







LLMs之Multilingual:《A Deepdive into Aya Expanse: Advancing the Frontier of Multilinguality》翻译与解读
导读:这篇博文介绍了Cohere For AI团队开发的Aya Expanse系列多语言模型(8B和32B参数),以及其背后的技术细节。
一、Aya Expanse 模型的突破:
>> 核心目标:解决当前AI领域中高性能多语言模型匮乏的问题,力求达到与单语言模型相当的性能。
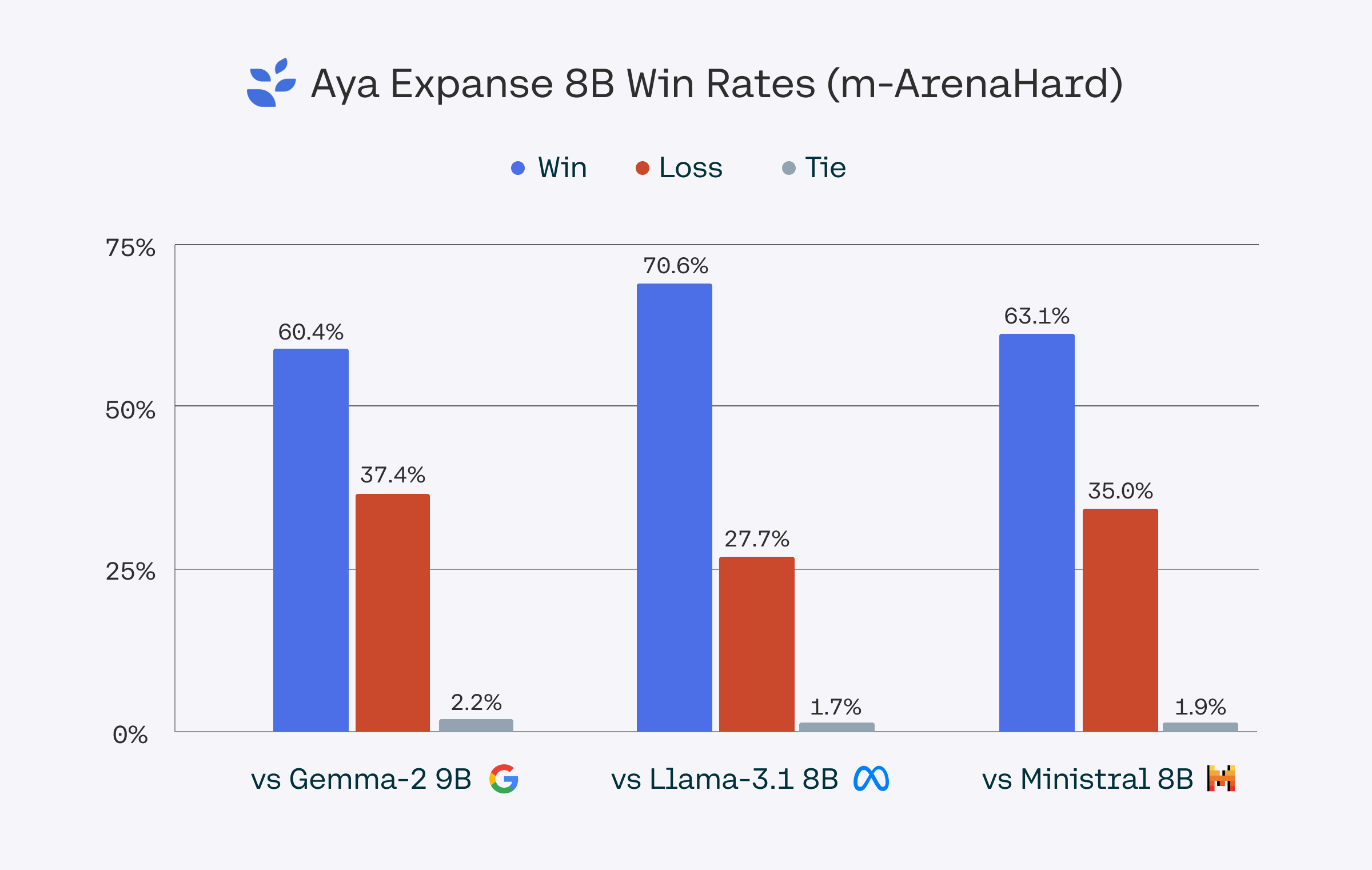
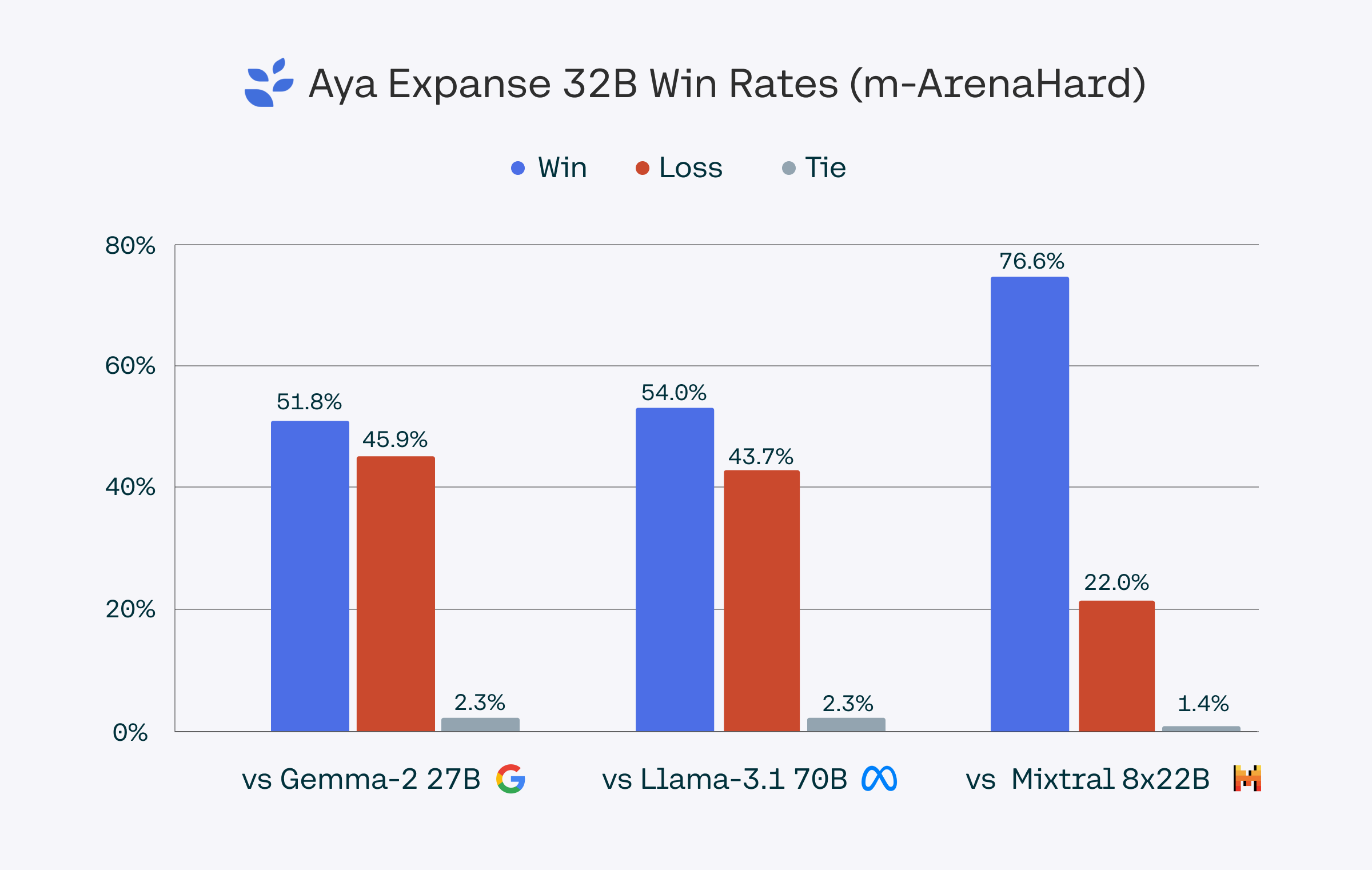
>> 模型性能:Aya Expanse 32B在多语言性能方面超越了Gemma 2 27B、Mistral 8x22B和Llama 3.1 70B(后者参数量是其两倍多);Aya Expanse 8B则超越了Gemma 2 9B、Llama 3.1 8B和Ministral 8B等同参数量级的领先开源模型。
>> 开源贡献:两个模型都以开放权重的方式发布,旨在加速多语言AI的发展。
Aya Expanse系列模型在多语言性能上取得了显著的突破,并以开源方式回馈社区,推动多语言AI领域的发展。
二、避免合成数据中的模型崩溃:
>> 挑战:利用合成数据训练大型语言模型(LLM)已成为主流,但在多语言场景中,特别是低资源语言,高质量的“教师模型”匮乏,容易导致模型崩溃。
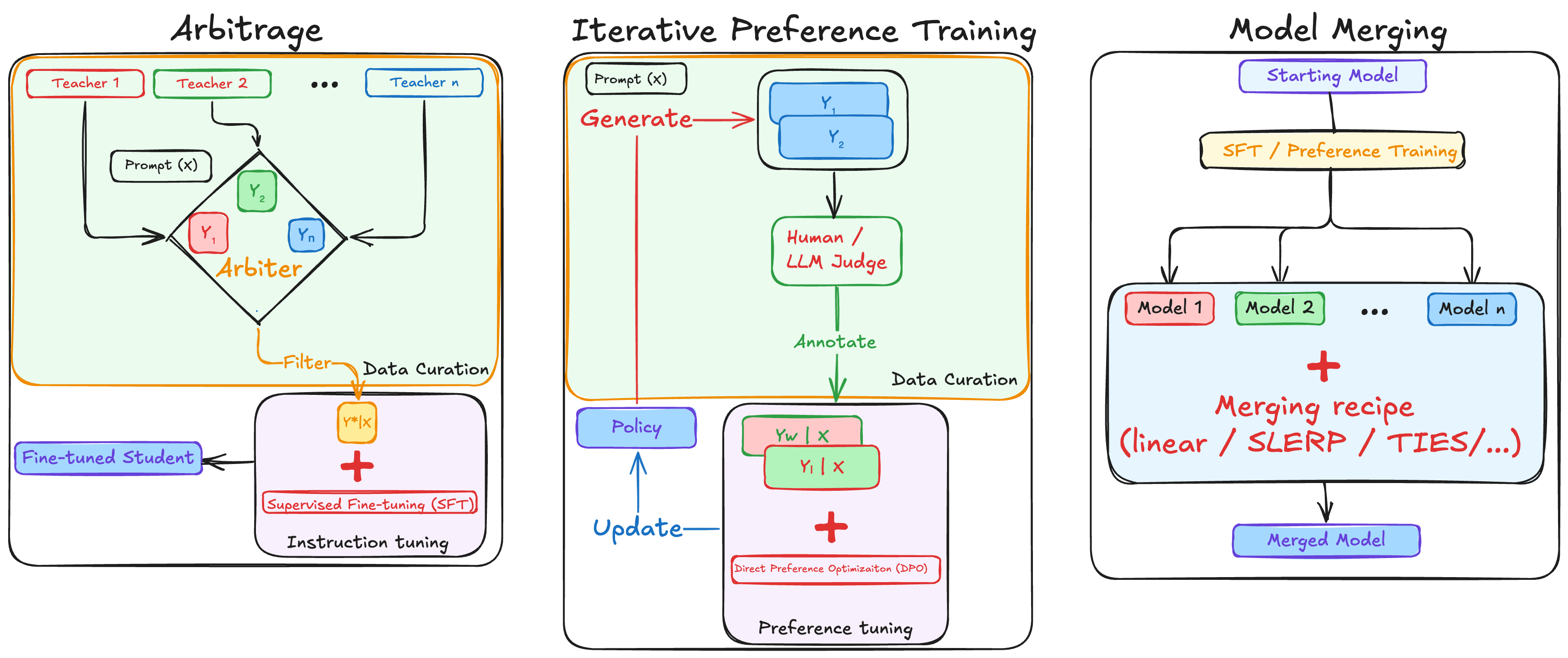
>> 解决方案:数据仲裁 (Data Arbitrage):该方法并非依赖单一教师模型,而是从多个教师模型中策略性地采样数据,利用模型间的性能差异来生成高质量的多语言合成数据集。
>> 具体实现:首先训练多个针对不同语言组的模型池,然后使用内部奖励模型(Arbiter)评估并选择最佳生成结果。
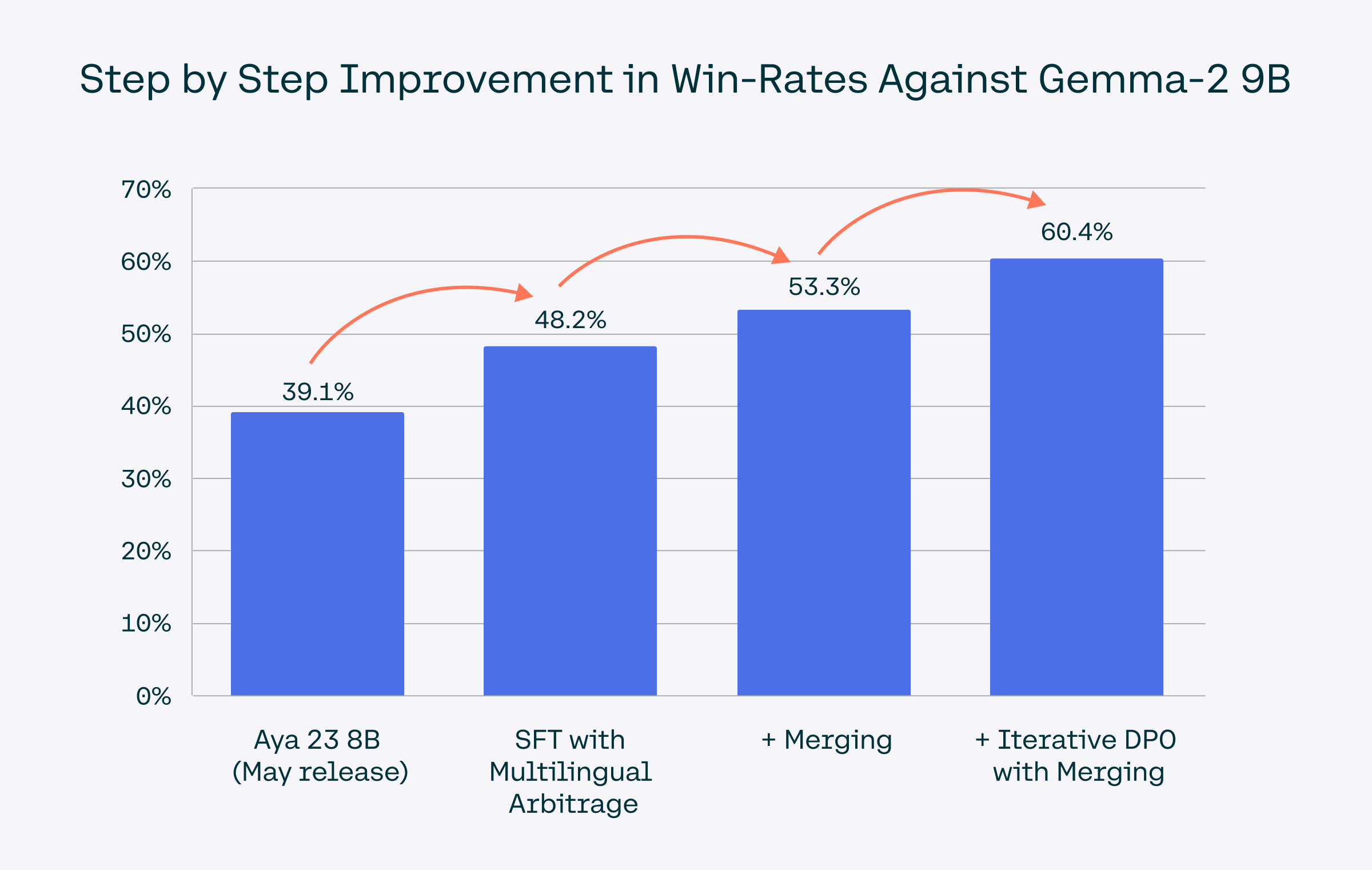
>> 效果:在8B模型的监督微调阶段,使用多语言仲裁技术比之前的Aya 23模型提高了9.1%以上的胜率。
数据仲裁技术有效解决了多语言合成数据训练中模型崩溃的问题,通过策略性地利用多个教师模型的优势,生成更高质量的多语言数据集,显著提升了模型性能。
三、迭代改进与全局偏好:
>> 挑战:在多语言环境下进行偏好训练面临诸多挑战,例如高质量的多语言偏好数据集匮乏,以及多语言同时优化带来的困难。
>> 解决方案:利用一种新颖的合成数据生成技术构建高质量的多语言偏好数据对,通过对比高性能多语言LLM生成的同语言补全与较弱模型翻译自英语的补全,引导模型避免生成低质量的多语言补全。
>> 训练策略:采用先离线偏好训练,再在线迭代偏好训练的策略。离线训练使用仲裁阶段的最高和最低奖励响应作为选择和拒绝的补全;在线训练则迭代地从模型中采样多个在线生成结果,并使用奖励模型进行排序和进一步训练。
>> 效果:对于Aya Expanse 8B模型,结合离线和在线偏好训练,相较于Gemma 2 9B,胜率额外提高了7.1%。
通过巧妙的合成数据生成技术和离线/在线结合的偏好训练策略,有效提升了模型对人类偏好的对齐程度,显著改善了多语言性能。
四、通过模型融合最大化性能:
>> 方法:采用模型融合技术,降低计算成本,并提升模型在多任务学习中的性能。
>> 模型多样性:为了最大化模型融合的收益,训练针对不同语言族的多个模型,并利用跨语言迁移学习的优势。
>> 融合技术:尝试了多种模型融合技术,包括加权线性平均、SLERP、TIES-merging和DARE-TIES,最终选择加权平均作为最一致有效的方法。
>> 效果:在35B规模的模型中,模型融合带来的性能提升更为显著,高达3倍。
模型融合技术有效提升了模型性能,特别是大规模模型中效果更佳,并通过策略性地训练不同语言族的模型,最大化了跨语言迁移学习的优势。
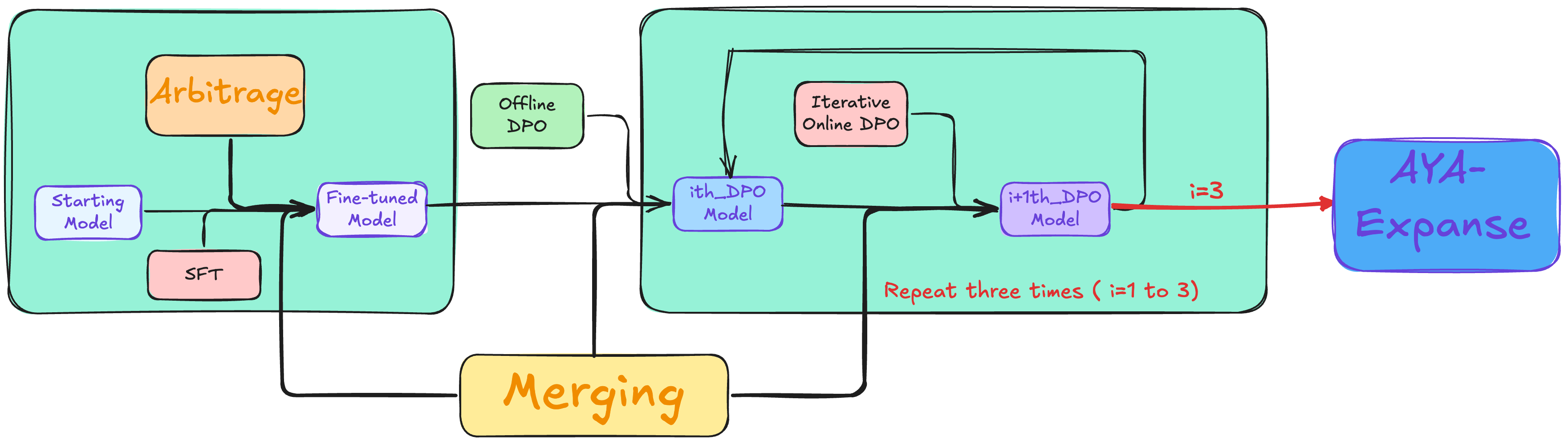
五、整体流程:
>> 端到端流程:文章总结了Aya Expanse模型的完整训练流程,包括数据仲裁、迭代偏好训练和模型融合等步骤。
Aya Expanse系列模型的成功,源于其在多语言模型训练中对多个关键问题的创新性解决。 这包括:利用数据仲裁技术克服合成数据训练中的模型崩溃问题;采用新颖的合成数据生成技术和离线/在线结合的偏好训练策略,有效提升模型对人类偏好的对齐程度;以及通过模型融合技术,最大化性能并降低计算成本。 这些技术的结合,最终使得Aya Expanse模型在多语言性能方面取得了显著的突破,并为多语言AI领域的发展做出了重要贡献。 其开源的特性也促进了社区的共同进步。
目录
《A Deepdive into Aya Expanse: Advancing the Frontier of Multilinguality》翻译与解读
《A Deepdive into Aya Expanse: Advancing the Frontier of Multilinguality》翻译与解读
| 地址 | |
| 时间 | 2024年10月24日 |
| 作者 | CohereForAI团队 |
这篇博文介绍了Cohere For AI团队开发的Aya Expanse系列多语言模型(8B和32B参数),该模型在多语言性能方面取得了显著突破。
Aya Expanse系列模型通过巧妙地结合数据套利、多语言偏好训练和模型融合等技术,在多语言性能方面取得了显著的突破。 文章详细介绍了每种技术的原理和实现方法,并通过实验结果证明了其有效性。 Aya Expanse模型的开源发布将有助于推动多语言AI领域的发展。 该研究的创新之处在于其对合成数据生成、多语言偏好训练和模型融合方法的改进,为构建高性能多语言模型提供了一种新的范例。 特别是数据套利策略的提出,有效地解决了低资源语言数据匮乏的问题,而结合离线和在线偏好训练的方法也提高了模型与人类偏好的对齐程度。 模型融合技术的应用则进一步提升了模型的效率和性能。
一、引言:突破多语言模型性能瓶颈
当前AI领域存在一个迫切的挑战:缺乏能够与单语言模型媲美的、高性能的多语言模型。Aya Expanse系列模型旨在解决这一问题。该模型是多年研究的成果,结合了数据套利、多语言偏好训练、安全微调和模型融合等技术突破。

二、避免合成数据中的模型崩溃:数据套利
合成数据在大型语言模型(LLM)开发中日益重要,但对于多语言数据,特别是低资源语言,高质量的教师模型匮乏。文章提出了一种名为“数据套利”的技术,通过从多个教师模型中策略性地采样来解决这个问题,避免了过度依赖单个教师模型导致的模型崩溃。
数据套利技术,通过利用多个模型的性能差异来生成高质量的多语言合成数据集,有效地解决了合成数据中模型崩溃的问题,并以Aya 8B模型在SFT阶段的改进为例证明了其有效性。
三、迭代改进:全局偏好
在监督微调之后,与人类偏好对齐是训练最先进LLM的关键步骤。多语言环境下的偏好训练面临诸多挑战,例如缺乏高质量的多语言偏好数据集。文章提出了一种新颖的合成数据生成技术,通过对比高性能多语言LLM生成的同语言完成与弱模型翻译自英语的完成,来构建高质量的多语言偏好数据对。此外,文章还探讨了离线和在线偏好训练的结合使用,并指出其优于单独使用其中一种方法。
如何通过构建高质量的多语言偏好数据和结合离线和在线偏好训练来改进模型,并通过Aya Expanse 8B模型与Gemma 2 9B模型的对比结果证明了该方法的有效性。
四、最大化性能:模型融合
模型融合是提高多任务学习效率的替代方法。文章利用了跨语言迁移学习的优势,通过训练针对不同语言族的多个模型,并最终进行融合来提高模型性能。文章比较了多种模型融合技术,最终选择加权平均作为最一致有效的方法。
模型融合技术在Aya Expanse模型中的应用,并指出在35B规模的模型中,模型融合带来的性能提升更为显著。
五、整体流程与结果
总结了Aya Expanse模型的端到端后训练流程,包括数据套利、迭代偏好训练和模型融合等步骤,并展示了每个步骤带来的性能提升。Aya Expanse 32B模型在多语言性能方面超越了多个现有模型,而Aya Expanse 8B模型也优于同参数规模的领先开源模型。
对整个模型训练流程和最终结果进行了总结,强调了Aya Expanse模型在多语言性能上的突破。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











