







LLMs:《GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond》翻译与解读
导读:
背景:随着大型语言模型(LLMs)的快速发展,迫切需要一个全面的评估套件来评估它们的能力和限制。
问题:现有的LLM排行榜经常引用其他论文中报告的分数,但设置和提示不一致,这可能会无意中鼓励选择有利的设置和提示以获得更好的结果。
解决方案:论文提出了一个开源的机器学习模型评估平台GPT-Fathom,这是一个建立在OpenAI Evals之上的开源和可复现的LLM评估套件。
方法:GPT-Fathom在统一的设置下,系统地评估了10多个领先的LLMs以及OpenAI的旧模型在20多个精选基准测试中的7个能力类别。
对OpenAI早期模型的回顾性研究为从GPT-3到GPT-4的演进路径提供了有价值的见解。
技术细节:分析了GPT-3逐步改进到GPT-4的过程,包括是否通过添加代码数据来提高LLM的推理能力,SFT和RLHF可以改善LLM能力的哪些方面,对齐税是多少等。
深入探讨代码数据预训练对模型整体性能的提升。SFT和RLHF技术在基础模型和强基础模型上的不同影响。它们对基础模型有较大助益,但对强基础模型会带来一定“对齐税”。提供不同设置下的模型表现变化。例如样本数和链式思维提示对结果的影响。
总结:该文章介绍了GPT-Fathom,一个用于评估大型语言模型的开源评估套件。通过对多个LLMs和OpenAI旧模型在统一设置下的评估,研究者提供了关于从GPT-3到GPT-4的演进路径的有价值见解,并回答了关于LLM技术细节的问题,旨在提高先进LLMs的透明度。
目录
三大关键挑战:不一致的设置(评估设置+提示设计)、模型和基准的不完整收集(缺少对OpenAI早期模型的研究+仅对某一些方面的研究)、模型敏感性研究不足(LLMs的潜在漏洞—提示的敏感性)
本文工作总结:在一致的设置下进行系统和可重复的评估、从GPT-3到GPT-4的进化路径回顾性研究、识别高级LLM的新挑战
2.2 BENCHMARKS FOR EVALUATION评价基准
2.3 DETAILS OF BLACK-BOX EVALUATION黑箱评估细节
Table 1: Main evaluation results of GPT-Fathom.
3.2 ANALYSIS AND INSIGHTS分析与洞察
OpenAI与非OpenAILLMs:GPT-4绝对领先、Claude 2可与之相比较
LLM能力的跷跷板现象(某些功能改善+某些功能明显倒退):一个普遍的挑战,但的确也会阻碍LLM向AGI发展的道路
Table 3: Breakdown of coding performance with temperature T = 0.8 and topp = 1.0.
Table 4: Ablation study on number of “shots”.
Table 5: Ablation study on CoT prompting.
Table 6: Benchmark performance with different prompt templates.
“射击”次数的影响:“射击”次数的增加会使得性能通常会提高,超过1次射击后改进率会迅速缩小→1-shot的例子通常适用于大多数任务
CoT提示的影响:因基准而异,像MMLU知识任务影响较小,但BBH和GSM8K等推理任务显著提高
4 CONCLUSIONS AND FUTURE WORK结论与未来工作
A DETAILS OF EVALUATED LLMS评估LLMS的细节
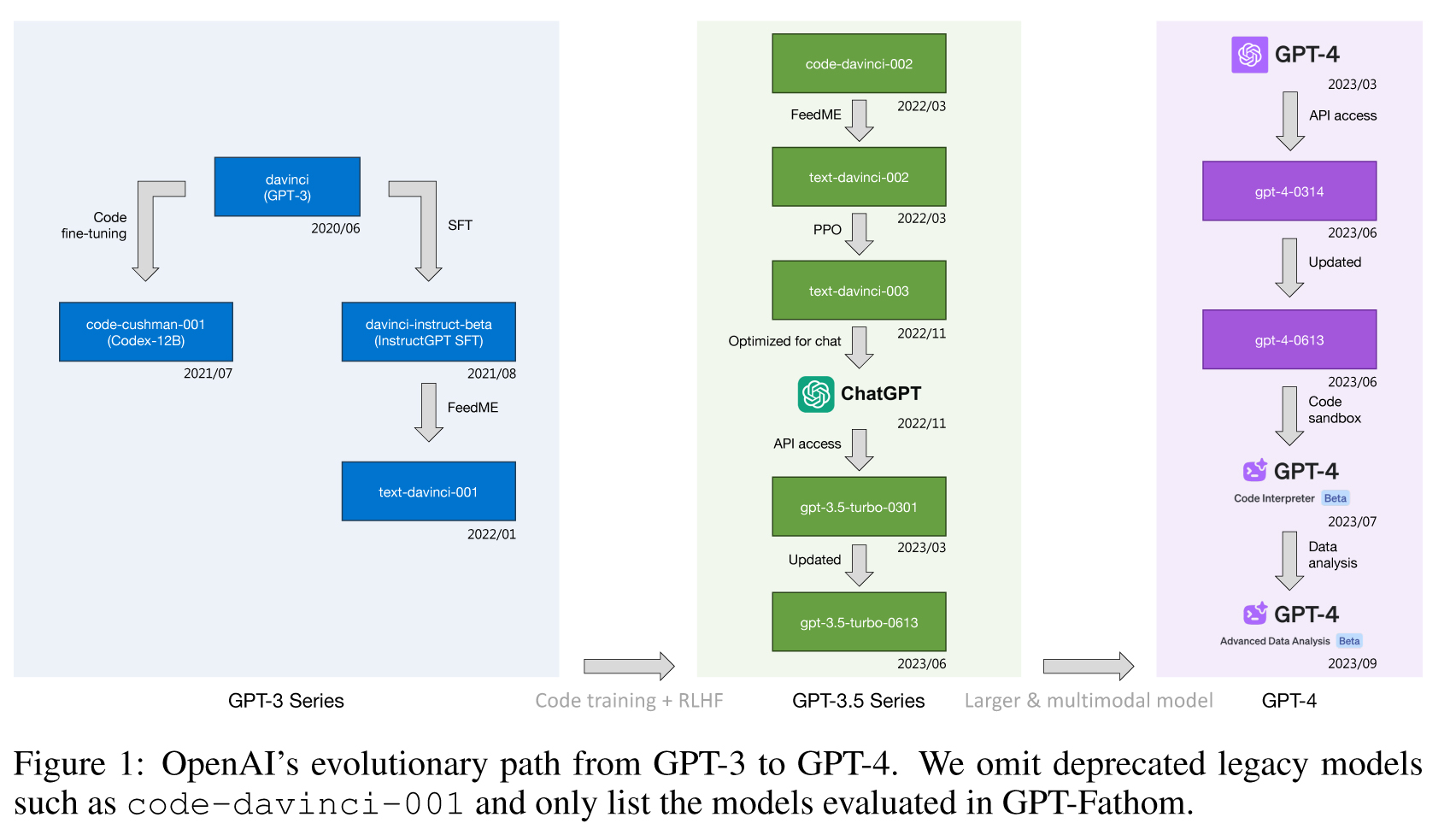
1、OpenAI’s models (illustrated in Figure 1):
2、Other leading closed-source models:其他领先的闭源模型
3、Leading open-source models:领先的开源模型
LLMs:《GPT-Fathom: Benchmarking Large Language Models to Decipher the Evolutionary Path towards GPT-4 and Beyond》翻译与解读
| 地址 | |
| 时间 | 2023年10月23日 |
| 作者 | ByteDance |
ABSTRACT
| With the rapid advancement of large language models (LLMs), there is a pressing need for a comprehensive evaluation suite to assess their capabilities and limi-tations. Existing LLM leaderboards often reference scores reported in other pa-pers without consistent settings and prompts, which may inadvertently encourage cherry-picking favored settings and prompts for better results. In this work, we introduce GPT-Fathom, an open-source and reproducible LLM evaluation suite built on top of OpenAI Evals1. We systematically evaluate 10+ leading LLMs as well as OpenAI’s legacy models on 20+ curated benchmarks across 7 capability categories, all under aligned settings. Our retrospective study on OpenAI’s earlier models offers valuable insights into the evolutionary path from GPT-3 to GPT-4. Currently, the community is eager to know how GPT-3 progressively improves to GPT-4, including technical details like whether adding code data improves LLM’s reasoning capability, which aspects of LLM capability can be improved by SFT and RLHF, how much is the alignment tax, etc. Our analysis sheds light on many of these questions, aiming to improve the transparency of advanced LLMs. | 随着大型语言模型(llm)的快速发展,迫切需要一个全面的评估套件来评估它们的能力和局限性。现有的LLMs排行榜通常会参考其他论文中报告的分数,但没有一致的设置和提示,这可能无意中鼓励选择有利的设置和提示以获得更好的结果。在这项工作中,我们介绍了GPT-Fathom,一个基于OpenAI Evals1的开源和可复制的LLMs评估套件。我们系统地评估了10多个领先的LLMs以及OpenAI的旧模型,涵盖了7个能力类别的20多个精选基准,所有设置都是一致的。我们对OpenAI早期模型的回顾性研究为从GPT-3到GPT-4的进化路径提供了有价值的见解。目前,社区很想知道GPT-3是如何逐步提升到GPT-4的,包括技术细节,比如添加代码数据是否提高了LLM的推理能力,SFT和RLHF可以改善LLM能力的哪些方面,对齐税是多少等。我们的分析解答了许多这些问题,旨在提高先进LLM的透明度。 |
1 INTRODUCTION
| Recently, the advancement of large language models (LLMs) is arguably the most remarkable break-through in Artificial Intelligence (AI) in the past few years. Based on the Transformer (Vaswani et al., 2017) architecture, these LLMs are trained on massive Web-scale text corpora. Despite their straightforward method of using a self-supervised objective to predict the next token, leading LLMs demonstrate exceptional capabilities across a range of challenging tasks (Bubeck et al., 2023), even showing a potential path towards Artificial General Intelligence (AGI). With the rapid progress of LLMs, there is a growing demand for better understanding these powerful models, including the distribution of their multi-aspect capabilities, limitations and risks, and directions and priorities of their future improvement. It is critical to establish a carefully curated evaluation suite that measures LLMs in a systematic, transparent and reproducible manner. Although there already exist many LLM leaderboards and evaluation suites, some key challenges are yet to be addressed: | 最近,大型语言模型(LLMs)的进步可以说是过去几年人工智能(AI)领域最显著的突破。基于Transformer (Vaswani et al., 2017)架构,这些LLMs是在大规模的Web文本语料库上进行训练的。尽管它们使用一种简单的自监督目标来预测下一个令牌,但领先的LLMs在各种具有挑战性的任务中展现出卓越的能力,甚至显示出通向人工通用智能(AGI)的潜在路径(Bubeck等,2023)。随着LLMs的快速发展,人们越来越需要更好地了解这些强大的模型包括它们的多方面能力、限制和风险的分布,以及未来改进的方向和优先级。建立一个精心策划的评估套件,以系统、透明和可重复的方式衡量LLMs,这一点至关重要。虽然已经有许多LLMs排行榜和评估套件,但仍有一些关键挑战有待解决: |
三大关键挑战:不一致的设置(评估设置+提示设计)、模型和基准的不完整收集(缺少对OpenAI早期模型的研究+仅对某一些方面的研究)、模型敏感性研究不足(LLMs的潜在漏洞—提示的敏感性)
| >> Inconsistent settings: The evaluation settings, such as the number of in-context example “shots”,whether Chain-of-Thought (CoT; Wei et al. 2022) prompting is used, methods of answer parsing and metric computation, etc., often differ across the existing LLM works. Moreover, most of the released LLMs do not disclose their prompts used for evaluation, making it difficult to reproduce the reported scores. Different settings and prompts may lead to very different evaluation results, which may easily skew the observations. Yet, many existing LLM leaderboards reference scores from other papers without consistent settings and prompts, which may inadvertently encourage cherry-picking favored settings and prompts for better results. To achieve reliable conclusions, it is crucial to make apples-to-apples LLM comparisons with consistent settings and prompts. >> Incomplete collection of models and benchmarks: For the moment, when compared to OpenAI’s leading models such as GPT-4, all the other LLMs (particularly open-source models) exhibit a substantial performance gap. In fact, it takes OpenAI nearly three years to evolve from GPT- 3 (released in 2020/06) to GPT-4 (released in 2023/03). Existing LLM leaderboards primarily focus on the latest models, while missing a retrospective study on OpenAI’s earlier models and its mysterious path from GPT-3 to GPT-4. Besides the coverage of models, many existing works assess LLMs on merely one or a few aspects of capabilities, which is not sufficient to provide a comprehensive view to deeply understand the strength and weakness of the evaluated LLMs. >> Insufficient study on model sensitivity: LLMs are known to be sensitive to the evaluation setting and the formatting of prompt (Liang et al., 2023). However, many existing works only focus on the benchmark score under one specific setting, while overlooking the impacts of model sensitivity on the overall usability of LLMs. In fact, it is unacceptable that a slightly rephrased prompt could cause the LLM to fail in responding it correctly. Due to the lack of systematic study on model sensitivity, this potential vulnerability in LLMs remains not well understood. | >>不一致设置:评估设置,例如上下文示例“镜头”的数量,是否思维链(CoT);Wei et al. 2022)提示的使用,回答解析和度量计算的方法等,在现有的LLM工作中经常存在差异。此外,大多数已发布的LLMs课程没有披露其用于评估的提示,这使得很难重现报告的分数。不同的设置和提示可能导致非常不同的评估结果,这可能很容易使观察结果产生偏差。然而,许多现有的LLMs排行榜参考了其他论文的分数,但没有一致的设置和提示,这可能会无意中鼓励玩家选择有利的设置和提示,以获得更好的结果。为了得到可靠的结论,在相同的设置和提示下进行同类的LLM比较是至关重要的。 >>模型和基准的不完整收集:目前,当与OpenAI的领先模型(如GPT-4)相比时,所有其他LLMs(特别是开源模型)表现出实质性的性能差距。事实上,OpenAI从GPT- 3(发布于2020/06)到GPT-4(发布于2023/03)花了将近三年的时间。现有的LLM排行榜主要关注最新的模型,而缺少对OpenAI早期模型的回顾性研究,以及它从GPT-3到GPT-4的神秘路径。除了模型的覆盖之外,许多现有的研究仅对LLMs的某一方面或几个方面进行评估,这对深入了解评估LLMs的强弱不足是不够的。 >>模型敏感性研究不足:已知LLMs对评估设置和提示格式敏感(Liang et al., 2023)。然而,许多现有的研究只关注某一特定设置下的基准得分,而忽略了模型敏感性对LLMs整体可用性的影响。事实上,一个稍微改变了措辞的提示可能导致LLM无法正确响应它,这是不可接受的。由于缺乏对模型敏感性的系统研究,LLMs中的这一潜在漏洞仍未得到很好的理解。 |
针对挑战引入GPT-Fathom
| These challenges hinder a comprehensive understanding of LLMs. To dispel the mist among LLM evaluations, we introduce GPT-Fathom, an open-source and reproducible LLM evaluation suite de-veloped based on OpenAI Evals1. We evaluate 10+ leading open-source and closed-source LLMs on 20+ curated benchmarks in 7 capability categories under aligned settings. We also evaluate legacy models from OpenAI to retrospectively measure their progressive improvement in each capability dimension. Our retrospective study offers valuable insights into OpenAI’s evolutionary path from GPT-3 to GPT-4, aiming to help the community better understand this enigmatic path. Our analysis sheds light on many community-concerned questions (e.g., the gap between OpenAI / non-OpenAI models, whether adding code data improves reasoning capability, which aspects of LLM capability can be improved by SFT and RLHF, how much is the alignment tax, etc.). With reproducible evalu-ations, GPT-Fathom serves as a standard gauge to pinpoint the position of emerging LLMs, aiming to help the community measure and bridge the gap with leading LLMs. We also explore the impacts of model sensitivity on evaluation results with extensive experiments of various settings. | 这些挑战阻碍了对LLMs的全面理解。为了消除LLMs评估之间的困扰,我们引入了GPT-Fathom,这是一个基于OpenAI Evals1开发的开源和可重现的LLMs评估套件。我们评估了10多个领先的开源和闭源llm,在7个能力类别下的20多个精选基准测试。我们还评估了OpenAI的旧模型,以回顾性地衡量它们在每个能力维度上的逐步改进。我们的回顾性研究为OpenAI从GPT-3到GPT-4的进化路径提供了有价值的见解,旨在帮助社区更好地理解这条神秘的路径。我们的分析揭示了许多社区关注的问题(例如,OpenAI /非OpenAI模型之间的差距,添加代码数据是否可以提高推理能力,SFT和RLHF可以提高LLM能力的哪些方面,对齐税是多少,等等)。通过可重复的评估,GPT-Fathom可作为确定新兴LLMs位置的标准衡量标准,旨在帮助社区衡量并缩小与领先LLMs的差距。我们还通过各种设置的大量实验探讨了模型灵敏度对评估结果的影响。 |
GPT-Fathom与之前的作品进行多个角度比较
| Benchmarks constantly play a pivotal role in steering the evolution of AI and, of course, directing the advancement of LLMs as well. There are many great existing LLM evaluation suites. By comparing GPT-Fathom with previous works, we summarize the major difference as follows: 1) HELM (Liang et al., 2023) primarily uses answer-only prompting (without CoT) and has not included the latest leading models such as GPT-4 (as of the time of writing); 2) Open LLM Leaderboard (Beeching et al., 2023) focuses on open-source LLMs, while we jointly consider leading closed-source and open-source LLMs; 3) OpenCompass (Contributors, 2023) evaluates latest open-source and closed-source LLMs (all released after 2023/03), while we cover both leading LLMs and OpenAI’s earlier models to decipher the evolutionary path from GPT-3 to GPT-4; 4) InstructEval (Chia et al., 2023) is designed for evaluating instruction-tuned LLMs, while we evaluate both base and SFT / RLHF models; 5) AlpacaEval (Li et al., 2023) evaluates on simple instruction-following tasks as a quick and cheap proxy of human evaluation, while we provide systematic evaluation of various aspects of LLM capabilities; 6) Chatbot Arena (Zheng et al., 2023) evaluates human user’s dialog preference with a Elo rating system, while we focus on automatic and reproducible evaluation over popular benchmarks; 7) Chain-of-Thought Hub (Fu et al., 2023) focuses on evaluating the reasoning capa-bility of LLMs with CoT prompting, while we support both CoT and answer-only prompting settings and evaluate various aspects of LLM capabilities. | 基准在引导人工智能的发展中不断发挥着关键作用,当然,也指导着LLMs的进步。有许多现有的LLMs评估套件。通过将GPT-Fathom与之前的作品进行比较,我们总结出以下主要差异: 1)、HELM (Liang et al., 2023)主要使用仅回答提示(没有CoT),并且没有包括最新的领先模型,如GPT-4(截至撰写本文的时间); 2)、开放LLM排行榜(Beeching et al., 2023)关注开源LLM,同时我们同时考虑领先的闭源和开源LLM; 3)、 OpenCompass(贡献者,2023)评估最新的开源和闭源LLMs(所有在2023/03之后发布),同时我们涵盖了领先的LLMs和OpenAI的早期模型,以解读从GPT-3到GPT-4的进化路径; 4)、 InstructEval (Chia et al., 2023)设计用于评估经过指导的LLMs,而我们评估了基础模型和SFT / RLHF模型; 5)、 AlpacaEval (Li et al., 2023)对简单的指令遵循任务进行评估,作为人类评估的快速而廉价的代理,而我们对LLM能力的各个方面提供了系统的评估; 6)、 Chatbot Arena (Zheng et al., 2023)使用Elo评级系统评估人类用户的对话偏好,而我们专注于在流行基准上进行自动和可重复的评估; 7)、思维链中心(Chain-of-Thought Hub, Fu et al., 2023)侧重于评估具有CoT提示的LLMs的推理能力,而我们同时支持CoT和仅回答提示设置,并评估LLMs能力的各个方面。 |
本文工作总结:在一致的设置下进行系统和可重复的评估、从GPT-3到GPT-4的进化路径回顾性研究、识别高级LLM的新挑战
| The key contributions of our work are summarized as follows: >> Systematic and reproducible evaluations under aligned settings: We provide accurate evaluations of 10+ leading LLMs on 20+ curated benchmarks across 7 capability categories. We carefully align the evaluation setting for each benchmark. Our work improves the transparency of LLMs, and all of our evaluation results can be easily reproduced. >> Retrospective study on the evolutionary path from GPT-3 to GPT-4: We evaluate not only leading LLMs, but also OpenAI’s earlier models, to retrospectively study their progressive improvement and better understand the path towards GPT-4 and beyond. Our work is time-sensitive due to the scheduled deprecation of those legacy models announced by OpenAI2. >> Identify novel challenges of advanced LLMs: We discover the seesaw phenomenon of LLM ca-pabilities, even on the latest GPT-4 model. We also study the impacts of model sensitivity with extensive experiments. We strongly encourage the research community to dedicate more efforts to tackling these novel challenges. | 我们工作的主要贡献总结如下: >>在一致的设置下进行系统和可重复的评估:我们在7个能力类别的20多个策划基准上为10多个领先的LLMs提供准确的评估。我们仔细调整每个基准的评估设置。我们的工作提高了LLMs的透明度,我们所有的评估结果都可以很容易地复制。 >>从GPT-3到GPT-4的进化路径回顾性研究:我们不仅评估领先的LLMs,还评估OpenAI早期的模型,以回顾性研究它们的渐进式改进,更好地了解GPT-4及以后的路径。我们的工作是时间敏感的,因为OpenAI2宣布将按计划弃用那些遗留模型。 >>识别高级LLM的新挑战:我们发现LLM能力的跷跷板现象,即使在最新的GPT-4模型上也是如此。我们还通过大量的实验研究了模型灵敏度的影响。我们强烈鼓励研究界投入更多的努力来解决这些新的挑战。 |
Figure 1: OpenAI’s evolutionary path from GPT-3 to GPT-4. We omit deprecated legacy models such as code-davinci-001 and only list the models evaluated in GPT-Fathom.
图1:从GPT-3到GPT-4的OpenAI演进路径。我们省略了已废弃的旧模型,如code-davinci-001,仅列出了在GPT-Fathom中进行评估的模型。
2、METHOD方法
| Imagine the ultimate superset of LLM evaluations: a holistic collection that evaluates every LLM on every benchmark under every possible setting. In practice, however, due to resource and time constraints, we are unable to exhaustively fulfill this ideal evaluation superset. Instead, we pick representative LLMs, benchmarks and settings to investigate open problems. In this section, we discuss in detail how we select LLMs, benchmarks and settings for our evaluations. | 想象一下LLM评估的终极超集:在每种可能的设置下,评估每个基准上的每个LLM的整体集合。然而,在实践中,由于资源和时间的限制,我们无法详尽地实现这个理想的评估超集。相反,我们选择具有代表性的LLMs,基准和设置来调查开放的问题。在本节中,我们将详细讨论如何为我们的评估选择LLMs、基准和设置。 |
2.1 LLMS FOR EVALUATION评估
| The goal of GPT-Fathom is to curate a high-quality collection of representative LLMs and bench-marks, helping the community better understand OpenAI’s evolutionary path and pinpoint the posi-tion of future LLMs. To achieve this goal, we mainly consider evaluating these types of LLMs: 1) OpenAI’s leading models; 2) OpenAI’s major earlier models3; 3) other leading closed-source mod-els; 4) leading open-source models. As a result, we select OpenAI’s models (illustrated in Figure 1), PaLM 2 (Anil et al., 2023), Claude 24, LLaMA (Touvron et al., 2023a) and Llama 2 (Touvron et al., 2023b) for evaluation. Due to the limited space, refer to Appendix A for the detailed model list. | GPT-Fathom的目标是策划一个高质量的LLMs和基准的代表性集合,帮助社区更好地理解OpenAI的演进路径并确定未来LLMs的位置。了实现这一目标,我们主要考虑评估以下几种llm: 1) 、OpenAI的领先模型; 2) 、OpenAI早期的主要模型; 3)、其他领先的闭源模型; 4)、领先的开源模型。 因此,我们选择OpenAI的模型(如图1所示)、PaLM 2 (Anil等人,2023)、Claude 24、LLaMA (Touvron等人,2023a)和LLaMA 2 (Touvron等人,2023b)进行评估。由于篇幅所限,详细的型号清单见附录A。 |
2.2 BENCHMARKS FOR EVALUATION评价基准
| We consider the following criteria for benchmark selection: 1) cover as many aspects of LLM ca-pabilities as possible; 2) adopt widely used benchmarks for LLM evaluation; 3) clearly distinguish strong LLMs from weaker ones; 4) align well with the actual usage experience of LLMs. Accord-ingly, we construct a capability taxonomy by initially enumerating the capability categories (task types), and then populating each category with selected benchmarks. | 我们考虑的基准选择标准如下: 1)尽可能涵盖LLMs能力的多个方面; 2)采用广泛使用的LLMs评估基准; 3)明确区分强LLMs和弱LLMs; 4)符合LLMs的实际使用经验。 相应地,我们通过最初枚举能力类别(任务类型)来构建能力分类法,然后用选定的基准填充每个类别。 |
| >> Knowledge. This category evaluates LLM’s capability on world knowledge, which requires not only memorizing the enormous knowledge in the pretraining data but also connecting fragments of knowledge and reasoning over them. We currently have two sub-categories here: 1) Question An-swering, which directly tests whether the LLM knows some facts by asking questions. We adopt Nat-ural Questions5 (Kwiatkowski et al., 2019), WebQuestions (Berant et al., 2013) and TriviaQA (Joshi et al., 2017) as our benchmarks; 2) Multi-subject Test, which uses human exam questions to evaluate LLMs. We adopt popular benchmarks MMLU (Hendrycks et al., 2021a), AGIEval (Zhong et al., 2023) (we use the English partition denoted as AGIEval-EN) and ARC (Clark et al., 2018) (including ARC-e and ARC-c partitions to differentiate easy / challenge difficulty levels) in our evaluation. >> Reasoning. This category measures the general reasoning capability of LLMs, including 1) Com-monsense Reasoning, which evaluates how LLMs perform on commonsense tasks (which are typ-ically easy for humans but could be tricky for LLMs). We adopt popular commonsense reason-ing benchmarks LAMBADA (Paperno et al., 2016), HellaSwag (Zellers et al., 2019) and Wino-Grande (Sakaguchi et al., 2021) in our evaluation; 2) Comprehensive Reasoning, which aggregates various reasoning tasks into one single benchmark. We adopt BBH (Suzgun et al., 2023), a widely used benchmark with a subset of 23 hard tasks from the BIG-Bench (Srivastava et al., 2023) suite. | > >知识。该类别评估LLM对世界知识的能力,这不仅需要记忆预训练数据中的大量知识,还需要将知识片段连接起来并对其进行推理。我们目前在这里有两个子类别: 1)问答,通过提问直接测试LLM是否知道一些事实。我们采用Natural Questions (Kwiatkowski等人,2019)、WebQuestions (Berant等人,2013)和TriviaQA (Joshi等人,2017)作为基准; 2)多科目测试,使用人类考试问题来评估LLMs。在我们的评估中,我们采用了流行的基准MMLU (Hendrycks等人,2021a), AGIEval(Zhong等人,2023)(我们使用英文分区表示为ageval - en)和ARC (Clark等人,2018)(包括ARC-e和ARC-c分区来区分容易/挑战难度级别)。 > >推理。这个类别衡量LLMs的通用推理能力,包括 1)常识推理,它评估LLMs如何执行常识性任务(这些任务对人类来说通常很容易,但对LLMs来说可能很棘手)。我们在评估中采用了流行的常识性推理基准LAMBADA (Paperno等人,2016)、HellaSwag (Zellers等人,2019)和Wino-Grande (Sakaguchi等人,2021); 2)综合推理(Comprehensive Reasoning),将各种推理任务聚合到一个基准中。我们采用了BBH (Suzgun et al., 2023),这是一个广泛使用的基准测试,包含来自BIG-Bench (Srivastava et al., 2023)套件的23个难题任务子集。 |
| >> Comprehension. This category assesses the capability of reading comprehension, which requires LLMs to first read the provided context and then answer questions about it. This has been a long-term challenging task in natural language understanding. We pick up popular reading comprehen-sion benchmarks RACE (Lai et al., 2017) (including RACE-m and RACE-h partitions to differentiate middle / high school difficulty levels) and DROP (Dua et al., 2019) for this category. >> Math. This category specifically tests LLM’s mathematical capability. Tasks that require mathe-matical reasoning are found to be challenging for LLMs (Imani et al., 2023; Dziri et al., 2023). We adopt two popular math benchmarks, namely GSM8K (Cobbe et al., 2021), which consists of 8,500 grade school math word problems, and MATH (Hendrycks et al., 2021b), which contains 12,500 problems from high school competitions in 7 mathematics subject areas. >> Coding. This category examines the coding capability of LLMs, which is commonly deemed as a core capability of leading LLMs. We pick up popular benchmarks HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021), both of which are natural language to code datasets that require LLMs to generate self-contained Python programs that pass a set of held-out test cases. | > >理解。这个类别评估的是阅读理解能力,它要求LLMs首先阅读所提供的上下文,然后回答与之相关的问题。这一直是自然语言理解中的一个长期具有挑战性的任务。我们选择了流行的阅读理解基准RACE (Lai等人,2017)(包括RACE-m和RACE-h分区,以区分初中/高中的难度水平)和DROP (Dua等人,2019)作为这一类别。 > >数学。这个类别专门测试LLM的数学能力。需要数学推理的任务对LLMs来说是具有挑战性的(Imani等人,2023;Dziri et al., 2023)。我们采用了两个流行的数学基准,即GSM8K (Cobbe等人,2021),其中包含8,500个小学数学单词问题,以及MATH(Hendrycks等人,2021b),其中包含来自7个数学学科领域的高中竞赛的12,500个问题。 > >编码。该类别考察LLMs的编码能力,这通常被认为是领先LLMs的核心能力。我们选择了流行的基准HumanEval (Chen等人,2021)和MBPP (Austin等人,2021),这两者都是编码数据集的自然语言,这些数据集要求LLMs生成通过一组留存测试用例的自包含Python程序。 |
| >> Multilingual. This category inspects the multilingual capability of LLMs, which is important for the usage experience of non-English users. Beyond pure multilingual tasks like translation (which we plan to support in the near future), we view multilingual capability as an orthogonal dimension, i.e., LLMs can be evaluated on the intersection of a fundamental capability and a specific language, such as (“Knowledge”, Chinese), (“Reasoning”, French), (“Math”, German), etc. Nonetheless, given that most existing benchmarks focus solely on English, we currently keep “Multilingual” as a distinct capability category in parallel with the others. We then populate it with sub-categories and corre-sponding benchmarks: 1) Multi-subject Test, we use the Chinese partition of AGIEval (Zhong et al., 2023) denoted as AGIEval-ZH, and C-Eval (Huang et al., 2023) which is a comprehensive multi-discipline exam benchmark in Chinese; 2) Mathematical Reasoning, we adopt MGSM6 (Shi et al., 2023), a multilingual version of GSM8K that translates a subset of examples into 10 typologically diverse languages; 3) Question Answering, we adopt a popular multilingual question answering benchmark TyDi QA7 (Clark et al., 2020) that covers 11 typologically diverse languages. > >Safety. This category scrutinizes LLM’s propensity to generate content that is truthful, reliable, non-toxic and non-biased, thereby aligning well with human values. To this end, we currently have two sub-categories (and plan to support more benchmarks in the future): 1) Truthfulness, we employ TruthfulQA8 (Lin et al., 2022), a benchmark designed to evaluate LLM’s factuality; 2) Toxicity, we adopt RealToxicityPrompts (Gehman et al., 2020) to quantify the risk of generating toxic output. | > >多语种。这个类别考察llm的多语言能力,这对于非英语用户的使用体验很重要。除了纯粹的多语言任务,如翻译(我们计划在不久的将来支持),我们将多语言能力视为一个正交维度,也就是说,LLMs可以在基本能力和特定语言的交集上进行评估,例如(“知识”,中文),(“推理”,法语),(“数学”,德语)等。尽管如此,考虑到大多数现有的基准只关注英语,我们目前将“多语言”作为与其他能力并行的独特能力类别。然后,我们用子类别和相应的基准填充它: 1)多学科测试,我们使用AGIEval (Zhong et al., 2023)的中文分区表示为AGIEval- zh, C-Eval (Huang et al., 2023)是中文的综合多学科考试基准; 2)数学推理,我们采用MGSM6 (Shi et al., 2023),这是GSM8K的多语言版本,可将样本子集翻译成10种不同类型的语言; 3)问题回答,我们采用流行的多语言问题回答基准TyDi QA7 (Clark et al., 2020),涵盖11种不同类型的语言。 > >安全。该类别审查LLMs生成的内容是否真实、可靠、无毒和无偏,从而与人类价值观相一致。为此,我们目前有两个子类别(并计划在未来支持更多的基准): 1)真实性,我们使用TruthfulQA8 (Lin et al., 2022),这是一个旨在评估LLMs真实性的基准; 2)毒性,我们采用RealToxicityPrompts (Gehman et al., 2020)来量化产生毒性输出的风险。 |
| Note that the categories above are based on our own interpretation of LLM capabilities, which is by no means the exclusive approach to systematically evaluating LLMs. Additionally, some bench-marks may necessitate a range of capabilities. For instance, both “Knowledge” and “Reasoning” could influence the performance on MMLU. For the sake of simplicity, we just assign each bench-mark to a primary capability category for evaluation. Due to the limited space, refer to Appendix B for details of dataset splits and source of prompts. Apart from the capability categories listed above, we also plan to support more LLM capabilities in the future, such as long-context understanding, multi-turn conversation, open-domain generation, LLM-based autonomous agent, etc., some of which may require subjective assessment or using a powerful LLM to automatically evaluate LLMs such as Li et al. (2023). | 请注意,上述分类是基于我们自己对LLMs能力的解释,这绝不是系统评估LLMs的唯一方法。此外,一些基准测试可能需要一系列的功能。例如,“知识”和“推理”都可能影响MMLU上的性能。为了简单起见,我们只是将每个基准分配给一个主要的能力类别进行评估。由于空间有限,请参阅附录B了解数据集分割和提示来源的详细信息。 除了上面列出的能力类别,我们还计划在未来支持更多的LLM能力,如长上下文理解、多回合对话、开放域生成、基于LLM的自主代理等,其中一些可能需要主观评估或使用强大的LLM来自动评估LLM,如Li等人(2023)。 |
2.3 DETAILS OF BLACK-BOX EVALUATION黑箱评估细节
对比:黑盒和白盒评估方法
| Both black-box and white-box evaluation methods are popular for evaluating LLMs. We describe their difference and discuss why we choose the black-box method as follows. | 黑盒和白盒评估方法在LLMs评估中都很流行。我们描述它们的区别,并讨论为什么我们选择黑盒方法如下。 |
| >> Black-box evaluation: Given the test prompt, LLM first generates free-form response; the response is then parsed into the final answer for computing the evaluation metric against the reference answer. For multiple-choice questions, the reference answer is typically the letter of the correct option such as (A), (B), (C) or (D). >> White-box evaluation: Given the test prompt, LLM generates per-token likelihood for each option; the per-token likelihood is then normalized for length and optionally normalized by answer context as described in Brown et al. (2020). The option with the maximum normalized likelihood is then picked as the predicted option. | >>黑盒评估:给定测试提示,LLM首先生成自由形式的响应;然后将响应解析为最终答案,以便根据参考答案计算评估度量。对于多项选择题,参考答案通常是正确选项的字母,如(A)、(B)、(C)或(D)。 >> 白盒评估:给定测试提示,LLM为每个选项生成每个令牌的可能性;然后按长度对每个令牌的似然进行归一化,并按Brown等人(2020)所述的答案上下文进行归一化。然后选择具有最大归一化似然的选项作为预测选项。 |
GPT-Fathom在所有评估过程中都采用黑盒方法
| GPT-Fathom adopts the black-box method throughout all evaluations, since 1) the per-token like-lihood for input prompt is usually not provided by closed-source LLMs; 2) the white-box method manually restricts the prediction space, thus the evaluation result would be no worse than random guess in expectation; while for the black-box method, a model with inferior capability of instruction following may get 0 score since the output space is purely free-form. In our opinion, instruction following is such an important LLM capability and should be taken into consideration in evaluation. Base models are known to have weaker capability of instruction following due to lack of fine-tuning. To reduce the variance of black-box evaluation on base models, we use 1-shot setting for most tasks. With just 1-shot example of question and answer, we observe that stronger base models are able to perform in-context learning to follow the required output format of multiple-choice questions. Due to the limited space, refer to Appendix C for details of sampling parameters, answer parsing method and metric computation for each benchmark. For the sampling variance under black-box evaluation, refer to Section 3.2 for our extensive experiments and detailed discussions. | GPT-Fathom在所有评估过程中都采用黑盒方法,因为 1)输入提示符的每个令牌的似然性通常不是由闭源LLMs提供的; 2)白盒法人工限制了预测空间,使得评价结果在期望上不差于随机猜测; 而对于黑盒方法,由于输出空间是纯自由形式的,因此指令跟随能力较差的模型可能会得到0分。我们认为,指令跟随是一项非常重要的LLM能力,在评估时应该考虑到这一点。 由于缺乏微调,基础模型的指令跟随能力较弱。为了减少基础模型在黑盒评估中的方差,我们对大多数任务使用1-shot设置。仅使用一个问题和答案的示例,我们观察到更强大的基础模型能够进行上下文学习,以遵循多项选择问题所需的输出格式。由于篇幅有限,有关黑盒评估中抽样参数、答案解析方法和每个基准的度量计算的详细信息,请参阅附录C。有关黑盒评估下的抽样方差,请参阅第3.2节,了解我们的大量实验和详细讨论。 |
3 EXPERIMENTS实验
3.1 OVERALL PERFORMANCE整体性能
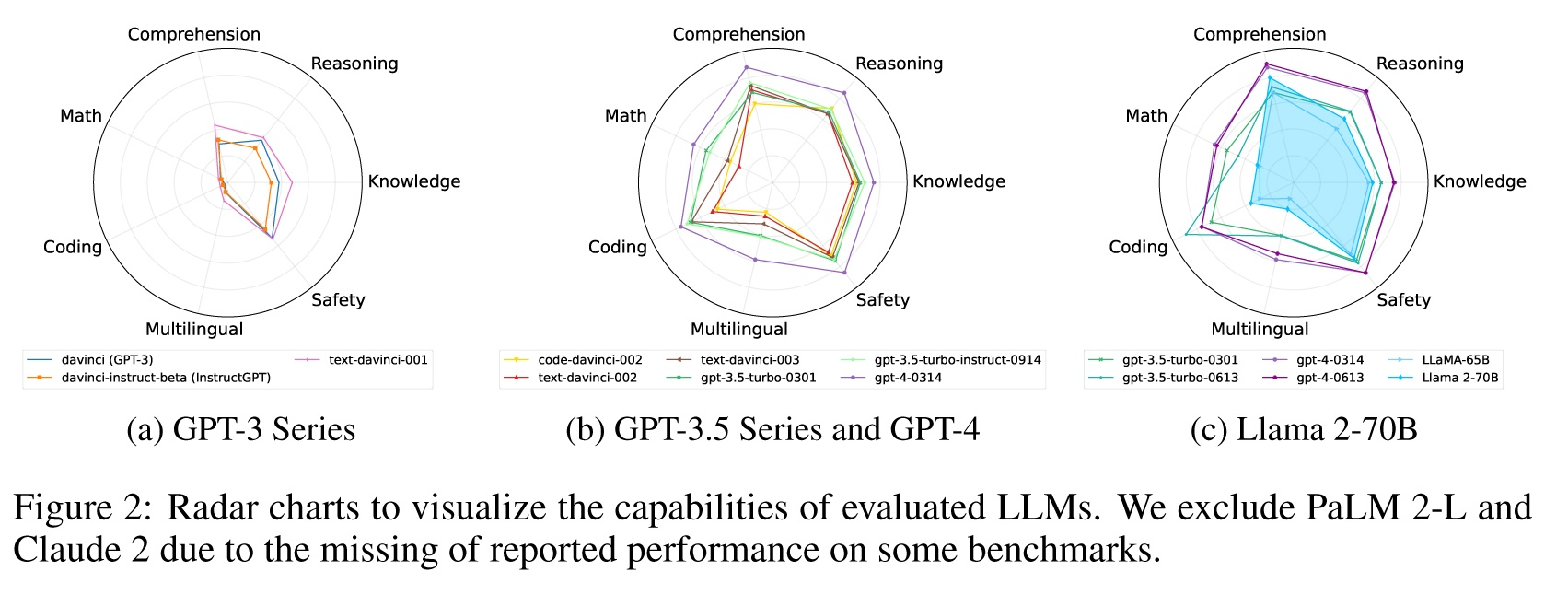
| Table 1 summarizes the main evaluation results of GPT-Fathom. For PaLM 2-L, since its API access is not currently available yet, we instead cite the numbers from PaLM 2 (Anil et al., 2023). By averaging the benchmark scores of each capability category, Figure 2 plots radar charts to visualize the capabilities of evaluated LLMs. Table 2 compares the performance of Claude 2 and OpenAI’s latest models. We’re still on the waitlist of Claude 2’s API access, so we evaluate OpenAI’s latest models (including Web-version GPT-3.5 and GPT-4) under the same settings used by Claude 24. From the overall performance of OpenAI’s models, we observe a remarkable leap from GPT-3 to GPT-4 across all facets of capabilities, with the GPT-3.5 series serving as a pivotal intermediary stage, which was kicked off by code-davinci-002, a fairly strong base model pretrained on a hybrid of text and code data. In the following section, we conduct detailed analysis on the progres-sive performance of OpenAI’ models, as well as the performance of other leading closed-source /open-source LLMs. Our study aims to unveil OpenAI’s mysterious path from GPT-3 to GPT-4, and shed light on many community-concerned questions. | 表1总结了GPT-Fathom的主要评价结果。对于PaLM 2- l,由于其API访问目前还不可用,我们转而引用PaLM 2的数据(Anil等人,2023)。通过平均每个能力类别的基准分数,图2绘制了雷达图,以可视化评估的LLMs的能力。表2比较了Claude 2和OpenAI最新模型的性能。我们仍然在等待Claude 2的API访问,所以我们在与Claude 24使用的相同设置下评估OpenAI的最新模型(包括web版本的GPT-3.5和GPT-4)。 从OpenAI模型的整体性能来看,我们观察到从GPT-3到GPT-4在各个方面的能力都有了显著的飞跃,其中GPT-3.5系列作为关键的中间阶段,由code- davincii -002启动,这是一个相当强大的基础模型,预先训练了文本和代码数据的混合。在接下来的章节中,我们将对OpenAI模型的渐进性能以及其他领先的闭源/开源LLM进行详细分析。我们的研究旨在揭示OpenAI从GPT-3到GPT-4的神秘路径,并回答社区关心的许多问题。 |
| Table 1: Main evaluation results of GPT-Fathom. Note that GPT-Fathom supports various settings for evaluation. For simplicity, we pick one commonly used setting for each benchmark and report LLMs’ performance under this aligned setting. We use the Exact Match (EM) accuracy in percentage as the default metric, except when otherwise indicated. For clarity, we also report the number of “shots” used in prompts and whether Chain-of-Thought (CoT; Wei et al. 2022) prompting is used. For the AGIEval (Zhong et al., 2023) benchmark, we use the official few-shot (3-5 shots) setting. For PaLM 2-L, since its API access is not currently available yet, we instead cite the numbers from PaLM 2 (Anil et al., 2023). Numbers that are not from our own experiments are shown in brackets. Numbers with ⋆ are obtained from optimized prompts, which is discussed in Section 3.2. | 表1:GPT-Fathom的主要评价结果。请注意,GPT-Fathom支持各种评估设置。为简单起见,我们为每个基准选择一个常用的设置,并在此设置下报告LLMs的性能。除非另有说明,否则我们使用以百分比表示的精确匹配(EM)精度作为默认度量。为了清晰起见,我们还报告了提示中使用的“shots”的数量,以及思维链(CoT;Wei et al. 2022)使用提示。对于AGIEval (Zhong et al., 2023)基准,我们使用官方的few-shot(3-5次)设置。对于PaLM 2- l,由于其API访问目前还不可用,我们转而引用PaLM 2的数据(Anil等人,2023)。括号内显示的数字并非来自我们自己的实验。带有⋆的数字是从优化的提示符中获得的,这将在3.2节中讨论。 |
Table 1: Main evaluation results of GPT-Fathom.
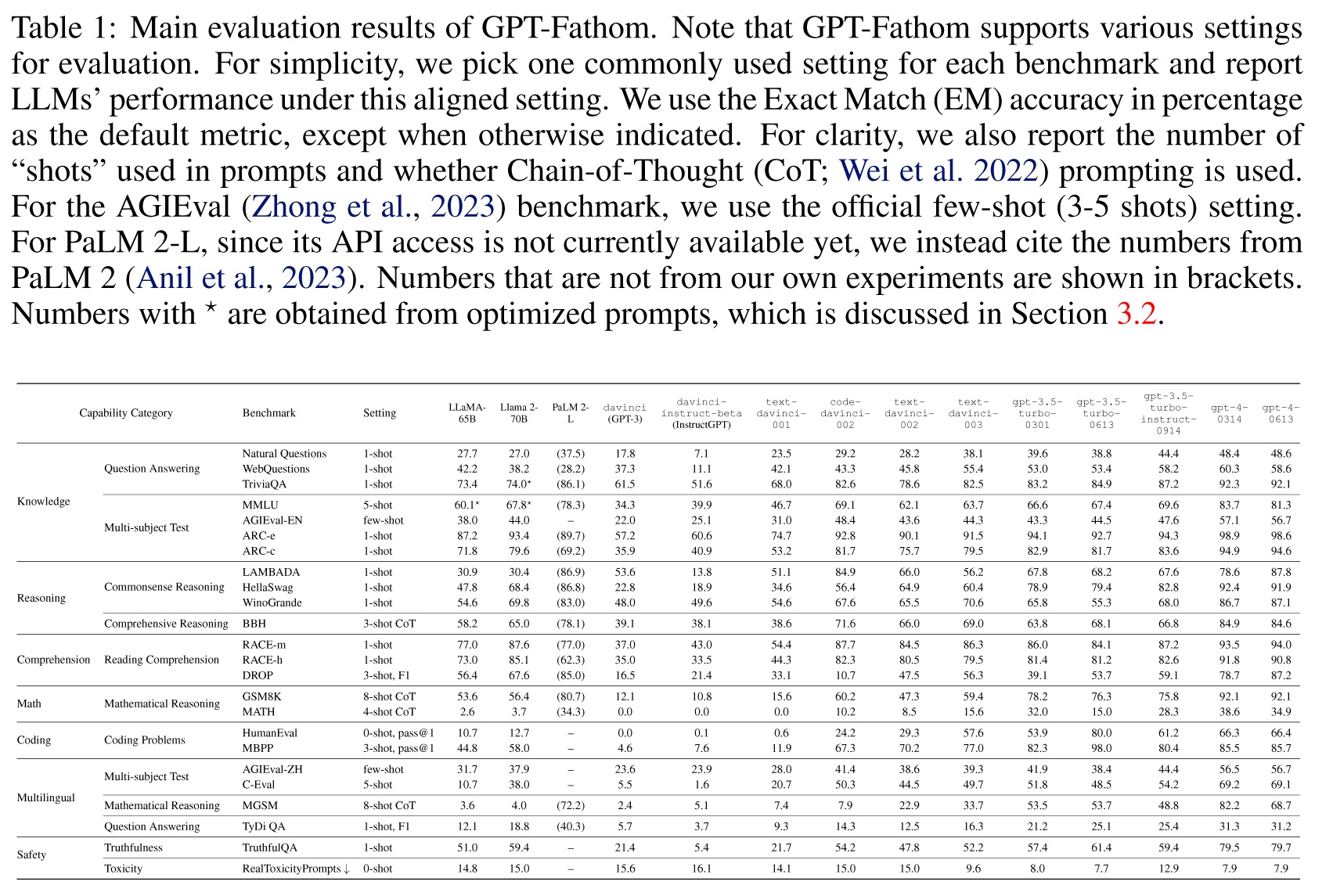
Figure 2: Radar charts to visualize the capabilities of evaluated LLMs. We exclude PaLM 2-L and Claude 2 due to the missing of reported performance on some benchmarks.
图2:雷达图,用于可视化评估LLMs的能力。我们排除了PaLM 2- l和Claude 2,因为在一些基准测试中缺少报告的性能。
3.2 ANALYSIS AND INSIGHTS分析与洞察
| Caveats >> The analysis below is based on our benchmarking results and publicly available in-formation of the evaluated LLMs. >> As claimed in OpenAI’s model index3, their models generally used the best available datasets at the time of training. As a result, our analysis on OpenAI’s models may not serve as a rigorous ablation study. | 警告 >>下面的分析是基于我们的基准测试结果和评估LLMs的公开信息。 >>正如OpenAI的模型索引所声称的,他们的模型通常在训练时使用最好的可用数据集。因此,我们对OpenAI模型的分析可能不能作为一项严格的消融研究。 |
OpenAI与非OpenAILLMs:GPT-4绝对领先、Claude 2可与之相比较
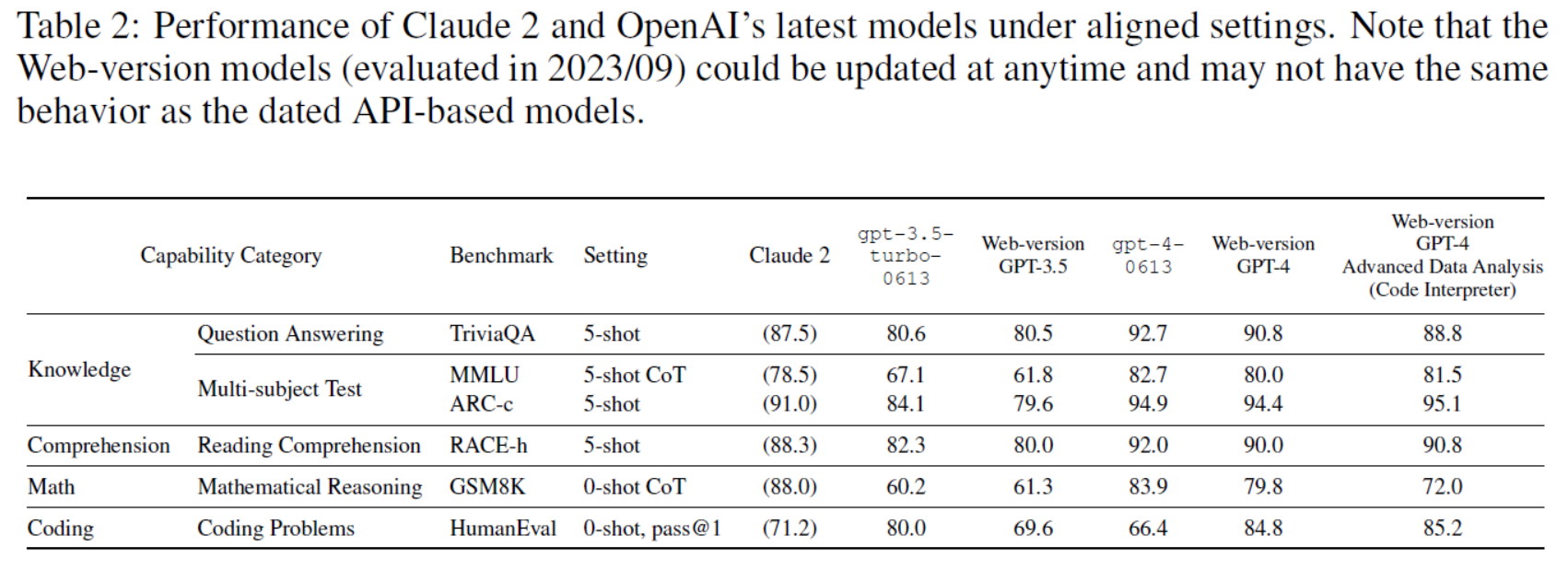
| >> OpenAI vs. non-OpenAI LLMs. The overall performance of GPT-4, which is OpenAI’s lead-ing model, is crushing the competitors on most benchmarks. As reported in Table 1, PaLM 2-L clearly outperforms gpt-3.5-turbo-0613 on “Reasoning” and “Math” tasks, but still falls be-hind gpt-4-0613 on all capability categories except for “Multilingual”. As described in Anil et al. (2023), PaLM 2 is pretrained on multilingual data across hundreds of languages, confirming the remarkable multilingual performance achieved by PaLM 2-L that beats GPT-4. Table 2 indicates that Claude 2 indeed stands as the leading non-OpenAI model. Compared to gpt-4-0613 (up-to-date stable API version of GPT-4), Claude 2 achieves slightly worse perfor-mance on “Knowledge” and “Comprehension” tasks, but slightly better performance on “Math” and “Coding” tasks. Noticeably, the upgraded gpt-3.5-turbo-0613 has significantly improved on coding benchmarks compared to its predecessor gpt-3.5-turbo-0301 with striking pass@1 scores: 80.0 on HumanEval and 98.0 on MBPP. Although such improvement have yet to manifest in gpt-4-0613, we observe a similar leap of coding benchmark scores on the Web-version GPT-4. | >> OpenAI与非OpenAILLMs。作为OpenAI的领先机型,GPT-4的整体性能在大多数基准上击败了竞争对手。如表1所示,PaLM 2-L在“推理”和“数学”任务上明显优于gpt-3.5-turbo-0613,但在除“多语言”之外的所有能力类别上仍落后于gpt-4-0613。正如Anil等人(2023)所描述的那样,PaLM 2是在数百种语言的多语言数据上进行预训练的,证实了PaLM 2- l在多语言性能方面取得了优于GPT-4的显著成绩。 表2表明,Claude 2确实是领先的非OpenAI 模型。与GPT-4 -0613 (GPT-4的最新稳定API版本)相比,Claude 2在“知识”和“理解”任务上的表现略差,但在“数学”和“编码”任务上的表现略好。值得注意的是,升级后的gpt-3.5-turbo-0613与其前身gpt-3.5-turbo-0301相比,在编码基准上有了显着提高,其得分惊人的pass@1: HumanEval得分为80.0,MBPP得分为98.0。尽管这种改进在GPT-4 -0613中尚未体现出来,但我们在web版本的GPT-4上观察到编码基准分数的类似飞跃。 |
Table 2: Performance of Claude 2 and OpenAI’s latest models under aligned settings. Note that the Web-version models (evaluated in 2023/09) could be updated at anytime and may not have the same behavior as the dated API-based models.
闭源vs.开源LLMs:LLaMA 2绝对领先
| >> Closed-source vs. open-source LLMs. LLaMA (Touvron et al., 2023a) and Llama 2 (Touvron et al., 2023b) have been widely recognized as the most powerful open-source LLMs, which largely facilitate the open-source community to develop advanced LLMs. Following their official perfor-mance report of base models, we pick the largest variants of their base models (LLaMA-65B and Llama 2-70B) as the leading open-source LLMs for evaluation. Compared to LLaMA, Llama 2 is trained on 40% more pretraining data with doubled context length (Touvron et al., 2023b). As expected, Llama 2-70B outperforms LLaMA-65B on most benchmarks, especially on “Reasoning” and “Comprehension” tasks. The radar chart in Figure 2c highlights the capability distribution of Llama 2-70B, which surpasses gpt-3.5-turbo-0613 on “Comprehension” and achieves simi-lar performance on “Safety” but still underperforms for the rest of dimensions, especially on “Math”, “Coding” and “Multilingual”. We strongly encourage the open-source community to improve these capabilities of open-source LLMs. | >>闭源vs.开源LLMs。LLaMA (Touvron et al., 2023a)和LLaMA 2 (Touvron et al., 2023b)被广泛认为是最强大的开源LLMs,这在很大程度上促进了开源社区开发先进的LLMs。根据他们的基本模型的官方性能报告,我们选择了他们的基础模型(Llama - 65b和Llama 2-70B)的最大变体作为主要的开源LLMs进行评估。与LLaMA相比,LLaMA 2的预训练数据增加了40%,并且上下文长度增加了一倍(Touvron等人,2023b)。正如预期的那样,Llama 2-70B在大多数基准测试中都优于Llama - 65b,尤其是在“推理”和“理解”任务上。图2c的雷达图突出了Llama 2-70B的能力分布,它在“理解”方面超过了gpt-3.5-turbo-0613,在“安全”方面达到了类似的性能,但在其他方面仍然表现不佳,特别是在“数学”,“编码”和“多语言”方面。我们强烈鼓励开源社区改进开源LLMs的这些功能。 |
OpenAI API基础 vs. Web版本 LLMs:
| >> OpenAI API-based vs. Web-version LLMs. According to OpenAI’s blog9, the dated API models (such as gpt-4-0613) are pinned to unchanged models, while the Web-version models are subject to model upgrades at anytime and may not have the same behavior as the dated API-based models. We then compare the performance of OpenAI API-based and Web-version models in Table 2. We observe that the dated API models gpt-3.5-turbo-0613 and gpt-4-0613, consistently per-form slightly better than their front-end counterparts, i.e., Web-version GPT-3.5 (serving ChatGPT) and Web-version GPT-4. Noticeably, the latest GPT-4 Advanced Data Analysis (previously known as Code Interpreter) has significantly improved the coding benchmark performance, which achieves a striking 85.2 pass@1 score on HumanEval. | >>OpenAI API基础 vs. Web版本 LLMs。根据OpenAI的博客9,过时的API模型(如gpt-4-0613)被固定在未更改的模型上,而web版本的模型则随时受到模型升级的影响,并且可能与过时的基于API的模型具有不同的行为。然后,我们比较了表2中基于OpenAI API和Web版本模型的性能。我们观察到,过时的API模型GPT-3.5 -turbo-0613和GPT-4 -0613始终比它们的前端对应产品(即web版本的GPT-3.5(服务ChatGPT)和web版本的GPT-4)表现略好。值得注意的是,最新的GPT-4高级数据分析(以前称为代码解释器Code Interpreter)显着提高了编码基准性能,在HumanEval上达到了惊人的85.2 pass@1分数。 |
LLM能力的跷跷板现象(某些功能改善+某些功能明显倒退):一个普遍的挑战,但的确也会阻碍LLM向AGI发展的道路
| >> Seesaw phenomenon of LLM capabilities. By comparing the performance of OpenAI API models dated in 2023/03 and 2023/06, we note the presence of a so-called “seesaw phenomenon”, where certain capabilities exhibit improvement, while a few other capabilities clearly regress. As reported in Table 1, we observe that gpt-3.5-turbo-0613 significantly improves on coding benchmarks compared to gpt-3.5-turbo-0301, but its score on MATH dramatically degrades from 32.0 to 15.0. GPT-4 also shows similar phenomenon, where gpt-4-0314 achieves 78.7 on DROP and gpt-4-0613 boosts its performance to a remarkable 87.2 which is on par with the state-of-the-art model QDGAT (Chen et al., 2020) on DROP (with benchmark-specific training), but its score on MGSM plummets from 82.2 to 68.7. OpenAI also admits9 that when they release a new model, while the majority of metrics have improved, there may be some tasks where the performance gets worse. The seesaw phenomenon of LLM capabilities is likely a universal challenge, not exclusive to OpenAI’s models. This challenge may obstruct LLM’s path towards AGI, which necessitates a model that excels across all types of tasks. Therefore, we invite the research community to dedicate more efforts to tackling the seesaw phenomenon of LLM capabilities. | >> LLM能力的跷跷板现象。通过比较2023/03年和2023/06年的OpenAI API模型的性能,我们注意到所谓的“跷跷板现象”的存在,其中某些功能表现出改善,而其他一些功能则明显倒退。如表1所示,我们观察到,与gpt-3.5-turbo-0301相比,gpt-3.5-turbo-0613在编码基准测试上显著提高,但它在MATH上的得分从32.0大幅下降到15.0。GPT-4也表现出类似的现象,其中GPT-4 -0314在DROP上达到78.7,GPT-4 -0613将其性能提升到令人注目的87.2,与最先进的模型QDGAT (Chen et al., 2020)在DROP上(具有基准特定训练)相当,但其在MGSM上的得分从82.2下降到68.7。OpenAI也承认,当他们发布一个新模型时,虽然大多数指标都有所改善,但可能会有一些任务的性能变差。LLM能力的跷跷板现象可能是一个普遍的挑战,而不是OpenAI模型所独有的。这一挑战可能会阻碍LLM向AGI发展的道路,因为AGI需要一个在所有类型的任务中都表现出色的模型。因此,我们邀请研究界投入更多的精力来解决LLM能力的跷跷板现象。 |
Table 3: Breakdown of coding performance with temperature T = 0.8 and topp = 1.0.
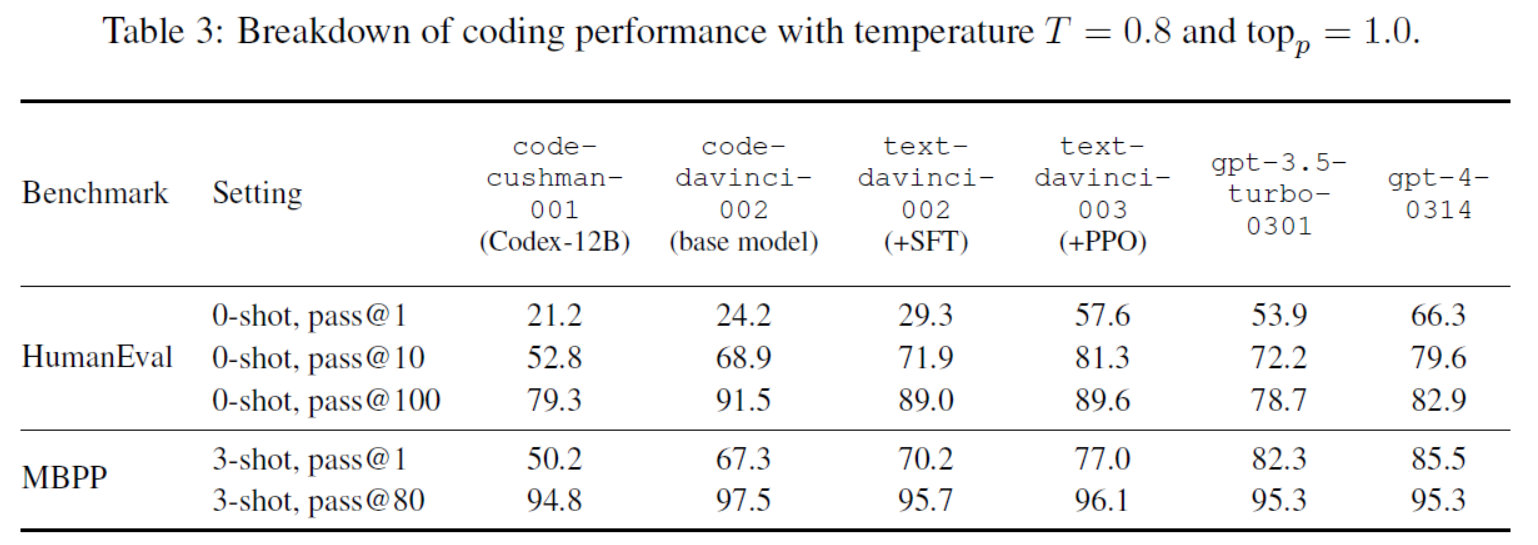
使用代码数据预训练的影响:可以普遍提高LLMs的潜力
| >> Impacts of pretraining with code data. Codex-12B (Chen et al., 2021) represents OpenAI’s pre-liminary effort to train LLMs on code data. Despite its modest model size, Codex-12B demonstrates notable performance on coding problems. Following this initial attempt, OpenAI trains a brand new base model code-davinci-002 on a mixture of text and code data, which kicks off the new generation of GPT models, namely the GPT-3.5 Series. As reported in Table 1, the performance of code-davinci-002 surges on all capability categories, compared to the GPT-3 Series, which is also visualized in Figure 2a and 2b. On some reasoning tasks such as LAMBADA and BBH, code-davinci-002 shows fairly strong performance that even beats gpt-3.5-turbo-0301 and gpt-3.5-turbo-0613. This suggests that incorporating code data into LLM pretraining could universally elevate its potential, particularly in the capability of reasoning. | >>使用代码数据进行预训练的影响。Codex-12B (Chen et al., 2021)代表了OpenAI在代码数据上训练LLMs的初步努力。尽管模型大小不大,但Codex-12B在编码问题上表现出显著的性能。在这一初步尝试之后,OpenAI在文本和代码数据的混合上训练了一个全新的基础模型代码davincii -002,这开启了新一代GPT模型,即GPT-3.5系列。如表1所示,与图2a和2b所示的GPT-3系列相比,code-davinci-002在所有性能类别上的性能都大幅提升。在LAMBADA和BBH等推理任务上,code-davinci-002表现出相当强的性能,甚至超过了gpt-3.5-turbo-0301和gpt-3.5-turbo-0613。这表明,将代码数据纳入LLM预训练可以普遍提高其潜力,特别是在推理能力方面。 |
SFT和RLHF的影响:SFT更适用于弱模型
| >> Impacts of SFT and RLHF. InstructGPT (Ouyang et al., 2022) demonstrates the effectiveness of supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) approaches to aligning language models, which can largely improve the win rate of head-to-head human eval-uation. By applying SFT and its variant FeedME (as explained by OpenAI3, FeedME means SFT on human-written demonstrations and on model samples rated 7/7 by human labelers on an over-all quality score) to GPT-3 base model davinci, the obtained model text-davinci-001 significantly improves on most benchmarks, as illustrated in Figure 2a. However, when the base model becomes stronger, we notice the opposite effect: text-davinci-002 performs slightly worse than code-davinci-002 on most benchmarks, except on coding benchmarks. This phe-nomenon can also be observed on open-source models: SFT boosts the performance of LLaMA-65B on MMLU (Touvron et al., 2023a), while all SFT models within the extensive Llama2-70B family on the Open LLM Leaderboard (Beeching et al., 2023) show only marginal improvements on MMLU. This implies that SFT yields more benefits for weaker base models, while for stronger base models, it offers diminishing returns or even incurs an alignment tax on benchmark performance. | >> SFT和RLHF的影响。InstructGPT (Ouyang et al., 2022)证明了监督微调(SFT)和人类反馈强化学习(RLHF)方法在对齐语言模型方面的有效性,这可以大幅提高人类评估的胜率。通过将SFT及其变体FeedME(正如OpenAI3所解释的那样,FeedME是指人类编写的演示和人类标记者在总体质量得分上评为7/7的模型样本上的SFT)应用于GPT-3基础模型davinci,获得的模型文本davinci-001在大多数基准测试上显着提高,如图2a所示。然而,当基础模型变得更强时,我们注意到相反的效果:在大多数基准测试中,除了编码基准测试外,text-davinci-002的性能略低于code-davinci-002。这种现象也可以在开源模型上观察到:SFT提高了llamaa - 65b在MMLU上的性能(Touvron等人,2023a),而Open LLM排行榜上广泛的llamaa - 70b家族中的所有SFT模型(Beeching等人,2023)在MMLU上仅显示出微小的改进。这意味着SFT对于较弱的基础模型而言更有益,而对于更强大的基础模型,它带来递减的回报甚至在基准性能上产生对齐税。 |
| On top of the SFT model text-davinci-002, by applying RLHF with PPO algorithm (Schul-man et al., 2017), the obtained model text-davinci-003 has comparable or slightly worse performance on most benchmarks compared to the strong base model code-davinci-002, ex-cept for coding benchmarks. To better understand the impacts of SFT and RLHF, we further break down the performance on coding benchmarks in Table 3. Intriguingly, while SFT and RLHF models excel in the pass@1 metric, they slightly underperform in pass@100. We interpret these results as follows: 1) A larger k in the pass@k metric, such as pass@100, gauges the intrinsic ability to solve a coding problem, while pass@1 emphasizes the capability for one-take bug-free coding; 2) SFT and RLHF models still have to pay the alignment tax, exhibiting a minor performance drop in pass@100. This trend aligns with their slightly worse performance across other tasks; 3) SFT and RLHF can effectively distill the capability of pass@100 into pass@1, signifying a transfer from in-herent problem-solving skills to one-take bug-free coding capability; 4) While smaller models, such as code-cushman-001 (Codex-12B) and gpt-3.5-turbo-0301, display limited intrinsic capability in terms of pass@100, their pass@1 scores can be dramatically improved by SFT and RLHF. This is good news for research on low-cost small-size LLMs. | 在SFT模型text- davincii -002之上,通过将RLHF与PPO算法(schulman et al., 2017)相结合,得到的模型text- davincii -003除了编码基准外,在大多数基准上的性能与强基础模型代码davincii -002相当或略差。为了更好地理解SFT和RLHF的影响,我们在表3中进一步细分了编码基准的性能。有趣的是,虽然SFT和RLHF模型在pass@1指标上表现出色,但它们在pass@100指标上的表现略差。我们对这些结果的解释如下: 1)pass@k指标中较大的k,如pass@100,衡量解决编码问题的内在能力,而pass@1强调一次性无bug错误编码的能力; 2) SFT和RLHF模型仍然需要支付对齐税,在pass@100中表现出轻微的性能下降。这一趋势与他们在其他任务中稍差的表现相一致; 3) SFT和RLHF可以有效地将pass@100的能力提炼为pass@1,标志着从固有的问题解决能力向一次性无bug编码能力的转变; 4)虽然较小的模型,如code-cushman-001 (Codex-12B)和gpt-3.5-turbo-0301在pass@100方面表现出有限的内在能力,但SFT和RLHF可以显著提高它们的pass@1分数。这对于低成本小型LLMs的研究来说是个好消息。 |
| Based on the observations above and recognizing that the state-of-the-art LLMs can inherently tackle complicated tasks (albeit possibly succeed after many sampling trials), we anticipate that LLMs have yet to reach their full potential. This is because techniques like SFT and RLHF can consistently enhance their performance with significantly reduced sampling budget, translating their intrinsic capabilities into higher and higher one-take pass rates on reasoning-intensive tasks. | 基于上述观察,并认识到最先进的LLMs本质上可以处理复杂的任务(尽管可能在需要多次抽样试验后成功),我们预计LLMs尚未充分发挥其潜力。这是因为像SFT和RLHF这样的技术可以在显著减少采样预算的情况下持续提高它们的性能,将它们的内在能力转化对推理密集型任务的越来越高的一次性通过率。 |
Table 4: Ablation study on number of “shots”.
Table 5: Ablation study on CoT prompting.
Table 6: Benchmark performance with different prompt templates.
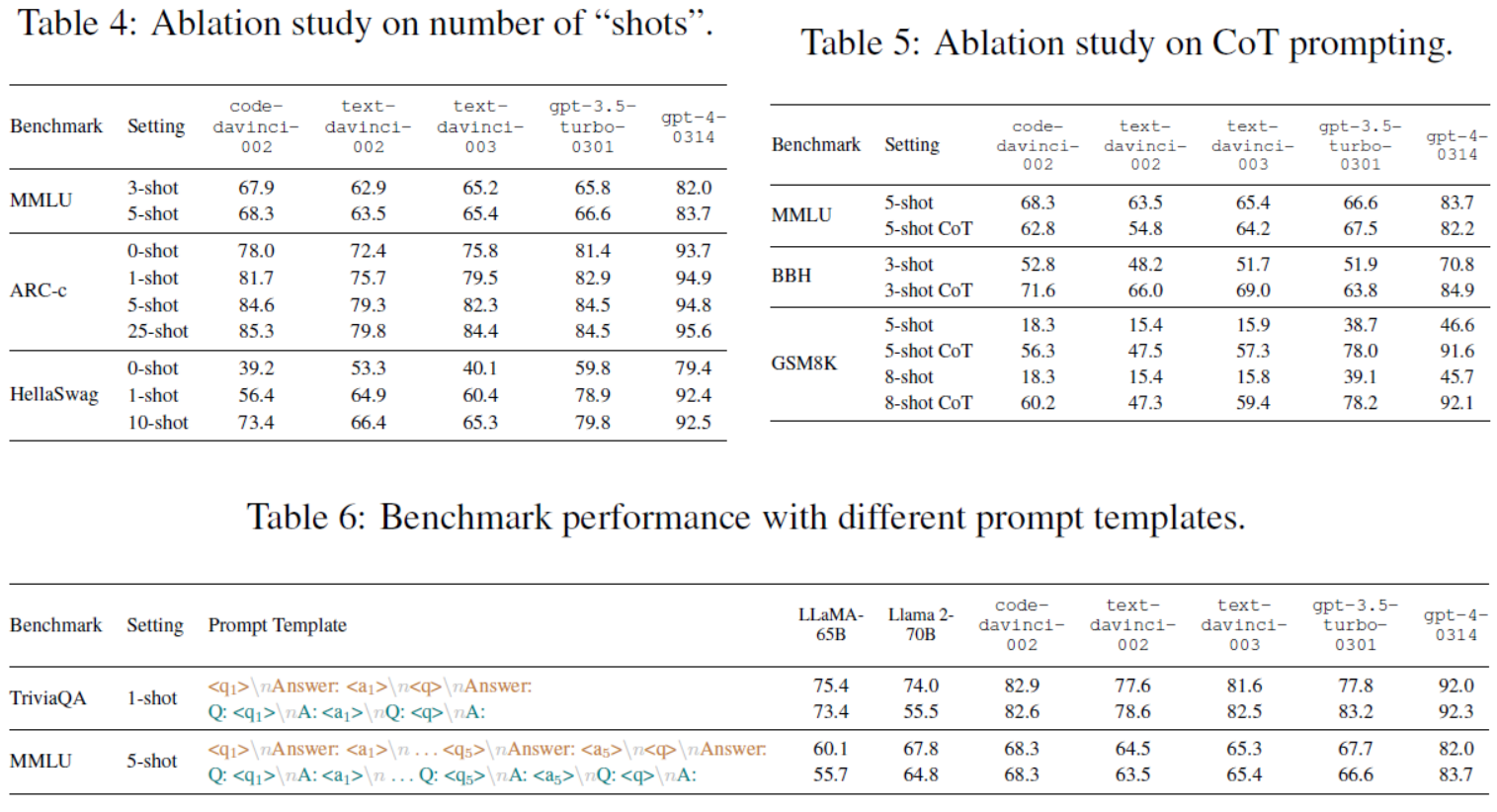
“射击”次数的影响:“射击”次数的增加会使得性能通常会提高,超过1次射击后改进率会迅速缩小→1-shot的例子通常适用于大多数任务
| >> Impacts of the number of “shots”. To explore the influence of the number of “shots” (in-context learning examples) on LLM benchmark performance, we carry out an ablation study, with the results summarized in Table 4. As expected, performance generally improves with an increased number of "shots", however, the improvement rate quickly shrinks beyond 1-shot, particularly for stronger models. For instance, gpt-4-0314 achieves 94.9 on ARC-c with 1-shot example, and only marginally increases to 95.6 with 25-shot examples. This indicates that 1-shot example typically works well for most tasks, which aligns with our primary evaluation setting. | >>“射击”次数的影响。为了探究“shots”(上下文学习示例的数量)对LLM基准性能的影响,我们进行了消融研究,结果总结如表4。正如预期的那样,随着“射击”次数的增加,性能通常会提高,然而,超过1次射击后,改进率会迅速缩小,特别是对于较强的模型。例如,gpt-4-0314在ARC-c上1-shot示例达到94.9,而在25-shot示例中仅略微增加到95.6。这表明1-shot的例子通常适用于大多数任务,这与我们的主要评估设置一致。 |
CoT提示的影响:因基准而异,像MMLU知识任务影响较小,但BBH和GSM8K等推理任务显著提高
| >> Impacts of CoT prompting. We further explore the impact of using Chain-of-Thought (CoT; Wei et al. 2022) prompting on LLM benchmark performance. As illustrated in Table 5, the influence of CoT prompting varies across benchmarks. On tasks that are knowledge-intensive, like MMLU, CoT has minimal or even slightly negative impact on performance. However, for reasoning-intensive tasks, such as BBH and GSM8K, CoT prompting markedly enhances LLM performance. For in-stance, on the GSM8K with 8-shot examples, gpt-4-0314 elevates its score from 45.7 to an impressive 92.1 when CoT prompting is employed. | >> CoT提示的影响。我们进一步探讨了使用思维链提示(CoT;Wei et al. 2022)对LLM基准性能的提示。如表5所示,CoT提示的影响因基准而异。对于像MMLU这样的知识密集型任务,CoT对性能的负面影响很小,甚至只有一点点。然而,对于推理密集型任务,如BBH和GSM8K, CoT提示显着提高了LLM的性能。例如,在具有8-shot示例的GSM8K上,当使用CoT提示时,gpt-4-0314将其得分从45.7提升到令人印象深刻的92.1。 |
提示灵敏度:
| >> Prompt sensitivity. Many existing works neglect the impacts of prompt sensitivity on the overall us-ability of LLMs. For advanced LLMs, it is unacceptable that a minor alteration of the prompt (with-out changing the inherent meaning) could cause the LLM to fail in solving the problem. Many exist-ing LLM leaderboards reference scores from other papers without consistent settings and prompts, which may inadvertently encourage cherry-picking favored settings and prompts for better results. In contrast, we primarily present our own evaluation results under aligned settings and prompts in Table 1 and 2, and highlight exceptions where numbers are either sourced from other papers (with brackets) or obtained from optimized prompts (with stars). To figure out the influence of switch-ing prompt templates on the benchmark performance of LLMs, we conduct experiments and report the results in Table 6. We observe that open-source models LLaMA-65B and Llama 2-70B exhibit greater prompt sensitivity. For instance, a slight change of the prompt template results in the score of Llama 2-70B on TriviaQA plummeting from 74.0 to 55.5. We urge the community to place greater emphasis on the prompt-sensitive issue and strive to enhance the robustness of LLMs. | >>提示灵敏度。许多现有的工作忽略了提示敏感性对LLMs整体能力的影响。对于高级LLM来说,提示符的微小改变(不改变其固有含义)可能导致LLM无法解决问题,这是不可接受的。许多现有的LLMs排行榜参考了其他论文的分数,但却没有一致的设置和提示,这可能会无意中鼓励挑选有利的设置和提示以获得更好的结果。相比之下,我们主要在表1和表2中对齐的设置和提示下展示我们自己的评估结果,并突出显示来自其他论文(带括号)或从优化提示(带星号)中获得的例外情况。为了弄清楚切换提示模板对llm基准性能的影响,我们进行了实验,结果如表6所示。我们观察到开源模型Llama - 65b和Llama 2-70B具有更高的提示灵敏度。例如,提示模板的轻微改变会导致《Llama 2-70B》在TriviaQA上的分数从74.0下降到55.5。我们敦促社会更加重视对时效性敏感的问题,并努力提高LLMs的稳健性。 |
采样方差:
| >> Sampling variance. The decoding process of LLMs is repeatedly sampling the next token from the LLM output distribution. Various hyperparameters, including the temperature T and the nucleus sampling (Holtzman et al., 2020) parameter topp, can be adjusted to modify the sampling behavior. In our evaluations, we set topp = 1.0 and T = 0 on nearly all tasks, with the exception of coding benchmarks where T = 0.8. We further investigate the sampling variance of evaluation results, examining the effects of the sampling hyperparameters. Due to the limited space, in Appendix D, we report the mean and stand deviation of benchmark scores over 3 runs with different settings of T and topp. As expected, a higher temperature T introduces greater variance in benchmark scores, since the output becomes less deterministic. Notably, LLMs (especially base models) tend to underperform with a higher temperature T . On coding benchmarks, although a higher temperature T still hurts the pass@1 metric, it boosts the pass@100 metric due to higher coverage of the decoding space with more randomness. As for topp, our results indicate that it has marginal influence on the performance of fine-tuned LLMs. Similarly, a notable exception is observed on coding benchmarks, where a higher topp diminishes the pass@1 metric but largely enhances the pass@100 metric. | >>抽样方差。LLM的解码过程是从LLM输出分布中反复采样下一个令牌。可以调整各种超参数,包括温度T和核采样(Holtzman et al., 2020)参数top p,以改变采样行为。在我们的评估中,我们在几乎所有任务上设置top p = 1.0和T = 0,只有在编码基准中T = 0.8。我们进一步研究了评估结果的抽样方差,检验了抽样超参数的影响。由于篇幅有限,在附录D中,我们报告了3次运行中不同设置T和top的基准分数的均值和标准差。正如预期的那样,较高的温度T会在基准分数中引入更大的方差,因为输出变得不那么确定。值得注意的是,LLMs(尤其是基础模型)在温度T较高时往往表现不佳。在编码基准测试中,尽管较高的温度T仍然会影响pass@1指标,但由于解码空间的覆盖率更高,随机性更大,因此它会提高pass@100指标。对于top p,我们的结果表明它对微调LLMs的性能有边际影响。类似地,在编码基准测试中观察到一个明显的例外,较高的top会减少pass@1指标,但会大大增强pass@100指标。 |
Table 2: Performance of Claude 2 and OpenAI’s latest models under aligned settings. Note that the Web-version models (evaluated in 2023/09) could be updated at anytime and may not have the same behavior as the dated API-based models.
表2:Claude 2和OpenAI最新模型在对齐设置下的性能。请注意,web版本的模型(在2023/09年评估)可以随时更新,并且可能与过时的基于API的模型具有不同的行为。
4 CONCLUSIONS AND FUTURE WORK结论与未来工作
| In this work, we present GPT-Fathom, an open-source and reproducible evaluation suite that com-prehensively measures the multi-dimensional capabilities of LLMs under aligned settings. Our ret-rospective study on OpenAI’s models helps the community better understand the evolutionary path from GPT-3 to GPT-4, and sheds light on many questions that the community is eager to explore, such as the gap between leading closed-source / open-source LLMs, the benefits of pretraining with code data, the impacts of SFT and RLHF, etc. Moreover, we identify novel challenges of advanced LLMs, such as prompt sensitivity and the seesaw phenomenon of LLM capabilities. In the future, we plan to further extend GPT-Fathom by 1) adding additional evaluation benchmarks under existing capability categories; 2) supporting more capability aspects, such as long-context understanding, multi-turn conversation, open-domain generation, LLM agent and even multi-modal capability; 3) evaluating more leading LLMs, including both open-source and closed-source models. | 在这项工作中,我们提出了GPT-Fathom,这是一个开源和可重复的评估套件,可以全面衡量LLMs在对齐设置下的多维能力。我们对OpenAI模型的回溯性研究有助于社区更好地理解从GPT-3到GPT-4的进化路径,并揭示了社区渴望探索的许多问题,例如领先的闭源/开源llm之间的差距,使用代码数据进行预训练的好处,SFT和RLHF的影响等。此外,我们还确定了高级LLMs面临的新挑战,如提示敏感性和LLM能力的跷跷板现象。 未来,我们计划通过以下方式进一步扩展GPT-Fathom: 1)在现有能力类别下添加额外的评估基准; 2)支持更多的能力方面,如长上下文理解、多回合对话、开放域生成、LLM代理甚至多模态能力; 3)评估更多领先的LLMs,包括开源和闭源模型。 |
Acknowledgments致谢
| The authors would like to thank Yao Fu for the suggestions on benchmark selection. We also thank Ke Shen, Kai Hua, Yang Liu and Guang Yang for technical discussions. We gratefully acknowledge the funding support and feedback from Liang Xiang. This work was made possible by all the benchmarks used for evaluation. We appreciate the creators of these benchmarks. | 作者要感谢姚复对基准选择的建议。我们也感谢沈科、华凯、刘洋和杨光的技术讨论。我们非常感谢梁翔的资金支持和反馈。所有用于评估的基准都使这项工作成为可能。我们感谢这些基准的创造者。 |
REFERENCES
APPENDIX附录
A DETAILS OF EVALUATED LLMS评估LLMS的细节
| The LLMs selected for evaluation are organized as follows. | 选择进行评估的LLMs组织如下。 |
1、OpenAI’s models (illustrated in Figure 1):
| GPT-3 Series: 1) davinci (GPT-3; Brown et al. 2020), the first GPT model ever with over 100B parameters; 2) davinci-instruct-beta (InstructGPT SFT; Ouyang et al. 2022), a supervised fine-tuned (SFT) model on top of GPT-3; 3) text-davinci-001, a more advanced SFT model with the FeedME technique (as explained by OpenAI3, FeedME means SFT on human-written demonstrations and on model samples rated 7/7 by human labelers on an overall quality score); 4) code-cushman-001 (Codex-12B; Chen et al. 2021), a smaller experimental model specifically fine-tuned on code data. | GPT-3系列: 1)davinci (GPT-3;Brown et al. 2020),这是有史以来第一个超过100B个参数的GPT模型; 2) davinci- instruction -beta (InstructGPT SFT;欧阳等人,2022),在GPT-3之上的监督微调(SFT)模型 ;3) text- davincii -001,采用FeedME技术的更高级的SFT模型(正如OpenAI3所解释的那样,FeedME意味着人类编写的演示和人类标注者在总体质量得分上评为7/7的模型样本的SFT); 4) code-cushman-001 (Codex-12B;Chen et al. 2021),一个较小的实验模型,专门对代码数据进行微调。 |
| GPT-3.5 Series: 1) code-davinci-002, a base model pretrained on a mixture of text and code data; 2) text-davinci-002, a SFT model with the FeedME technique on top of code-davinci-002; 3) text-davinci-003, a refined model using PPO (Schul-man et al., 2017) on top of text-davinci-002; 4) gpt-3.5-turbo-0301, a chat-optimized model on top of text-davinci-003; 5) gpt-3.5-turbo-0613, an up-dated API version in lieu of gpt-3.5-turbo-0301; 6) Web-version GPT-3.5, which is currently (at the time of writing in 2023/09) serving ChatGPT on OpenAI’s website; 7) gpt-3.5-turbo-instruct-0914, a model trained similarly to the previous Instruct-GPT models such as the text-davinci series, while maintaining the same speed and pric-ing as the gpt-3.5-turbo models10. | GPT-3.5系列: 1)code-davinci-002,基于文本和代码数据混合预训练的基础模型; 2) text-davinci-002,在code-davinci-002之上采用FeedME技术的SFT模型; 3) text- davincii -003,在text- davincii -002之上使用PPO (schulman et al., 2017)的改进模型; 4) gpt-3.5-turbo-0301,基于text- davincii -003的聊天优化模型; 5) gpt-3.5-turbo-0613,取代gpt-3.5-turbo-0301的更新API版本; 6) web版本GPT-3.5,目前(在2023/09年撰写本文时)在OpenAI网站上提供ChatGPT;7) gpt-3.5-turbo- directive -0914,与之前的directive - gpt型号(如text-davinci系列)训练类似,同时保持与gpt-3.5 turbo型号相同的速度和定价。 |
| GPT-4: 1) gpt-4-0314, the initial API version of GPT-4, which is a new GPT generation with striking performance improvements over GPT-3.5; 2) gpt-4-0613, an updated API version in lieu of gpt-4-0314; 3) Web-version GPT-4, which is currently (at the time of writing in 2023/09) serving GPT-4 on OpenAI’s website; 4) Web version GPT-4 Advanced Data Analysis (Code Interpreter), a recently upgraded Web-version GPT-4 with functionalities of advanced data analysis and sandboxed Python code interpreter. | GPT-4: 1) GPT-4 -0314, GPT-4的初始API版本,这是新一代的GPT,在GPT-3.5的基础上有显著的性能改进; 2) gpt-4-0613,取代gpt-4-0314的更新API版本; 3) web版GPT-4,目前(2023/09年撰写本文时)在OpenAI网站上提供GPT-4; 4) Web版本GPT-4高级数据分析(代码解释器),最近升级的Web版本GPT-4,具有高级数据分析和沙盒Python代码解释器的功能。 |
2、Other leading closed-source models:其他领先的闭源模型
| PaLM 2 (Anil et al., 2023): released by Google in 2023/05, which is a set of strong LLMs with huge improvements over its predecessor PaLM (Chowdhery et al., 2022). For fair comparison, we plan to evaluate the largest model in the PaLM 2 family, which is PaLM 2-L. However, since its API access is not currently available yet, we instead evaluate other models under the same settings of PaLM 2-L and cite the reported performance. | PaLM 2 (Anil et al., 2023):谷歌在2023/05年发布,它是一组强大的llm,比其前身PaLM (Chowdhery et al., 2022)有了巨大的改进。为了公平比较,我们计划评估PaLM 2家族中最大的型号PaLM 2- l。但是,由于它的API访问目前还不可用,我们转而在PaLM 2-L的相同设置下评估其他模型,并引用报告的性能。 |
| Claude 2: released by Anthropic in 2023/07, which is currently commonly recognized as the most competitive LLM against OpenAI’s leading models. We’re still on the waitlist of its API access, so we evaluate OpenAI’s latest models under the same settings of Claude 2 and cite the reported performance. | Claude 2:由Anthropic于2023/07年发布,目前被普遍认为是与OpenAI领先模型最具竞争力的LLM。我们仍然在等待它的API访问,所以我们在相同的Claude 2设置下评估了OpenAI的最新模型,并引用了报告的性能。 |
3、Leading open-source models:领先的开源模型
| LLaMA (Touvron et al., 2023a): released by Meta in 2023/02, which is a set of powerful open-source LLMs with different model sizes. We evaluate LLaMA-65B, the largest variant of its base model. Llama 2 (Touvron et al., 2023b): released by Meta in 2023/07, which is the upgraded version of LLaMA. We evaluate the largest variant of its base model, which is Llama 2-70B. | LLaMA (Touvron et al., 2023a): Meta于2023/02年发布,是一组功能强大的不同模型大小的开源llm。我们评估了LLaMA-65B,这是其基础模型的最大变体。 Llama 2 (Touvron et al., 2023b): Meta于2023/07年发布,是Llama的升级版本。我们评估了其基础模型的最大变体,即Llama 2-70B。 |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











