









目录
前言
我一直都很喜欢“统一内存”这个设计。内存可以作为显存使用,价比金贵的内存第一次有了性价比。自从Apple M1芯片引入了统一内存架构,我第一次发现,从前只能办公上网的轻薄本在拥有了11TOPS算力后,也是能在AI领域战未来的。Jetson Orin系列AI开发板就是百花齐放的统一内存阵营的一员。在固件更新后,Jetson Orin Nano的8G版本性能释放到了25w,双通道内存带宽达到了102GB/s,算力也是来到了恐怖的67TOPS。进入AI时代,大语言模型的更新换代层出不穷,喜欢自己部署大语言模型的朋友,相信都对ollama爱不释手,ollama是如今最常见的本地大语言模型部署工具,它开源且开放,我也习惯从大语言模型入手来接触一个平台,尤其是在支持 CUDA 的 Jetson 平台上能够以更少性能损失的代价使用 MLC 运行具有更高性能后端的模型,也就是说能比通用的llama.cpp具有更高的单位时间有效token处理速度,token/s代表了模型一秒钟可以处理的数据量,这个数字越大,模型处理数据的速度更快,直观地感受token/s的速度就是能明显看到,在使用MLC为后端的模型时,回答的思考速度和吐字速度变得更快了。daisy.skye-CSDN博客daisy.skye擅长Linux,嵌入式,Qt,等方面的知识https://blog.csdn.net/qq_40715266?spm=1011.2124.3001.5343
一、开箱体验:极简扩展并存
Jetson Orin Nano Super的包装延续了NVIDIA一贯的简洁风格,内部配件包括电源适配器、Type-C数据线及快速上手指南。开发板本体仅69.6mm×45mm,重量约150g,体积与树莓派相当,但功能却远超传统单板计算机。
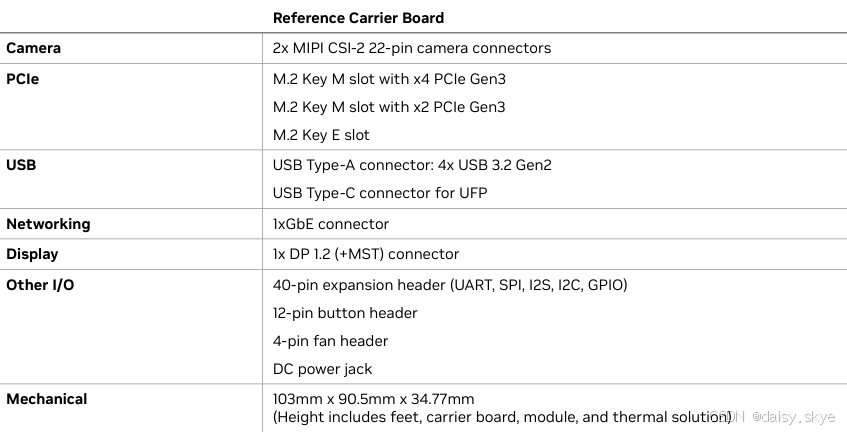
接口配置堪称豪华:
显示输出:仅保留DisplayPort 1.2接口,支持4K@60Hz输出;
存储扩展:双M.2插槽(2280/2230规格),支持NVMe SSD,理论容量达4TB;
外设连接:4×USB 3.2、千兆网口、CSI摄像头接口(支持4路物理通道)及40针GPIO扩展,满足机器人、无人机等复杂场景需求。

二、NVIDIA Jetson 软件生态
1. JetPack SDK
- 核心组件:L4T (Linux for Tegra):定制化 Linux 发行版,集成 GPU 驱动和 AI 加速库。
- CUDA Toolkit:支持 GPU 加速计算。
- cuDNN:深度学习卷积神经网络加速库。
- TensorRT:优化推理性能,支持 INT8 量化。
- OpenCV 和 GStreamer:多媒体处理框架。
- 下载与文档:JetPack SDK 下载JetPack 文档
2. 开发工具链
- Nsight:GPU 调试与性能分析工具。官网:Nsight
- NVML (NVIDIA Management Library):监控和管理 GPU 资源的 API。
- 文档:NVML Programming Guide
- Triton Server:支持多模型推理的容器化服务。官网:Triton Inference Server
3. 容器化与云边协同
- L4T 容器引擎:支持 Docker 和 Kubernetes 在 Jetson 上运行。
- NVIDIA Clara:云端训练与边缘推理框架。官网:NVIDIA Clara
- NVDS (NVIDIA Deep Learning SDK):集成视频分析、目标检测等工具链。官网:NVDS
三 、应用场景
1、本地部署DeepSeek
跟着官方引导来到模型页面,国产骄傲DeepSeek排名在与MLC适配好的众多热门模型之首,想也不用想当然是想要试试deepseek的。由于8G内存最大只能运行8B的模型,所以就直接选择DeepSeek R1 Llama-8B来进行本地部署。
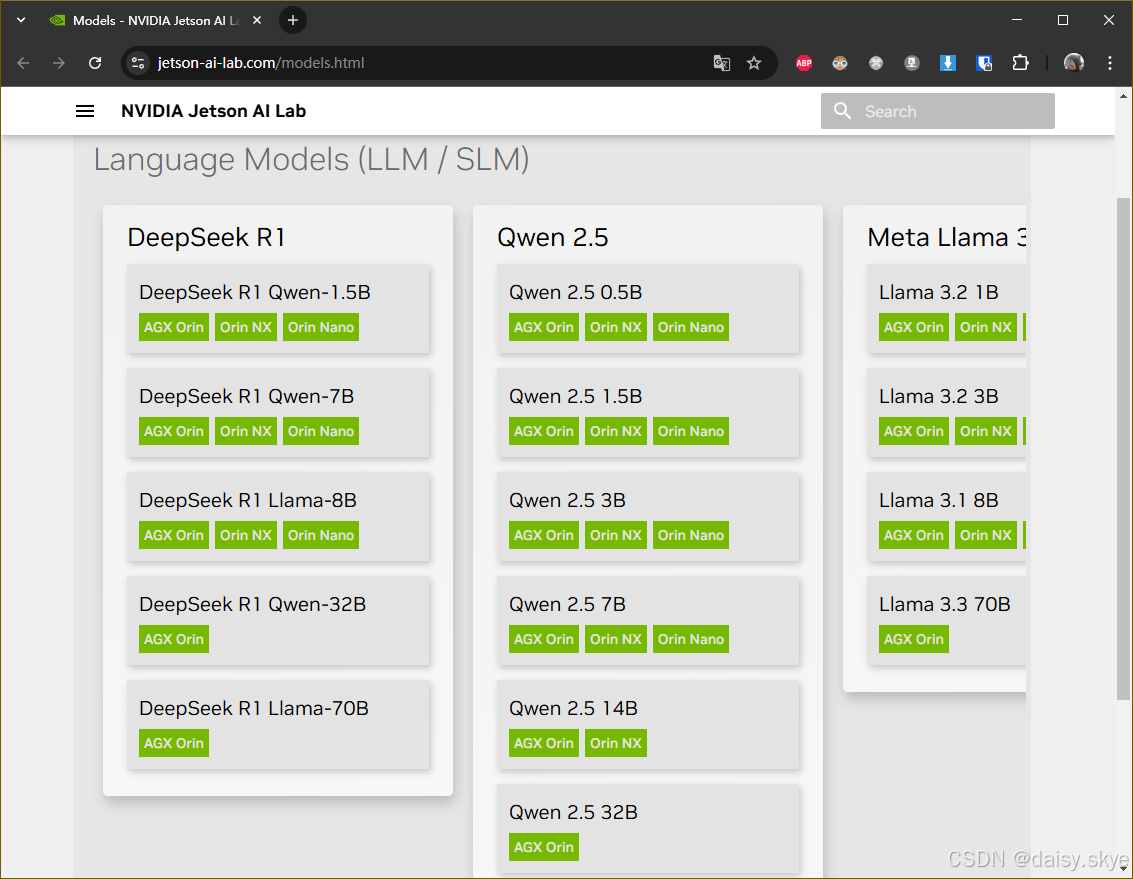
经常自己部署模型的朋友都知道,从头开始部署一系列环境和应用乃至模型,是一件不算简单的事情,而遇到麻烦的环境,就不得不见见我们的好朋友docker了。docker是一个优秀的部署工具,而使用docker compose是一种相当优雅的体验,不需要关心参数选项,将繁琐的路径最优化,我只想要也只需要与应用交互。所以能够直接套用的compose脚本,更能够体现现代化的应用部署方式。
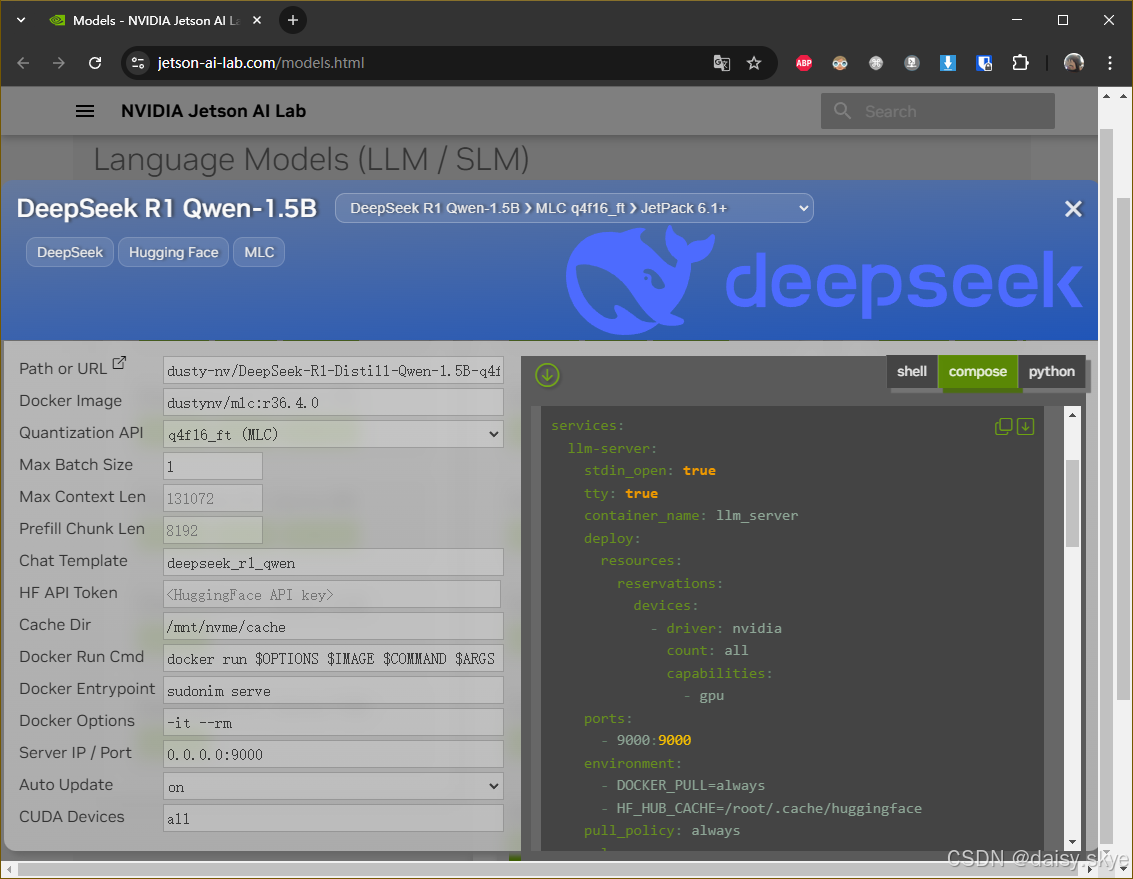
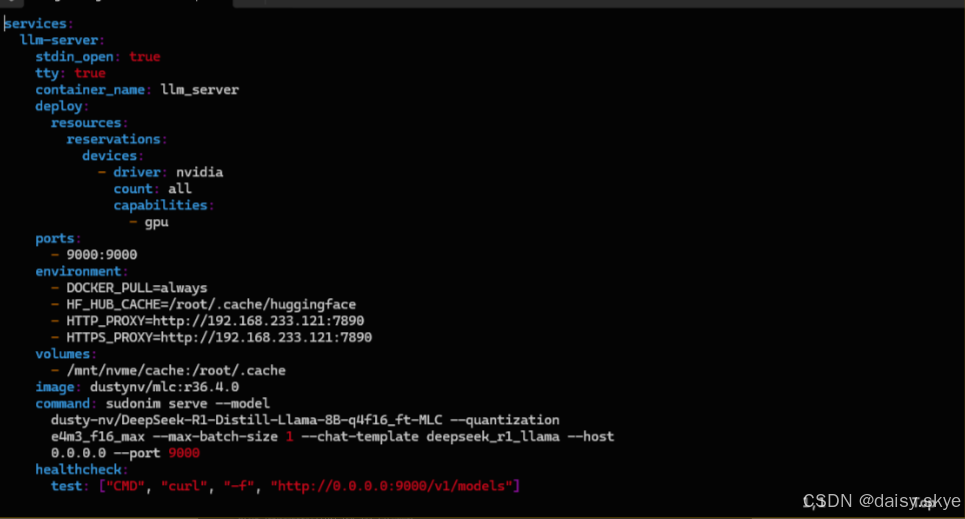
基于compose脚本我微调了一些选项,我为了流畅下载,在配置中增加了代理选项,让模型的下载速度更上一层楼;取消了每次启动时强制拉取镜像的选项,更适合中国宝宝的体质。代理选项HTTP_PROXY和HTTPS_PROXY的地址根据实际情况进行更改或者移除。
services:
llm-server:
stdin_open: true
tty: true
container_name: llm_server
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities:
- gpu
ports:
- 9000:9000
environment:
- HF_HUB_CACHE=/root/.cache/huggingface
- HTTP_PROXY=http://192.168.233.121:7890
- HTTPS_PROXY=http://192.168.233.121:7890
volumes:
- /mnt/nvme/cache:/root/.cache
image: dustynv/mlc:r36.4.0
command: sudonim serve --model
dusty-nv/DeepSeek-R1-Distill-Llama-8B-q4f16_ft-MLC --quantization
e4m3_f16_max --max-batch-size 1 --chat-template deepseek_r1_llama --host
0.0.0.0 --port 9000
healthcheck:
test: ["CMD", "curl", "-f", "http://0.0.0.0:9000/v1/models"]
interval: 20s
timeout: 60s
retries: 45
start_period: 15s
open-webui:
profiles:
- open-webui
depends_on:
llm-server:
condition: service_healthy
stdin_open: true
tty: true
container_name: open-webui
network_mode: host
environment:
- ENABLE_OPENAI_API=True
- ENABLE_OLLAMA_API=False
- OPENAI_API_BASE_URL=http://0.0.0.0:9000/v1
- OPENAI_API_KEY=foo
- HF_HUB_CACHE=/root/.cache/huggingface
volumes:
- /mnt/nvme/cache/open-webui:/app/backend/data
- /mnt/nvme/cache:/root/.cache
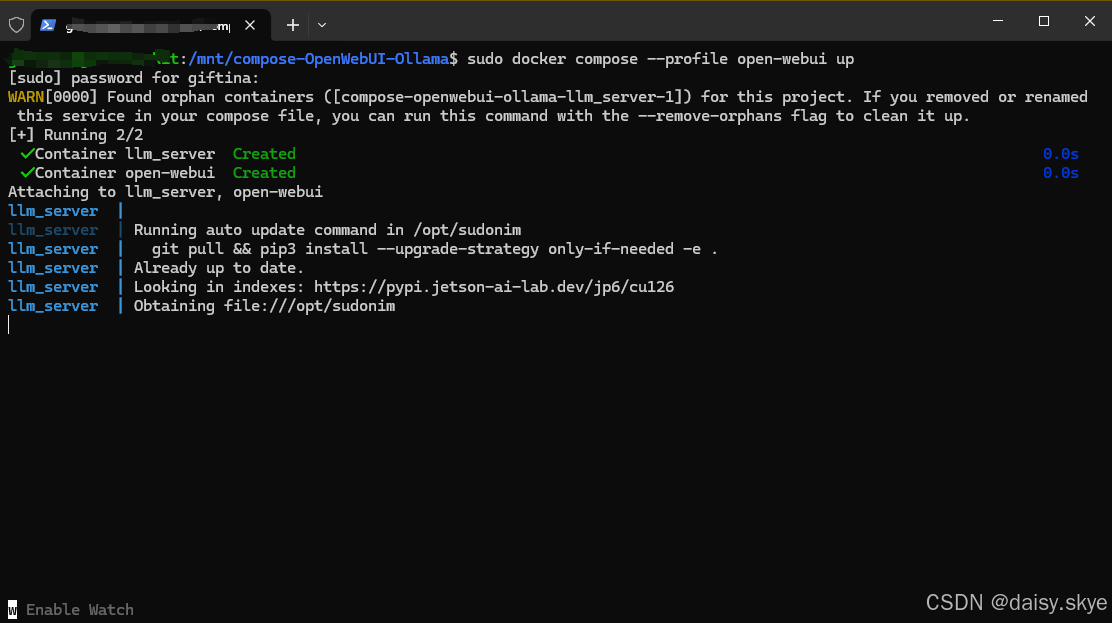
image: https://ghcr.io/open-webui/open-webui:main将docker compose脚本保存到本地,只需要输入`sudo docker compose --profile open-webui up`就可以按照脚本中的预设,等待后端llm-server启动完成后再跟随启动前端open-webui,免去了手动启动或者是同步启动导致的前端干等后端的情况。
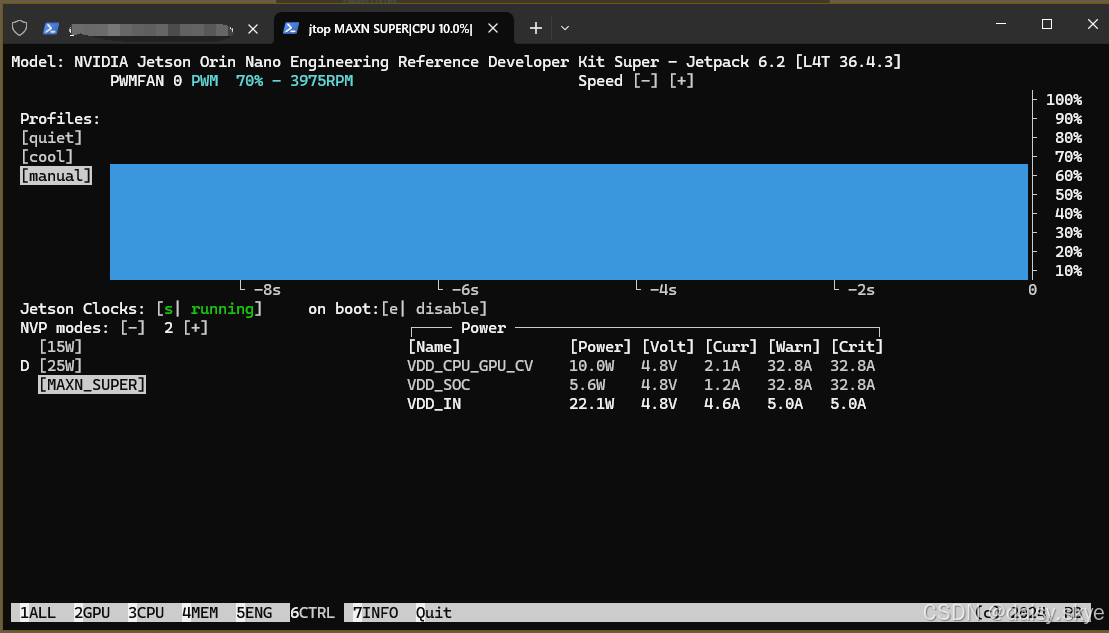
在运行大模型套件之前,为了最大化这块67TOPS算力卡的性能,可以使用jtop工具锁定最高工作频率和功率,物尽其用。具体是在jtop的Ctrl页,可以通过鼠标点击来启用散热优先的cool风扇策略,接着启用Jestson clocks强制电源使用最高功率,最后不要忘了把功率切换到MaxnSuper模式,这样操作三部曲过后,可以在散热、电源和功率层面上最大化发挥出这套系统的处理能力。
一键运行,去泡一杯卡布奇诺,用不了几分钟,镜像和模型就都下载好了,一切都是无感知地有序启动,只需要像以前那样,打开openwen ui的8080端口
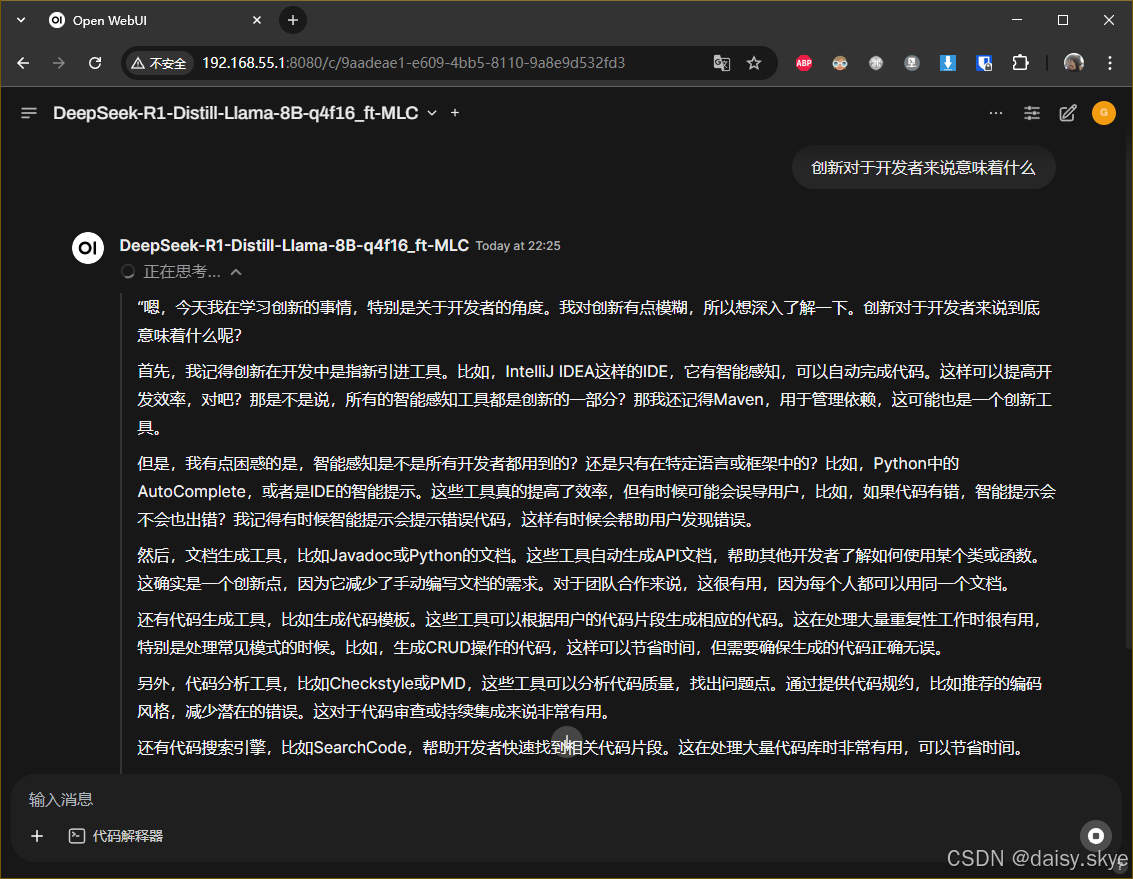
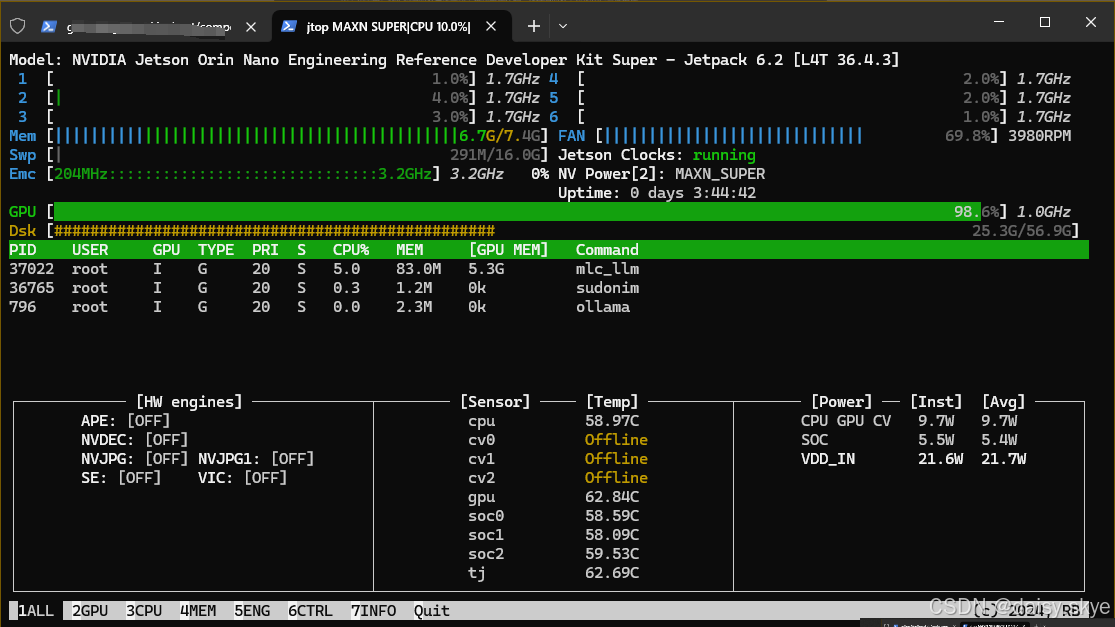
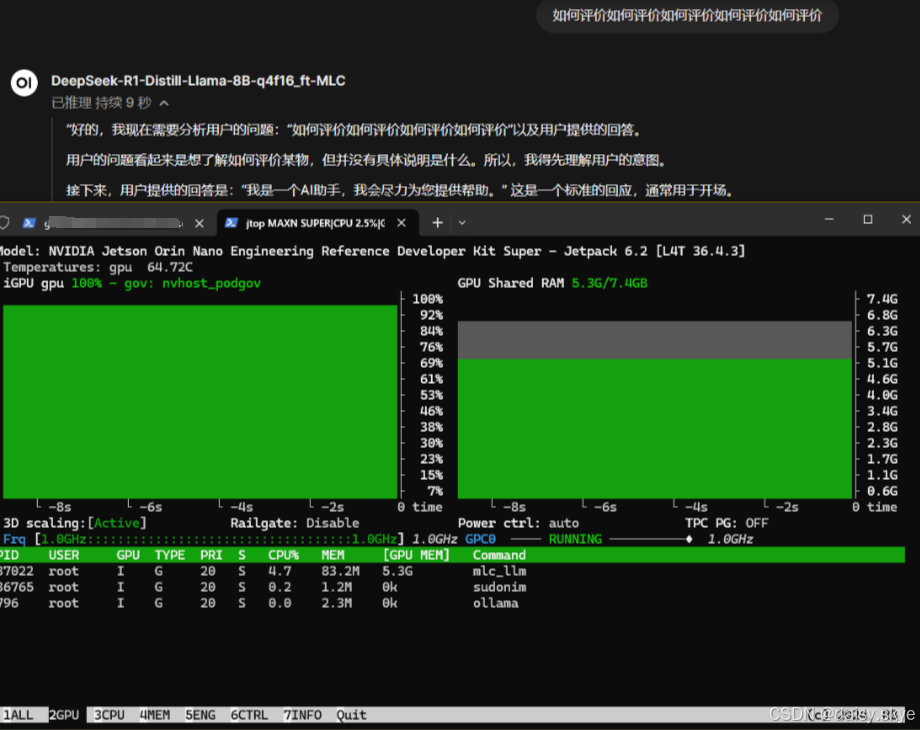
由于大模型使用GPU进行计算,基本不占用CPU,所以可以看到GPU有难,CPU围观的奇妙景象,也就意味着还有余量使用CPU进行其他工作。
2、视觉检测 Jetson-AI-Lab
Jetson Orin Nano不仅能部署大语言模型,还能以最少的学习和使用成本进行众多的ai相关的应用,像是视觉模型、图像媒体生成、机器人,甚至能够将这些所有应用组合在一起成为一个工作室级别的跨应用。
要让AI进入科幻时代,视觉模型是必不可少的一环,当AI获得了视野,就像是新时代的巨人睁开了双眼,映入眼帘的不再是猜测,而是确定的实体。给运行着视觉模型NanoOWL的Jetson Orin Nano接入一个普通的USB摄像头,它就得到了/dev/video0这只眼睛。

使用 jetson-containers run 和 autotag 命令来自动拉取或构建兼容的容器镜像,非常简单方便
jetson-containers run --workdir /opt/nanoowl $(autotag nanoowl)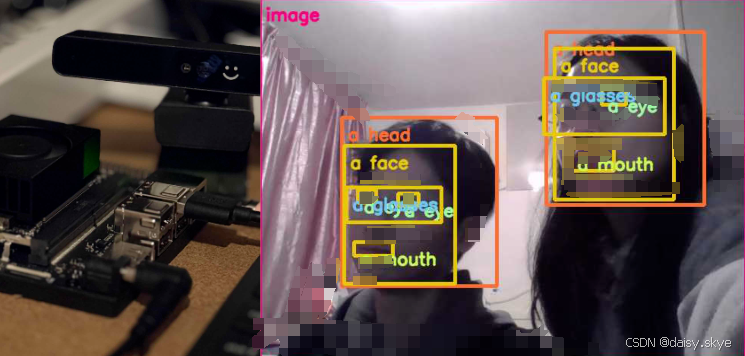
| 维度 | Jetson-AI-Lab 模型 | 传统云端/通用模型 |
|---|---|---|
| 延迟 | 毫秒级(本地处理) | 秒级(网络传输+云端计算) |
| 成本 | 硬件一次性投入(<3000元) | 持续云服务费用 |
| 隐私安全 | 数据本地处理,无需上传云端 | 数据外流风险 |
| 更新维护 | 热更新支持(Triton 服务器) | 需依赖云端更新 |
Jetson-AI-Lab 模型的核心优势在于 轻量化、多模态、低延迟,通过技术与生态的双重优化,为边缘 AI 场景提供了高性价比的解决方案。
3、开源模型 加速创新
除了上述提到Jetson AI Lab推出的LLava(Live LLaMA Video-Text Adapter)项目以外,还有如下NGC (NVIDIA GPU Cloud)和NVIDIA Model Zoo的开源模型。Nvidia在开源领域持续深耕,以及详细的技术指导大幅降低AI研发门槛,助力了全球开发者加速创新。更通过开源社区协作,推动硬件与算法协同优化,为人工智能普及奠定坚实基础。Nvidia的开放策略不仅加速了技术迭代,更重塑了行业协作范式,堪称开源精神的典范践行者。
| 开源 模型 | NGC (NVIDIA GPU Cloud) | NVIDIA Model Zoo |
| 简介 | 提供预训练模型、工具包和容器镜像,加速开发流程。 | 开源模型库,支持 Jetson 直接部署。 |
| 模型类型 | 目标检测:YOLOv8、SSD-ResNet50。 图像分割:U-Net、Mask R-CNN。 语音识别:Tacotron 2、WaveGlow。 | 分类:ResNet-18、MobileNet-SSD。 分割:FCN-8s、UNet。 检测:Faster R-CNN、YOLOv7。 |
| 官方链接 |
四、总结:性价比与性能的完美平衡
Jetson Orin Nano Super以249美元的售价(前代499美元),提供堪比专业级设备的AI算力,足够成为学生、创客与中小企业的理想选择。而且即插即用特性与丰富的软件生态,大幅降低AI开发门槛;而通过刷机升级至Super模式,对于老用户来说更是无缝过渡。非常适合想要学习和正在学习AI开发领域与嵌入式智能人工领域相关的开发者学习者!

















 1659
1659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









