






使用Python实现简单的词频统计
前言
此次作为一个简单demo分享,闲来试试做一个词频统计统计英语卷子单词出现的次数及频率,具体代码及分析如下。
anaconda第三方库的安装
使用pip list查看已经安装的

没有安装的使用pip install jieba
即可安装(建议安装时使用科学上网,安装速度会非常快)
代码分享及分析
这里代码有些乱,是为了进行一些测试。最后选取效果较好的一种。使用时将你的要分析的文件直接放进1.txt文件即可,设置好路径会统计出前1000的单词,可以根据循环次数进行统计数量的设定。
import jieba
import nltk
path = 'C:Users/Admin/Desktop/1.txt'
file = open(path, encoding='gb18030', errors='ignore')
file2 = open("C:Users/Admin/Desktop/2.txt", 'w',encoding='utf-8')
file2.write(file.read())
file.close()
file2.close()
#以上代码用于文本格式的修改,避免文档中格式的种种问题,也可以读取docx等文件
excludes = {"they","their","your","this","that","from","with","which","about","should"}
#去除掉你不想要统计次数的单词
def getText():
txt = open("C:Users/Admin/Desktop/2.txt", "r",encoding='utf-8').read() #读取Hamlet文本文件,并返回给txt
txt = txt.lower() #将文件中的单词全部变为小写
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, " ") #将文本中特殊字符替换为空格
return txt
#去除特殊符号
hamletTxt = getText()
#words = hamletTxt.split() #按照空格,将文本分割
#words = nltk.word_tokenize(hamletTxt)
words = jieba.lcut(hamletTxt)
#这里使用jieba库进行分词,也可以用上边的两者进行测试分词效果
counts = {}
for word in words:
if len(word) < 7:
continue
elif word in excludes:
continue
else:
rword = word
counts[rword] = counts.get(rword, 0) + 1
#去除单词长度在7个以下的,去除之前定义的,统计其他单词的数量
items = list(counts.items()) #将字典转换为列表,以便操作
items.sort(key=lambda x:x[1], reverse=True) # 见下面函数讲解
file2 = open("C:Users/Admin/Desktop/test2.txt","w")
for i in range(1000):
word, count = items[i]
#print ("{0:<10}{1:>5}{1:>5}".format(word, count,count))
file2.write("{0:<20}\n".format(word))
print("{0:<20}{1:>20}".format(word, count))
file2.close()
#将统计的信息打印并写入文件,这里写入时没有加入词频
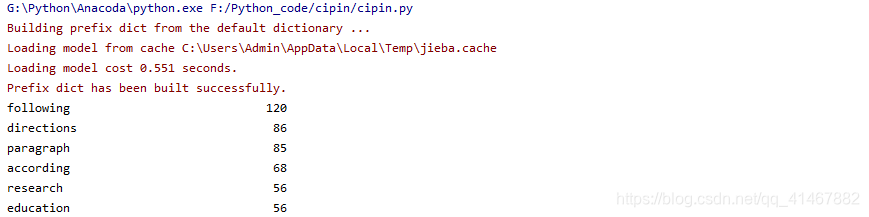
下附运行结果


















 2370
2370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









