







LLMs之LRM之o1:《LLMs Still Can't Plan; Can LRMs? A Preliminary Evaluation of OpenAI's o1 on PlanBench》翻译与解读
导读:这篇论文的核心议题是评估LLM和新型大型推理模型(LRM)在规划任务上的能力。论文以PlanBench基准测试为工具,对各种LLM和OpenAI新发布的o1(Strawberry)模型进行了评估,并分析了其优缺点。
>> 背景痛点:
● LLM在规划任务上的能力不足:规划能力被认为是智能体的核心能力之一。尽管LLM在各种自然语言处理任务上表现出色,但它们在需要规划和推理的复杂任务上表现却很差。即使是简单的规划问题,LLM也难以有效解决,其性能提升缓慢且不稳定。这主要是因为LLM本质上是近似检索器,而非近似推理器。
● 现有基准测试的局限性:PlanBench基准测试虽然能够评估LLM的规划能力,但其静态数据集和简单的测试场景,不足以全面评估新型LRM的能力。 特别是LRM的推理过程不透明,难以进行有效的评估。
● 缺乏对效率和可靠性的考量:之前的LLM评估主要关注准确率,而忽略了效率和成本。LRM则会根据输入动态调整计算时间和成本,因此需要考虑效率和成本因素。此外,LLM和LRM通常缺乏正确性保证,这在安全关键型应用中是不可接受的。
>> 具体的解决方案:论文使用PlanBench基准测试,对一系列LLM和OpenAI的o1模型进行了测试,并扩展了测试的范围和难度,包括:
● 使用更复杂的场景:除了简单的Blocksworld问题,还使用了语义相同但语法模糊的Mystery Blocksworld问题,以及包含更多步骤的更复杂Blocksworld问题。
● 测试对不可解问题的识别能力:评估模型识别不可解问题的准确性。
● 考虑效率和成本:比较不同模型的推理时间和成本。
>> 核心思路步骤:论文的主要思路是通过在PlanBench基准测试上对不同模型进行对比实验,来评估LLM和LRM在规划任务上的能力。具体步骤包括:
● 选择基准测试:使用PlanBench基准测试,其包含Blocksworld和Mystery Blocksworld两个领域。
● 选择模型:测试了多个不同类型的LLM(如GPT-4, LLaMA)和OpenAI的o1模型(LRM)。
● 设计实验:设计了不同难度的测试案例,包括不同规模的Blocksworld问题、Mystery Blocksworld问题以及不可解的问题。
● 进行测试:对每个模型在不同测试案例上的性能进行评估,记录准确率、推理时间和成本。
● 分析结果:分析不同模型的性能差异,并探讨其原因。
>> 优势:
● 对LLM和LRM的综合评估:论文同时评估了LLM和LRM,并对两者进行了比较。
● 扩展了测试范围:使用了更复杂的测试场景和不可解的问题,更全面地评估了模型的能力。
● 考虑了效率和成本:对不同模型的推理时间和成本进行了比较,更全面地评估了模型的实用性。
>> 结论和观点:
● LLM在规划任务上的能力仍然有限:LLM主要依靠近似检索,难以进行有效的规划和推理。
● LRM在规划任务上取得了一定进展:o1模型在简单的Blocksworld问题上取得了显著的性能提升,但其性能并不鲁棒,在更复杂的场景下性能下降明显。o1代表了从"近似检索"向"近似推理"的重要进展,虽然o1的表现优于传统LLMs,但距离完美规划能力还有很大差距。
● LRM的效率和成本仍然很高:o1模型的推理时间和成本远高于LLM和传统的规划器。
● LRM缺乏可靠性保证:o1模型有时会给出错误的答案,并且难以解释其推理过程。
● 需要开发更完善的评估方法:需要考虑模型的效率、成本和可靠性,并开发更完善的评估方法来评估LRM的能力。
● 论文建议结合LLM和传统规划器,或者使用LLM-Modulo系统,以获得更高的准确性和可靠性,同时降低成本。 这比单纯依赖黑盒LRM更安全可靠。
总而言之,这篇论文对LLM和LRM在规划任务上的能力进行了深入的评估,并指出了现有模型的局限性和未来研究的方向。 它强调了在评估大型模型时,不仅要关注准确性,还要考虑效率、成本和可靠性等因素。 单纯追求高准确率的LRM,在缺乏可解释性和可靠性保证的情况下,其应用价值受到极大限制。
目录
《LLMs Still Can't Plan; Can LRMs? A Preliminary Evaluation of OpenAI's o1 on PlanBench》翻译与解读
2 State-of-the-Art LLMs Still Can’t Plan
《LLMs Still Can't Plan; Can LRMs? A Preliminary Evaluation of OpenAI's o1 on PlanBench》翻译与解读
| 地址 | 论文地址: |
| 时间 | 2024年9月20日 |
| 作者 | 美国亚利桑那大学 |
Abstract
| The ability to plan a course of action that achieves a desired state of affairs has long been considered a core competence of intelligent agents and has been an integral part of AI research since its inception. With the advent of large language models (LLMs), there has been considerable interest in the question of whether or not they possess such planning abilities. PlanBench, an extensible benchmark we developed in 2022, soon after the release of GPT3, has remained an important tool for evaluating the planning abilities of LLMs. Despite the slew of new private and open source LLMs since GPT3, progress on this benchmark has been surprisingly slow. OpenAI claims that their recent o1 (Strawberry) model has been specifically constructed and trained to escape the normal limitations of autoregressive LLMs--making it a new kind of model: a Large Reasoning Model (LRM). Using this development as a catalyst, this paper takes a comprehensive look at how well current LLMs and new LRMs do on PlanBench. As we shall see, while o1's performance is a quantum improvement on the benchmark, outpacing the competition, it is still far from saturating it. This improvement also brings to the fore questions about accuracy, efficiency, and guarantees which must be considered before deploying such systems. | 长期以来,人们一直认为智能代理的核心能力是制定行动计划以实现理想状态的能力,从一开始就是人工智能研究的一个组成部分。随着大型语言模型(LLMs)的出现,人们对它们是否具备此类规划能力产生了相当大的兴趣。我们在2022年开发的PlanBench是一个可扩展的基准,推出不久后便成为评估LLMs规划能力的重要工具。尽管自GPT-3以来出现了大量新的私有和开源LLMs,但在这一基准上的进展却出人意料地缓慢。OpenAI声称,他们最近的o1(Strawberry)模型是专门构建和训练以摆脱自回归LLMs的常规限制,从而成为一种新型模型:大型推理模型(LRM)。本文以此发展为催化剂,全面探讨当前LLMs和新LRMs在PlanBench上的表现。正如我们所见,尽管o1在基准测试中的表现实现了量子级的提升,超越了竞争对手,但仍远未达到饱和。这一改进也引发了关于准确性、效率和保障的问题,这些问题必须在部署此类系统之前加以考虑。 |
1 Introduction
| The recent release of OpenAI’s o1 (Strawberry) [2] brings with it the opportunity to both freshly evaluate progress on PlanBench and to consider directions for extending the benchmark. In particular, unlike the LLMs which came before it, which can roughly be viewed as approximate retrievers, o1 seems to have been trained to be an approximate reasoner.1 Following OpenAI2, we draw a distinction between previous Large Language Models and o1, a Large Reasoning Model (or LRM), as its new (unknown) architecture, operation, and capabilities all seem to be fundamentally different from those of vanilla LLMs, both at pretraining phase and at inference time. To properly evaluate this new kind of model and understand its abilities and limitations will require new tools and evaluation methods, especially if details of the overall model structure are kept secret and internal traces remain inaccessible to outside researchers.3 Since PlanBench [1] first debuted on arXiv in 2022, we have continually retested new models on one particular subset: a static dataset of 600 three to five block problems. Even though LLMs have gotten ever larger and required substantially more investment per model, their performance on even the simplest planning problems has never come close to saturating this test set, and the improvements we have seen have not been robust or generalizable [6]. Our benchmark has thus served as a useful marker of LLM progress (or lack thereof) on planning and reasoning tasks, though it is important to note that this analysis–especially when confined to a static test set–can only serve as an upper bound on performance. When we first designed PlanBench, it was intended to be more than just this set, but rather to be an extensible suite of tools for evaluating LLM planning capabilities. Now that LRMs score so highly on at least parts of the original test set, those tools will become ever more important for future evaluations. | OpenAI最近发布的o1(Strawberry)为我们提供了重新评估PlanBench进展的机会,同时也考虑扩展基准的方向。特别是,与之前的LLMs相比,o1似乎是被训练为近似推理器,而之前的模型大致可以视为近似检索器。我们借鉴OpenAI的定义,区分以往的大型语言模型与o1,即大型推理模型(LRM),因为其新的(未知的)架构、操作和能力似乎在预训练阶段和推理时都与普通LLMs有根本的不同。为了正确评估这种新型模型并理解其能力和局限性,我们需要新的工具和评估方法,尤其是在整体模型结构的细节被保密且内部追踪对外部研究人员不可访问的情况下。自2022年PlanBench首次在arXiv上发布以来,我们不断对特定子集进行再测试:一个由600个三至五块的静态问题组成的数据集。尽管LLMs越来越庞大且每个模型的投资显著增加,但它们在最简单的规划问题上的表现从未接近饱和这个测试集,而我们所见的改进也并不稳健或具有普遍适用性。我们的基准因此成为了LLM在规划和推理任务上进展(或缺乏进展)的有用标志,尽管值得注意的是,这种分析——尤其是在静态测试集上——只能作为性能的上限。当我们首次设计PlanBench时,旨在不仅仅是这个集合,而是成为一个可扩展的工具套件,用于评估LLM的规划能力。现在LRMs在至少部分原始测试集上得分很高,这些工具在未来评估中将变得越来越重要。 |
| In this preliminary evaluation (at time of writing, o1-preview and o1-mini have only been out a week, and the full o1 model is yet to be released), we examine the performance jump that these new Large Reasoning Models promise. We record the slow progress we’ve observed in vanilla LLM performance since the release of the benchmark, discuss o1’s performance, and then tackle the question of how PlanBench’s domains and tests can be elaborated on in order to remain relevant metrics for LRMs. We argue that, to be complete, new approaches to measuring LRM reasoning capabilities must take into account efficiency, cost, and guarantees. | 在这次初步评估中(在撰写时,o1-preview和o1-mini刚刚发布一周,完整的o1模型尚未发布),我们考察了这些新的大型推理模型承诺带来的性能飞跃。我们记录了自基准发布以来,普通LLM表现缓慢进展的观察,讨论o1的表现,并探讨如何扩展PlanBench的领域和测试,以保持其对LRMs的相关性。我们认为,为了全面,新方法在测量LRM推理能力时必须考虑效率、成本和保障。 |
2 State-of-the-Art LLMs Still Can’t Plan
| PlanBench remains a challenging benchmark for vanilla LLMs (massive transformer models which have been fine-tuned via RLHF), and their lackluster performance on even our easiest test set leads us to continue to believe that planning cannot be generally and robustly solved by approximate retrieval alone. In Table 1, we present the results of running current and previous generation LLMs on a static test set of 600 three to five block Blocksworld problems, as well as on a set of 600 semantically identical but syntactically obfuscated instances which we call Mystery Blocksworld. Across these models, the best performance on regular Blocksworld is achieved by LLaMA 3.1 405B with 62.6% accuracy. Despite the underlying problems being identical, Mystery Blocksworld performance lags far behind–no LLM achieves even 5% on our test set–and performance on one version of the domain does not clearly predict performance on the other.4 In the original paper, we tested both natural language prompts and PDDL, and found that vanilla language models perform better when tested on the former, even though natural language prompts can introduce uncertainty due to polysemanticity and syntactic ambiguity. To make our comparisons "fair" for the models being tested, the results we have been reporting are the higher accuracy natural language prompting numbers. | PlanBench仍然是普通LLMs(通过RLHF微调的大型变换器模型)的一项挑战性基准,它们在我们最简单的测试集上的表现平平,令我们继续相信,仅靠近似检索无法普遍且稳健地解决规划问题。在表1中,我们展示了当前和前一代LLMs在由600个三至五块的Blocksworld问题组成的静态测试集上的结果,以及在我们称之为神秘Blocksworld的600个语义相同但句法混淆实例上的结果。在这些模型中,常规Blocksworld的最佳表现由LLaMA 3.1 405B取得,准确率为62.6%。尽管基础问题是相同的,但神秘Blocksworld的表现却远远滞后——没有任何LLM在我们的测试集上达到5%的准确率,并且一个领域的表现并不能明确预测另一个领域的表现。 在最初的论文中,我们测试了自然语言提示和PDDL,发现普通语言模型在测试前者时表现更好,尽管自然语言提示可能由于多义性和句法歧义引入不确定性。为了使我们对被测试模型的比较“公平”,我们报告的结果是更高准确度的自然语言提示数字。 |
| LLMs are highly capable of providing translations between equivalent representations [7]. This fact, combined with their significantly higher performance on the unobfuscated version of the Blocksworld domain, predicts that–if they are capable of composing reasoning operations–the performance gap between Mystery Blocksworld and classic Blocksworld should shrink substantially if the translation from Mystery Blocksworld back into Blocksworld is explicitly provided. However, when we provide this in the prompt (see Appendix C), performance only improves a very small amount: GPT-4 achieves 10%. We also find that, contrary to previous claims, one-shot prompting is not a strict improvement over zero-shot. In fact, for many models it seems to do significantly worse!5 This is most notable in our tests of LLaMA family models. The original iteration of our benchmark did not take efficiency into consideration, as the time taken by a vanilla LLM to produce some output is only dependent on the length of that output, but otherwise independent of the semantic content or difficulty of the instance. However, as LRMs adaptively vary their time taken and dollar cost per instance in response to the input, measuring efficiency has become much more important. As a comparison point between LRMs and LLMs, we compute prompting costs across models and present them in Table 4. | LLMs在提供等效表示之间的翻译方面非常有能力。这个事实,加上它们在未混淆的Blocksworld领域上表现明显更好的结果,预测了——如果它们能够组合推理操作——神秘Blocksworld与经典Blocksworld之间的表现差距应该会显著缩小,如果将神秘Blocksworld明确翻译回Blocksworld时提供。不过,当我们在提示中提供这一点时(见附录C),性能仅略有提高:GPT-4的准确率为10%。 我们还发现,与先前的声明相反,一次性提示并不严格优于零次提示。事实上,对于许多模型而言,它似乎表现得更差!这在我们对LLaMA家族模型的测试中尤为显著。 我们基准的初始迭代没有考虑效率,因为普通LLM生成某些输出所需的时间仅依赖于输出的长度,而与实例的语义内容或难度无关。然而,随着LRMs根据输入自适应地调整每个实例的时间和成本,测量效率变得更加重要。作为LRMs与LLMs之间的比较,我们计算了模型之间的提示成本,并在表4中展示。 |
Figure 1: These examples are on Mystery Blocksworld. Fast Downward, a domain-independent planner [8] solves all given instances near-instantly with guaranteed perfect accuracy. LLMs struggle on even the smallest instances. The two LRMs we tested, o1-preview and o1-mini, are surprisingly effective, but this performance is still not robust, and degrades quickly with length.图1:这些例子来自神秘Blocksworld。Fast Downward是一个与领域无关的规划器,能够几乎瞬间解决所有给定实例,并保证完美准确性。LLMs在最小实例上也表现不佳。我们测试的两个LRMs,o1-preview和o1-mini,表现令人惊讶地有效,但这种性能仍然不够稳健,且随着问题长度的增加迅速下降。
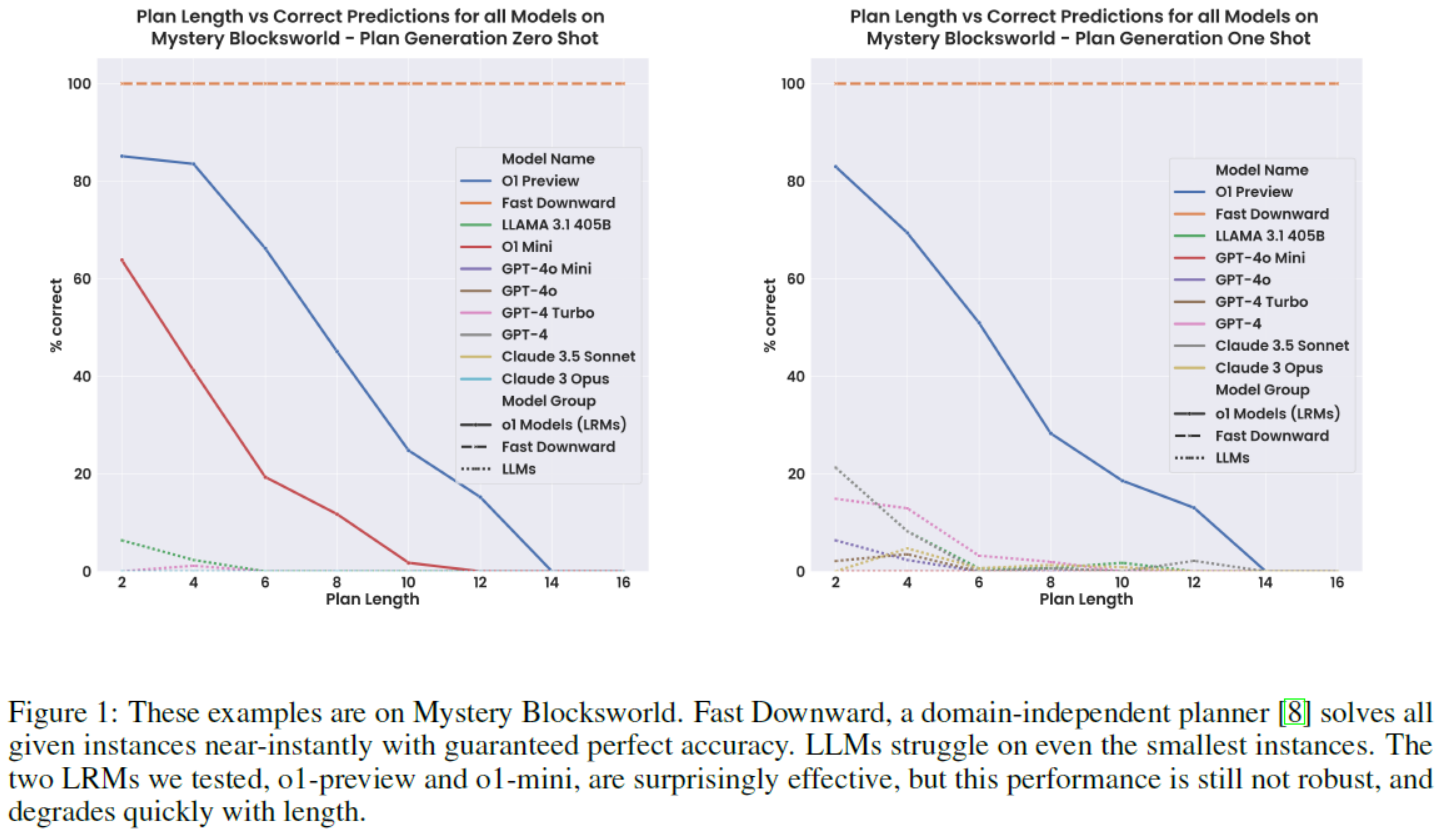
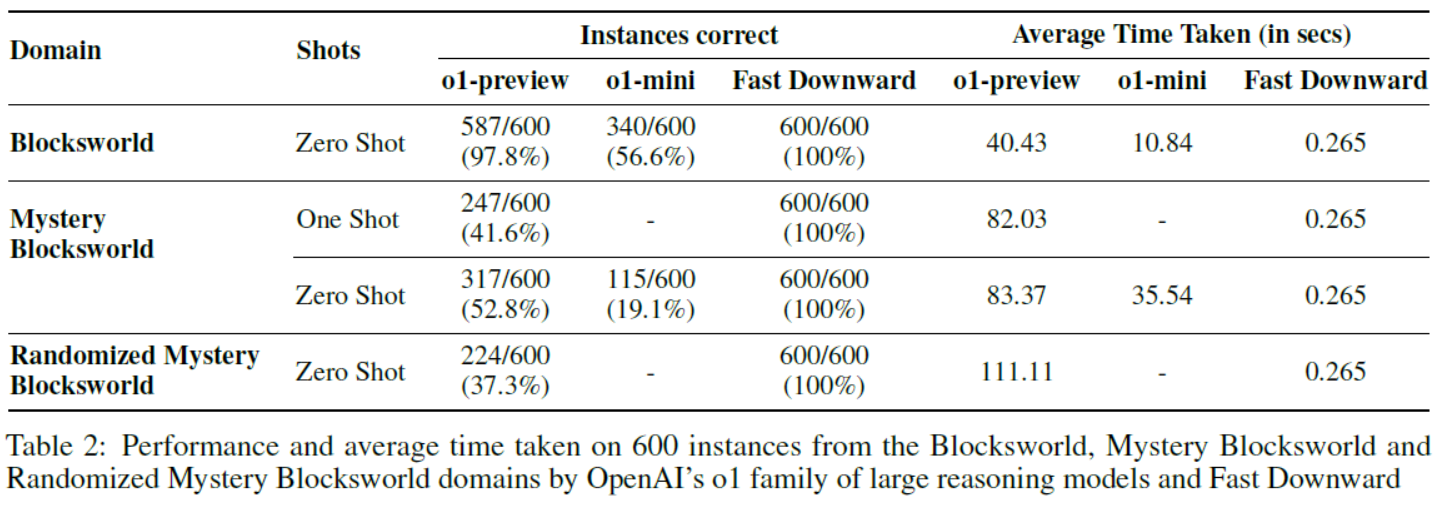
Table 2: Performance and average time taken on 600 instances from the Blocksworld, Mystery Blocksworld and Randomized Mystery Blocksworld domains by OpenAI’s o1 family of large reasoning models and Fast Downward 表2:OpenAI的o1大型推理模型系列和Fast Downward在Blocksworld、神秘Blocksworld和随机神秘Blocksworld领域的600个实例上的性能和平均耗时。
4 Conclusion
| We took a fresh look at the planning capabilities of both SOTA LLMs, and examined the performance of OpenAI’s new o1 models on PlanBench. Over time, LLMs have improved their performance on vanilla Blocksworld–with the best performing model, LlaMA 3.1 405B, reaching 62.5% accuracy. However, their dismal performance on the obfuscated ("Mystery") versions of the same domain betrays their essentially approximate retrieval nature. In contrast, the new o1 models, which we call LRMs (Large Reasoning Models)–in keeping with OpenAI’s own characterizations–not only nearly saturates the original small instance Blockworld test set, but shows the first bit of progress on obfuscated versions. Encouraged by this, we have also evaluated o1’s performance on longer problems and unsolvable instances, and found that these accuracy gains are not general or robust. We also discussed the critical accuracy/efficiency tradeoffs that are brought up by the fact that o1 that uses (and charges for) significant inference-time compute, as well as how it compares to other LLM-based approaches (such as LLM-Modulo [10]) and dedicated solvers. We hope this research note gives a good snapshot of the planning capabilities of LLMs and LRMs as well as useful suggestions for realistically evaluating them. | 我们重新审视了SOTA LLMs的规划能力,并考察了OpenAI的新o1模型在PlanBench上的表现。随着时间推移,LLMs在普通Blocksworld上的表现有所提升,表现最佳的模型LLaMA 3.1 405B达到了62.5%的准确率。然而,它们在相同领域的混淆版本(“神秘”版本)上的糟糕表现揭示了它们本质上是近似检索的特性。相比之下,我们称之为LRMs(大型推理模型)的新o1模型——与OpenAI的自身描述一致——不仅几乎饱和了原始的小实例Blockworld测试集,还在混淆版本上显示出了一些进展。在此鼓励下,我们还评估了o1在更长问题和无法解决实例上的表现,发现这些准确率的提升并不普遍或稳健。我们还讨论了由于o1使用(并收取费用的)显著推理时计算能力而引发的关键准确性/效率权衡,以及它与其他基于LLM的方法(如LLM-Modulo)和专用求解器的比较。我们希望这份研究笔记能够清晰展现LLMs和LRMs的规划能力,并提供现实评估它们的有用建议。 |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











