









LLMs之KGQA:fact-finder的简介、安装和使用方法、案例应用之详细攻略
目录
第一步,调用LM生成Cypher查询:使用语言模型调用来生成针对知识图谱的 Cypher 查询。
第二步,Cypher查询预处理:使用正则表达式预处理生成的 Cypher 查询。
第三步,图查询:使用 Cypher 预处理的最终结果查询图。
fact-finder的简介
2024年5月,基于知识图谱的智能问答系统fact-finder,通过结合LLM和Neo4j数据库,实现了用户问题到自然语言答案的自动化转换。系统特点包括利用Neo4j数据库存储和管理知识图谱以供查询,使用语言模型将问题自动转化为Cypher查询并生成回答,整个过程无需手动干预,实现了查询与回答的自动化。
GitHub地址:GitHub - chrschy/fact-finder
1、解读流程图
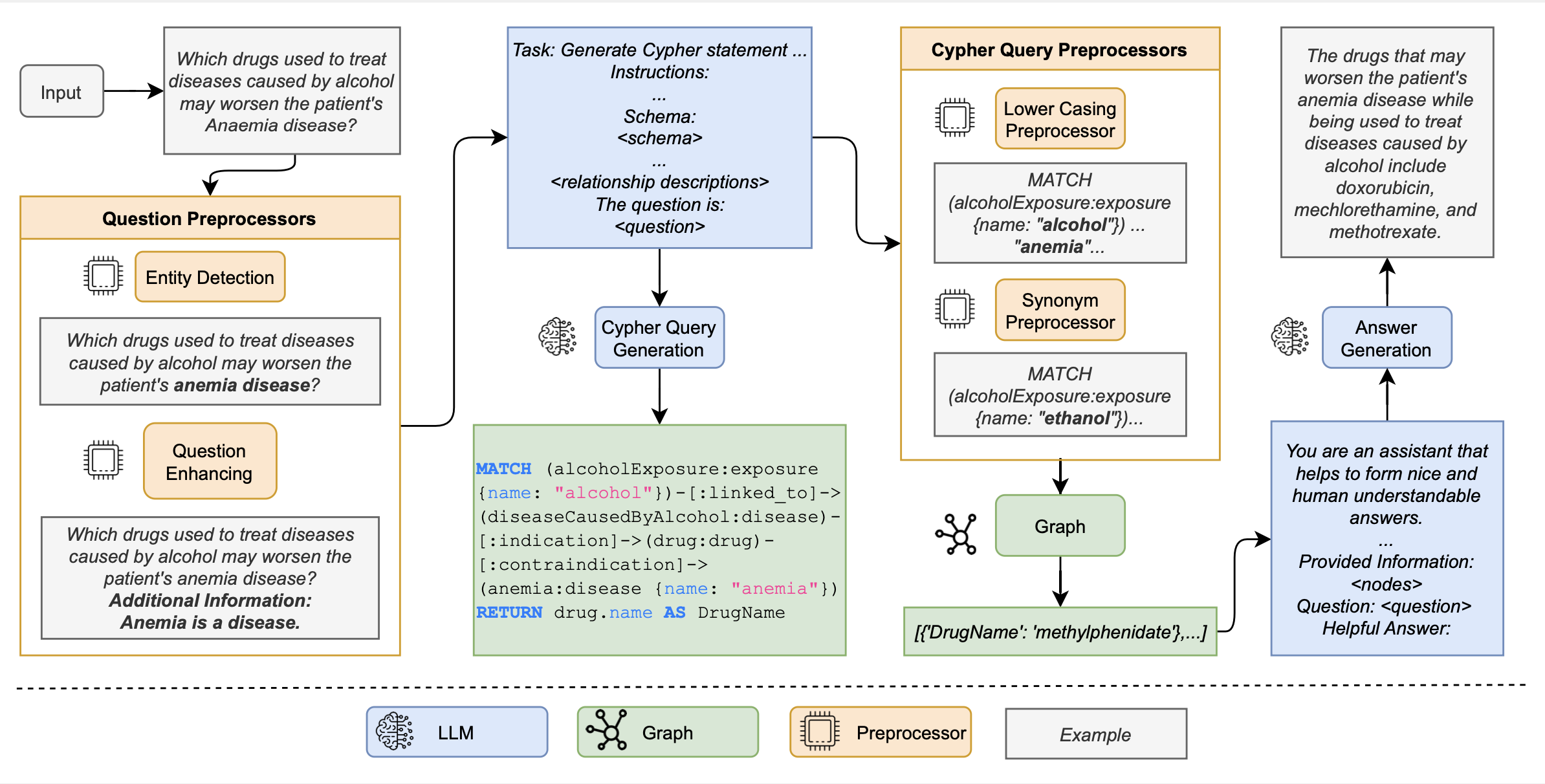
从自然语言问题中提取事实信息并生成答案的流程
该图片展示了一个用于从自然语言问题中提取事实信息并生成答案的流程,该流程涉及多个步骤和组件,主要围绕“fact-finder”这一核心功能展开。
| 输入 | 输入: 用户提出一个问题,如:“哪种药物用于治疗由酒精引起的疾病可能会加重患者的贫血症?” 这个问题将作为系统的输入。 |
| 输入处理 | 问题预处理器:该模块负责识别问题中的实体,并可能增强问题以提高语言模型的理解能力。在这个例子中,实体检测器发现了一个实体“anemia”,并将其替换为“anaemia”(贫血),同时提供了额外信息:“Anemia is a disease.”(贫血是一种疾病)。 输入处理(Question Preprocessors) 实体检测(Entity Detection): 识别问题中的关键实体。例如,在输入的问题中检测到“anemia(贫血)”。 问题增强(Question Enhancing): 增强问题以添加额外的上下文信息,例如“Anemia is a disease(贫血是一种疾病)”,以便更好地理解问题的意图。 |
| 查询生成 | 任务:生成Cypher语句... 这一步骤的目标是生成一个Cypher查询,用于在知识图谱上搜索相关信息。这个任务包含了图谱的模式(Schema)和关系描述(Relationship Descriptions)。 Cypher查询生成(Cypher Query Generation) 通过语言模型(LLM)生成Cypher查询语句,该查询用于从知识图谱中检索相关信息。示例查询为: MATCH (alcoholExposure:exposure {name: "alcohol"})-[:linked_to]->(diseaseCausedByAlcohol:disease)-[:indication]->(drug:drug)-[:contraindication]->(anemia:disease {name: "anemia"}) RETURN drug.name AS DrugName 该查询意在找到与酒精相关的疾病治疗药物,这些药物可能会加重贫血病情。 |
| 查询预处理 | Cypher查询预处理器:这些预处理器用于修改Cypher查询,使其更容易理解和执行。在这个示例中,有两个预处理器: Lower Casing Preprocessor(小写预处理器):将查询中的所有属性值转换为小写字母,确保与图谱中的数据匹配。 Synonym Preprocessor(同义词预处理器):将查询中的某些名称替换为图谱中实际存在的同义词。在这个例子中,它将“alcohol”替换为“ethanol”。 Cypher查询预处理(Cypher Query Preprocessors) 小写预处理(Lower Casing Preprocessor): 将查询中的关键词进行小写化处理,例如“Alcohol”转换为“alcohol”,以统一查询格式。 同义词预处理(Synonym Preprocessor): 将同义词进行替换以提高查询的匹配率,例如“anemia”可以被替换为“ethanol”来扩展查询范围。 |
| 答案生成 | 答案生成(Answer Generation) 使用图数据库返回的查询结果,通过答案生成模块,生成更易理解的人类语言答案。例如,根据查询结果生成:“The drugs that may worsen the patient's anemia disease while being used to treat diseases caused by alcohol include doxorubicin, mechlorethamine, and methotrexate.”。 图谱查询:使用经过预处理的Cypher查询在图谱上执行查询,得到结果。 答案生成:根据图谱查询的结果,使用语言模型生成自然语言答案。在这个例子中,答案是:“The drugs that may worsen the patient's anaemia disease while being used to treat diseases caused by alcohol include doxorubicin, mechlorethamine, and methotrexate.” |
Fact-Finder的作用
Fact-Finder在这个流程中扮演的角色是将自然语言问题转化为结构化的查询语言(Cypher),从而在知识图谱中找到精确的答案。
它通过语言模型(LLM)生成查询,并通过一系列预处理步骤(如同义词替换和大小写规范化)优化查询的准确性和广泛性。
最终,Fact-Finder帮助生成一个基于知识图谱数据的答案,这个答案是经过语言模型调整的,以确保其对用户而言是清晰且有帮助的。
总之,这个系统通过多步骤的处理流程,将复杂的自然语言查询转化为结构化数据查询,并返回精确的答案,体现了Fact-Finder在信息检索和自然语言处理中的重要作用。FactFinder系统结合了语言模型(LLM)、图谱(Graph)和预处理器(Preprocessor)等组件,旨在提供准确、易懂的答案。
2、用户界面
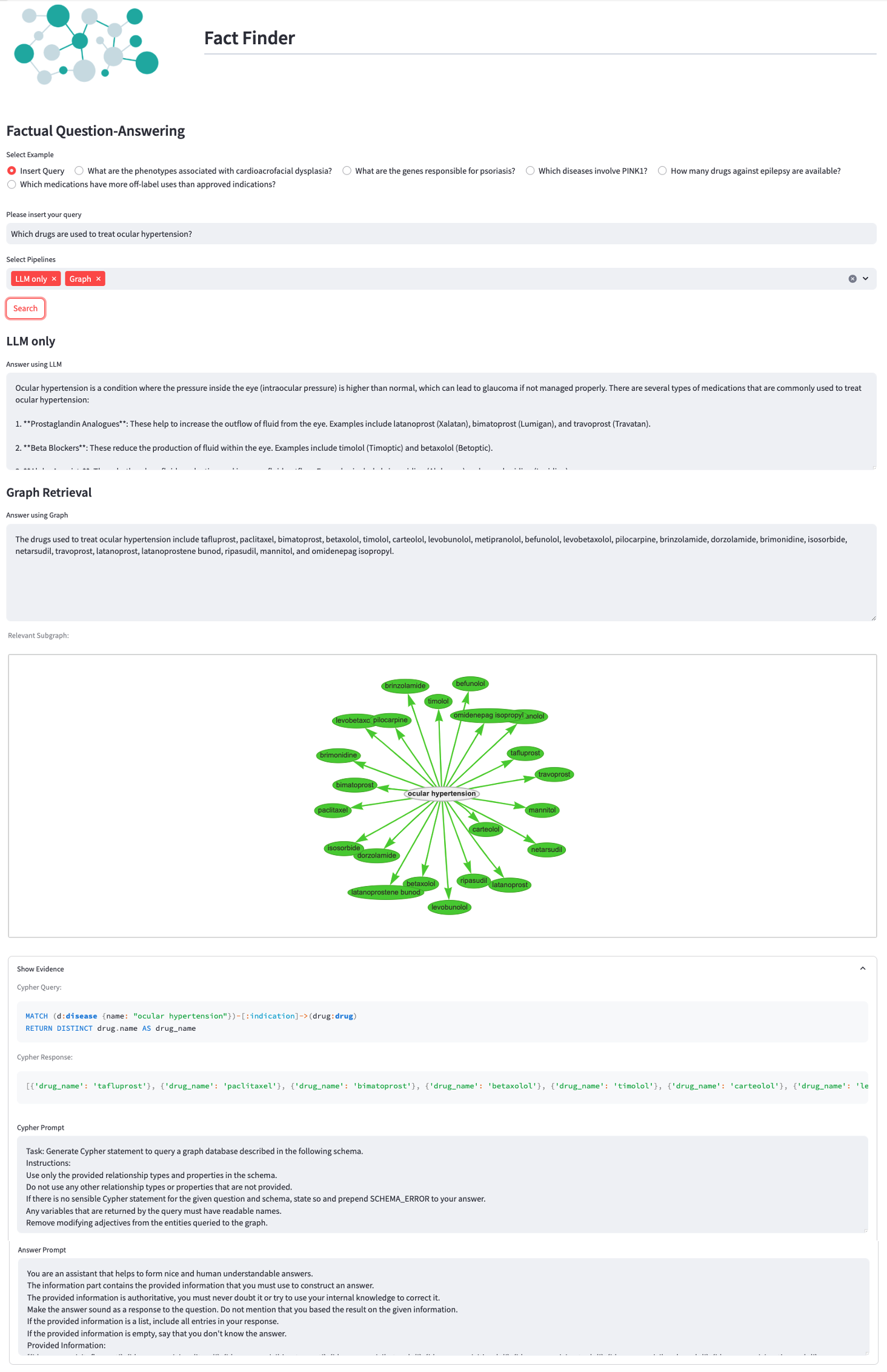
下图展示了应用程序的用户界面,针对的问题是“哪些药物用于治疗眼压升高?”。比较了独立 LLM 和我们的基于图的混合系统的答案。此外,还显示了相关的子图作为证据,连同生成的 Cypher 查询、来自图的答案以及所使用的提示。
fact-finder的安装和使用方法
1、安装
设置 PrimeKG Neo4j 实例
地址:fact-finder/neo4j_primekg/README.md at main · chrschy/fact-finder · GitHub
安装依赖
pip install -e .
FactFinder 的一些功能基于外部 API。运行 FactFinder 需要 OpenAI API 密钥,而 Semantic Scholar 以及 Bayer 的 LinnaeusAnnotate 实体检测则是可选的。设置环境变量:
export LLM="gpt-4o" # 可以选择 "gpt-4-turbo" 作为替代方案
export SEMANTIC_SCHOLAR_KEY="" # 填入 Semantic Scholar 的 API 密钥
export OPENAI_API_KEY="" # 填入 OpenAI 的 API 密钥
export SYNONYM_API_KEY="" # Bayer 内部 LinnaeusAnnotate 同义词 API 密钥
export SYNONYM_API_URL="" # Bayer 内部 LinnaeusAnnotate 同义词 API 地址运行用户界面:
streamlit run src/fact_finder/app.py --browser.serverAddress localhost带有额外参数运行(例如激活规范化图同义词):
streamlit run src/fact_finder/app.py --browser.serverAddress localhost -- [args]
streamlit run src/fact_finder/app.py --browser.serverAddress localhost -- --normalized_graph --use_entity_detection_preprocessing可用的标志包括:
--normalized_graph = 在应用到图之前,根据规范化图进行同义词替换处理 Cypher 查询。
--use_entity_detection_preprocessing = 在生成 Cypher 查询前,对用户问题应用实体检测。找到的实体将被其首选术语替换,并且会在查询中添加描述其类别的字符串(例如,“银屑病是一种疾病。”)。这需要设置相应的 API 密钥($SYNONYM_API_KEY)。同时,应该使用规范化图。
--use_subgraph_expansion = 通过周围的邻域扩展证据图。2、使用方法
从用户问题到自然语言答案和提供的证据,涉及以下步骤:
第一步,调用LM生成Cypher查询:使用语言模型调用来生成针对知识图谱的 Cypher 查询。
为了实现这一点,提示模板包含图的模式,即关于所有节点及其属性的信息。此外,可以为图中的(部分)关系丰富自然语言描述,使语言模型更好地理解它们的意义。如果模型确定给定模式的图无法回答用户问题,则会返回以标记字符串 "SCHEMA_ERROR" 开头的错误消息。然后会检测到这一错误消息,并直接转发给用户。
第二步,Cypher查询预处理:使用正则表达式预处理生成的 Cypher 查询。
首先,应用格式化以便后续的正则表达式更易于设计。这包括去除不必要的空格以及对所有字符串使用双引号。
接下来,将所有属性值转换为小写。假设图中的属性值已经进行了类似的预处理,这样可以使得查询不区分大小写。
最后,对于某些节点类型,在查询中使用的名称会被图中实际使用的同义词替换。例如,可以通过查找名称的同义词并检查哪个同义词实际上存在于图中来完成这项工作。
第三步,图查询:使用 Cypher 预处理的最终结果查询图。
Cypher 查询及图的答案是界面上展示的证据的一部分,从而实现了对用户的透明度。
第四步,调用LM生成自然语言答案
通过另一个语言模型调用,从图查询的结果生成最终的自然语言答案。
第五步,生成子图
此外,根据图查询和结果生成子图。这作为可视化的证据供用户参考。子图可以通过基于规则的方法生成,也可以借助语言模型生成。
fact-finder的案例应用
持续更新中……




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











