版本,具有开放的权重、预训练的变体和指令调优的变体。
- Gemma模型非常适合执行各种文本生成任务,包括问答、摘要和推理。它们相对较小的尺寸使得可以在资源有限的环境中部署,例如笔记本电脑、桌面电脑或您自己的云基础设施,使每个人都能获得最先进的AI模型,促进创新。
2.1 文本生成
2.1.1 CPU上执行
from transformers import AutoTokenizer, AutoModelForCausalLM
'''
AutoTokenizer用于加载预训练的分词器
AutoModelForCausalLM则用于加载预训练的因果语言模型(Causal Language Model),这种模型通常用于文本生成任务
'''
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2b",token='。。。')
#加载gemma-2b的预训练分词器
model = AutoModelForCausalLM.from_pretrained("google/gemma-2b",token='。。。' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 578
578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











