










 本文围绕ChatGLM3展开,介绍其性能突破、新功能、智能体算法等特点,还涵盖安装方法,包括环境安装、模型微调、推理测试及低成本部署,最后给出实战应用,如在线测试和进阶用法,如基于不同框架和数据集的微调训练。
本文围绕ChatGLM3展开,介绍其性能突破、新功能、智能体算法等特点,还涵盖安装方法,包括环境安装、模型微调、推理测试及低成本部署,最后给出实战应用,如在线测试和进阶用法,如基于不同框架和数据集的微调训练。
LLMs之ChatGLM-3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装和使用方法、案例应用(实现多轮对话能力(Chat)、工具调用能力(Function Call)、代码执行能力(Code Interpreter)→进而实现 Agent 复杂任务场景)之详细攻略
导读:2023年10月27日,智谱AI在2023中国计算机大会上推出了全自研的第三代基座大模型ChatGLM3及其相关系列产品,这是继推出千亿基座的对话模型ChatGLM和ChatGLM2之后的重大突破。ChatGLM3采用了独创的多阶段增强预训练方法,排名国内同尺寸模型中首位。ChatGLM3具备多模态理解、代码生成和执行、网络搜索增强等功能,性能和部署方面也有显著提升。智谱清言作为ChatGLM3的赋能产品,成为国内首个具备代码交互能力的大模型。
>>ChatGLM3的性能突破—排名第一:ChatGLM3采用了独创的多阶段增强预训练方法,使训练更为充分。在44项中英文公开数据集测试中,ChatGLM3在国内同尺寸模型中排名第一。与ChatGLM2相比,ChatGLM3在多个指标上有显著提升,包括MMLU提升36%、CEval提升33%、GSM8K提升179%、BBH提升126%。
>>ChatGLM3的新功能—看齐GPT-4V:ChatGLM3实现了若干全新功能的迭代升级,包括多模态理解能力的CogVLM-看图识语义,在多个国际标准图文评测数据集上取得SOTA;代码增强模块Code Interpreter根据用户需求生成代码并执行,自动完成数据分析、文件处理等复杂任务;网络搜索增强WebGLM-接入搜索增强,能自动根据问题在互联网上查找相关资料并在回答时提供参考相关文献或文章链接。ChatGLM3的语义能力与逻辑能力得到了极大的增强。
>> ChatGLM3采用全新Agent智能体算法:ChatGLM3集成了自研的AgentTuning技术,提升了模型智能体能力,尤其在智能规划和执行方面,相比于ChatGLM2提升了1000%。
>>ChatGLM3的性能和部署—可手机端部署:ChatGLM3还推出了可手机部署的端测模型ChatGLM3-1.5B和ChatGLM3-3B,支持多款手机和车载平台,甚至支持移动平台上CPU芯片的推理,速度可达20 tokens/s。
>>ChatGLM3的推理性能:ChatGLM3当前的推理框架在相同硬件、模型条件下,相较于目前最佳的开源实现,推理速度提升了2-3倍,推理成本降低一倍,每千tokens仅0.5分,成本最低。
>>智谱清言的升级:在ChatGLM3的赋能下,生成式AI助手智谱清言成为国内首个具备代码交互能力的大模型产品(Code Interpreter)。智谱清言还具有搜索增强能力,可以整理出相关问题的网上文献或文章链接,并直接给出答案。
目录
LLMs之GLM-130B/ChatGLM-1:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读
LLMs之ChatGLM-2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
LLMs之ChatGLM-3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略
LLMs之ChatGLM:ChatGLM系列模型(ChatGLM-1/ChatGLM-2/ChatGLM-3/ChatGLM-4)网络架构详解及其对比
LLMs之GLM:《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读
LLMs之ChatGLM3:inference.py文件解读—实现一个简单的基于ChatGLM3的交互式语言模型+根据用户输入文本生成相应的响应
LLMs之FineTuning:LLaMA-Factory(通过一站式网页界面快速上手)的简介、安装、使用方法(微调ChatGLM3等)之详细攻略
4、三大能力:Chat对话能力、Tool工具调用、CodeInterpreter代码解释器
5、解读工具调用能力的实现:构建 System Prompt→提出问题→调用工具生成回复
1、根据ChatGLM3每一步的响应,深度探讨和剖析实现工具调用的逻辑思路
T1、基于官方Demo利用单卡GPU并采用LORA微调:源自GitHub
T2、基于官方Demo微调:单论对话对微调+多轮对话微调【可包括工具调用能力】
参考显存用量:P-Tuning V2需要21G显存、全量微调需要4*80G、8bit需要12G、4bit需要7.6G
(1)、对于数据文件的样例采用如下格式:仅希望微调模型的对话能力、微调模型的对话和工具能力
对于输入输出格式的微调,可使用 inference.py 进行基本的推理验证。
T3、基于官方Demo利用云服务器采用P-Tuning v2微调
(1)、编写代码:调用 ChatGLM 模型来生成对话,会自动下载模型实现和参数
LLMs之ChatGLM3:inference.py文件解读—实现一个简单的基于ChatGLM3的交互式语言模型+根据用户输入文本生成相应的响应
T2、基于 Streamlit 的网页版 demo:更流畅!
T3、采用基于LangChain框架实现ChatGLM3的对话生成、工具调用功能
LLMs之LangChain之ChatGLM3:使用LangChain框架基于本地部署的ChatGLM3的API端点的URL(设置url)开启交互并实现文本补全任务实战代码之详细攻略
LLMs之ToolAgent:基于LangChain框架采用ChatGLM3通过调用自定义的工具实现ToolAgent的功能(arxiv论文查询、天气查询、数值计算等单工具调用或者多工具调用)输出详解
>> 请问,你作为ChatGLM3,和此前的ChatGLM2版本有什么重大区别?
>> 请问,你作为ChatGLM3-6B,你是怎么进行预训练的,主要实现的核心过程包括哪些?
帮我梳理整个文档《Baichuan2-technical-report3》
GLM模型系列
LLMs之GLM-130B/ChatGLM-1:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读
LLMs之GLM-130B/ChatGLM:《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》翻译与解读-CSDN博客
LLMs之ChatGLM-2:ChatGLM2-6B的简介、安装、使用方法之详细攻略
LLMs之ChatGLM2:ChatGLM2-6B的简介、安装、使用方法之详细攻略_一个处女座的程序猿的博客-CSDN博客
LLMs之ChatGLM-3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介(多阶段增强+多模态理解+AgentTuning技术)、安装、使用方法之详细攻略-CSDN博客
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略
LLMs之GLM-4:GLM-4的简介(全覆盖【对话版即ChatGLM4的+工具调用+多模态文生图】能力→Agent)、安装和使用方法、案例应用之详细攻略-CSDN博客
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略
MLM之GLM-4:GLM-4-9B的简介、安装和使用方法、案例应用之详细攻略-CSDN博客
阶段性综合对比
LLMs之ChatGLM:ChatGLM系列模型(ChatGLM-1/ChatGLM-2/ChatGLM-3/ChatGLM-4)网络架构详解及其对比
https://yunyaniu.blog.csdn.net/article/details/139816980
LLMs之GLM:《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读
LLMs之GLM:《ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools》翻译与解读-CSDN博客
相关文章
LLMs之ChatGLM3:finetune.py文件解读—基于数据集(多轮对话格式/输入-输出格式)来微调ChatGLM3-6B模型来适应特定的任务(如对话系统)—参数解析和配置→加载预训练模型和分词器(P-tuning v2技术+模型量化技术)→数据预处理(支持不同格式的训练数据【多轮对话格式/输入-输出格式】)→初始化数据收集器和训练器→模型训练(基于PyTorch分布式框架+梯度累积+梯度检查点技术等,显存21G/对比推理需要13G)
LLMs之ChatGLM3:inference.py文件解读—实现一个简单的基于ChatGLM3的交互式语言模型+根据用户输入文本生成相应的响应
https://yunyaniu.blog.csdn.net/article/details/135040296
LLMs之ChatGLM3:ChatGLM3源码解读(finetune_hf.py)微调模型实现生成任务——初始化模型训练环境→加载数据→配置模型→微调训练模型(支持SFT/Ptuning_v2/LoRA+可从检查点恢复)→模型评估(BLEU/ROUGE等)
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介—“对话格式”功能介绍(推理系统如何解析参数/采用Python代码形式/编写工具调用的代码/Manual Mode)、推理演示(Chat/Tool/Code Interpreter)、微调(AdvertiseGen/ToolAlpaca)实现之图文教程攻略
https://yunyaniu.blog.csdn.net/article/details/134342685
LLMs之FineTuning:LLaMA-Factory(通过一站式网页界面快速上手)的简介、安装、使用方法(微调ChatGLM3等)之详细攻略
https://yunyaniu.blog.csdn.net/article/details/134098674
LLMs之ChatGLM3:基于LLaMA-Factory利用自定义json格式指令数据集采用LoRA微调ChatGLM3训练(合并模型可作为基模型进而实现二次微调)+微调(CLI/WebUI)+推理的案例实战
https://yunyaniu.blog.csdn.net/article/details/134236595
ChatGLM3的简介
2023年10月27日,ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型。 ChatGLM3 开源模型旨在与开源社区一起推动大模型技术发展,恳请开发者和大家遵守开源协议,勿将开源模型和代码及基于开源项目产生的衍生物用于任何可能给国家和社会带来危害的用途以及用于任何未经过安全评估和备案的服务。目前,本项目团队未基于 ChatGLM3 开源模型开发任何应用,包括网页端、安卓、苹果 iOS 及 Windows App 等应用。
尽管模型在训练的各个阶段都尽力确保数据的合规性和准确性,但由于 ChatGLM3-6B 模型规模较小,且模型受概率随机性因素影响,无法保证输出内容的准确。同时模型的输出容易被用户的输入误导。本项目不承担开源模型和代码导致的数据安全、舆情风险或发生任何模型被误导、滥用、传播、不当利用而产生的风险和责任。
GitHub地址:GitHub - THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型
1、ChatGLM3-6B的特点
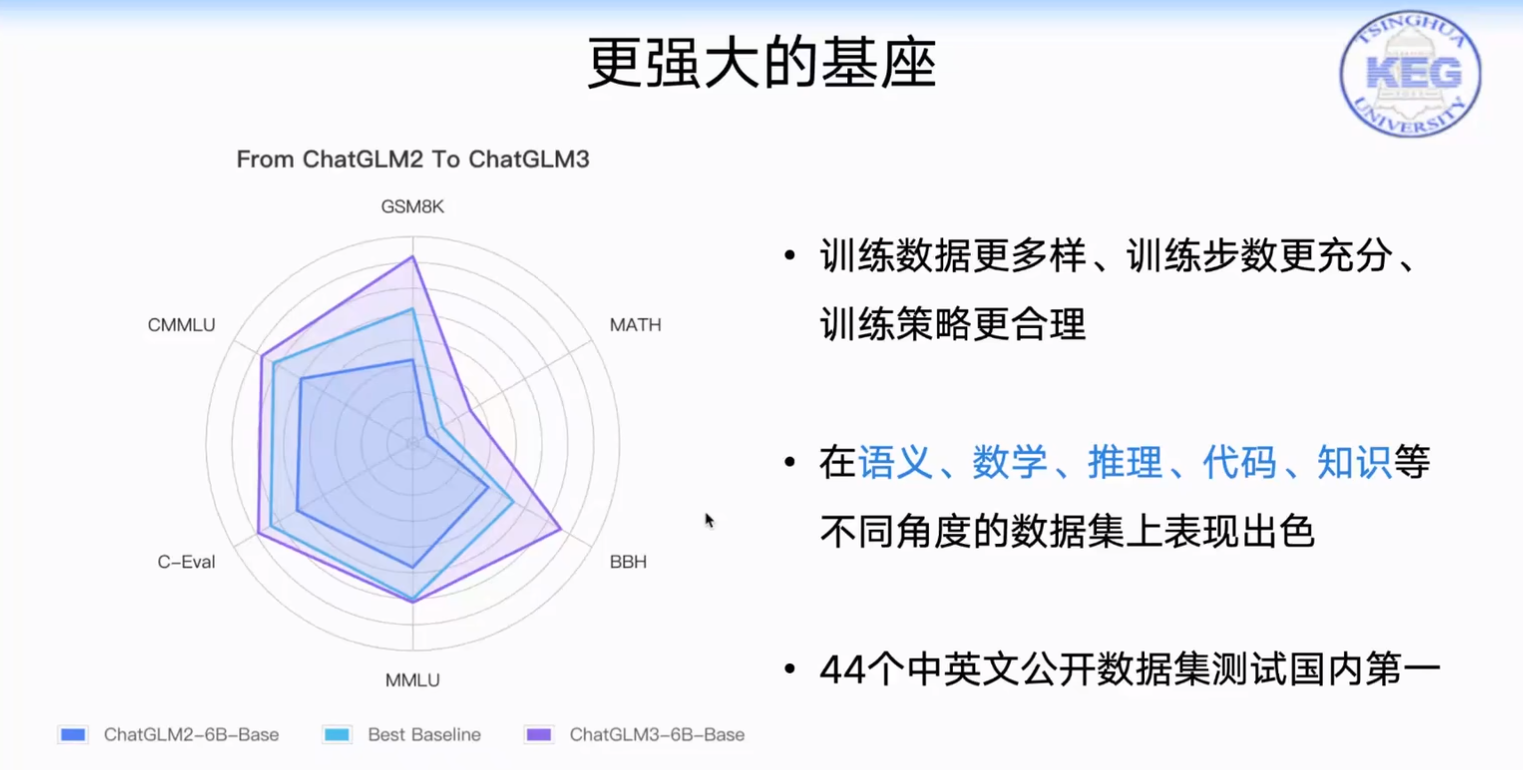
ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
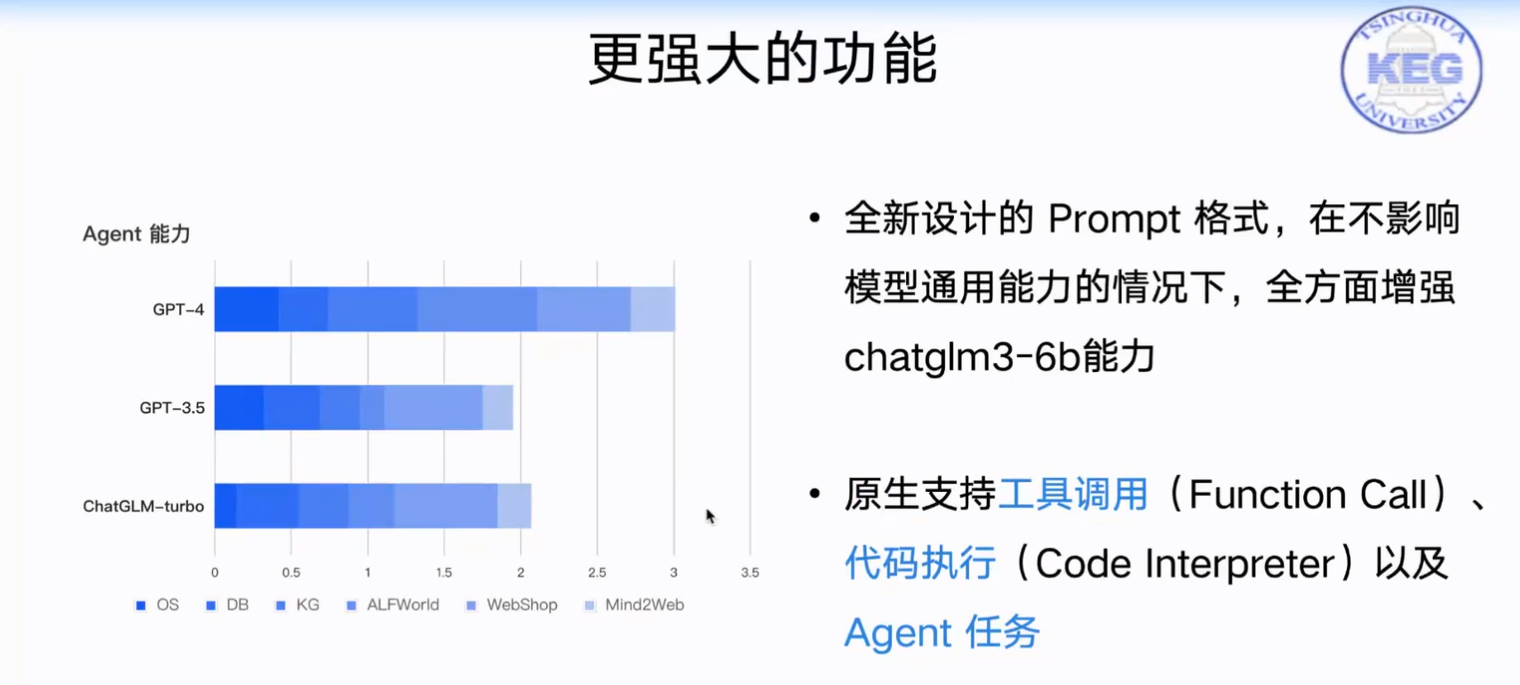
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
ChatGLM3-6B地址:https://huggingface.co/THUDM/chatglm3-6b
2、模型列表
| Model | Seq Length | Download |
|---|---|---|
| ChatGLM3-6B | 8k | HuggingFace | ModelScope |
| ChatGLM3-6B-Base | 8k | HuggingFace | ModelScope |
| ChatGLM3-6B-32K | 32k | HuggingFace | ModelScope |
3、评测结果
(1)、典型任务
我们选取了 8 个中英文典型数据集,在 ChatGLM3-6B (base) 版本上进行了性能测试。
| Model | GSM8K | MATH | BBH | MMLU | C-Eval | CMMLU | MBPP | AGIEval |
|---|---|---|---|---|---|---|---|---|
| ChatGLM2-6B-Base | 32.4 | 6.5 | 33.7 | 47.9 | 51.7 | 50.0 | - | - |
| Best Baseline | 52.1 | 13.1 | 45.0 | 60.1 | 63.5 | 62.2 | 47.5 | 45.8 |
| ChatGLM3-6B-Base | 72.3 | 25.7 | 66.1 | 61.4 | 69.0 | 67.5 | 52.4 | 53.7 |
Best Baseline 指的是模型参数在 10B 以下、在对应数据集上表现最好的预训练模型,不包括只针对某一项任务训练而未保持通用能力的模型。
对 ChatGLM3-6B-Base 的测试中,BBH 采用 3-shot 测试,需要推理的 GSM8K、MATH 采用 0-shot CoT 测试,MBPP 采用 0-shot 生成后运行测例计算 Pass@1 ,其他选择题类型数据集均采用 0-shot 测试。
(2)、 LongBench评测集的测试
我们在多个长文本应用场景下对 ChatGLM3-6B-32K 进行了人工评估测试。与二代模型相比,其效果平均提升了超过 50%。在论文阅读、文档摘要和财报分析等应用中,这种提升尤为显著。此外,我们还在 LongBench 评测集上对模型进行了测试,具体结果如下表所示
| Model | 平均 | Summary | Single-Doc QA | Multi-Doc QA | Code | Few-shot | Synthetic |
|---|---|---|---|---|---|---|---|
| ChatGLM2-6B-32K | 41.5 | 24.8 | 37.6 | 34.7 | 52.8 | 51.3 | 47.7 |
| ChatGLM3-6B-32K | 50.2 | 26.6 | 45.8 | 46.1 | 56.2 | 61.2 | 65 |
4、三大能力:Chat对话能力、Tool工具调用、CodeInterpreter代码解释器
| Chat | Chat对话能力 |
| Tool | Tool工具调用:利用自然语言去调用外部工具,比如调用python函数或者Web API,来拓展大模型的能力并且能够接入各种实际业务;
|
| CodeInterpreter | CodeInterpreter代码解释器:输入自然语言,模型得到对应生成的代码,并自动执行输出结果; |
LLMs之ChatGLM3:ChatGLM3/ChatGLM3-6B的简介—“对话格式”功能介绍(推理系统如何解析参数/采用Python代码形式/编写工具调用的代码/Manual Mode)、推理演示(Chat/Tool/Code Interpreter)、微调(AdvertiseGen/ToolAlpaca)实现之图文教程攻略
https://yunyaniu.blog.csdn.net/article/details/134342685
5、解读工具调用能力的实现:构建 System Prompt→提出问题→调用工具生成回复
本文档将介绍如何使用 ChatGLM3-6B 进行工具调用。目前只有 ChatGLM3-6B 模型支持工具调用,而 ChatGLM3-6B-Base 和 ChatGLM3-6B-32K 模型不支持。
地址:https://github.com/THUDM/ChatGLM3/blob/main/tool_using/README.md
LLMs之Tool之ChatGLM3:解读ChatGLM3的除正常的多轮对话外的两大新功能—工具调用(Function Call)+代码执行(Code Interpreter)核心原理详解—工具调用(事先定义工具及其参数→对话触发工具调用→模型确定调用工具→推理系统实现工具调用【解析参数三法(python内置eval()函数/手动解析AST/Transformers Agents)】→模型接受反馈并总结再生成)
https://yunyaniu.blog.csdn.net/article/details/137607017
T1、基于官方demo实现ChatGLM3的工具调用功能
1、根据ChatGLM3每一步的响应,深度探讨和剖析实现工具调用的逻辑思路
ChatGLM3的安装
1、环境安装:需要 Python 3.10 或更高版本
| 下载项目文件 | 首先需要下载本仓库: git clone https://github.com/THUDM/ChatGLM3 cd ChatGLM3 |
| 下载模型 | 下载模型: |
| 安装依赖 | 然后使用 pip 安装依赖: pip install -r requirements.txt 其中 transformers 库版本推荐为 4.30.2,torch 推荐使用 2.0 及以上的版本,以获得最佳的推理性能。 |
2、模型微调
T1、基于官方Demo利用单卡GPU并采用LORA微调:源自GitHub
LLMs之ChatGLM3:基于AdvertiseGen广告数据集采用单卡GPU 利用LORA 高效微调(显存24G+内存16G)ChatGLM3-6B模型实现广告生成能力——切分数据集→模型微调(支持SFT/Ptuning_v2/LoRA+可从检查点恢复)+模型评估(BLEU/ROUGE等)→模型推理
https://yunyaniu.blog.csdn.net/article/details/137648790
T2、基于官方Demo微调:单论对话对微调+多轮对话微调【可包括工具调用能力】
本文内容资料(微调部分+部署部分)已被重新总结与梳理迁移
LLMs之Tool之ChatGLM3-6B:模型微调实战(单论对话对微调+多轮对话微调【可包括工具调用能力】)——基于输入输出(prompt-response)格式AdvertiseGen、多轮对话格式数据集(AdvertiseGen/ToolAlpaca,模板四要素【system-user-assistant-observation-interpreter】)→微调模型(利用全量微调/P-Tuning v2/LORA【另一个文件】微调+支持多卡/可继续微调)+仅微调模型对话额能力{system-user-assistant}/同时微调对话能力和工具调用能力{tools→system-user-assistant-observation}→模型量化→低成本部署(模型量化4-bit /CPU 部署仍需32G/Mac 部署需13G/多卡部署需安装accelerate库)→实现多轮对话能力+工具调用能力+代码执行能力
https://yunyaniu.blog.csdn.net/article/details/137412422
本目录提供 ChatGLM3-6B 模型的微调示例,包括全量微调和 P-Tuning v2。格式上,提供多轮对话微调样例和输入输出格式微调样例。
地址:https://github.com/THUDM/ChatGLM3/blob/main/finetune_demo/README.md
LLMs之ChatGLM3:finetune_pt_DIY.sh文件解读(脚本命令参数/模型微调核心参数)—实现基于PyTorch框架微调训练大型语言模型
LLMs之ChatGLM3:finetune_pt_DIY.sh文件解读(脚本命令参数/模型微调核心参数)—实现基于PyTorch框架微调训练大型语言模型-CSDN博客
(1)、配置环境:下载依赖和下载模型
| 下载依赖 | 运行示例需要 python>=3.9,除基础的 torch 依赖外,示例代码运行还需要依赖 pip install transformers==4.30.2 accelerate sentencepiece astunparse deepspeed |
| 下载模型 | 如果将模型下载到了本地,本文和代码中的 THUDM/chatglm3-6b 字段均应替换为相应地址以从本地加载模型。 |
参考显存用量:P-Tuning V2需要21G显存、全量微调需要4*80G、8bit需要12G、4bit需要7.6G
| 高效微调 | P-Tuning V2 PRE_SEQ_LEN=128, DEV_BATCH_SIZE=1, GRAD_ACCUMULARION_STEPS=16, MAX_SEQ_LEN=2048 配置下约需要 21GB 显存。 |
| 全量微调 | 全量微调时,./scripts/finetune_ds_multiturn.sh 中的配置(MAX_SEQ_LEN=2048, DEV_BATCH_SIZE=16, GRAD_ACCUMULARION_STEPS=1)恰好用满 4 * 80GB 显存。 |
| 模型量化 | 若尝试后发现显存不足,可以考虑 尝试降低 DEV_BATCH_SIZE 并提升 GRAD_ACCUMULARION_STEPS 尝试添加 --quantization_bit 8 或 --quantization_bit 4。 PRE_SEQ_LEN=128, DEV_BATCH_SIZE=1, GRAD_ACCUMULARION_STEPS=16, MAX_SEQ_LEN=1024 配置下,--quantization_bit 8 约需 12GB 显存,--quantization_bit 4 约需 7.6GB 显存。 |
(2)、多轮对话格式
多轮对话微调示例采用 ChatGLM3 对话格式约定,对不同角色添加不同 loss_mask 从而在一遍计算中为多轮回复计算 loss。
第1步,数据格式和预处理
(1)、对于数据文件的样例采用如下格式:仅希望微调模型的对话能力、微调模型的对话和工具能力
| 仅希望微调模型的对话能力,而非工具能力 | 如果您仅希望微调模型的对话能力,而非工具能力,您应该按照以下格式整理数据。 [ { "conversations": [ { "role": "system", "content": "<system prompt text>" }, { "role": "user", "content": "<user prompt text>" }, { "role": "assistant", "content": "<assistant response text>" }, // ... Muti Turn { "role": "user", "content": "<user prompt text>" }, { "role": "assistant", "content": "<assistant response text>" } ] } // ... ] 请注意,这种方法在微调的step较多的情况下会影响到模型的工具调用功能 |
| 微调模型的对话和工具能力 | 如果您希望微调模型的对话和工具能力,您应该按照以下格式整理数据。 [ { "tools": [ // available tools, format is not restricted ], "conversations": [ { "role": "system", "content": "<system prompt text>" }, { "role": "user", "content": "<user prompt text>" }, { "role": "assistant", "content": "<assistant thought to text>" }, { "role": "tool", "name": "<name of the tool to be called", "parameters": { "<parameter_name>": "<parameter_value>" }, "observation": "<observation>" // don't have to be string }, { "role": "assistant", "content": "<assistant response to observation>" }, // ... Muti Turn { "role": "user", "content": "<user prompt text>" }, { "role": "assistant", "content": "<assistant response text>" } ] } // ... ] >> 关于工具描述的 system prompt 无需手动插入,预处理时会将 tools 字段使用 json.dumps(..., ensure_ascii=False) 格式化后插入为首条 system prompt。 >> 每种角色可以附带一个 bool 类型的 loss 字段,表示该字段所预测的内容是否参与 loss 计算。若没有该字段,样例实现中默认对 system, user 不计算 loss,其余角色则计算 loss。 >> tool 并不是 ChatGLM3 中的原生角色,这里的 tool 在预处理阶段将被自动转化为一个具有工具调用 metadata 的 assistant 角色(默认计算 loss)和一个表示工具返回值的 observation 角色(不计算 loss)。 >> 目前暂未实现 Code interpreter的微调任务。 >> system 角色为可选角色,但若存在 system 角色,其必须出现在 user 角色之前,且一个完整的对话数据(无论单轮或者多轮对话)只能出现一次 system 角色。 |
(2)、示例使用 ToolAlpaca 数据集来进行微调
作为示例,我们使用 ToolAlpaca 数据集来进行微调。首先,克隆 ToolAlpaca 数据集,并使用
./scripts/format_tool_alpaca.py --path "ToolAlpaca/data/train_data.json"将数据集处理成上述格式。在这里,我们有意将工具处理成了了 list[str] 这样的自然语言形式,以观察模型在微调前后对工具定义的理解能力。
第2步,微调模型:全量微调、P-Tuning v2微调
以下脚本提供了微调模型的参考方式。
./scripts/finetune_ds_multiturn.sh # 全量微调
./scripts/finetune_pt_multiturn.sh # P-Tuning v2 微调第3步,部署模型
我们更新了 ChatGLM3 的综合 Demo,使其可以部署微调后的模型 checkpoint。
| 全量微调 | 对于全量微调,可以使用以下方式进行部署 cd ../composite_demo MODEL_PATH="path to finetuned model checkpoint" TOKENIZER_PATH="THUDM/chatglm3-6b" streamlit run main.py |
| P-Tuning v2 微调 | 对于 P-Tuning v2 微调,可以使用以下方式进行部署 cd ../composite_demo MODEL_PATH="THUDM/chatglm3-6b" PT_PATH="path to p-tuning checkpoint" streamlit run main.py |
(3)、输入输出格式
第1步,数据格式和预处理
(1)、对于输入-输出格式,样例采用如下输入格式
[
{
"prompt": "<prompt text>",
"response": "<response text>"
}
// ...
]预处理时,不会拼接任何角色标识符。
(2)、示例使用 AdvertiseGen据集来进行微调
作为示例,我们使用 AdvertiseGen 数据集来进行微调。从 Google Drive 或者 Tsinghua Cloud 下载处理好的 AdvertiseGen 数据集,将解压后的 AdvertiseGen 目录放到本目录下。
./scripts/format_advertise_gen.py --path "AdvertiseGen/train.json"来下载和将数据集处理成上述格式。
第2步,微调模型
以下脚本提供了微调模型的参考方式。
./scripts/finetune_ds.sh # 全量微调
./scripts/finetune_pt.sh # P-Tuning v2 微调第3步,推理验证
对于输入输出格式的微调,可使用 inference.py 进行基本的推理验证。
python inference.py \
--pt-checkpoint "path to p-tuning checkpoint" \
--model THUDM/chatglm3-6b
python inference.py \
--tokenizer THUDM/chatglm3-6b \
--model "path to finetuned model checkpoint"输出结果
微调代码在开始训练前,会先打印首条训练数据的预处理信息,显示为如下字样,每行依次表示一个 detokenized string, token_id 和 target_id。可在日志中查看这部分的 loss_mask 是否符合预期。若不符合,可能需要调整代码或数据。
| 提示信息 | Sanity Check >>>>>>>>>>>>> '[gMASK]': 64790 -> -100 'sop': 64792 -> -100 '<|system|>': 64794 -> -100 '': 30910 -> -100 '\n': 13 -> -100 'Answer': 20115 -> -100 'the': 267 -> -100 'following': 1762 -> -100 ... 'know': 683 -> -100 'the': 267 -> -100 'response': 3010 -> -100 'details': 3296 -> -100 '.': 30930 -> -100 '<|assistant|>': 64796 -> -100 '': 30910 -> 30910 '\n': 13 -> 13 'I': 307 -> 307 'need': 720 -> 720 'to': 289 -> 289 'use': 792 -> 792 ... <<<<<<<<<<<<< Sanity Check |
T3、基于官方Demo利用云服务器采用P-Tuning v2微调
LLMs之ChatGLM3:基于AutoDL云服务器利用自定义json格式指令数据集(或官方AdvertiseGen)+数据格式转换(三元组格式转为二元组)对ChatGLM3训练(P-Tuning v2微调)+推理的案例实战
https://yunyaniu.blog.csdn.net/article/details/134426358
T4、基于LLaMA-Factory框架微调
LLMs之ChatGLM3:基于LLaMA-Factory利用自定义json格式指令数据集采用LoRA微调ChatGLM3训练(合并模型可作为基模型进而实现二次微调)+微调(CLI/WebUI)+推理的案例实战
https://yunyaniu.blog.csdn.net/article/details/134236595
3、模型推理/测试使用
T1、采用官方Demo的CLI的形式
(1)、编写代码:调用 ChatGLM 模型来生成对话,会自动下载模型实现和参数
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
model = model.eval()
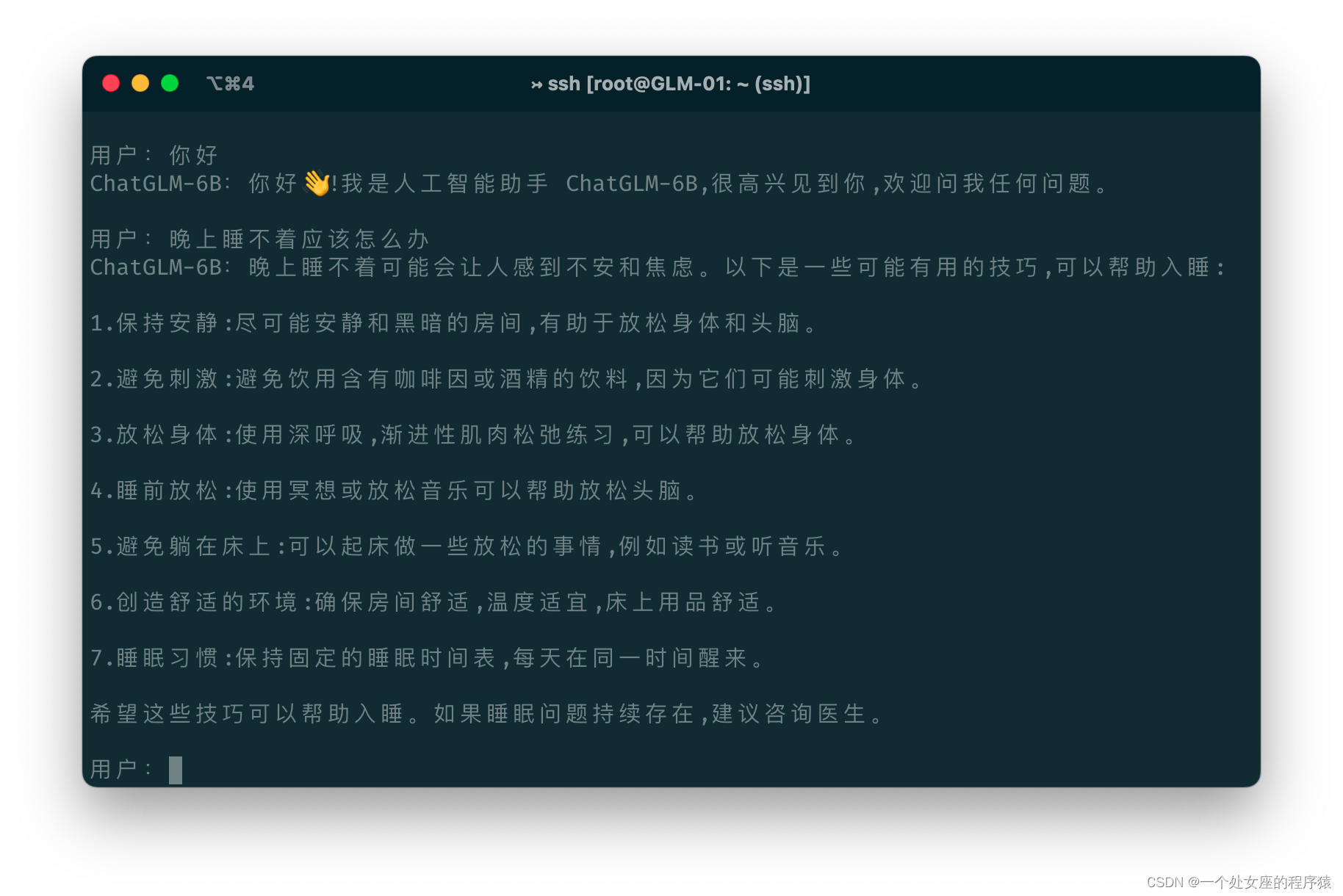
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
# 你好👋!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。(2)、或者手动下载模型再进行加载
以上代码会由 transformers 自动下载模型实现和参数。完整的模型实现在 Hugging Face Hub。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。
从 Hugging Face Hub 下载模型需要先安装Git LFS,然后运行
git clone https://huggingface.co/THUDM/chatglm3-6b如果从你从 HuggingFace 下载比较慢,也可以从 ModelScope 中下载。
Hugging Face地址:https://huggingface.co/THUDM/chatglm3-6b
ModelScope地址:https://modelscope.cn/models/ZhipuAI/chatglm3-6b
(3)、命令行demo实现:占内存将近13G
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
source activate LLMs_chat_DIY
python cli_demo.py
如何评价CSDN社区上的AI博主“一个处女座的程序猿”的文章?
T2、采用官方Demo的Web界面使用——三大功能的实现
LLMs之ChatGLM3:inference.py文件解读—实现一个简单的基于ChatGLM3的交互式语言模型+根据用户输入文本生成相应的响应
https://yunyaniu.blog.csdn.net/article/details/135040296
安装
我们建议通过 Conda 进行环境管理。
执行以下命令新建一个 conda 环境并安装所需依赖:
conda create -n chatglm3-demo python=3.10
conda activate chatglm3-demo
pip install -r requirements.txt请注意,本项目需要 Python 3.10 或更高版本。
此外,使用 Code Interpreter 还需要安装 Jupyter 内核:
ipython kernel install --name chatglm3-demo --user运行
运行以下命令在本地加载模型并启动 demo:
streamlit run main.py之后即可从命令行中看到 demo 的地址,点击即可访问。初次访问需要下载并加载模型,可能需要花费一定时间。
如果已经在本地下载了模型,可以通过 export MODEL_PATH=/path/to/model 来指定从本地加载模型。如果需要自定义 Jupyter 内核,可以通过 export IPYKERNEL=<kernel_name> 来指定。
网页版 demo 会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。 经测试,基于 Streamlit 的网页版 Demo 会更流畅。
T1、基于 Gradio 的网页版 demo
python web_demo.py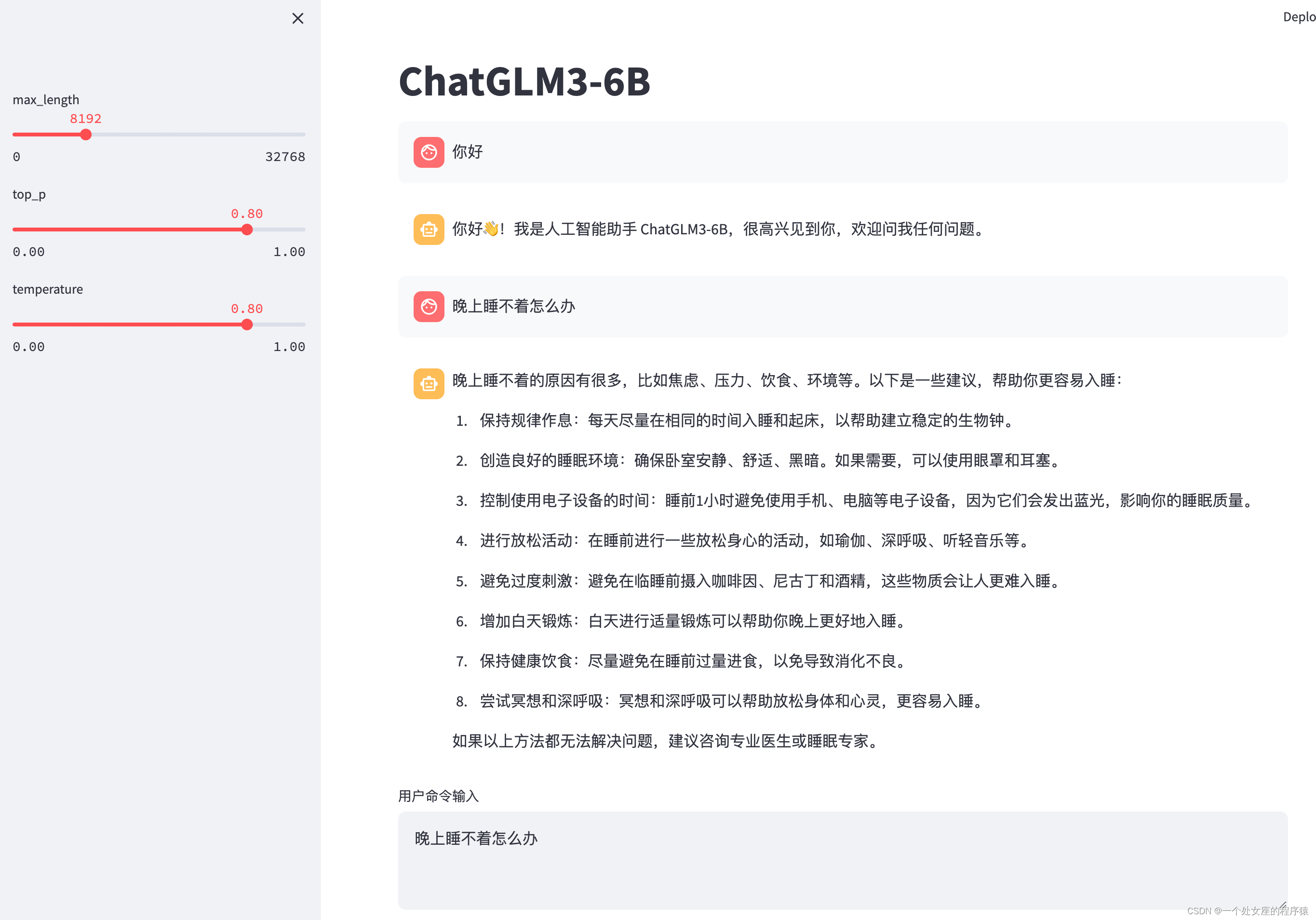
T2、基于 Streamlit 的网页版 demo:更流畅!
streamlit run web_demo2.py
使用
ChatGLM3 Demo 拥有三种模式:
- Chat: 对话模式,在此模式下可以与模型进行对话。
- Tool: 工具模式,模型除了对话外,还可以通过工具进行其他操作。
- Code Interpreter: 代码解释器模式,模型可以在一个 Jupyter 环境中执行代码并获取结果,以完成复杂任务。
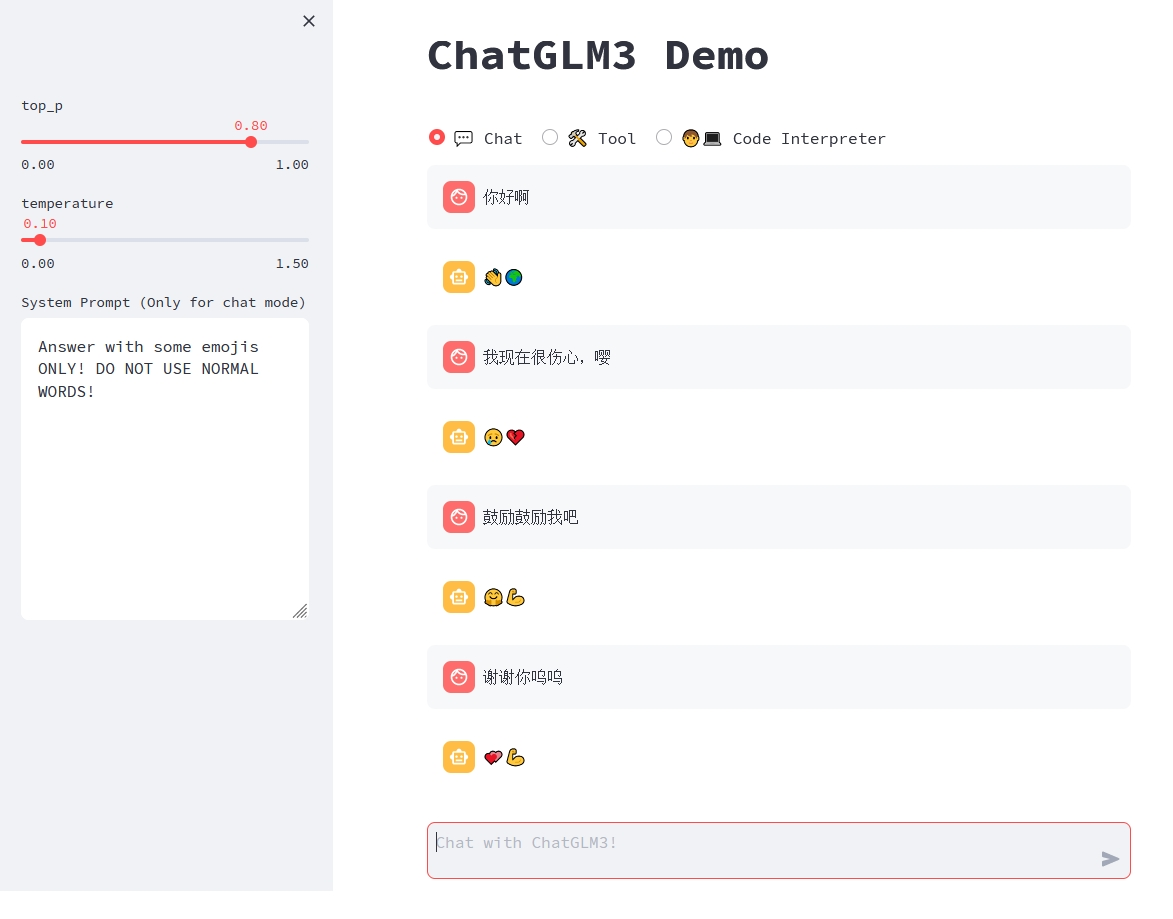
(1)、对话模式
对话模式下,用户可以直接在侧边栏修改 top_p, temperature, System Prompt 等参数来调整模型的行为。例如
(2)、工具模式
可以通过在 tool_registry.py 中注册新的工具来增强模型的能力。只需要使用 @register_tool 装饰函数即可完成注册。对于工具声明,函数名称即为工具的名称,函数 docstring 即为工具的说明;对于工具的参数,使用 Annotated[typ: type, description: str, required: bool] 标注参数的类型、描述和是否必须。
例如,get_weather 工具的注册如下:
@register_tool
def get_weather(
city_name: Annotated[str, 'The name of the city to be queried', True],
) -> str:
"""
Get the weather for `city_name` in the following week
"""
...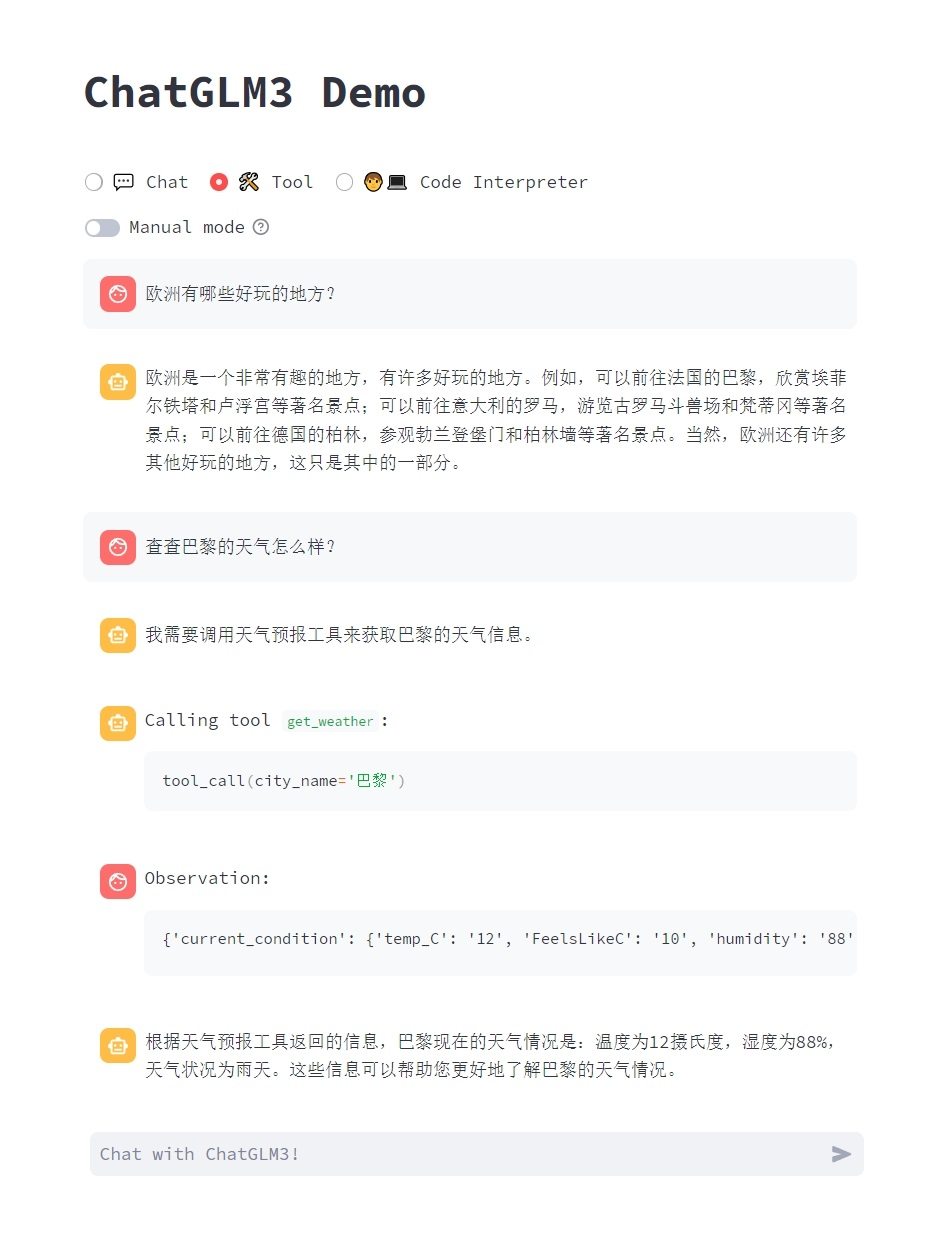
(3)、代码解释器模式
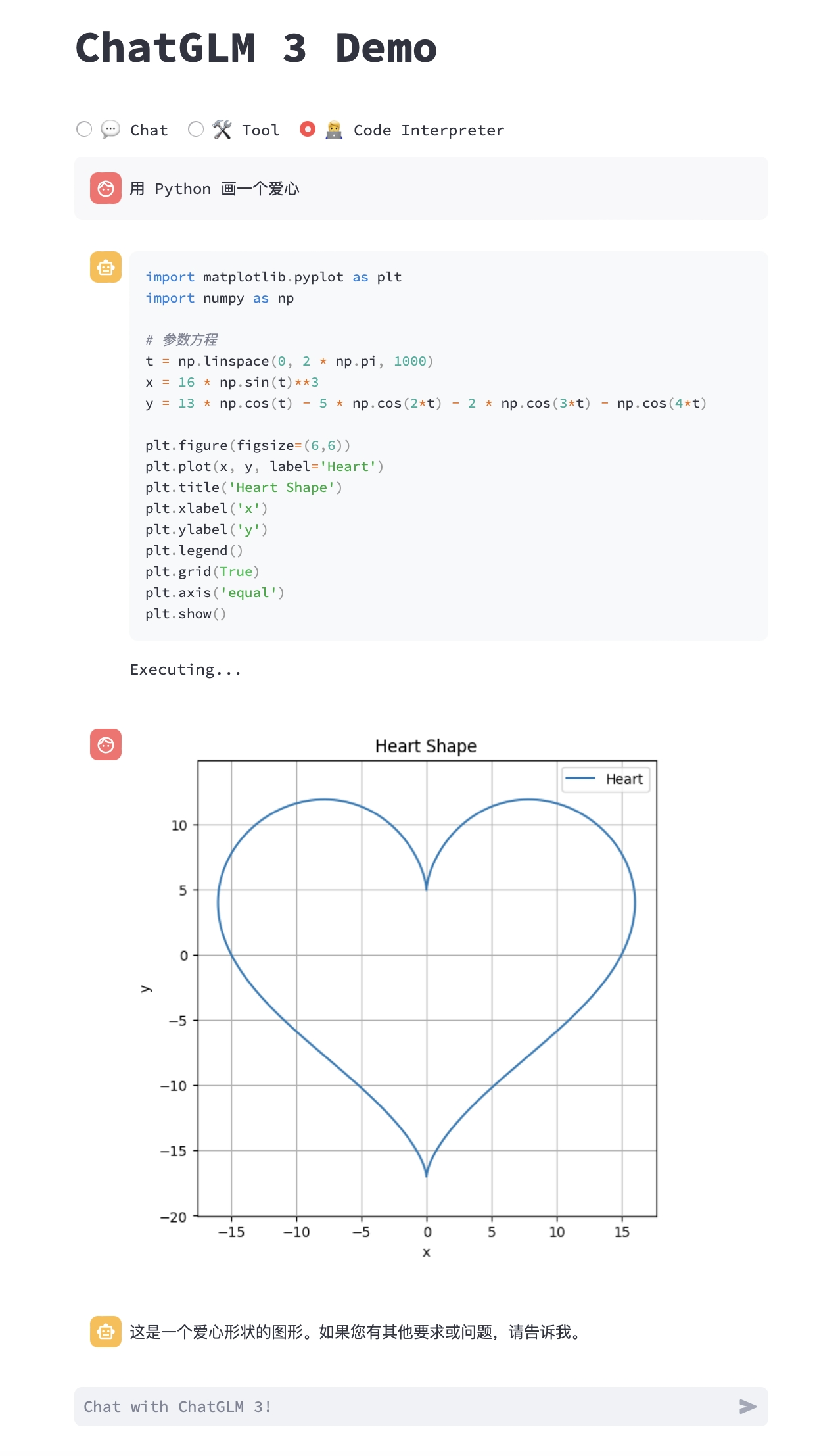
由于拥有代码执行环境,此模式下的模型能够执行更为复杂的任务,例如绘制图表、执行符号运算等等。模型会根据对任务完成情况的理解自动地连续执行多个代码块,直到任务完成。因此,在这一模式下,你只需要指明希望模型执行的任务即可。
例如,我们可以让 ChatGLM3 画一个爱心:
T3、采用基于LangChain框架实现ChatGLM3的对话生成、工具调用功能
LLMs之LangChain之ChatGLM3:使用LangChain框架基于本地部署的ChatGLM3的API端点的URL(设置url)开启交互并实现文本补全任务实战代码之详细攻略
https://yunyaniu.blog.csdn.net/article/details/137760406
LLMs之ToolAgent:基于LangChain框架采用ChatGLM3通过调用自定义的工具实现ToolAgent的功能(arxiv论文查询、天气查询、数值计算等单工具调用或者多工具调用)输出详解
4、低成本部署
地址:https://github.com/THUDM/ChatGLM3/blob/main/DEPLOYMENT.md
T1、模型量化: 4-bit 量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
model = AutoModel.from_pretrained("THUDM/chatglm3-6b",trust_remote_code=True).quantize(4).cuda()模型量化会带来一定的性能损失,经过测试,ChatGLM3-6B 在 4-bit 量化下仍然能够进行自然流畅的生成。
T2、CPU 部署:仍需32G
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).float()T3、Mac 部署:半精度要 13GB 内存
对于搭载了 Apple Silicon 或者 AMD GPU 的 Mac,可以使用 MPS 后端来在 GPU 上运行 ChatGLM3-6B。需要参考 Apple 的 官方说明 安装 PyTorch-Nightly(正确的版本号应该是2.x.x.dev2023xxxx,而不是 2.x.x)。
目前在 MacOS 上只支持从本地加载模型。将代码中的模型加载改为从本地加载,并使用 mps 后端:
model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')加载半精度的 ChatGLM3-6B 模型需要大概 13GB 内存。内存较小的机器(比如 16GB 内存的 MacBook Pro),在空余内存不足的情况下会使用硬盘上的虚拟内存,导致推理速度严重变慢。
T4、多卡部署:需先安装accelerate库
如果你有多张 GPU,但是每张 GPU 的显存大小都不足以容纳完整的模型,那么可以将模型切分在多张GPU上。首先安装 accelerate:
pip install accelerate然后通过如下方法加载模型:
from utils import load_model_on_gpus
model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)即可将模型部署到两张 GPU 上进行推理。你可以将 num_gpus 改为你希望使用的 GPU 数。默认是均匀切分的,你也可以传入 device_map 参数来自己指定。
ChatGLM3的实战应用
1、模型使用在线测试
测试地址:https://chatglm.cn/main/code
对话测试
>> 请问,你作为ChatGLM3,和此前的ChatGLM2版本有什么重大区别?
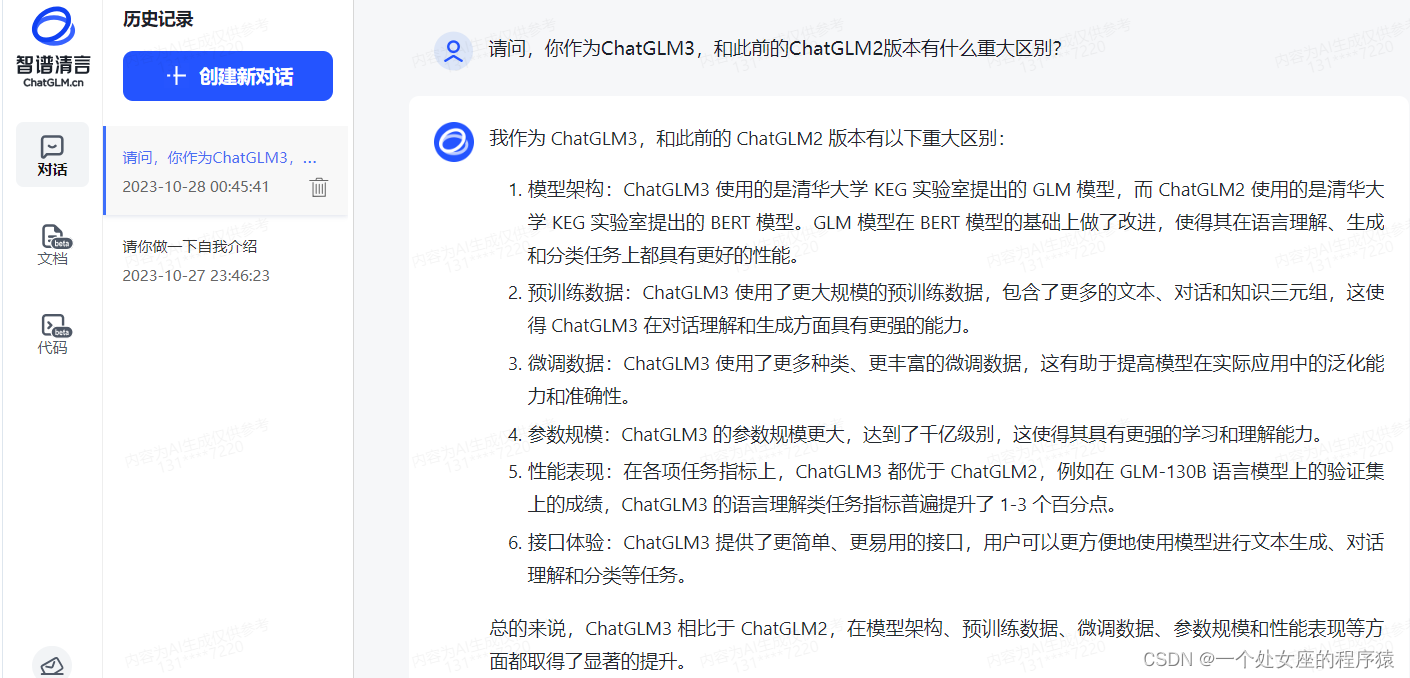
>> 请问,你作为ChatGLM3-6B,你是怎么进行预训练的,主要实现的核心过程包括哪些?

文档提问
帮我梳理整个文档《Baichuan2-technical-report3》
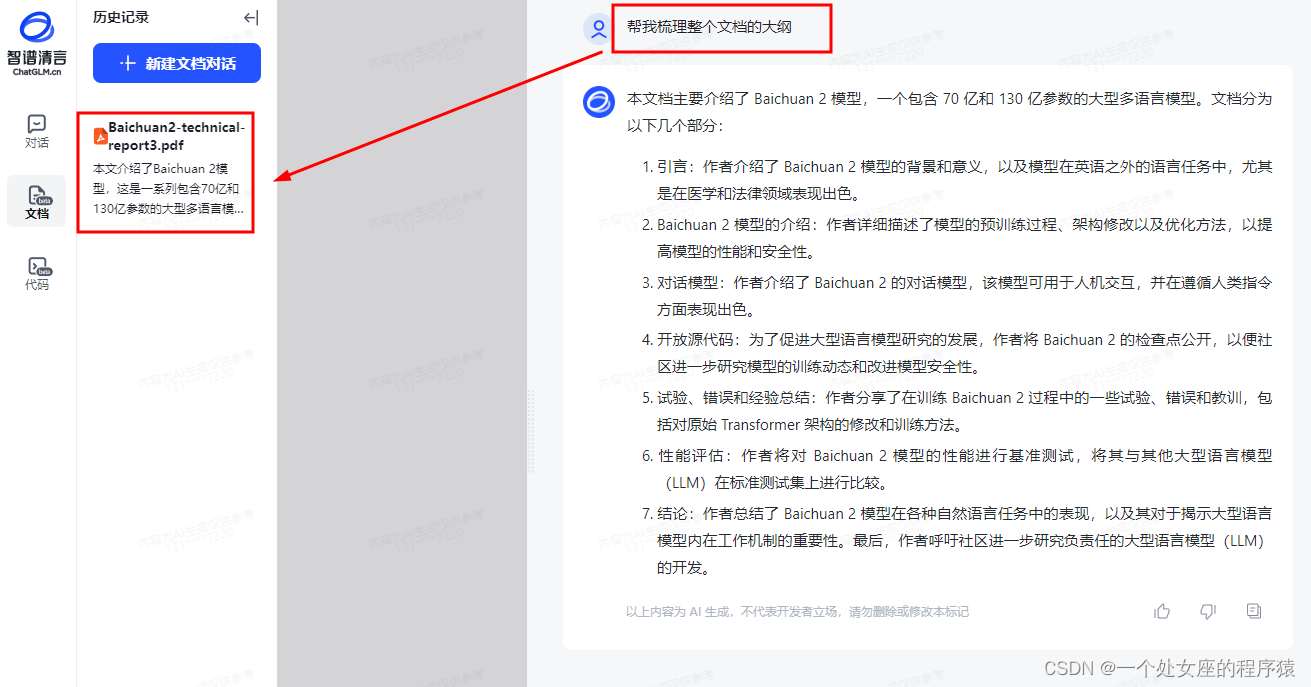
代码测试
帮我写一个冒泡排序算法
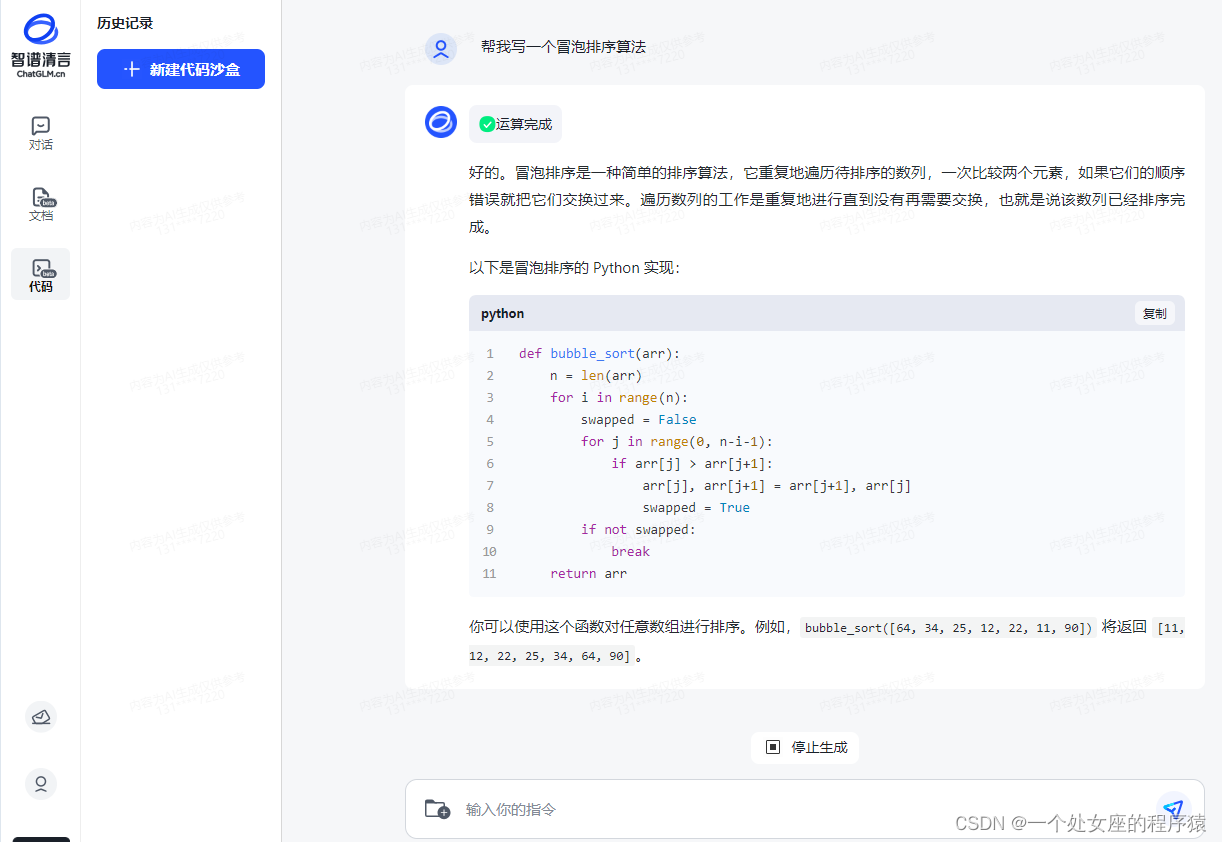
def bubble_sort(arr):
n = len(arr)
for i in range(n):
swapped = False
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
swapped = True
if not swapped:
break
return arr2、进阶用法
LLMs之ChatGLM3:基于LLaMA-Factory利用自定义json格式指令数据集采用LoRA微调ChatGLM3训练(合并模型可作为基模型进而实现二次微调)+微调(CLI/WebUI)+推理的案例实战
https://yunyaniu.blog.csdn.net/article/details/134236595
LLMs之ChatGLM3:基于AutoDL云服务器利用自定义json格式指令数据集(或官方AdvertiseGen)+数据格式转换(三元组格式转为二元组)对ChatGLM3训练(P-Tuning v2微调)+推理的案例实战
https://yunyaniu.blog.csdn.net/article/details/134426358




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











