







LLMs之MoE:《Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs》翻译与解读
导读:这篇论文提出了一种基于模拟和系统优化的训练大型 MoE 模型的方法,并通过 Pangu Ultra MoE 模型的成功训练验证了其有效性,为大规模语言模型的训练提供了新的思路和技术方案。 它强调了模拟在减少实验成本和提高效率中的重要作用,以及在硬件平台上进行系统级优化的必要性。
>> 背景痛点:超大规模语言模型的挑战: 混合专家模型 (MoE) 的稀疏大型语言模型 (LLM) 参数量接近万亿,其训练对软件和硬件系统提出了巨大挑战。主要问题在于如何有效利用计算资源,如何在动态稀疏模型结构下实现预期的性能提升。反复进行代价高昂的实验来选择适合昇腾 NPU 的模型配置也十分低效。
>> 具体的解决方案:论文提出了一种在昇腾 NPU 上高效训练大型 MoE 模型的方法,核心在于 Pangu Ultra MoE 模型及其训练策略。具体包括:
● 基于模拟的模型配置选择: 为了避免反复进行耗时的实验,论文利用模拟技术比较不同模型超参数的权衡,从而选择最适合昇腾 NPU 的模型配置。
● 专家并行优化: 深入研究专家并行机制,优化 NPU 设备间的通信,减少同步开销。
● 内存效率优化: 优化设备内的内存效率,进一步减少参数和激活管理开销。
>> 核心思路步骤:
● 模拟驱动模型设计: 使用模拟技术预先评估不同模型超参数的性能,选择最优配置。
● 专家并行优化: 通过优化通信策略,减少NPU之间通信的延迟和开销。
● 内存优化: 改进内存管理策略,降低内存占用,提高训练效率。
● 端到端系统优化: 对整个训练过程进行系统级的优化,保证训练的稳定性和效率。
>> 优势:
● 高效利用昇腾 NPU 资源: 通过优化模型配置和系统,最大程度地利用昇腾 NPU 的计算能力。
● 降低训练成本: 减少实验次数,降低训练成本。
● 实现高性能训练: 在 6000 个昇腾 NPU 上训练 7180 亿参数的 Pangu Ultra MoE 模型,模型浮点运算利用率 (MFU) 达到了 30.0%,性能与 DeepSeek R1 相当。
>> 结论和观点:
● 论文提出的方法能够有效地训练大型稀疏 MoE 语言模型。
● 昇腾系统能够胜任最先进语言模型的所有训练阶段。
● 论文验证了模拟技术在选择模型配置方面的有效性。
● 论文对大型稀疏 MoE 模型的行为进行了研究,为未来的研究提供了参考。
● Pangu Ultra MoE 模型在 6000 个昇腾 NPU 上取得了显著的训练效率,证明了昇腾 NPU 在训练超大规模模型方面的能力。
目录
《Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs》翻译与解读
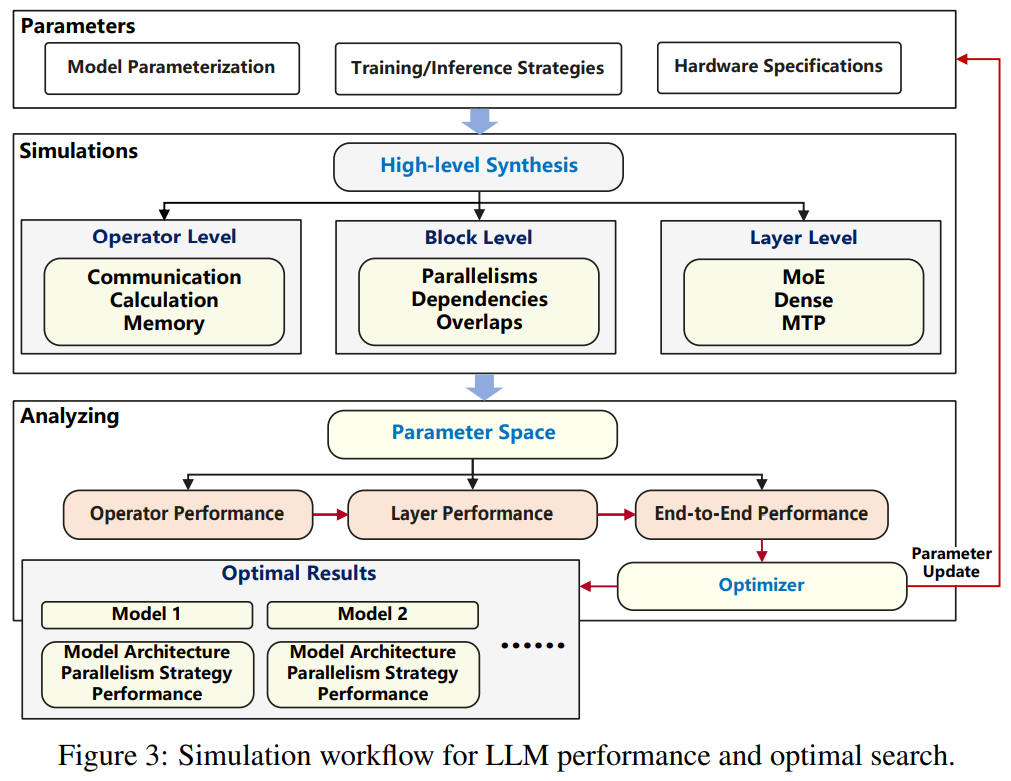
Figure 3:Simulation workflow for LLM performance and optimal search.图 3:LLM 性能与最优搜索的模拟工作流程。
《Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs》翻译与解读
| 地址 | 论文地址:[2505.04519] Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs |
| 时间 | 2025年5月5日 |
| 作者 | Pangu Team Huawei |
Abstract
| Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference. | 具有专家混合(MoE)结构且参数接近万亿的稀疏大型语言模型(LLM)正在主导最强大的语言模型领域。然而,如此庞大的模型规模给底层的软件和硬件系统带来了巨大挑战。在本文中,我们旨在探索在昇腾 NPU 上驾驭这种规模的方法。关键目标在于更好地利用动态稀疏模型结构下的计算资源,并在实际硬件上实现预期的性能提升。为了选择适合昇腾 NPU 的模型配置,而无需反复进行昂贵的实验,我们利用模拟来比较各种模型超参数的权衡。这项研究促成了拥有 7180 亿参数的稀疏 LLM——盘古超大规模 MoE 的诞生,并对模型进行了实验以验证模拟结果。在系统方面,我们深入研究专家并行技术,以优化 NPU 设备之间的通信,减少同步开销。我们还优化了设备内的内存效率,进一步降低参数和激活管理的开销。最终,在 6000 个昇腾 NPU 上训练盘古超大规模 MoE 模型时,我们实现了 30.0% 的最大浮点利用率(MFU),其性能与 DeepSeek R1 相当,并证明了昇腾系统能够驾驭最先进的语言模型的所有训练阶段。大量实验表明,我们的方案能够高效训练大规模稀疏语言模型的 MoE。我们还研究了此类模型的行为,以供未来参考。 |
1、Introduction
| Recent advances in sparse large-scale models have positioned Mixture of Experts (MoE) as a key ingredient for Large Language Models (LLMs), thanks to their capacity of learning effectively from tens of trillions of tokens [53, 58, 21, 33, 28, 4, 10]. The inference of MoE models is also more efficient than that of dense models because only a fraction of parameters are activated for a token [49]. However, training such large MoE models is no small feat, which requires sustained orchestra of thousands of AI computing nodes [10]. In addition, although the sparse structure can theoretically reduce the required computation by an order of magnitude, materializing the reduction is challenging because the actual fraction of parameters is dynamically determined jointly by the input tokens and the parameter states. Therefore, the computing cluster systems usually suffer from inefficient utilization when training large-scale MoE models. In this report, we aim to improve system utilization to make it effective and efficient to train large MoE language models on Ascend NPUs. Our design consists of two key aspects: model architecture design and system optimization. We hope to find the right model configuration that can be efficiently supported on Ascend NPUs, while reducing the overhead of communication between memory and processors as well as between NPUs. We first examine systematic architectural exploration to look for efficient model configurations on Ascend NPUs. We employ a two-level approach: pilot experiments for the MoE block design and system simulation for optimal model structures on Ascend NPUs. First, we conduct pilot studies on two critical aspects of MoE models: expert granularity [9] and the number of shared experts [26, 32]. Then, we develop a simulator to predict model performance by analyzing model throughput. The prediction employs a bottom-up workflow, with validating individual operators on Ascend NPUs as simulation basis, then to evaluate end-to-end system efficiency. To improve the precision of our simulation, we also consider computation-communication patterns across layers, operator-level interactions, and hardware-specific constraints. This simulation gives us the configuration of Pangu Ultra MoE, a sparse LLM with 718 billion parameters. During the actual model training, we also examine expert load imbalance and token drop strategy under the setup of the large MoE model with close to one trillion parameters. We find its training behavior is different from smaller sparse models. | 近期在稀疏大规模模型方面的进展使专家混合模型(MoE)成为大型语言模型(LLMs)的关键组成部分,这得益于其能够从数万亿个标记中有效学习的能力[53, 58, 21, 33, 28, 4, 10]。MoE 模型的推理效率也高于密集模型,因为对于每个标记,只有部分参数会被激活[49]。然而,训练如此大规模的 MoE 模型并非易事,这需要数千个 AI 计算节点的持续协同工作[10]。此外,尽管稀疏结构理论上能够将所需计算量降低一个数量级,但要实现这一目标颇具挑战性,因为实际激活的参数比例是由输入标记和参数状态共同决定的。因此,在训练大规模 MoE 模型时,计算集群系统通常会面临资源利用效率低下的问题。 在本报告中,我们旨在提高系统利用率,以实现高效地在 Ascend NPU 上训练大型 MoE 语言模型。我们的设计包含两个关键方面:模型架构设计和系统优化。我们希望找到一种合适的模型配置,能够在昇腾 NPU 上高效运行,同时减少内存与处理器之间以及 NPU 之间的通信开销。我们首先通过系统架构探索来寻找在昇腾 NPU 上高效的模型配置。我们采用两步走的方法:针对 MoE 块设计进行试点实验,以及通过系统模拟来确定在昇腾 NPU 上的最优模型结构。首先,我们针对 MoE 模型的两个关键方面进行试点研究:专家粒度[9]和共享专家的数量[26, 32]。然后,我们开发了一个模拟器,通过分析模型吞吐量来预测模型性能。该预测采用自下而上的工作流程,以在昇腾 NPU 上验证单个操作作为模拟基础,进而评估端到端系统的效率。为了提高模拟的精度,我们还考虑了跨层的计算-通信模式、操作级别交互以及特定硬件的约束条件。通过这种模拟,我们得到了盘古超大规模 MoE 模型的配置,这是一个拥有 7180 亿参数的稀疏大语言模型。在实际模型训练过程中,我们还研究了在拥有近一万亿参数的大规模 MoE 模型设置下专家负载不平衡和标记丢弃策略的情况。我们发现其训练行为与较小的稀疏模型有所不同。 |
| We then try to improve system utilization when training the models on thousands of Ascend NPUs. When conducting such experiments on large-scale MoE models, we encountered three bottlenecks: device communication overhead, high memory utilization, and imbalanced expert load. Traditional All-to-All communication in expert parallelism does not distinguish intra-node and inter-node traffic [51], leading to suboptimal bandwidth utilization and increased communication overhead. Most widely used memory-saving strategy recomputation focuses on the entire layer or the whole module [24], failing to effectively balance memory and runtime efficiency. Moreover, although auxiliary loss [11] may implicitly control the degree of expert balance through regularization, they do not adapt well to real-time fluctuations in computational load across devices. To address those challenges accordingly, we first carry out a fine-grained parallelism strategy and optimize communication patterns. To improve the efficiency of All-to-All communication in Expert Parallelism (EP), we introduce Hierarchical EP All-to-All Communication, optimizing bandwidth utilization by separating inter-node Allgather and intra-node All-to-All communications. These two communications are both effectively overlapped with computations by our proposed Adaptive Pipe Overlap mechanism, which leverages finer-grained operations to overlap communication with computation. To ensure stability within limited NPU memory, we then improve the efficiency of memory utilization by two techniques. First, we conduct fine-trained recomputation that selectively recomputes intermediate activations of specific operators instead of storing all activations or recomputing the entire layer. Second, we propose tensor swapping that offloads activations to the host temporarily and prefetches them for backward computation, without storing them on the NPU. To mitigate expert load imbalance, we propose a dynamic device-level load balancing approach using real-time load expert prediction and adaptive expert placement across NPUs. Taking advantage of our model selection strategy and parallel computing system optimization, when training Pangu Ultra MoE, with performance comparable to DeepSeek R1 [10], we achieve a Model Flops Utilization (MFU) of 30.0% and Tokens Per Second (TPS) of 1.46M on 6K Ascend NPUs, compared to the baseline MFU of 18.9% and TPS of 0.61M on 4K Ascend NPUs. In particular, Pangu Ultra MoE performs well on medical benchmarks. We also study the model behaviors, especially the MoE structure, to uncover further guidelines for training large-scale MoE models on Ascend NPUs. | 然后,我们在数千个 Ascend NPU 上训练模型时,尝试提高系统利用率。在对大规模 MoE 模型进行此类实验时,我们遇到了三个瓶颈:设备通信开销、高内存利用率和专家负载不均衡。专家并行中的传统全对全通信不区分节点内和节点间流量[51],导致带宽利用率低下和通信开销增加。大多数广泛使用的节省内存策略——重新计算,侧重于整个层或整个模块[24],无法有效平衡内存和运行时效率。此外,尽管辅助损失[11]可能通过正则化隐式控制专家平衡的程度,但它们不太适应设备间计算负载的实时波动。 为相应地解决这些挑战,我们首先实施了细粒度并行策略,并优化了通信模式。为了提高专家并行(EP)中全对全通信的效率,我们引入了分层 EP 全对全通信,通过将节点间 Allgather 和节点内全对全通信分离来优化带宽利用率。这两种通信都通过我们提出的自适应管道重叠机制与计算有效重叠,该机制利用更细粒度的操作来重叠通信与计算。为了在有限的 NPU 内存中确保稳定性,我们通过两种技术提高内存利用率。首先,我们进行精细训练的重新计算,选择性地重新计算特定操作的中间激活值,而不是存储所有激活值或重新计算整个层。其次,我们提出张量交换,将激活值暂时卸载到主机并预取以用于反向计算,而无需在 NPU 上存储它们。为了缓解专家负载不平衡,我们提出了一种动态设备级负载均衡方法,使用实时负载专家预测和在 NPUs 之间自适应放置专家。借助我们的模型选择策略和并行计算系统优化,在训练性能与 DeepSeek R1 [10] 相当的盘古超大规模 MoE 模型时,我们在 6000 个昇腾 NPU 上实现了 30.0% 的模型浮点运算利用率(MFU)和每秒 146 万的通量(TPS),而基准模型在 4000 个昇腾 NPU 上的 MFU 为 18.9%,TPS 为 61 万。特别是盘古超大规模 MoE 在医疗基准测试中表现出色。我们还研究了模型的行为,尤其是 MoE 结构,以进一步探索在昇腾 NPU 上训练大规模 MoE 模型的指导原则。 |
Figure 1:Experts number ablation. Since increasing experts from 256 to 512 brings limited gains, we select 256 experts for Pangu Ultra MoE to balance performance and practical efficiency.图 1:专家数量消融。由于将专家数量从 256 增加到 512 带来的收益有限,我们为盘古超大规模 MoE 模型选择 256 个专家,以平衡性能和实际效率。
Figure 2:Shared expert ablation. We compare the 20B baseline MoE (topk=8) and its no shared expert variant (topk=9). The former leads to slightly lower training loss.图 2:共享专家消融实验。我们将 200 亿参数的基线 MoE 模型(topk=8)与其无共享专家的变体(topk=9)进行比较。前者导致训练损失略低。
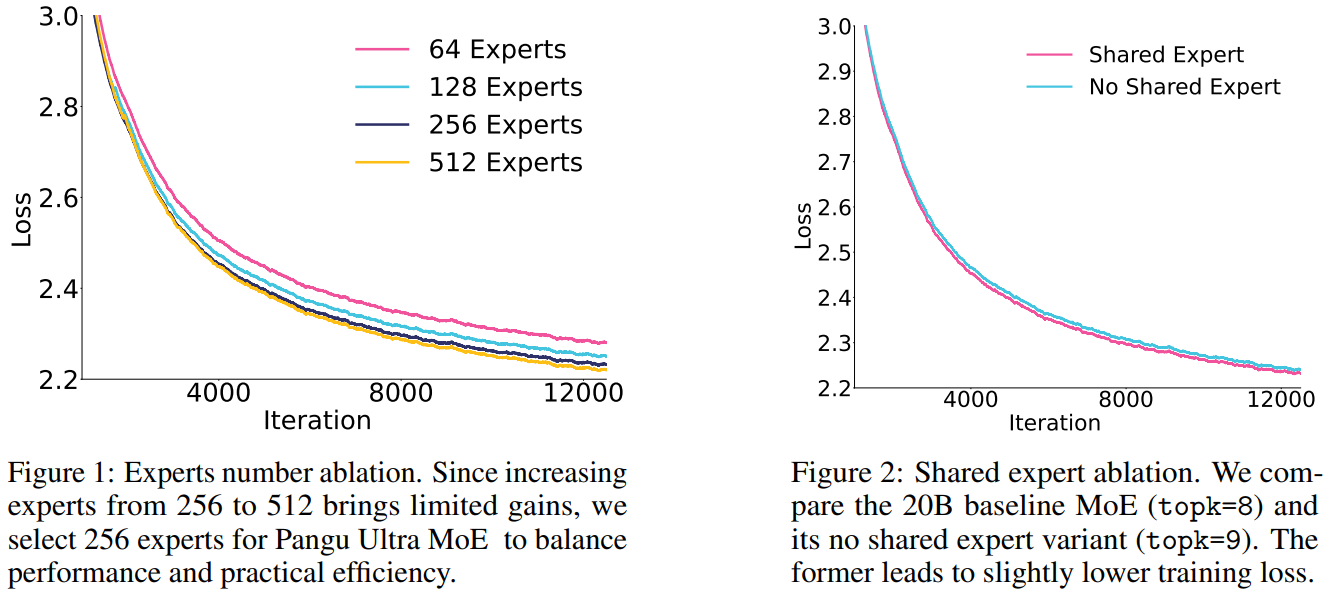
Figure 3:Simulation workflow for LLM performance and optimal search.图 3:LLM 性能与最优搜索的模拟工作流程。
Conclusion
| We present a systematic training recipe to efficiently train large-scale sparse MoE models on Ascend NPUs. To address system challenges posed by trillion-parameter models, we propose a simulation-driven strategy for optimizing model hyperparameters, reducing the need for costly hardware experiments. Our system optimizations focus on Expert Parallelism and memory management, significantly lowering communication and activation overhead across 6K NPUs. These innovations enable a 30.0% MFU, demonstrating Ascend NPUs’ capability to support full-scale training of large-scale sparse LLMs, e.g., Pangu Ultra MoE, with comparable performance as DeepSeek R1. Experiments validate that our method achieves hardware-aligned performance gains while maintaining training stability. Furthermore, our analysis of model behaviors provides insights for future research on balancing computational efficiency and model capacity. This work establishes a practical foundation for deploying massive MoE models in Ascend NPUs. | 我们提出了一套系统的训练方案,能够高效地在昇腾 NPU 上训练大规模稀疏的 MoE 模型。为了解决万亿参数模型带来的系统挑战,我们提出了一种基于仿真的策略来优化模型的超参数,从而减少了昂贵的硬件实验需求。我们的系统优化集中在专家并行性和内存管理方面,显著降低了 6000 个 NPU 之间的通信和激活开销。这些创新使得模型的计算利用率达到了 30.0%,证明了昇腾 NPU 能够支持大规模稀疏 LLM(例如盘古超大规模 MoE)的全规模训练,其性能与 DeepSeek R1 相当。实验验证了我们的方法在保持训练稳定性的同时实现了与硬件相匹配的性能提升。此外,我们对模型行为的分析为未来研究如何平衡计算效率和模型容量提供了见解。这项工作为在昇腾 NPU 上部署大规模的 MoE 模型奠定了实用基础。 |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











