







neurips 2024
1 intro
- 深入挖掘check-in序列的关键在于理解其丰富的语义信息
- 现有方法主要聚焦于特定任务(位置预测、时间预测。。。),而不是深入探究人类行为的语义信息。
- ——>这种局限性往往导致优化目标狭窄、对签到语义的理解较浅。
- 大语言模型在语义理解和上下文信息处理方面表现出强大能力,已在多个任务中成功适应。
- ——>旨在将预训练的 LLM 作为强大的签到序列学习者
- 现有方法主要聚焦于特定任务(位置预测、时间预测。。。),而不是深入探究人类行为的语义信息。
- 作为典型的序列数据,签到序列蕴含丰富语义,体现出多种短期规律和内在特征。
- 用户的未来行为往往受接近近期访问位置的短期规律影响,我们称之为访问意图(visiting intentions)
- 个体的内在特征具有跨时间和任务的持久性,决定其出行偏好(travel preferences)
- ——>主要挑战是:如何使 LLM 能够从签到序列中有效提取语义,全面理解用户的访问意图与出行偏好。
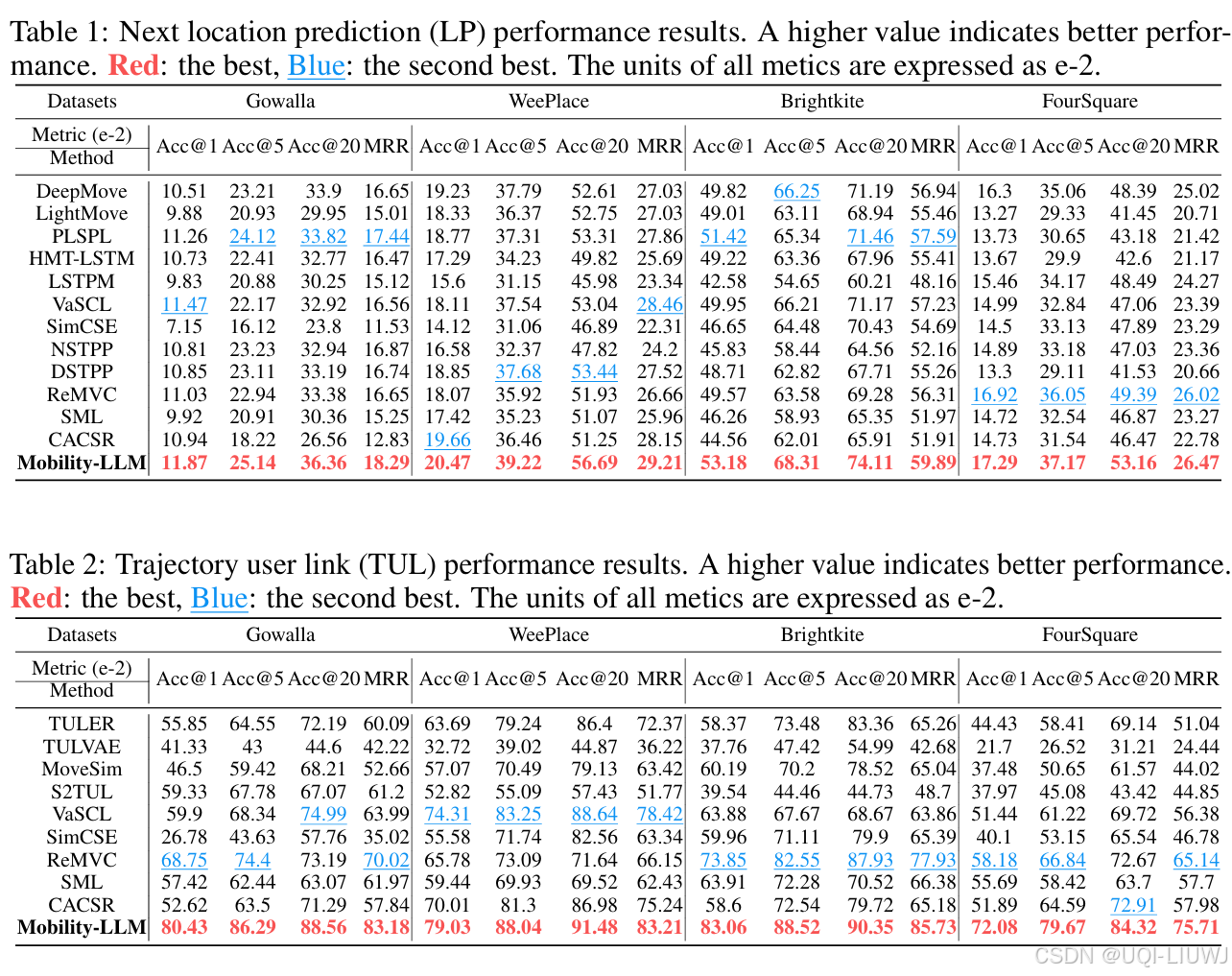
- ——>论文提出了一个统一框架 Mobility-LLM,利用预训练 LLM 在多个签到分析任务(如位置预测、轨迹用户链接、时间预测)中达到 SOTA 或相当水平。
- 从签到序列中提取语义信息,使 LLM 能够全面理解人类的访问意图和出行偏好。
- ——>提出访问意图记忆网络(VIMN),用于捕捉用户在每次签到中的访问意图
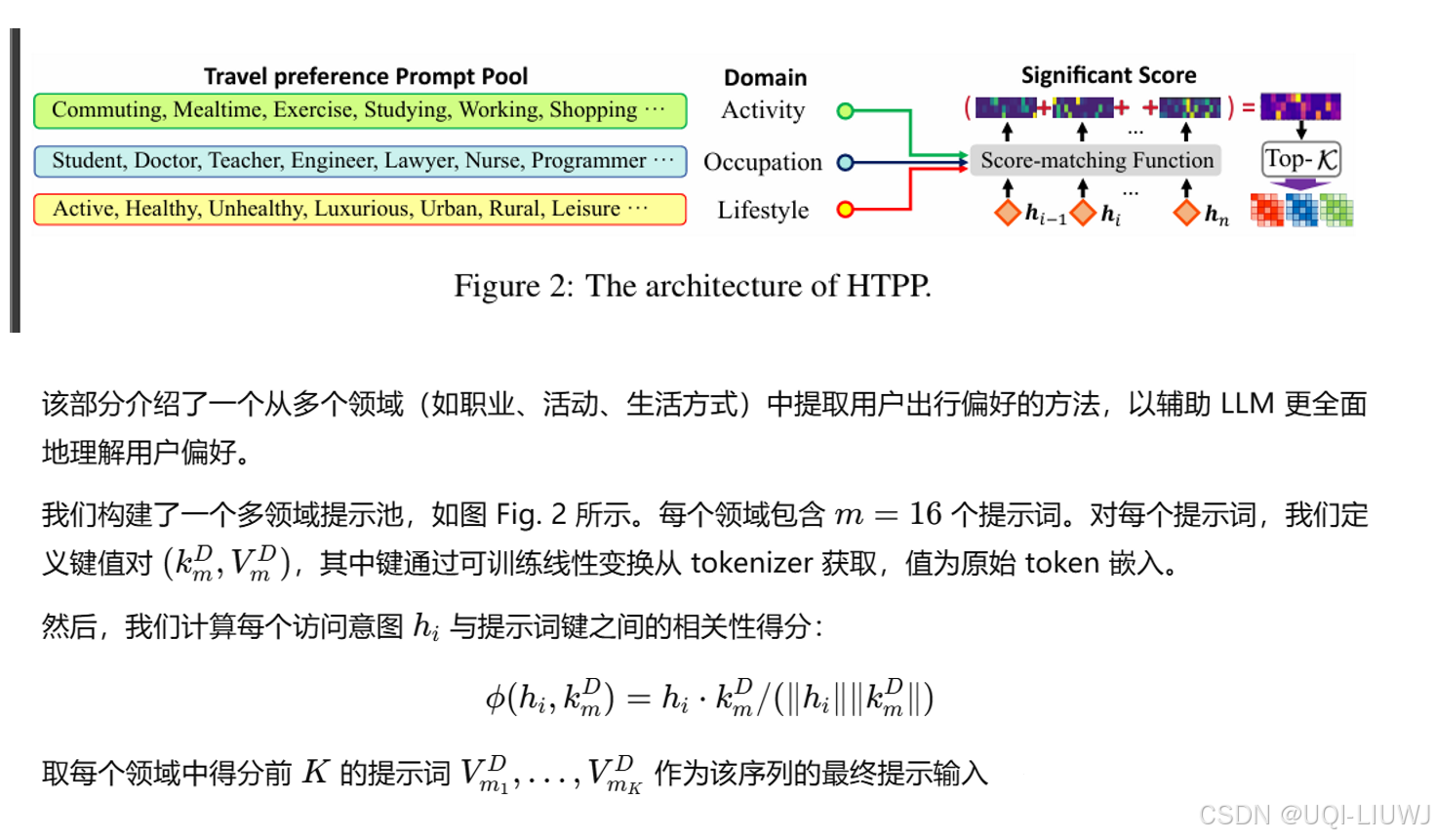
- ——>提出人类偏好的共享提示(HTPP),用于不同领域中引导 LLM 理解用户的出行偏好,从而实现跨领域迁移,并匹配适当领域的任务。
2 Preliminary

3 方法
3.1 整体框架

3.2 PPEL(POI嵌入)
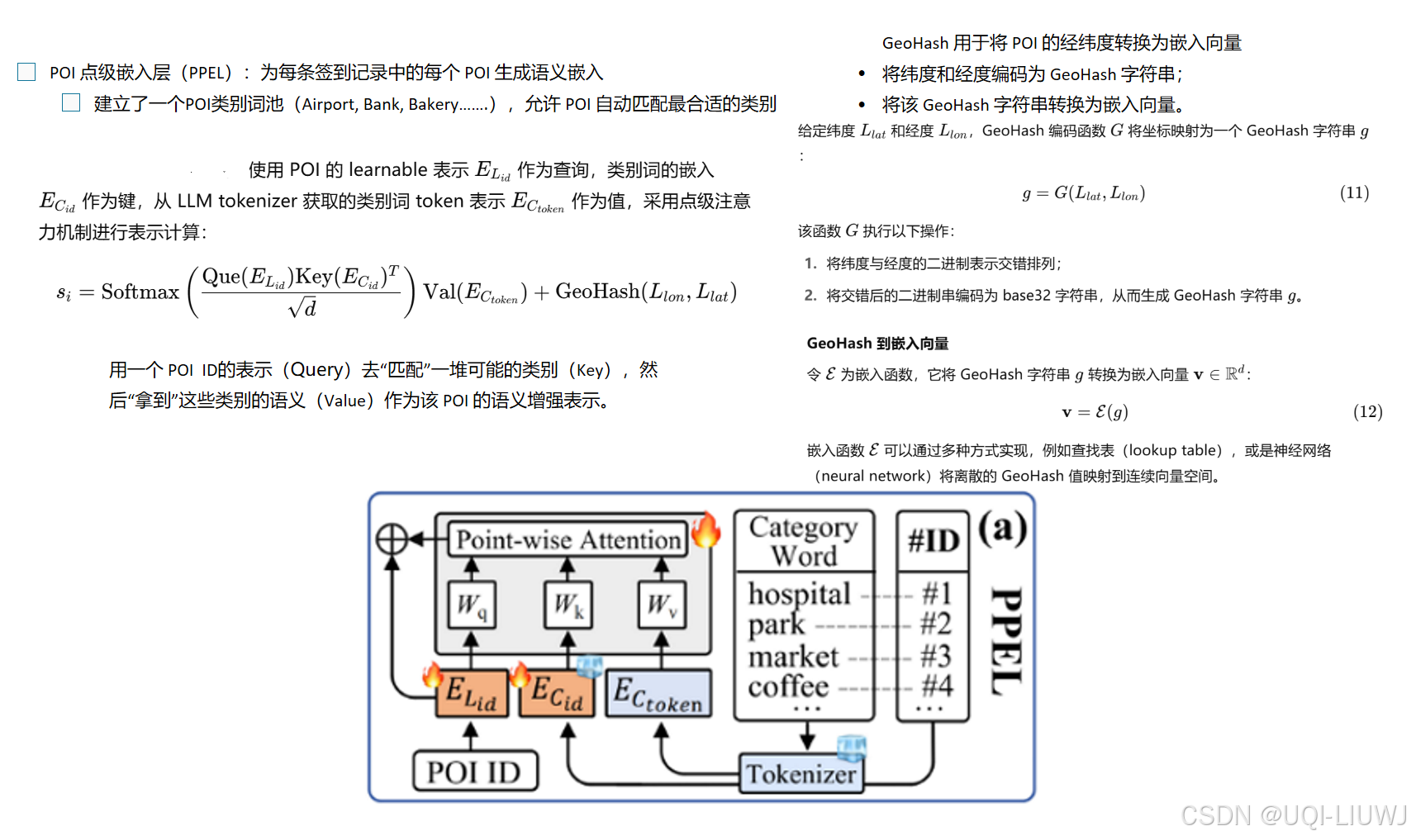
3.3 VIMN 用户访问意图建模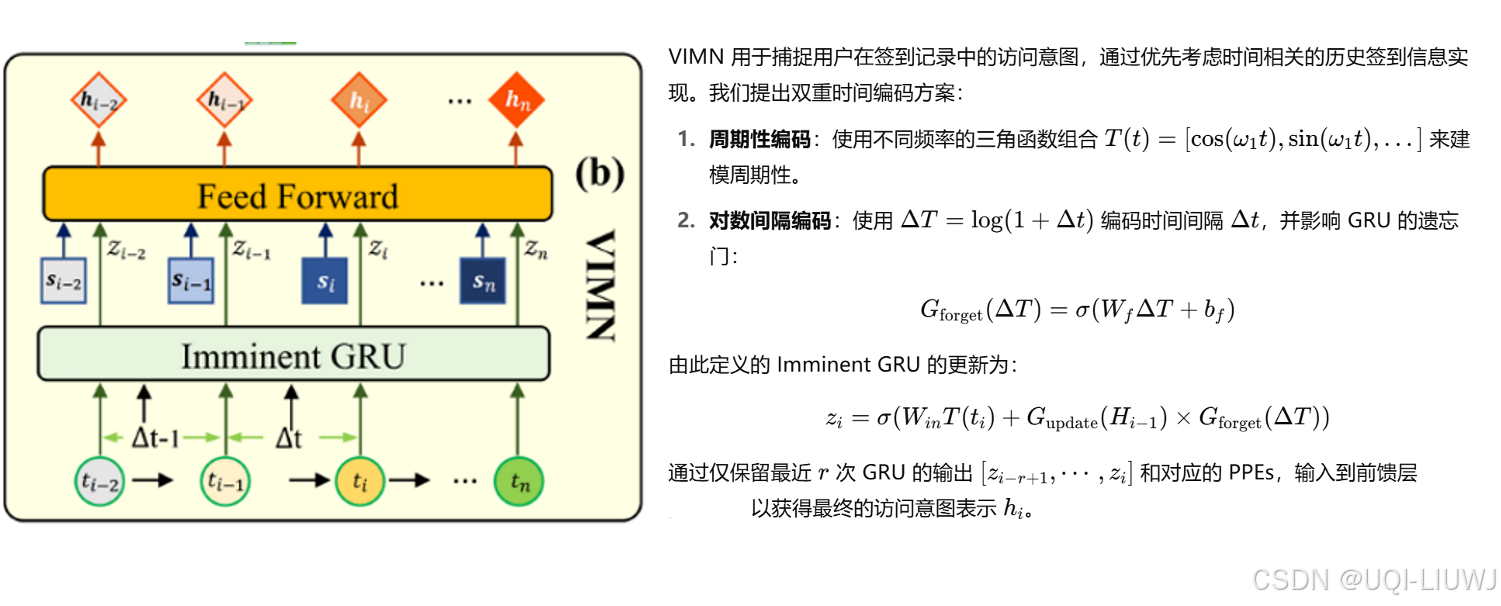 3.4 HTPP 用户偏好建模
3.4 HTPP 用户偏好建模


















 6508
6508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











