







DTLD整体结构为:CNN + Transformer-decoder。主要改进是针对decoder,包含四个部分:
- Query初始化方法,基于CNN的顶层特征接回归头,使用FC后的特征作为初始化;
- 在Cross-attention前,增加self-attention;
- 引入Deformable Attention,并将初始的reference point替换为CNN特征回归的粗结果;
- 在decoder中,基于deformable attention机制,迭代更新feature map。
目录
摘要
cascaded transformers with deformable attention mechnism
novel decoder that refines image features and landmark positions simultaneously.
方法
DTLD主要包含三个部分:1)backbone:提取图片特征;2)query initialization module:用于decoder中Query的初始化;3)decoder module:预测关键点。

Backbone
- ImageNet pre-trained ResNet-18;
- 输出式Pyramid features,包含4层:F_1, F_2, F_3, F_4,分别对应降采样率4, 8, 16, 32;
- 特征接1 x 1卷积,将他们映射到相同通道数;
- 特征展平为一维,并拼接在一起,作为memory feature,维度为M ∈ M x C,M是展平特征的长度和。
Query Initialization
- 通常设置是learnable query matrix Q,并且随机初始化;
- 本文中query matrix设置为N x C,其中N是点位数量,C是特征维度。DTLD基于F_4特征,初始化query matrix:Q_0 = FC(F_4);
- query features后接另一个FC层和Sigmoid函数,用于预测N个点位坐标:Y_0 = σ(FC(Q_0)),作为初始化点位坐标,后续会用作initial reference points(Deformable Attention中用于特征采样),维度为N x 2。
Decoder Module
- 包含T个decoder layer,每个decoder layer的输入包含:query matrix Q, memory feature M和reference points R,输出是:相较于R的偏移量。
- 本文设计了两种decoder:basic decoder和parallel decoder,两者的区别在于是否更新memory feature;
Basic Decoder
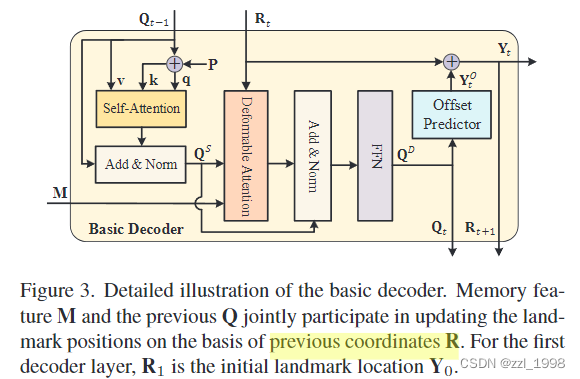
- Self-attention layer:输入为Q^P, Q^P和Q,其中Q^P = Q + P,P是learnable position embedding。
- Deformable Attention layer:输入为Self-Attention layer的输出Q^S和memory feature M。与通常的Cross-attention不同,本文使用deformable attention,也即不使用完整特征图作为输入,而是在特征图上采样:

- 具体来说,x_ik是在memory feature M的p_ik位置上采样到的特征, 其中,采样点p_ik = r_i + δp_ik,r_i是reference point,是前decoder层计算的坐标,δp_ik = FC(q_i)是采样偏移量,q_i是query matrix。β_ik = σ(FC(q_i))
- Offset Predictor:是3层MLP,输入为Deformable Attention layer的输出Q^D,输出为坐标偏移量Y^o,输出坐标为Y_t = σ(Y^o + R_t)。
- 在每个decoder层中,Q = Q^D和Y会被更新。
Parallel Decoder
- 相较于DETR和deformable DETR,DTLD去除了encoder。然后,实验表明encoder是有益处的,因此本文提出parallel decoder,使得memory feature也被同步更新。

- 将level embedding和pixel position embedding,添加到memory feature M中:M^P = M + P';
- 借助deformable attention,更新M^P;
- 在Cross Attention中,会将M^P和Q^S concat在一起。
Training Target
- L1损失,监督T个decoder层的输出
实验
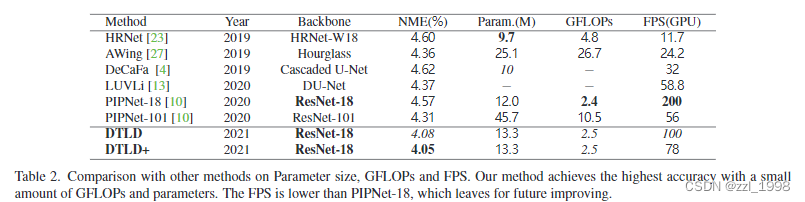
Comparison with the SOTA

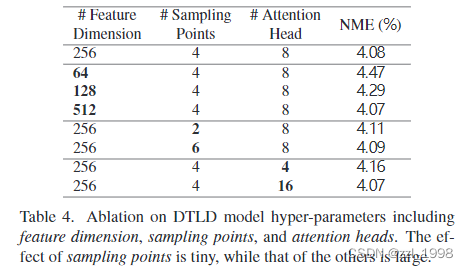
Ablation Studies
- Q_0初始化和Self-Attn对结果影响很大

- 超参对结果影响大
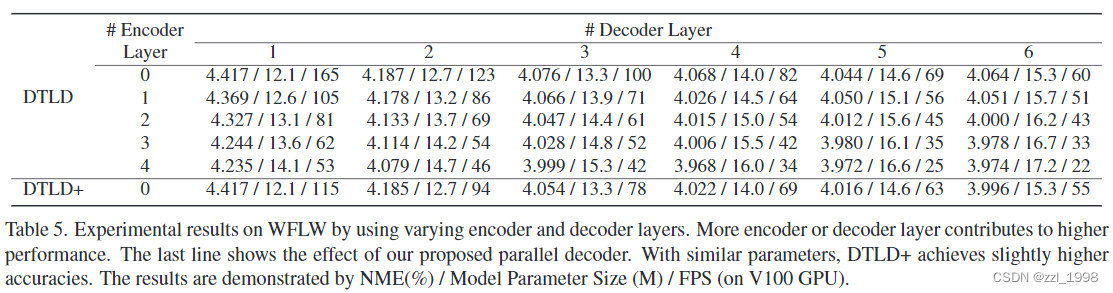
- decoder层数越多效果越好
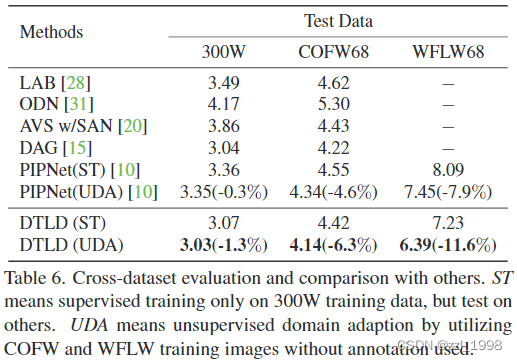
- Cross-dataset Evaluation















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









