










摘要
- 随着计算机视觉领域取得的惊人成功,我们有望把卷积网络特征应用到机器人领域。
但是这存在本质性的困难和挑战,因为:
1.计算机视觉的数据集是不同于机器人摄像机的数据;
2.实时的性能是至关重要的;
3.性能优先级是不同的。 - 这篇paper:综合评估了目前三种最优秀的ConvNet在机器人导航相关任务中的实用性、viewpoint-invariance and condition-invariance、以及通过集成各种现有的(位置敏感散列)和新颖的(语义搜索空间划分)优化技术,首次使用带有大型地图的ConvNets实现实时位置识别性能。
- 我们在四个真实世界数据集上做了大量的实验,这些数据集被用来评估在位置识别领域每个特定的挑战。
- (我们改进了搜算算法)结果证明用最小的精度退化的取得了加速两个数量级,我们确认为语义位置分类在面临着严重的环境变化时训练的模型,也在位置识别中能表现的很好,并且对于位置识别问题的不同方面给出了一个参考:哪个网络的哪个层是最优最合适的。
I. 导言
机器人需要长时间工作,一天、一个月、一年…面临着相同环境的剧烈变化,视觉识别系统需要在这些剧烈变化中依旧能够识别出已经知道的位置。最佳有很多方法提出如何解决环境的剧烈变化问题,典型的有SeqSLAM,还有做一些阴影移除,粒子滤波器等等。最近随着计算机视觉的发展,发现用卷积神经网络提取的特征更具鲁棒性在视觉位置识别领域。ConvNets已经被证明是通用的和可转移的,也就是说,即使他们被训练在一个非常具体的目标任务,他们可以成功地部署解决不同的问题(类似迁移学习)。
- 我们的论文利用了这些惊人的性能,并介绍了第一个实时的基于卷积神经网络的位置识别系统。我们利用了卷积神经网络特性的层次性,并且使用在高层次的语义信息编码用于搜索空间分区,以及使用中等层次的特征,在具有挑战性的条件下,用于位置匹配。
- 这些特征的局部敏感哈希允许我们实现鲁棒的位置识别,用以3Hz采集的100000万张已知的地方。
- 我们提供了一个全面的在ConvNet中每层的实用性调查,并且更深入的比较了三种网络对于位置识别的性能,我们确定了以下主要结果:
(1)来自网络高层的特征编码了很多语义信息,可以用来划分搜索空间,显著减少位置识别时间。
(2)将特征间的余弦距离与局部敏感哈希得到的位向量上的汉明距离近似,将特征数据压缩99.6%,但保留95%的位置识别性能,可以实现两个数量级的加速
(3)在比较不同的卷积神经网络在严重的外观变化下的位置识别任务时,针对语义位置分类任务训练的网络优于针对对象识别任务训练的卷积神经网络
(4)来自ConvNet层次结构中间层的特征对由时间、季节或天气条件引起的外观变化表现出健壮性;
(5)从顶层提取的特征在视点变化方面更健壮。
II.相关工作
A. 位置识别
针对环境改变这个问题,提出了很多Idea,但是这些idea都有一些问题:除了需要训练数据之外,这些方法的普遍性目前也是未知的;这些方法只能在相同的环境中,在与训练数据集中遇到的环境变化相同或非常相似的情况下使用。
B. 卷积网络
预先训练的网络模型的可用性使我们可以很容易地在不同的任务中试验这些方法。这里的意思可以直接用框架中的深度学习网络做一些测试,例如以前的caffe,现在的pytorch等。
这篇文章 Convolutional Neural Network-based Place Recognition
是第一次考虑把ConVNet运用到位置识别中,而我们的文章更加全面,而且将ConVNet的贡献从特征匹配中分离,而且还提出一种基于ConVNet的重要的实时算法。
III .Preliminaries
使用卷积神经网络提取特征
我们应用AlexNet,它由五个卷积层,三个全连接层,以及一个soft-max层组成。
每一层的输出都可以从网络中提取出来,作为整体的图像描述符。
由于第三个全连接层和soft-max层用于图像分类 ILSVRC 任务中,所以我们不采用这两层。

B. 图像匹配和性能指标
位置识别是通过计算图像提取出的特征向量,与数据库特征向量之间的余弦距离,搜索出在图像数据库中它的最近邻,从而实现的。
我们用PR曲线和F1分数,则为正,否则为负)来分析性能。与Convolutional Neural Network-based Place Recognition相比,我们明确不应用序列搜索技术或其他专门的算法方法来提高匹配性能,以观察所研究的ConvNet特性的baseline性能。
**F1 score:**人们通常使用准确率和召回率这两个指标,来评价二分类模型的分析效果。
但是当这两个指标发生冲突时,我们很难在模型之间进行比较。比如,我们有如下两个模型A、B,A模型的召回率高于B模型,但是B模型的准确率高于A模型,A和B这两个模型的综合性能,哪一个更优呢?为了解决这个问题,人们提出了F(b)分数。
F(b)的物理意义就是将准确率和召回率这两个分值合并为一个分值,在合并的过程中,召回率的权重是准确率的b倍 。F(1)分数认为召回率和准确率同等重要,F(2)分数认为召回率的重要程度是准确率的2倍,F(0.5)而分数认为召回率的重要程度是准确率的一半.
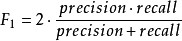
如果我们想创建一个具有最佳的精度—召回率平衡的模型,那么就要尝试将 F1 score 最大化
C.在评估中使用的数据集

Nordland数据集:
Nordland数据集包含从前车的角度记录的四个不同季节的10小时火车旅程的视频片段。图6显示了不同季节间外观的严重变化。Nordland数据集是一个完美的实验数据集,因为它没有显示任何的视点变化,因此允许在纯粹的条件变化上测试算法。在我们的实验中,我们以每秒1帧的速度提取图像帧并排除所有在隧道内或火车停站时拍摄的图像。
Gardens Point 花园点数据集:
:它包括三次环境遍历,两次在白天,一次在晚上。在此过程中,对夜间图像进行了极大的对比度增强并转换为灰度。其中一天的行程记录在人行道的左侧,而另一天和夜晚的数据集记录在右侧。通过这种方式,数据集同时显示外观和视角变化。
Campus Human vs. Robot数据集:
这个数据集记录在我们校园的不同区域(户外、办公室、走廊、美食广场),一次由使用Kinect RGB摄像头的机器人记录,一次由使用GoPro摄像头的人类记录。机器人的镜头是在白天拍摄的,而人类则是在黎明的时候穿越环境,导致了明显的外观变化,尤其是户外场景。GoPro的图像被裁剪成只有原始图像一半大小的中间部分。
The St. Lucia 数据集:
圣卢西亚的数据集[31]记录了一辆汽车在布里斯班郊区一天内5次不同的移动,以及两周内不同的日子。它的特点是温和的视点变化,由于轻微的变化,在具体路线的汽车采取。可以观察到由于一天中不同时间而产生的更显著的外观变化,以及由于交通或车辆停靠等动态对象而产生的一些变化。
一层层的研究
本节将深入研究ConvNet层次结构中不同层次在位置识别方面的效用,并评估它们对视觉位置识别中的两个主要挑战(严重的外观变化和视角变化)的鲁棒性。
A. 外观变化鲁棒性
实验结果表明,与其他层的特征相比,conv3层的中层特征对外观变化的抵抗能力更强。

B.视角变化
我们进行了两个实验:
1)Nordland spring数据集,通过使用裁剪图像并移位,来创建合成的视点变化。
2)我们使用Gardens Point数据集(白天的左视图和白天的右视图)来验证在真实数据集上观察到的效果。

上层增加的视点健壮性可以归因于池化层,池化层是网络架构的一部分,在第一、第二和第五卷积层之后执行最大池化。
C. 总结

- 即使是在严重的外观变化的情况下(如春夏秋冬或者白天和黑夜) ,中间层的conv3作为全局特征描述子表现的很好。在外观变化很少或几乎没有的,并且有视角变化的情况下,高层的fc6(全连接层)变现的较好。
- 这是可以说通的:第一卷积层提取的是类似形状特征这类简单的特征,这些特征不足以位置识别系统在严重外观变化的条件下work,越高层的特征越能表征语义信息,但是也因此丢失了区分在相同语义类型场景下两个位置。
- 例如在St. Lucia 数据集中,较高的层编码郊区道路场景”信息,这对于数据集中所有图像是一样的。这个功效有利于位置分类,但不利于位置识别。中间层,尤其是conv3,似乎只编码了适量的信息;它们比纯粹的低水平像素或基于梯度的特征更能提供信息和对变化更强的抵抗力,同时保留了区分度足够去确认单个位置。
- 效率:
在Nvidia Quadro K4000 GPU上,从图像中提取卷积神经网络特性大约需要15ms。位置识别系统的瓶颈是基于64,896维特征向量之间的余弦距离的最近邻搜索,这是一个计算量很大的操作。我们的Numpy/Scipy实现需要3.5秒才能在10,000个以前访问过的地方中找到一个匹配的地方。正如我们将在下一节中看到的,可以引入两个重要的算法改进,从而提高2个数量级的速度。
V. 实时大规模位置识别
相比典型的计算机视觉基准,识别精确度是最重要的性能指标,机器人应用依赖于在一定软实时限制下的敏锐算法。最近邻搜算是限制大规模的位置识别的关键因素,因为它的运行时间随着参观过的地方增加而增加接下来我们提出两个方法,使得搜算时间降低两个数量级,仅仅用很少的精确度退化。
A. 局部敏感哈希
我们使用一个专门的二分局部敏感哈希变体,保留余弦相似性,















 2860
2860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









