







1 moe介绍
混合专家模型主要由两个关键部分组成
1.0 MOE的motivation
- 神经元的稀疏性
- 大型模型中80%的输入只激活少于3%的神经元
- 神经元的多义性
- 神经元不专注于一个单一的主题,而是专注于许多主题,而且这些主题在语义上并不相关
- ——>希望有一种技术可以拆分和消除这种多义性
- 计算资源的有限性
1.1 稀疏MoE 层
- 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层
- 通常只将这些子层的一部分(例如,每隔一层)转换为 MoE 层
- MoE 层包含若干“专家”,每个专家本身是一个独立的神经网络。
- 通常是参数更少的前馈网络 (FFN)
- 甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构
- 核心思想是,每个专家在训练过程中学习不同的信息。而在推理时,仅使用与当前任务最相关的特定专家
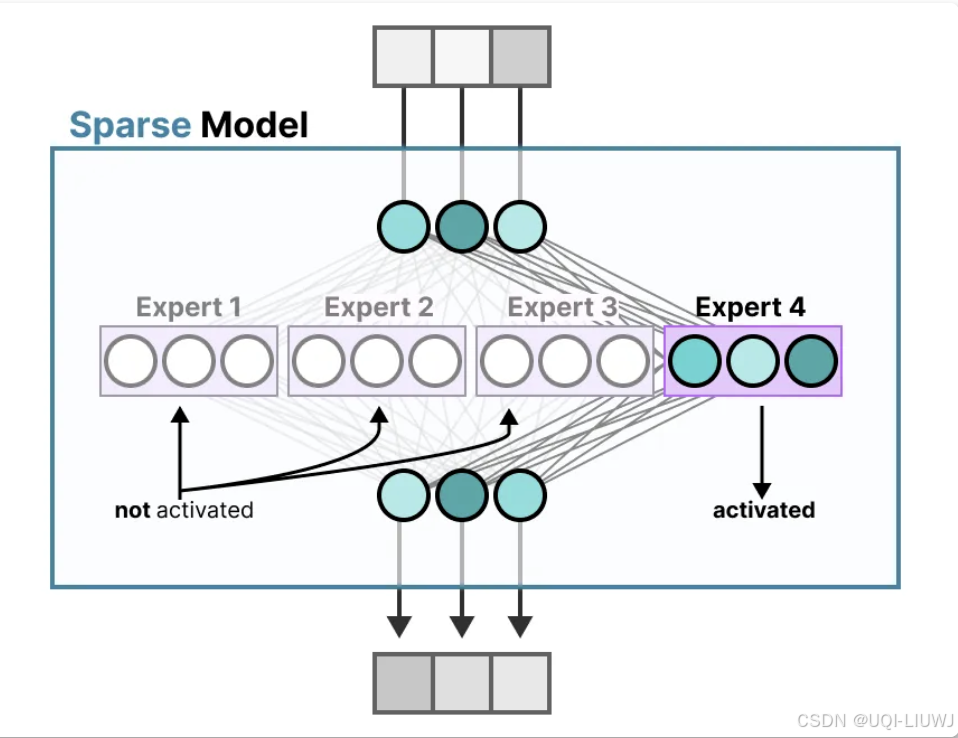
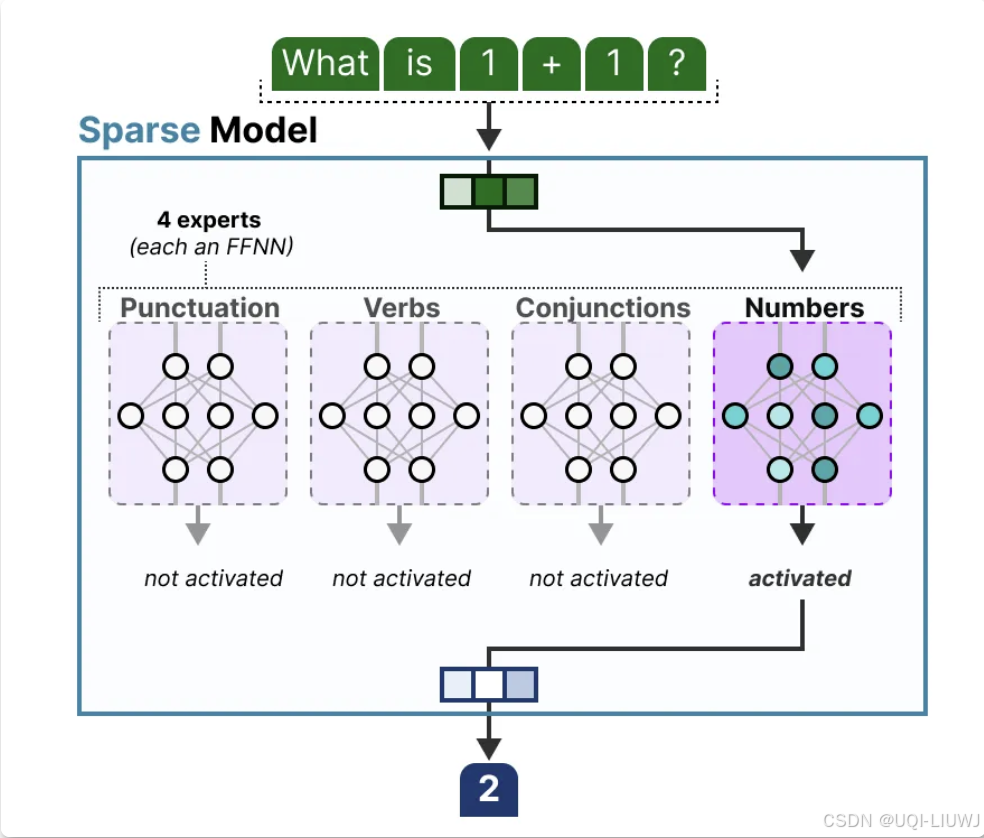
-
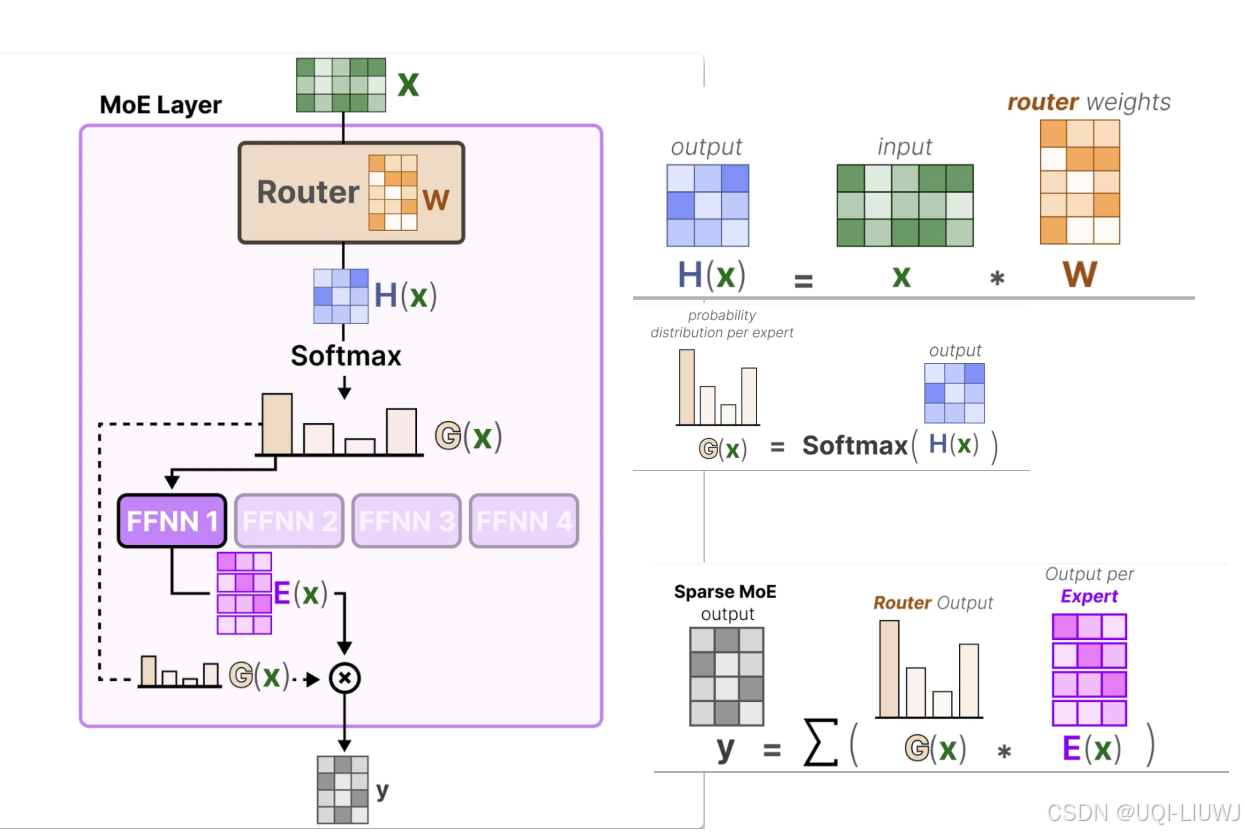
1.2 门控网络(路由)
- 用于决定哪些令牌 (token) 被发送到哪个专家

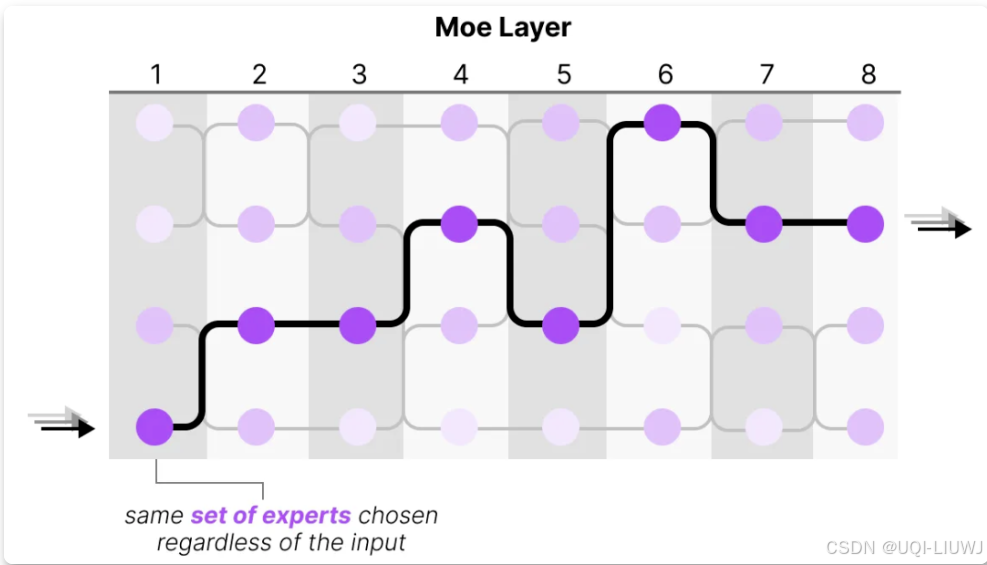
不同 tokens 被选中的专家可能各不相同,这导致了不同的“路径”被选择:
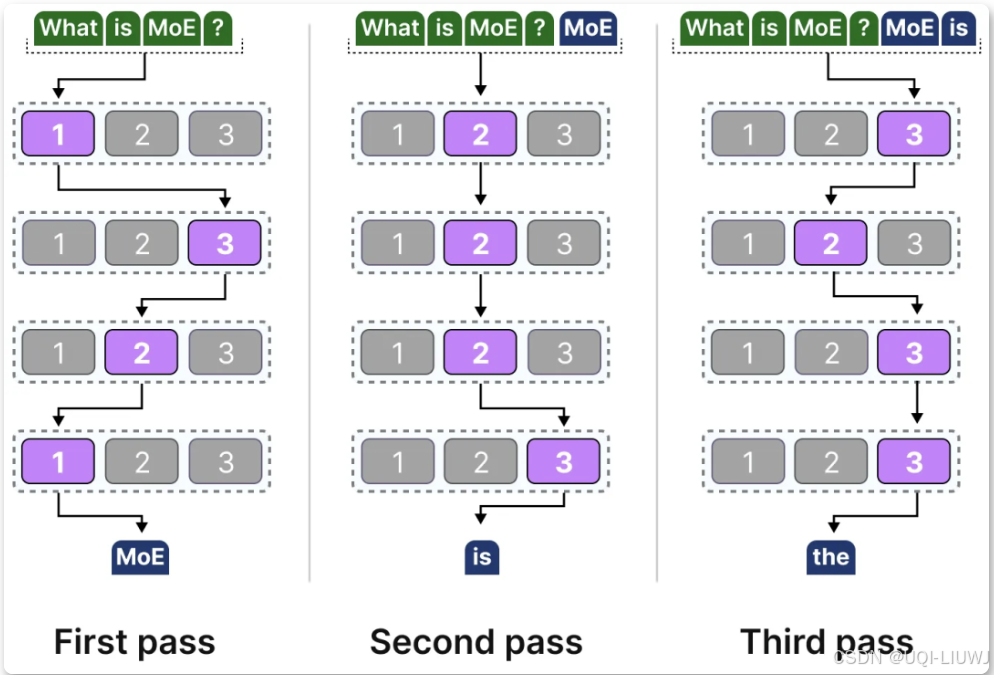
路由/门控网络:根据特定的输入选择专家。路由器会输出概率值,并利用这些概率来选择最匹配的专家
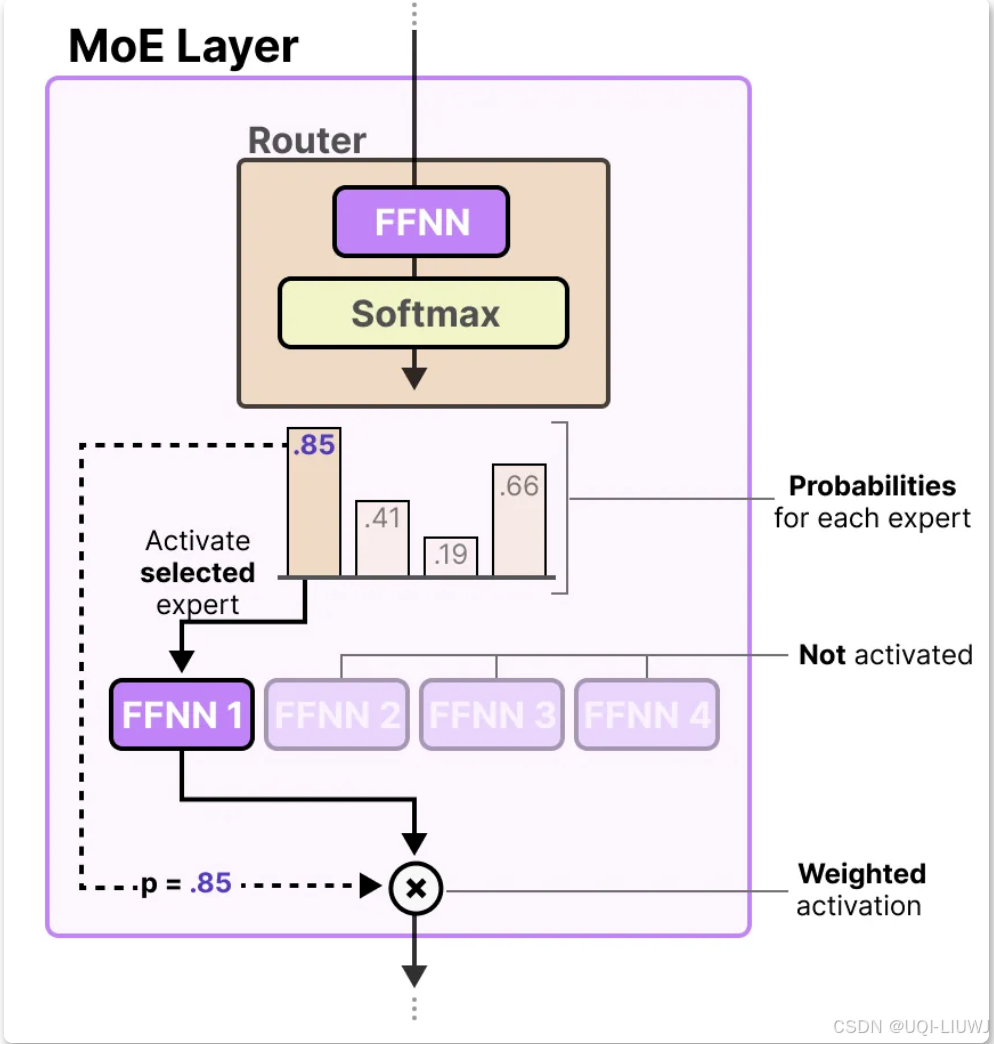
专家层返回被选定专家的输出,并乘以门控值(选择概率)
1.3 计算流程
- 根据输入 Token 生成专家的概率分布
- 选择排序靠前的 K 个专家进行 Token 处理
- 再将 K 个专家的结果加权汇总输出给下一层网络
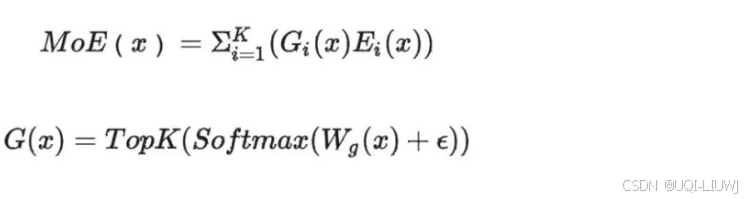
2 特点
2.1 优点
- 与稠密模型相比, 预训练速度更快
- 在相同的计算预算条件下,可以显著扩大数据集的规模
- 适用于处理大规模数据集
- 提高模型性能
- 通过将多个专家的预测结果进行整合,MoE模型可以在不同的数据子集或任务方面发挥每个专家的优势,从而提高整体模型的性能
- 例如,在图像分类任务中,一个专家可能擅长识别动物图片,而另一个专家可能擅长识别车辆图片
- 通过门控网络的合理分配,MoE模型可以更准确地对不同类型的图片进行分类。
- 与具有相同参数数量的模型相比,具有更快的 推理速度
- 推理阶段只使用moe的一部分,有些参数是用不上的
- 多任务学习能力(强)
- 在多任务学习中具备很好的性能
- 容错和鲁棒性增加
- 由于MOE架构将任务分散到多个专家中,即使其中一个或几个专家失败,整个系统通常仍能保持运行。
- 这种设计提高了模型的容错性和鲁棒性
2.2 挑战
- 在 微调方面存在诸多挑战
- 在微调阶段往往面临泛化能力不足的问题,长期以来易于引发过拟合现象
- ——>为了应对过拟合,需要更高的dropout率
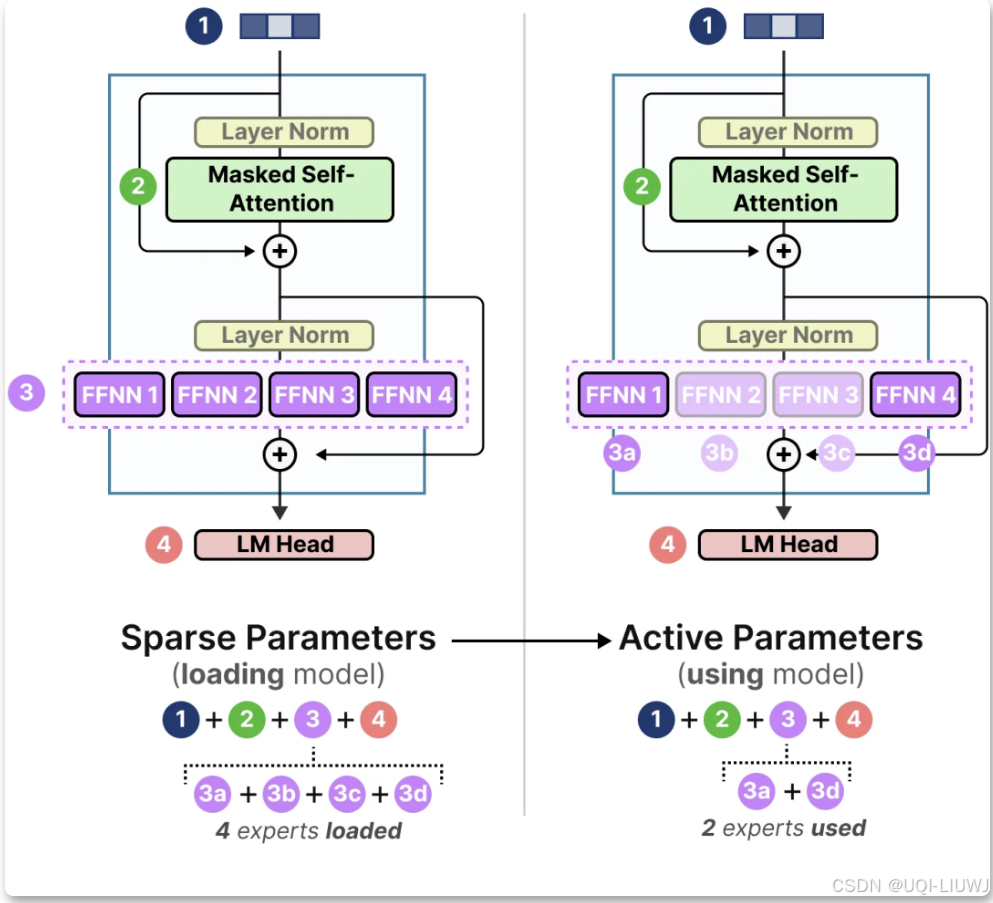
- 推理硬件要求方面
- 模型需要将所有参数加载到内存中(虽然推理只使用一部分)p,因此对内存的需求非常高
- 训练复杂度增每个专家网络都需要进行独立的训练,并且还需要训练门控网络来选择最合适的专家。
- 这增加了模型的训练复杂度,需要更多的计算资源和时间来进行训练。
- 训练稳定性也是一个挑战
- 门控网络和专家之间的交互引入了不可预测的动态,阻碍了实现统一的学习率,并需要大量的超参数调整
- 令牌存在负载均衡的挑战
- 在训练过程中,门控网络往往倾向于主要激活相同的几个专家。
- 这种情况可能会自我加强,因为受欢迎的专家训练得更快,因此它们更容易被选择。
- ——>解决方法有:
- 引入辅助损失,旨在鼓励给予所有专家相同的重要性
- 给每个专家处理令牌的阈值
- 在训练过程中,门控网络往往倾向于主要激活相同的几个专家。
2.1 参数量相关
- 需要将整个模型(包括所有专家)加载到设备中,但在实际运行推理时,只需要使用部分参数
- MoE 模型需要更多的显存来加载所有专家,但推理时运行速度更快
3 decoder专家着色
在 Mixtral 8x7B 论文中,每个 token 都被其选择的第一个专家进行了着色

——>专家往往更关注句法,而不是某个特定领域的内容
4 专家选择不均匀性的解决方法
为了提高专家的泛化能力和防止过拟合,通常还会在训练过程中引入正则化技术,如权重衰减、Dropout等,或者以下的技术:
4.1 负载平衡
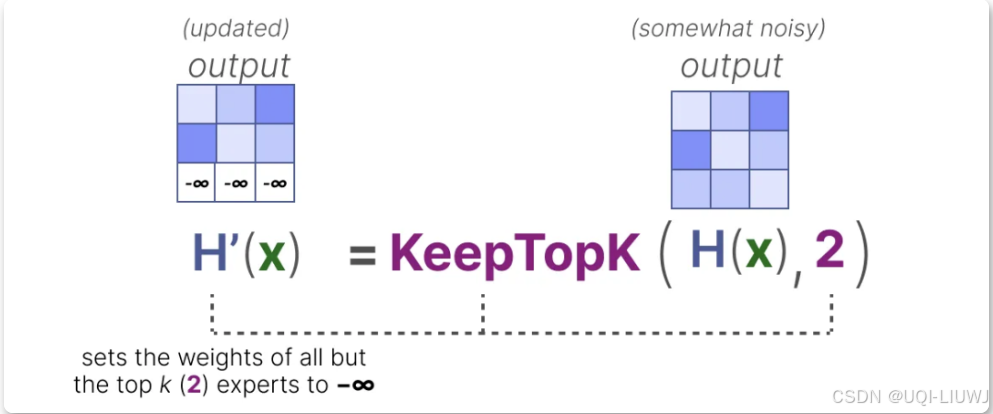
4.1.1 KeepTopK
- 通过引入可训练的(高斯)噪声,可以防止总是选择相同的专家
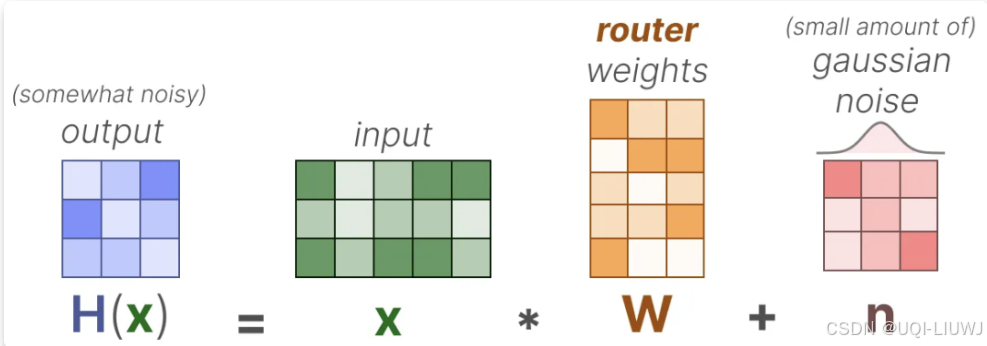
- 除希望激活的前 k 个专家(例如 2 个)以外的所有专家权重都将被设为 -∞
OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER 2017 ICLR
4.1.2 辅助损失【重要性得分计算变异系数】
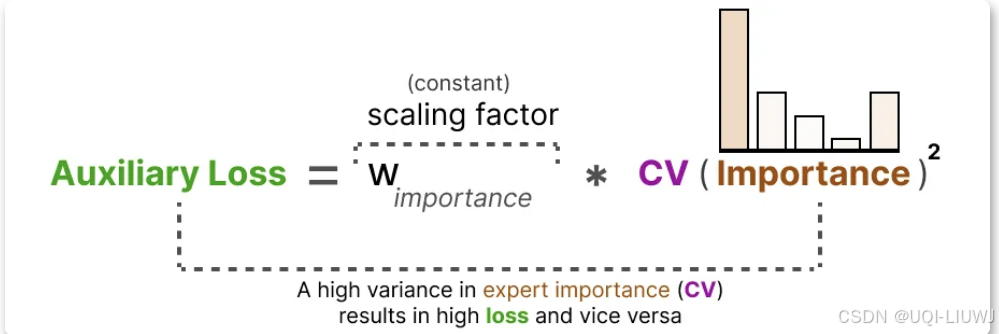
- 辅助损失增加了一个约束,强制专家在训练过程中具有相同的重要性。
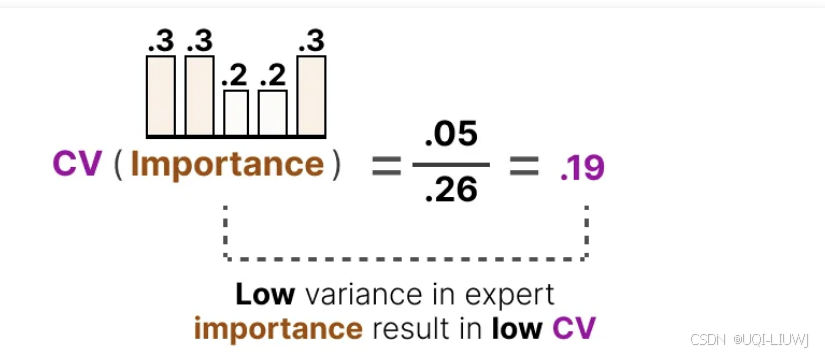
- 重要性得分计算变异系数(Coefficient of Variation, CV)
- 表示各个专家的重要性得分之间的差异程度
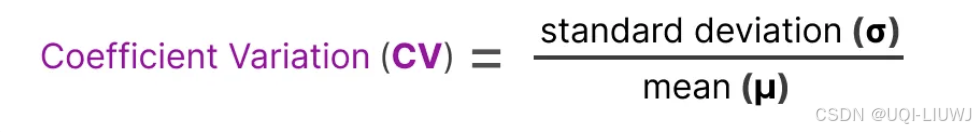
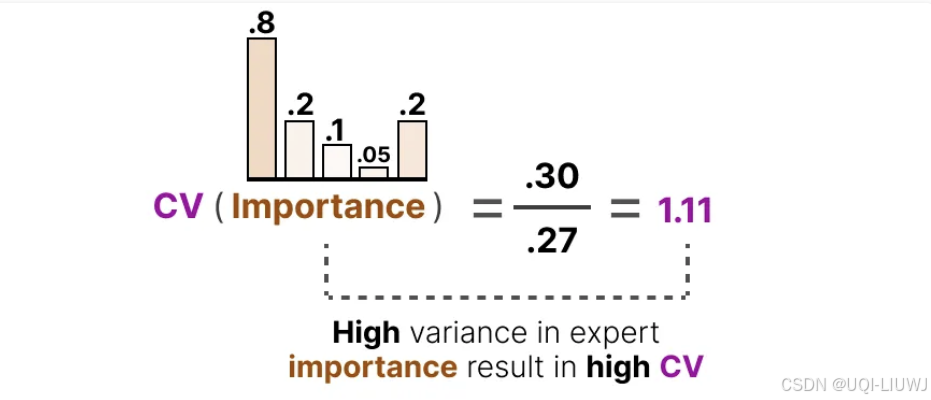
- 重要性得分之间的差异较大,那么 CV 值就会较高
- 如果所有专家的得分都相似,则 CV 值较低(期望的情况)
- 通过使用这个 CV 得分,可以在训练过程中更新辅助损失,使其尽可能降低 CV 得分(从而使每个专家具有相同的重要性)
4.1.3 专家容量
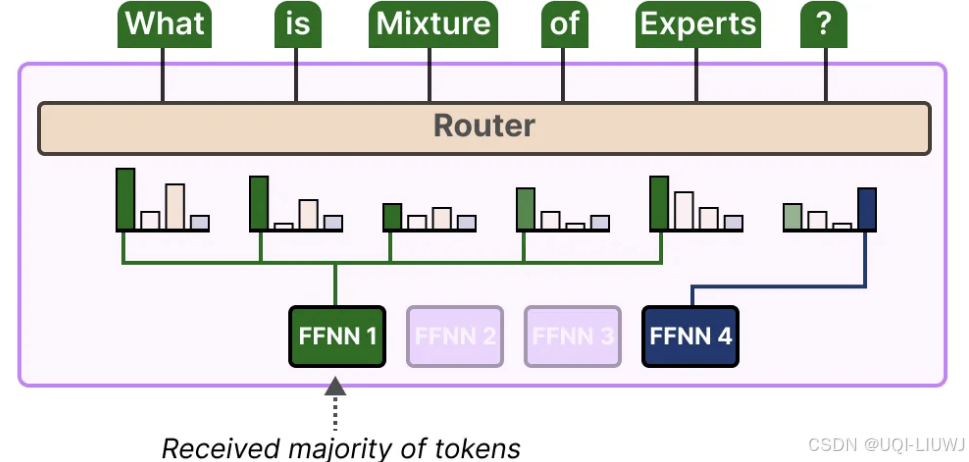
- 专家的不平衡不仅体现在被选中的专家上,还体现在分配给这些专家的 token 分布上
- 如果输入 token 被不成比例地分配到某些专家上,而不是平均分配,这可能导致某些专家的训练不足
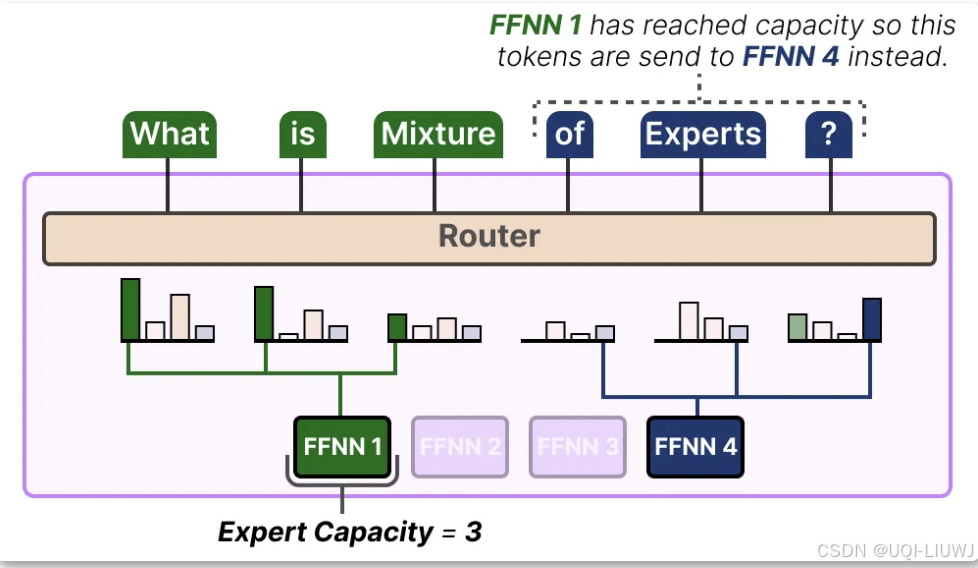
- ——>限制每个专家能够处理的 token 数量,即专家容量(Expert Capacity)
- 当一个专家达到其容量时,多余的 token 将被分配到下一个专家
- 如果两个专家都达到了其容量,token 将不会被任何专家处理,而是直接传递到下一层。(token overflow)
- 如果容量因子过大,就会浪费计算资源
- 如果容量因子过小,模型性能会因为 token 溢出而下降
- 当一个专家达到其容量时,多余的 token 将被分配到下一个专家
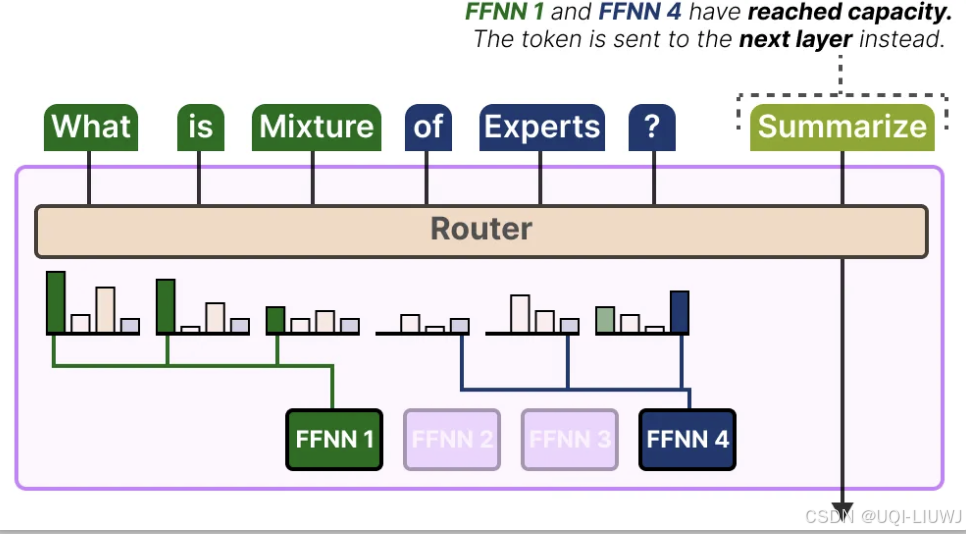
4.1.4 辅助损失(switch Transformer简化版本)

5 其他变体
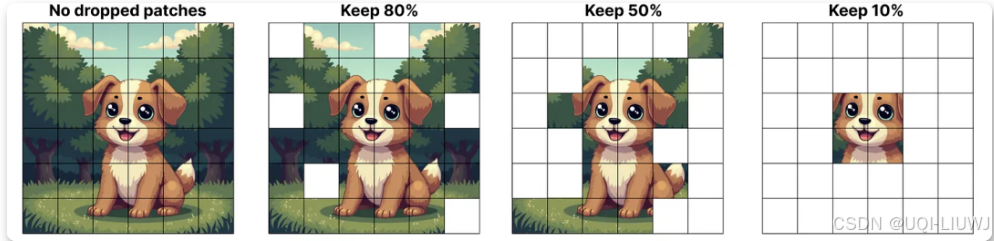
5.1 vison-MOE
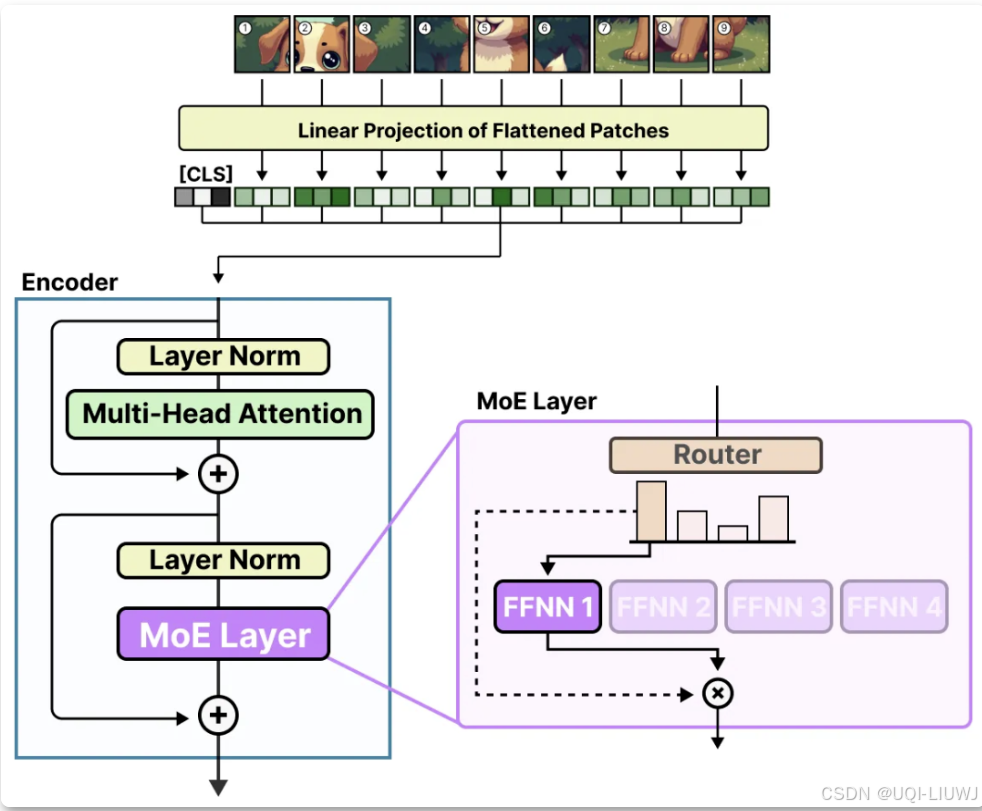
- 为了降低硬件限制,每个专家都设置了一个较小的预定义容量,因为图像通常包含大量的图像块。
- 然而,低容量往往会导致图像块被丢弃(token 溢出)
- ——>为每个图像块分配重要性得分,并优先处理这些得分较高的图像块,从而避免溢出图像块的丢失
- ——>即使 token 数量减少,重要的图像块仍然能被成功路由
- 然而,低容量往往会导致图像块被丢弃(token 溢出)
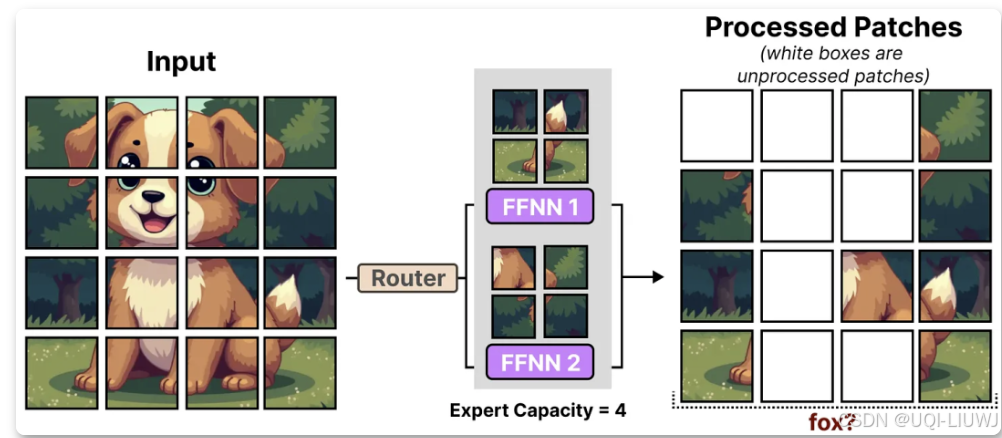
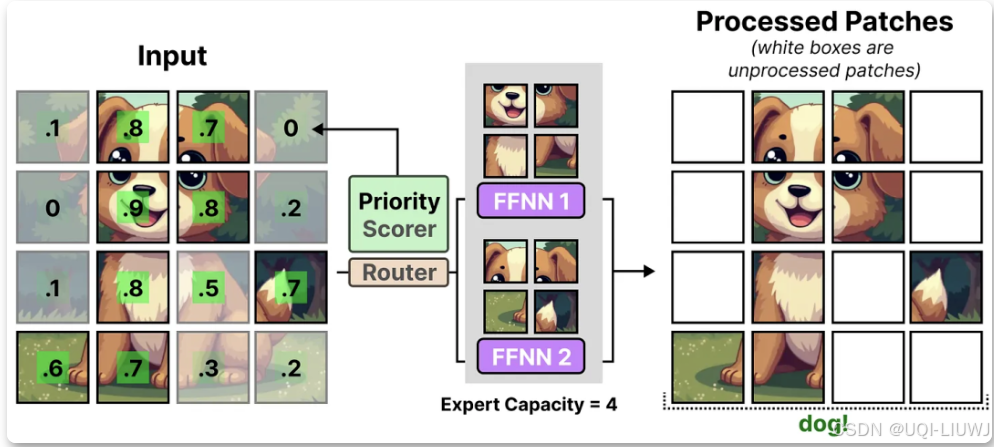
6 MOE 分类
6.1 参数由来
- 基于已有模型训练的MoE策略【upcycle(向上复用)】
- 复制已训练好的大模型的前馈神经网络权重
- 将每个复制的权重作为一个expert,构建MoE模型
- 缺点:
- expert之间可能存在知识重叠和权重冗余
- —>MoE架构的潜力无法充分发挥
- 举例:Mixtral系列,Qwen1.5-MoE-A2.7B,MiniCPM-MoE-8x2B
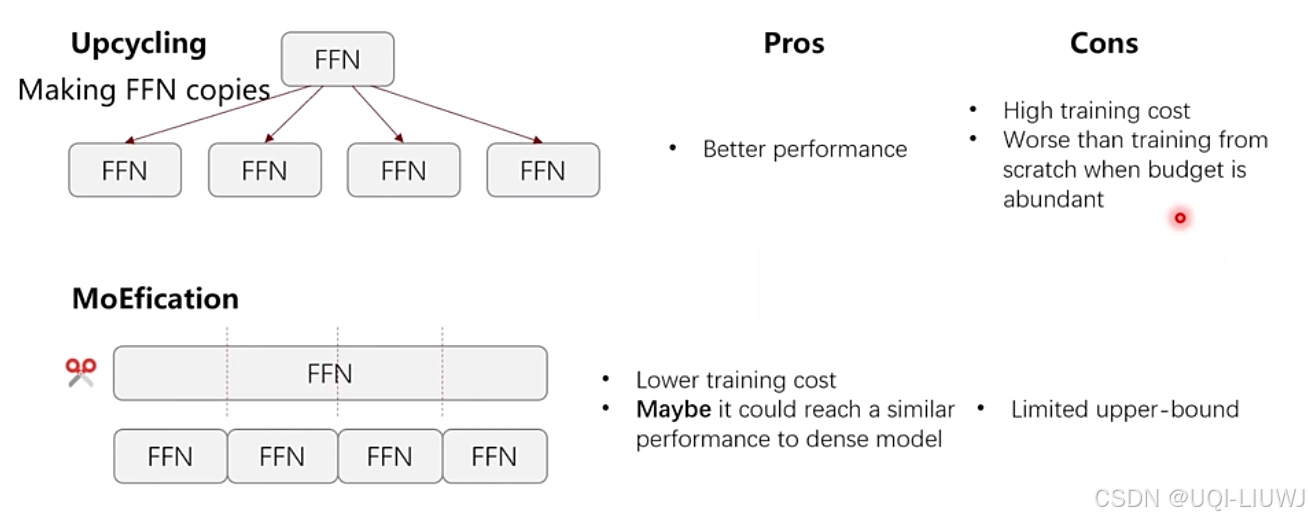
FFN复制多分/FFN切成小的几份(modification的缺点是上限不太可能超过dense模型)
- 从头开始训练的MoE策略
- 要求更高
- 举例:DeepSeek-V2
6.2 专家选择
| Soft Gating MoE |
|
| Hard Gating MoE |
|
| Sparse MoE |
|
| Hierarchical MoE |
|
7 专家并行计算
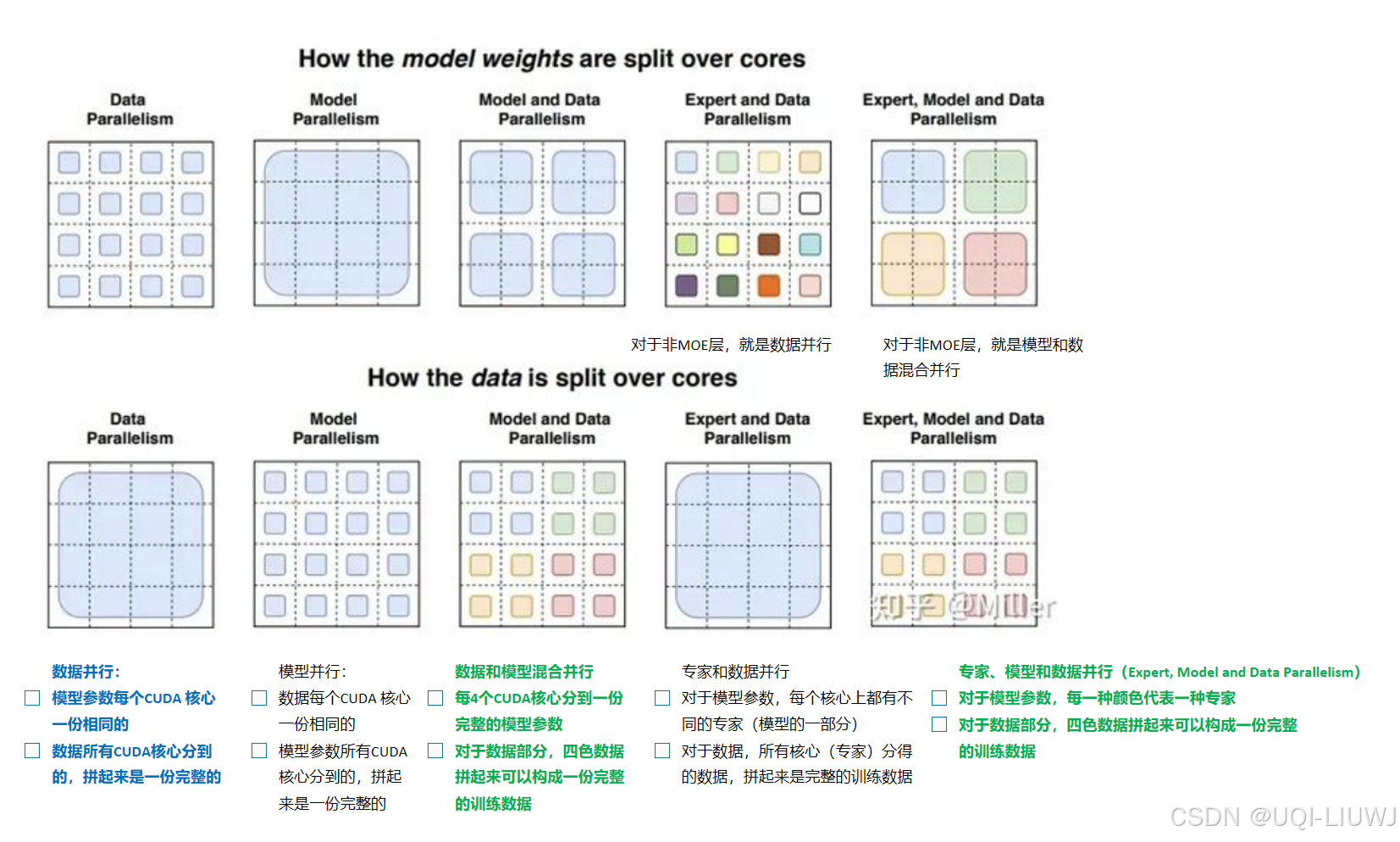
参考内容:图解 MoE 模型


















 1831
1831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











