







Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
Xiaohan Ding 1* Xiangyu Zhang 2† Yizhuang Zhou 2
Jungong Han 3 Guiguang Ding 1 Jian Sun 2
1 Beijing National Research Center for Information Science and Technology (BNRist);
School of Software, Tsinghua University, Beijing, China
2 MEGVII Technology
3 Computer Science Department, Aberystwyth University, SY23 3FL, UK
悼念 孙剑博士
CVPR 2022 : https://export.arxiv.org/pdf/2203.06717.pdf
Code/models : https://github.com/megvii-research/ RepLKNet
Abstract
We revisit large kernel design in modern convolutional neural networks (CNNs). Inspired by recent advances in vision transformers (ViTs), in this paper, we demonstrate that using a few large convolutional kernels instead of a stack of small kernels could be a more powerful paradigm. We suggested five guidelines, e.g., applying re-parameterized large depth-wise convolutions, to design efficient highperformance large-kernel CNNs. Following the guidelines, we propose RepLKNet, a pure CNN architecture whose kernel size is as large as 31×31, in contrast to commonly used 3×3. RepLKNet greatly closes the performance gap between CNNs and ViTs, e.g., achieving comparable or superior results than Swin Transformer on ImageNet and a few typical downstream tasks, with lower latency. RepLKNet also shows nice scalability to big data and large models, obtaining 87.8% top-1 accuracy on ImageNet and 56.0% mIoU on ADE20K, which is very competitive among the state-of-the-arts with similar model sizes. Our study further reveals that, in contrast to small-kernel CNNs, largekernel CNNs have much larger effective receptive fields and higher shape bias rather than texture bias.
本文重新审视现代卷积神经网络 (CNNs) 中的大卷积核设计。
受 ViTs 的启发,本文演示了使用几个大型卷积核--而不是堆叠小卷积核--可能是一种更强大的范例。 本文提出了 5 条指导原则,例如,应用重新参数化的大深度卷积来设计高效高性能的大内核cnn。 遵循这些准则,本文提出了 RepLKNet,一个纯粹的 CNN 架构,其内核大小为 31×31,而不是常用的 3×3。 RepLKNet 极大地缩小了 CNNs 和 ViT 之间的性能差距,例如,在 ImageNet 和一些典型的下游任务上实现了与 Swin Transformer 相当或更好的结果,并且延迟更低。 RepLKNet 对大数据和大型模型的可扩展性也很好,在 ImageNet 上获得了 87.8% 的 top-1 精度,在 ADE20K 上获得了 56.0% 的 mIoU,在同类模型尺寸的尖端技术中非常有竞争力。 研究进一步揭示,与小核 CNN 相比,大核 CNN 有更大的有效感受野和更高的形状偏差而不是纹理偏差。
Introduction
大家都清楚,最近,CNNs 受到 ViT 的极大挑战,ViT 在图像分类和表示学习等视觉任务以及后续的目标检测、语义分割和图像恢复等视觉任务上都表现出领先的性能。为什么 ViT 非常强大?有研究认为 ViT 中的多头自注意 (MHSA) 机制起着关键作用。他们提供的实证结果表明,MHSA 具有更灵活的[52],能够 (更少的 inductive bias),对失真更稳健,或能够建模长距离依赖关系。但一些工作对 MHSA 的必要性提出了挑战 [121],将 ViT 的高性能归因于适当的构建块 ( building blocks ) [34]和/或动态稀疏权值。更多的文献从不同的角度解释了 ViTs的优越性。
例如:

ViT 强大,究竟是由于 A 还是 B ?
三个证据都指向 A:7x7,MLP,pooling 都是采用了更大的感受野。
本文专注于一个观点:建立大的感受野的方式。在 ViT 中,MHSA 通常被设计为全局的或局部的,但具有较大的核,因此单个 MHSA 层的每个输出都能够从一个大的区域收集信息。然而,大核在 CNN 中并不普遍使用 (除了第一层)。相反,一种典型的方式是使用许多小空间卷积的堆栈(例如,3x3) 来扩大最先进的 CNN 的感受野。只有一些老式的网络,如 AlexNet [55], ineptions [81 83] 和一些由神经结构搜索衍生而来的架构 [39,45,58,122] 采用大空间卷积 (其大小大于 5) 作为主要部分。上述观点自然引出了一个问题:如果在传统的 CNN 中使用几个大核而不是很多小核,会怎么样? 大卷积核或构建大感受野的方式是否是拉近 CNNs 和 ViTs 之间的性能差距的关键?

不是 !!!
证据见下图:


为了回答这个问题,本文系统地探索了 CNNs 的大内核设计。本文遵循一个非常简单的理念:只在传统网络中引入大的深度卷积,其大小从 3x3 到 31x31,尽管存在其他的选择,通过单个或几个层引入大的接收域,例如特征金字塔 [96],膨胀卷积 [14,106,107] 和可变形卷积 [24]。通过一系列的实验,总结了 5 条有效利用大卷积的经验准则:
3. Guidelines
1) 非常大的核在实践中仍然可以有效;
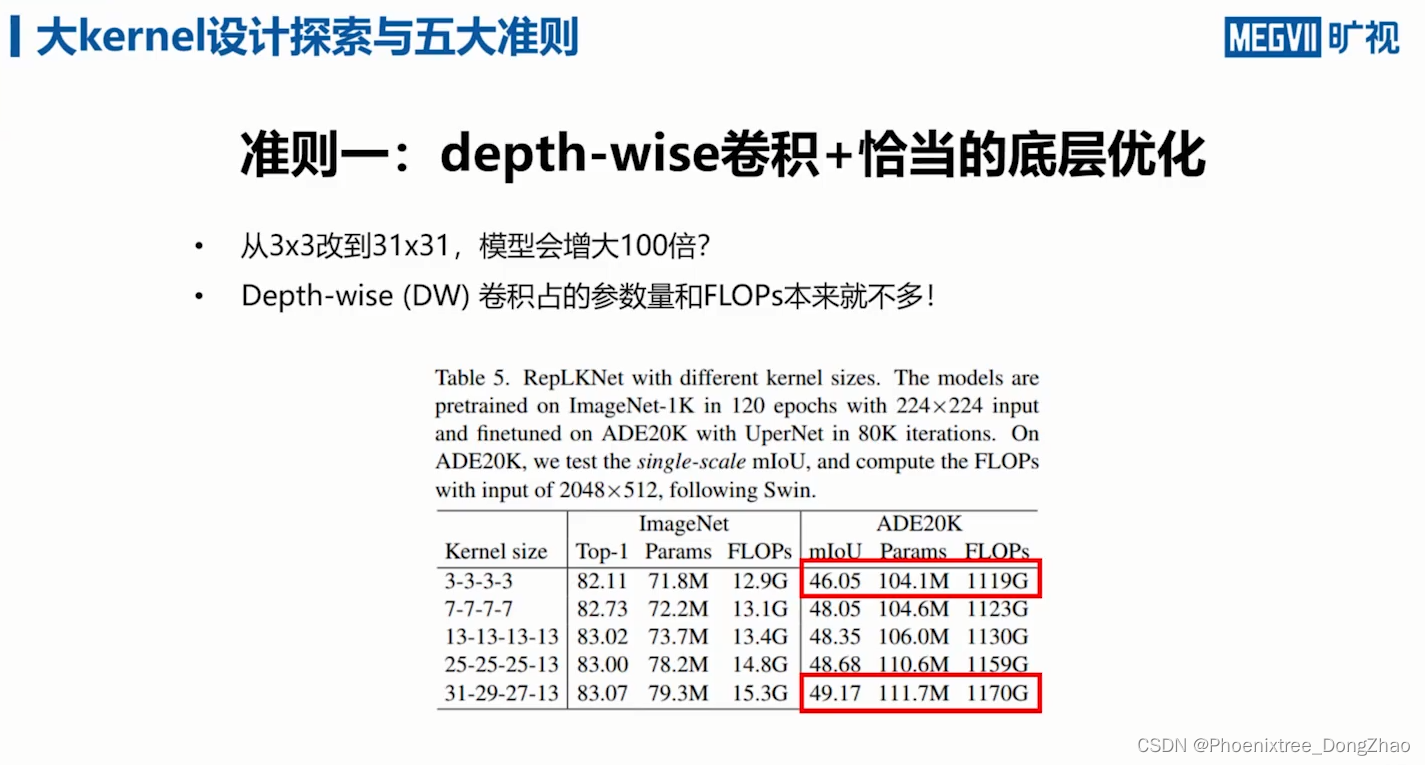

2) identity shortcut 对具有超大卷积核的网络尤为重要;

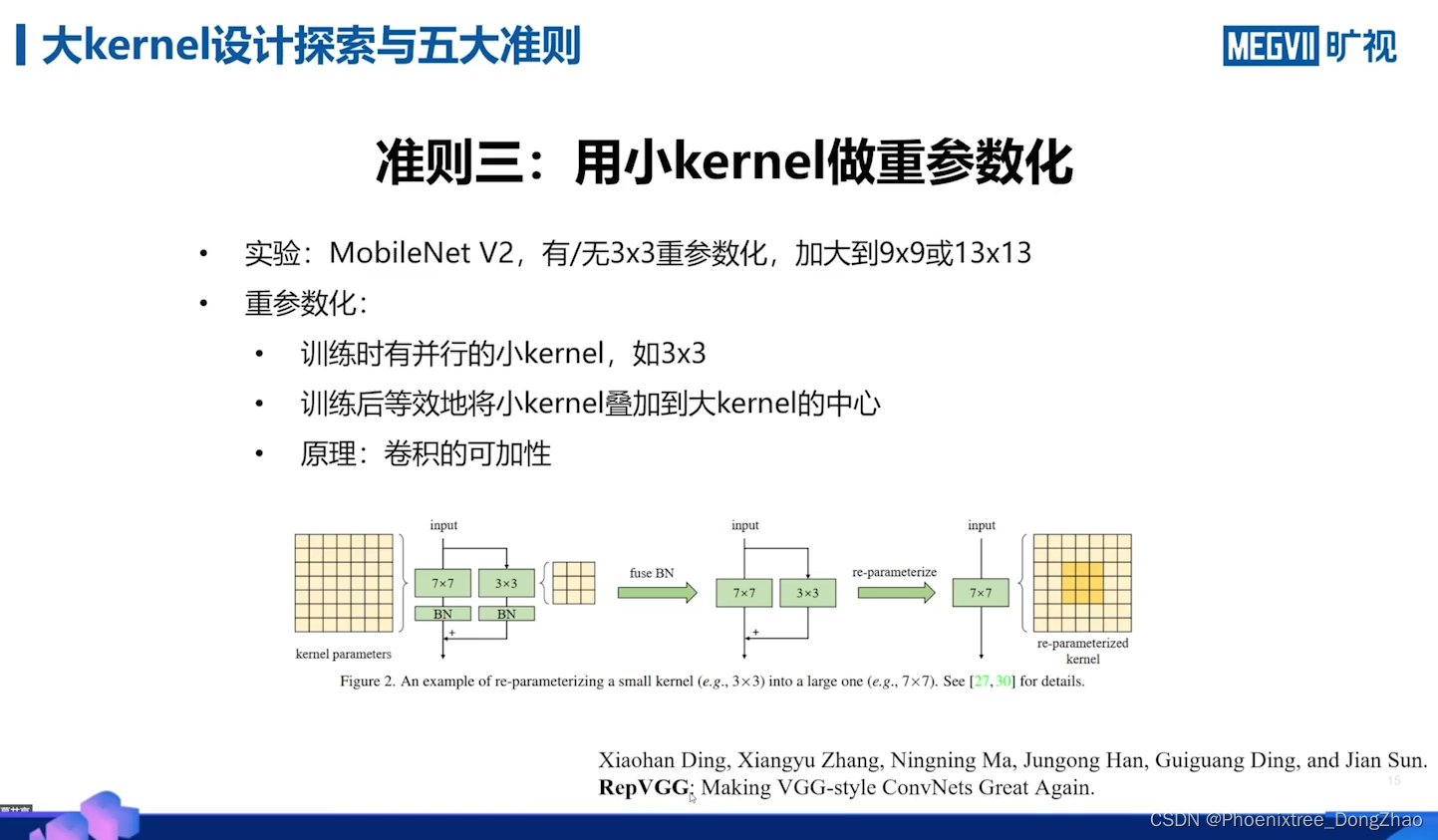
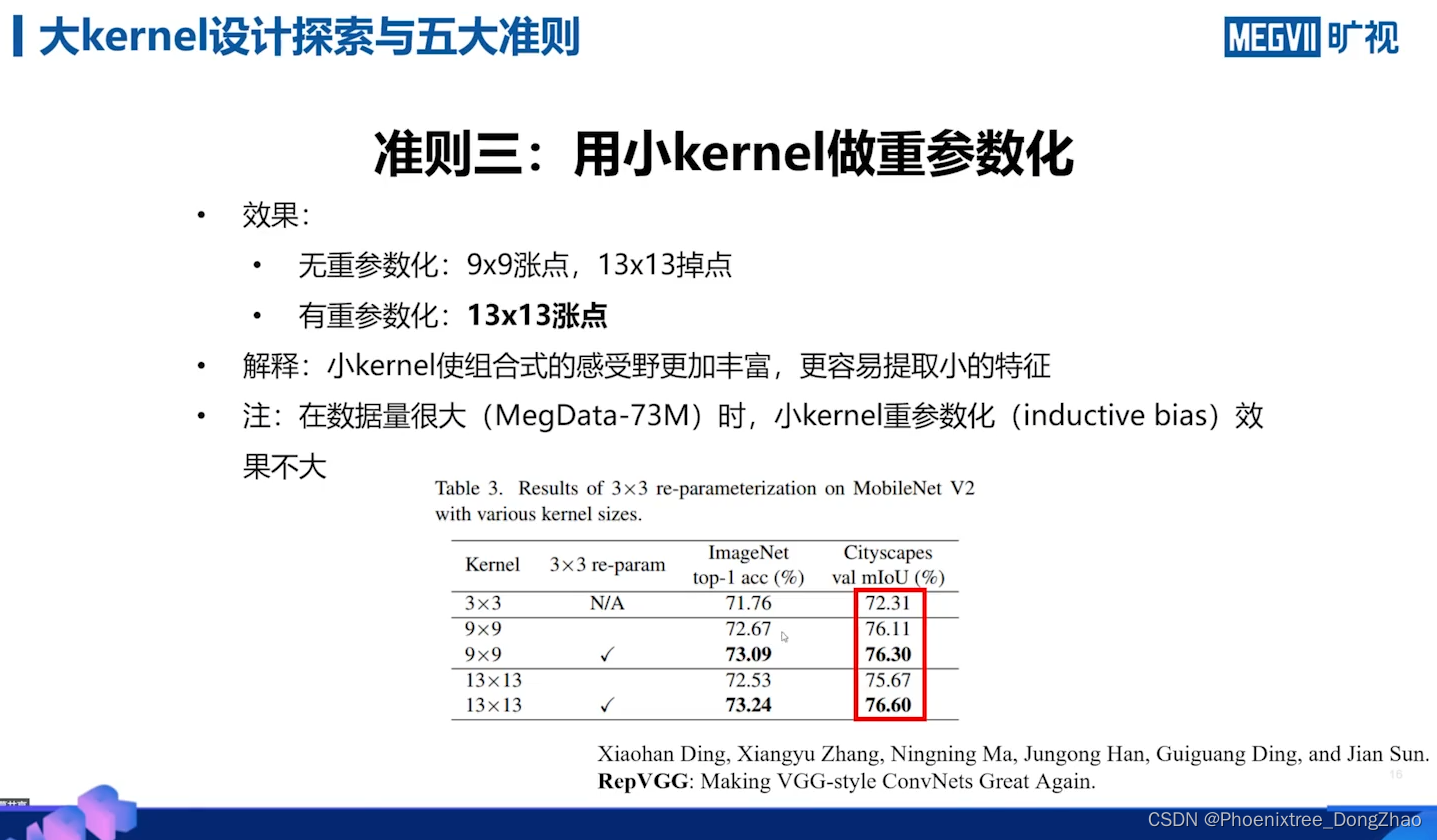
3) 用小的卷积核重新参数化有助于弥补优化问题;
4) 与 ImageNet 相比,大卷积核对下游任务的促进作用更大;
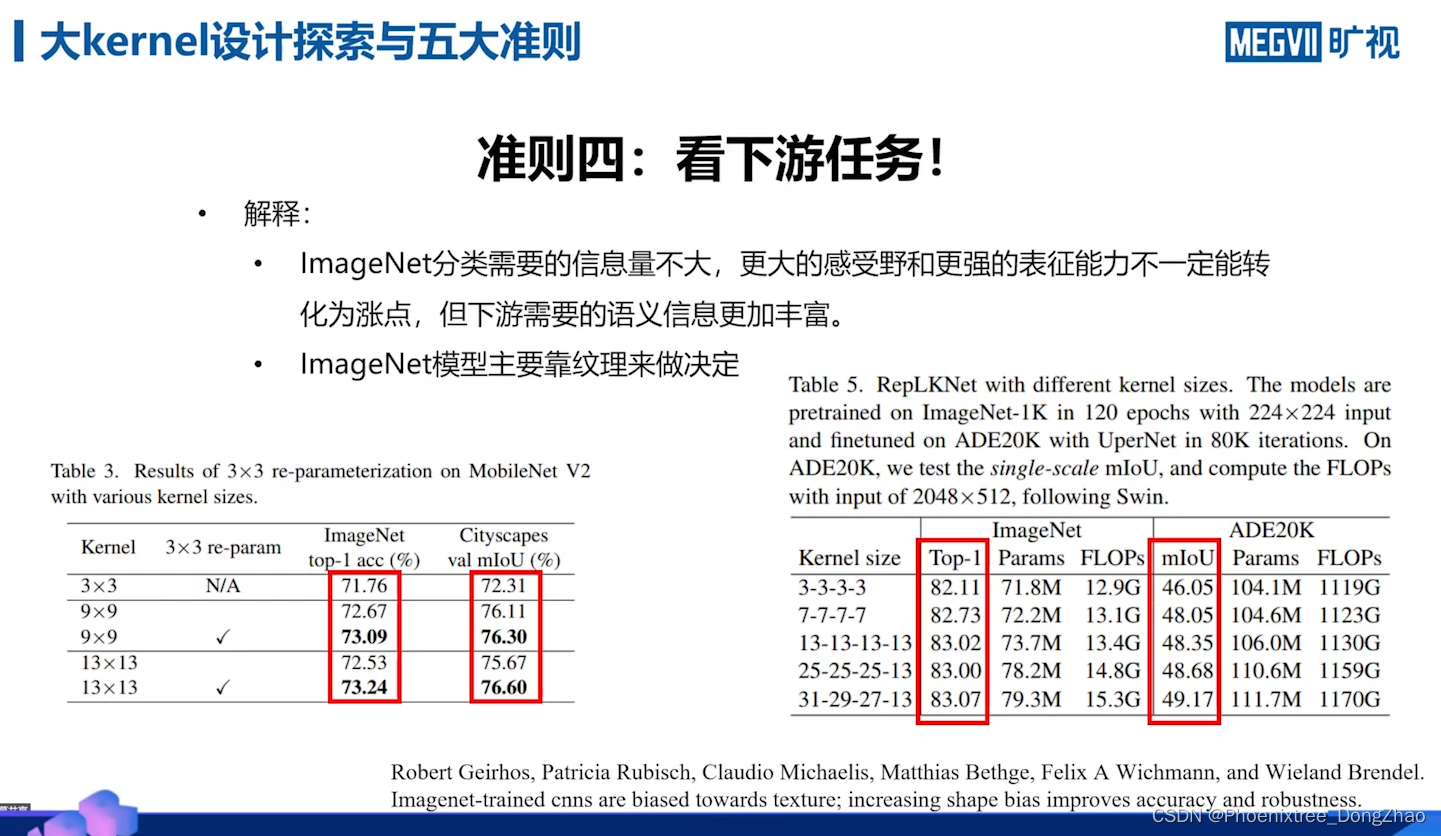
(提出的理论方法在 ImageNet 的分类问题上有些情况下掉电,但作者认为不重要。有证据显示,在分类上好的模型,未必在回归问题上表现更好;反之亦然。)
5) 即使在小的特征映射上,大的卷积核也是有用的:

(不符合平移不变性,但谁说一定要符合平移不变性才能提高性能呢?不符合未必掉点!)
基于上述准则,本文提出了一种新的架构,名为 RepLKNet,它是一个纯 CNN,其中采用重新参数化的大卷积来建立大的感受野。本文的网络总体上遵循 Swin Transformer[61] 的宏观架构,并进行了少量修改,同时用大深度卷积替换多头自注意力。本文主要对中型和大型模型进行基准测试,因为vit过去被认为在大数据和模型上超过了cnn。在ImageNet分类上,本文的基线 (与 Swin-B 的模型大小相似),其内核大小高达 31x31,仅在 ImageNet1K 数据集上训练就实现了 84.8% 的 top-1 精度,比 Swin-B 好 0.3%,但在延迟方面效率更高。
本文打破了很多常规认知:

上述截图:

















 1994
1994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









