







 本文详细介绍了OLLAMA,一款支持本地运行大型语言模型的工具,涉及模型库、安装步骤、快速入门、自定义模型(包括从GGUF和PyTorch导入)、CLI和RESTAPI使用,以及多种案例应用如Llama3部署和RAG功能实现。
本文详细介绍了OLLAMA,一款支持本地运行大型语言模型的工具,涉及模型库、安装步骤、快速入门、自定义模型(包括从GGUF和PyTorch导入)、CLI和RESTAPI使用,以及多种案例应用如Llama3部署和RAG功能实现。
LLM之Ollama:ollama的简介、安装和使用方法、案例应用之详细攻略
目录
可以使用提示来定制 Ollama 库中的模型。例如,要定制 llama2 模型:
ollama的案例应用—Ollama的两种实现模式:聊天模式、服务器模式
LLMs之DeepSeek:仅需四个步骤的最简练实现DeepSeek-R1推理—基于Ollama框架实现本地部署并启用DeepSeek-R1模型服务图文教程
T2、基于Ollama后端框架结合WebUI界面+采用Docker部署服务实现Ollama的GUI聊天模式
T3、基于Ollama后端框架并开启服务器模式+并结合AnythingLLM实现本地知识库问答
T4、基于Ollama后端框架结合Dify前端框架实现RAG
LLMs之RAG:基于Ollama后端框架(配置phi3/LLaMA-3模型)结合Dify前端框架(设置知识库文件+向量化存储+应用发布)创建包括实现本地知识库问答/翻译助手等多个应用
ollama的简介
ollama是一款可以开始使用本地的大型语言模型。启动并运行大型语言模型。运行Llama 2、Code Llama和其他模型。自定义并创建您自己的模型。
官网:Ollama
1、模型库
Ollama 支持 ollama.com/library 上可用的一系列模型。
注意:运行 7B 模型时,您应至少有 8GB 的可用 RAM,运行 13B 模型时需要 16GB,运行 33B 模型时需要 32GB。
以下是一些可下载的示例模型:
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Dolphin Phi | 2.7B | 1.6GB | ollama run dolphin-phi |
| Phi-2 | 2.7B | 1.7GB | ollama run phi |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| Vicuna | 7B | 3.8GB | ollama run vicuna |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
ollama的安装和使用方法
实战安装案例:https://yunyaniu.blog.csdn.net/article/details/138235781
1、下载
macOS、Windows、Linux
macOS:https://ollama.com/download/Ollama-darwin.zip
Windows:https://ollama.com/download/OllamaSetup.exe
Linux:
curl -fsSL https://ollama.com/install.sh | sh手动安装说明:ollama/docs/linux.md at main · ollama/ollama · GitHub
Docker
Ollama 官方 Docker 镜像 ollama/ollama 已在 Docker Hub 上可用。
https://hub.docker.com/r/ollama/ollama
相关库
ollama-python
ollama-js2、快速入门
要运行并与 Llama 2 聊天:
ollama run llama23、自定义模型
从 GGUF 导入
# 从 GGUF 导入:Ollama 支持在 Modelfile 中导入 GGUF 模型:
创建一个名为 Modelfile 的文件,其中包含一个 FROM 指令,指向要导入的模型的本地文件路径。FROM ./vicuna-33b.Q4_0.gguf
# 在 Ollama 中创建模型
ollama create example -f Modelfile
# 运行模型
ollama run example从 PyTorch 或 Safetensors 导入
有关导入模型的指南,请参阅指南。
ollama/docs/import.md at main · ollama/ollama · GitHub
自定义提示
可以使用提示来定制 Ollama 库中的模型。例如,要定制 llama2 模型:
ollama pull llama2创建一个 Modelfile:
FROM llama2
PARAMETER temperature 1 将温度设置为 1 [较高为更具创造性,较低为更连贯]
# set the system message设置系统消息
SYSTEM """
You are Mario from Super Mario Bros. Answer as Mario, the assistant, only.
""
FROM llama2接下来,创建并运行模型:
ollama create mario -f ./Modelfile
ollama run mario
>>> hi
Hello! It's your friend Mario.有关更多示例,请参阅示例目录。有关使用 Modelfile 的更多信息,请参阅 Modelfile 文档。
4、CLI 参考
# 创建模型:使用 Modelfile 创建模型的命令是 ollama create。
ollama create mymodel -f ./Modelfile
# 拉取模型:此命令还可用于更新本地模型。只会拉取差异。
ollama pull llama2
# 删除模型
ollama rm llama2
# 复制模型
ollama cp llama2 my-llama2
多行输入:对于多行输入,可以使用"""
>>> """Hello,
... world!
... """
I'm a basic program that prints the famous "Hello, world!" message to the console.
# 多模态模型
>>> What's in this image? /Users/jmorgan/Desktop/smile.png
The image features a yellow smiley face, which is likely the central focus of the picture.
# 将prompt作为参数传递
$ ollama run llama2 "Summarize this file: $(cat README.md)"
Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications.
# 列出计算机上的型号
ollama list
# 开始Ollama:在不运行桌面应用程序的情况下启动Ollama时使用Ollama服务。
ollama serve
5、构建
安装 cmake 和 go
# 安装 cmake 和 go:
brew install cmake go
# 然后生成依赖项:
go generate ./...
# 然后构建二进制文件:
go build .
有关更详细的说明,请参阅开发人员指南
运行本地构建
# 接下来,启动服务器:
./ollama serve
# 最后,在另一个 shell 中,运行一个模型:
./ollama run llama26、REST API
Ollama 具有用于运行和管理模型的 REST API。
生成响应
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt":"天空为什么是蓝色?"
}'与模型聊天
curl http://localhost:11434/api/chat -d '{
"model": "mistral",
"messages": [
{ "role": "user", "content": "天空为什么是蓝色?" }
]
}'有关所有端点的 API 文档,请参阅 API 文档。
ollama的案例应用—Ollama的两种实现模式:聊天模式、服务器模式
持续更新中……
T1、在Dos内直接实现Ollama的CLI聊天模式
官网查找下载模型的命令→Dos内执行下载→执行对话聊天
模型地址:library
ollama run llama3:8b
ollama run llama3:70b
ollama run phi3
ollama run phi3:3.8b-mini-instruct-4k-fp16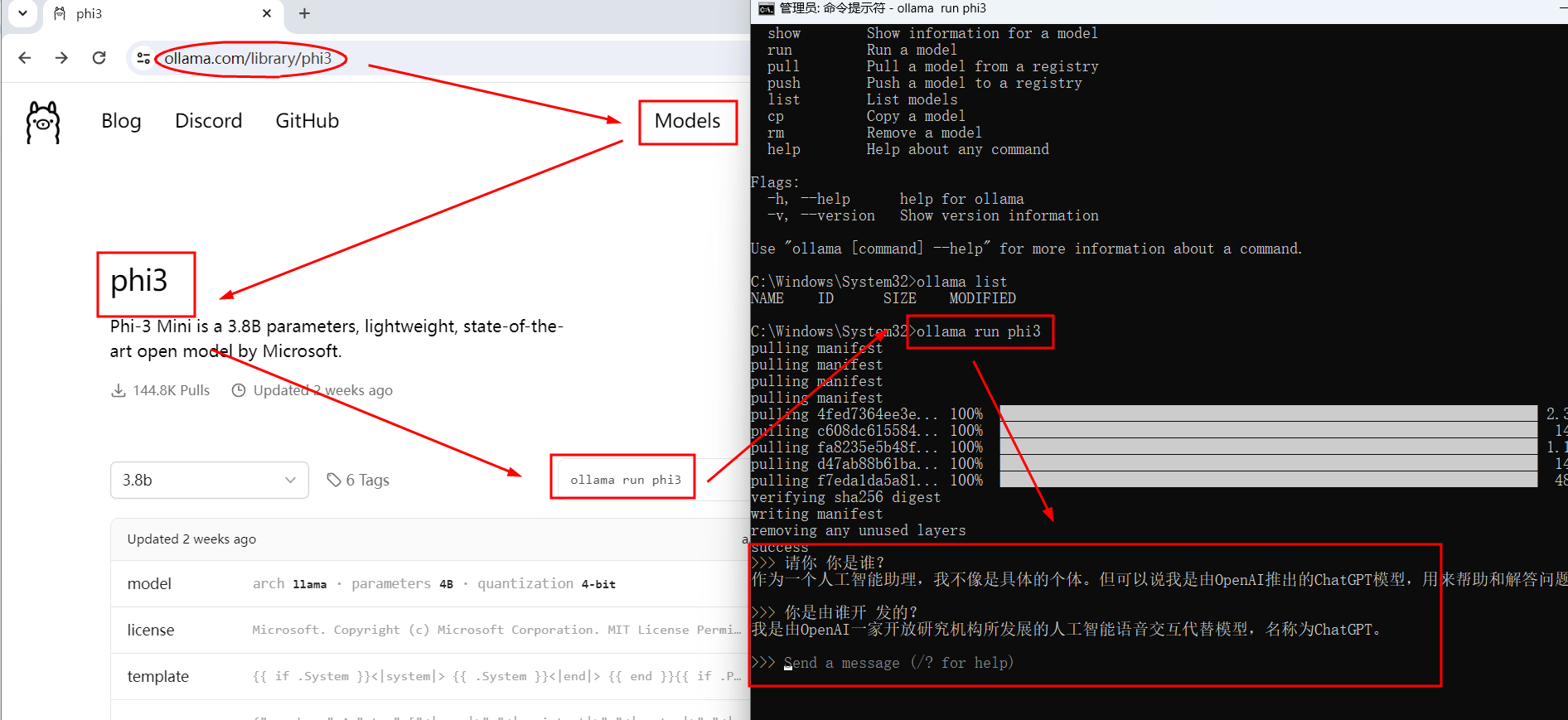
LLMs之DeepSeek:仅需四个步骤的最简练实现DeepSeek-R1推理—基于Ollama框架实现本地部署并启用DeepSeek-R1模型服务图文教程
LLMs之DeepSeek:仅需四个步骤的最简练实现DeepSeek-R1推理—基于Ollama框架实现本地部署并启用DeepSeek-R1模型服务图文教程-CSDN博客
T2、基于Ollama后端框架结合WebUI界面+采用Docker部署服务实现Ollama的GUI聊天模式
LLMs之Llama3:手把手教你(只需四步)基于ollama框架(安装并配置)及其WebUI界面对LLaMA-3-8B模型进行Docker部署(打包依赖项+简化部署过程+提高可移植性)并测试对话和图像生成功能
https://yunyaniu.blog.csdn.net/article/details/138235781
T3、基于Ollama后端框架并开启服务器模式+并结合AnythingLLM实现本地知识库问答
LLMs之RAG:基于Ollama框架(开启服务器模式+加载LLMs)部署LLaMA3/Phi-3等大语言模型、并结合AnythingLLM框架(配置参数LLM Preference【LLM Provider-Chat Model】 /Embedding Preference/Vector Database)实现RAG功能(包括本地文档和抓取网页)实现Chat聊天以及本地知识库问答实战
https://yunyaniu.blog.csdn.net/article/details/138514062
T4、基于Ollama后端框架结合Dify前端框架实现RAG
LLMs之RAG:基于Ollama后端框架(配置phi3/LLaMA-3模型)结合Dify前端框架(设置知识库文件+向量化存储+应用发布)创建包括实现本地知识库问答/翻译助手等多个应用
https://yunyaniu.blog.csdn.net/article/details/138514081




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











