









MLM之RAG:探索基于LangChain和Redis的新多模态RAG模板实战
导读:本文主要提出了一个多模态RAG框架模板,结合Redis和LangChain来解决传统RAG仅限于文本的不足。
背景和痛点:传统RAG仅能处理文本数据,无法很好利用图像、图表等信息富集型数据;
许多报告或PPT中包含丰富的图像信息,传统RAG无法提取和利用这部分信息。
方案论点:
>> 提出使用Redis和GPT4-V等多模态模型来实现检索和生成功能,支持处理文本和图像两种类型数据;
>> 提出将图像和文本结合索引存储在Redis中,供模型同时访问和利用;
>> 将图像提取为基64编码字符串存储,文本提取关键信息形成嵌入向量进行存储,共同关联一个主键支持检索;
框架设计
>> 提取报告中的文本摘要和图像信息,使用GPT4-V和嵌入模型进行处理;
>> 将处理后的信息存储在Redis中,构建多模态文档索引库;
>> 输入查询后,同时检索相关文本和图像,使用GPT4-V进行多源信息综合生成回答;
优势
>> 相比仅文本的RAG,支持结合图像等多种信息类型,回答质量得以提升;
>> 借助Redis高效存储和检索能力,提高了系统性能;
>> 采用标准处理和存储流程,扩展性好,可作为通用多模态RAG模板。
总之,该文章提出了一个面向Redis和多模态模型的通用RAG模板,支持同时处理文本和图像,利用图像信息丰富回答内容,解决了传统RAG在利用信息富集型数据上的不足,具有很好的扩展性。
目录
《Explore the new Multimodal RAG template from LangChain and Redis》
相关文章
《Explore the new Multimodal RAG template from LangChain and Redis》
| 地址 | 地址:Explore Redis & LangChain's Multimodal RAG Template - Redis |
| 时间 | 2024 年 5 月16日 |
| 作者 | Tyler Hutcherson,Lance Martin |
LLMs的限制与RAG的介绍
大型语言模型(LLMs)是在大量公共数据集上训练的,并且擅长根据这些信息生成类似人类的文本。然而,它们无法访问私人或企业数据,这限制了它们在企业用例中的有效性。检索增强生成(RAG)是一种流行的方法,用于将LLMs与这些专业数据连接起来,扩展它们的知识库到初始训练数据之外。通过RAG,公司正在使用LLMs回答关于其独特文档和数据的问题。
RAG的工作原理
RAG通过将检索组件整合到生成过程中来工作。应用程序首先根据输入查询检索相关文档,然后综合这些信息以生成响应。这种方法不仅提供了更深层次的背景,还通过最新信息增强了模型的响应,与传统LLMs相比提供了更准确和相关的响应。
文本和图像的多模态RAG
然而,大多数RAG方法专注于文本,忽略了幻灯片演示或报告中包含的信息丰富的图像或图表。随着多模型模型的兴起,例如GPT4-V,可以直接将图像传递到LLMs进行推理。然而,在与文本和图像无缝配合的RAG框架的发展方面存在差距。
Redis和LangChain的创新
Redis和LangChain通过引入多模态RAG模板来超越文本。通过整合视觉数据,这个模板允许模型跨文本和图像进行处理和推理,为更全面和细致的AI应用铺平了道路。我们很高兴地提出了一个系统,不仅可以阅读文本,还可以解释图像,有效地结合这些来源以增强理解和响应准确性。
使用指南
在本文中,我们将介绍多模态RAG,并详细说明模板的设置步骤,展示一些示例查询以及使用多模态RAG的好处。还将超越简单的RAG,并讨论了RAG的典型流水线。
典型的RAG流程
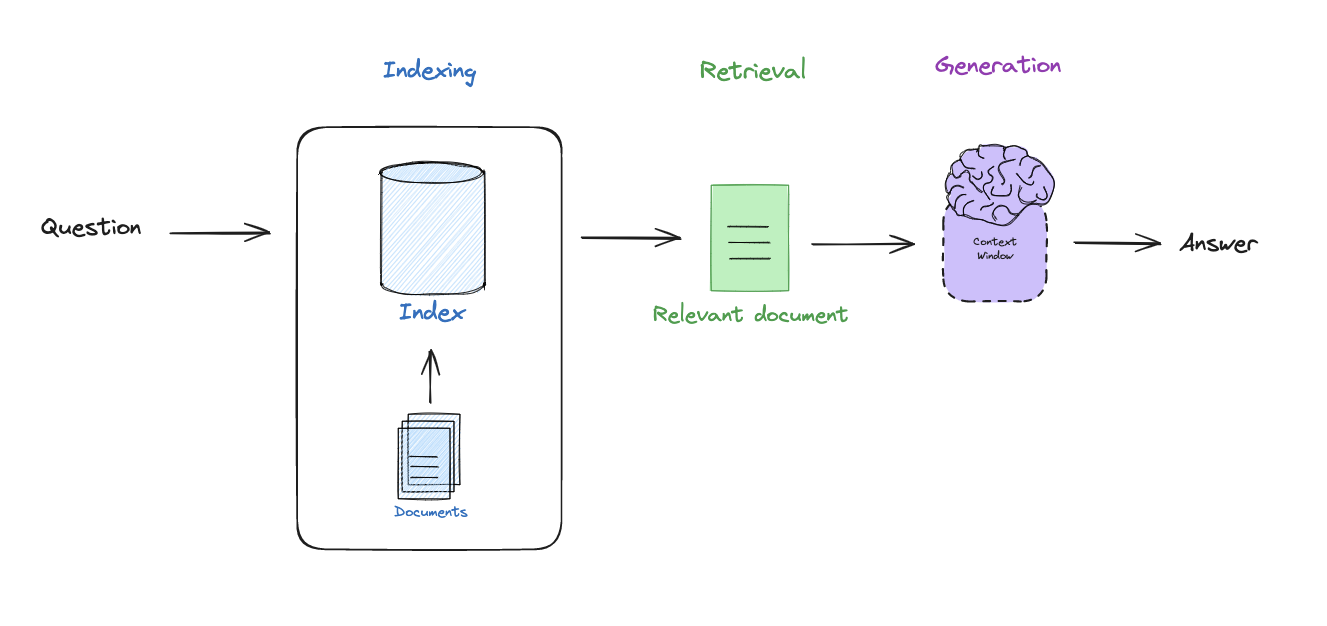
典型的RAG流水线涉及使用向量嵌入和元数据对文本文档进行索引,从数据库中检索相关上下文,形成基于实地的提示,并使用LLMs合成答案。有关更多信息,请参阅LangChain的视频系列“从零开始的RAG”。
处理非文本数据
但是,对于像图像或图形这样的非文本数据呢?对于这些其他数据类型,我们必须通过独特的过程提取语义。例如,考虑分析Nvidia Q3 FY24投资者演示的幻灯片演示。幻灯片是文本、图像、表格和图表的组合。标准PDF提取技术只会提取文本,将信息丰富的图像留在检索范围之外。
使用多模态RAG
幸运的是,我们可以使用Redis的灵活数据结构和OpenAI的综合文本和视觉模型GPT4-V的创新功能来解决这个问题。为了设置多模态RAG流水线,我们首先进行了一些预处理步骤:
>> 使用GPT4-V提取幻灯片摘要作为文本
>> 使用OpenAI的嵌入模型嵌入文本摘要
>> 在Redis哈希中索引文本摘要嵌入,由主键引用
>> 将原始图像编码为base64字符串,并将其存储在带有主键的Redis哈希中
对于这种用例,LangChain提供了MultiVector Retriever以有效地索引文档和摘要。这种方法的好处在于,我们可以像处理任何其他文本一样使用常用的文本嵌入来索引图像摘要,而无需使用更专门化且不太成熟的多模态嵌入。
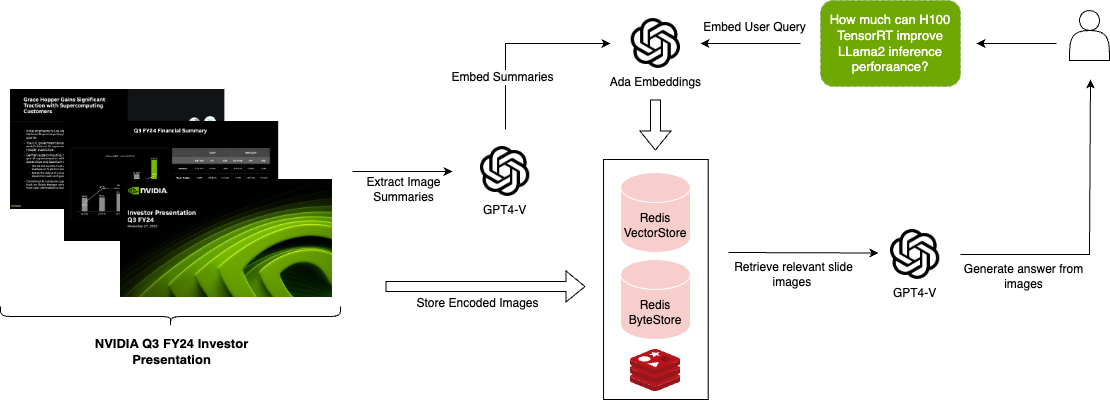
使用RAG模板启动
在运行时,当用户提出问题时:
>> 使用OpenAI嵌入用户问题。
>> 根据嵌入的图像摘要从Redis检索相关图像。
>> 使用主键从Redis中查找原始图像。
>> 使用原始图像和原始问题使用GPT4-V生成有根据的答案。
分析
随着RAG功能的不断发展,许多人预计这样的过程将对数据库和LLMs产生更多的检索调用,从而创建复合AI系统。每个额外的步骤都会增加延迟和成本。Redis语义缓存减少了对重复问题的数据库和LLMs的调用次数,消除了冗余工作。语义缓存的工作原理是存储先前回答的问题的响应。然后,当提出类似的问题时,应用程序从缓存中检索该存储的答案,而不是发起对数据库的重复调用和对LLMs的另一个昂贵的调用。通过消除频繁提问的额外步骤,应用程序可以加快响应速度,并显着降低调用LLMs的成本。
使用RAG模板启动
在启动应用程序之前,您需要一个(免费的)Redis Cloud实例和一个OpenAI API密钥。
设置环境变量
设置您的OpenAI API密钥和Redis URL环境变量:
export OPENAI_API_KEY=<your-openai-api-key> export REDIS_URL=redis://:<redis-pwd>@<redis-host>:<redis-port>安装LangChain CLI
在您的Python环境中安装LangChain CLI:
pip install -U langchain-cli创建LangChain应用
创建一个新的LangChain应用:
langchain app new my-app cd my-app这将创建一个名为my-app的新目录,其中包含两个文件夹:
- app:LangServe代码所在的位置
- packages:您的链或代理所在的位置
添加多模态RAG包
添加多模态RAG包:
langchain app add rag-redis-multi-modal-multi-vector在提示安装模板时,选择yes选项,即y。
配置服务器文件
在您的app/server.py文件中添加以下片段:
from rag_redis_multi_modal_multi_vector.chain import chain as rag_redis_chain add_routes( app, rag_redis_chain, path="/rag-redis-multi-modal-multi-vector" )导入演示应用程序的源数据
为演示应用程序导入源数据:
cd packages/rag-redis-multi-modal-multi-vector poetry install poetry run python ingest.py这可能需要几分钟。ingest.py脚本执行一个流水线,加载幻灯片图像,使用GPT4-V提取摘要,并创建文本嵌入。
启动FastAPI应用
使用LangServe启动FastAPI应用:
cd ../../ langchain serve访问API并测试
在http://127.0.0.1:8000上访问API,并通过http://127.0.0.1:8000/playground测试您的应用程序:
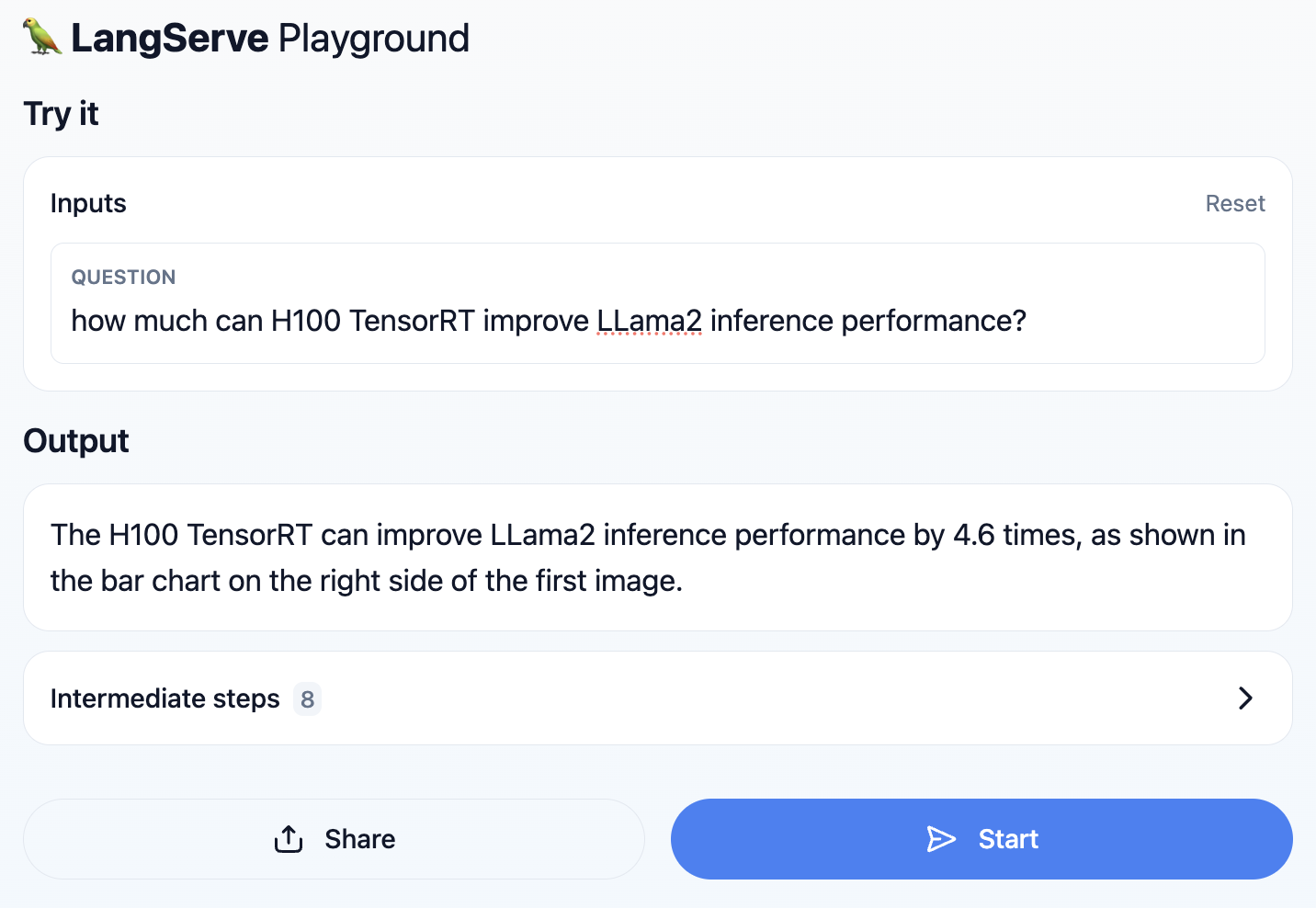
通过快速检查幻灯片演示文稿中的PDF图像来验证RAG系统的答案。
总结
有了新的多模态RAG模板,开发人员现在可以构建复杂的AI应用程序,这些应用程序可以理解和利用由单个后端技术Redis支持的多样化数据类型。
通过设置一个免费的Redis Cloud实例并使用新的Redis <> LangChain来开始。有关其他新兴RAG概念的见解,请探索与Lance Martin、Nuno Campos和Tyler Hutcherson的最近会话。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











