







论文:Reinforcement learning in ophthalmology: potential
applications and challenges to implementation
强化学习可以处理不完整的数据和多变量决策问题:
- 使用强化学习优化眼科影像分析(例如OCT扫描)
- 强化学习算法帮助选择最有效的药物治疗方案
- 眼科疾病管理的长期性和复杂性,慢性眼病(如青光眼)的监控
- 眼科手术后的恢复监控,术后恢复过程和干预的个性化调整
慢病
- 子问题: 年龄相关性黄斑变性和糖尿病性视网膜病变的治疗优化
- 子解法: 使用强化学习优化抗VEGF注射决策和跟踪治疗效果
- 子问题: 青光眼的压力控制
- 子解法: 强化学习用于确定最佳降眼压治疗方案和手术时机
眼科中管理慢性疾病,如糖尿病性视网膜病变、老年性黄斑变性、葡萄膜炎和青光眼,是一个复杂且耗费资源的任务。
在处理这些疾病时,医生需要根据患者的具体情况做出一系列决策,例如是否进行药物治疗、选择何种药物,以及何时安排后续随访。
这就是强化学习在眼科慢性疾病管理中可以发挥作用的地方。
强化学习是一种机器学习方法,其核心在于通过试错来学习如何在特定环境中做出最优决策。
在眼科的情境中,强化学习算法可以被训练来识别何时进行治疗、选择最适合的药物,以及确定后续随访的时间。
这个过程可以类比于一个游戏,其中算法通过尝试不同的策略来获得“奖励”(如病情改善或视力提高)。每一次决策都会被算法评估,以确定其是否接近目标(即获得奖励)。
例如,在管理老年性黄斑变性或糖尿病性视网膜病变时,算法的目标可能是减少眼底的液体积聚(这可以通过光学相干断层扫描测量得到),或者提高患者的视力。
算法会在不同的治疗方案中做出选择,比如是否注射抗VEGF药物,如果注射,则选择哪种药物,以及何时进行随访。
通过这种方式,算法不断学习并改进其策略,以实现最佳的治疗效果。
在青光眼的治疗中,算法可能会被设置为将眼压控制在一个特定的范围内。
这可能涉及到选择不同的眼药水或考虑进行微创手术。
强化学习治疗糖尿病视网膜病变:
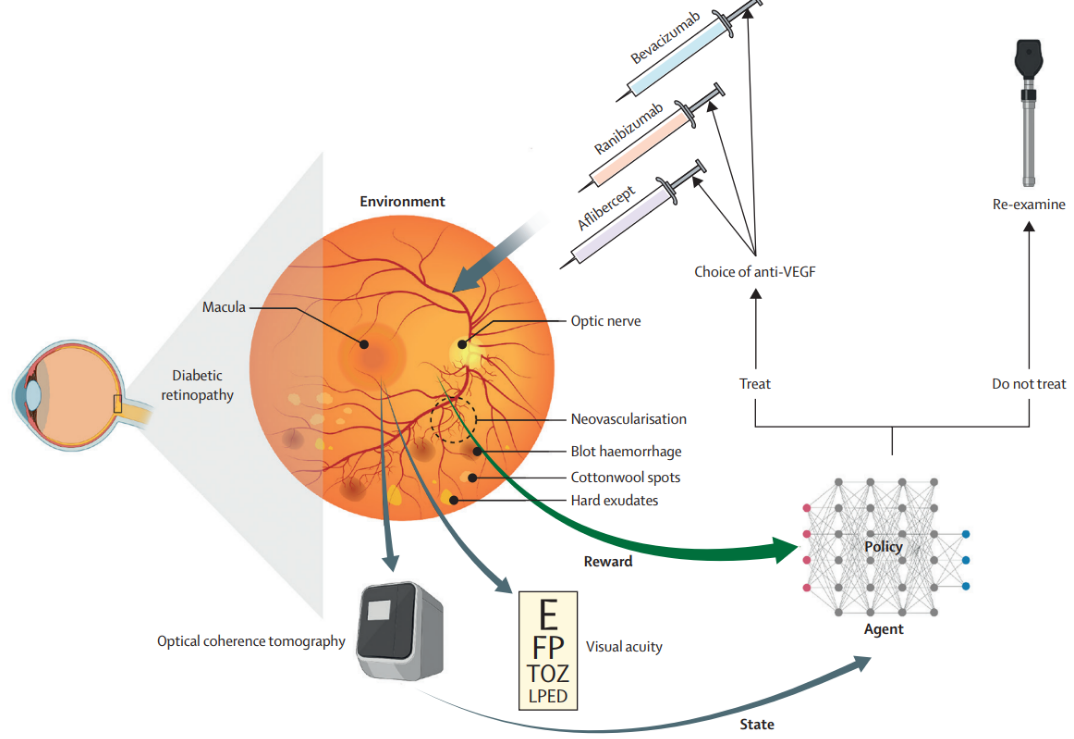
-
环境(Environment): 这通常指的是患者的临床情况以及所有相关的医疗数据。在这个例子中,环境由视网膜的详细图像所代表,这可能是通过光学相干断层扫描(OCT)获得的。
-
状态(State): 在强化学习中,状态是指环境的当前情况。在这里,状态可能包括OCT图像上的细节(如新生血管、出血斑点、棉絮斑和硬渗出物),以及视力测试的结果。
-
奖励(Reward): 强化学习模型的目标是最大化奖励,这在医疗应用中通常与治疗效果相关。这里的奖励可能是基于OCT图像上病变的减少和视力测试结果的改善。
-
策略(Policy): 这是由强化学习算法确定的决策过程,它定义了在给定状态下应采取的最佳行动。
-
代理(Agent): 代理是执行策略、进行决策和行动的实体,在这个场景中,代理将是强化学习模型本身。
-
行动(Action): 在治疗糖尿病视网膜病变的背景下,可能的行动包括是否治疗,如果治疗,使用哪种抗血管内皮生长因子(VEGF)药物,以及何时复查患者。
影像
- 原因: 强化学习能够处理复杂的影像数据,需要较少的标注数据
- 使用强化学习辅助影像分割,减少对人工标注的依赖
医生们使用多种成像技术来诊断和监测眼部疾病,这些成像方法能捕捉到大量的数据,但同时也给医生分析这些数据带来了挑战。
通常,医生需要从这些复杂的图像中识别出疾病相关的特定区域。
在传统的监督学习方法中,需要大量的标记数据(即专家标记的图像)来训练算法识别这些区域。
这不仅耗时耗力,而且在实际应用中很难扩展。
强化学习在这方面提供了一个独特的优势。
不同于传统的监督学习,强化学习不依赖大量的标记数据。
相反,它通过不断的尝试和错误来“学习”如何正确地进行病症识别。
就像是在玩一个游戏,算法通过不断尝试来学习怎样更准确地识别出病理区域。
每次尝试都会根据算法的表现给予一定的“奖励”或“惩罚”,从而使算法逐渐优化其分割技巧。
例如,当使用光学相干断层扫描来检测眼底疾病时,强化学习算法可以被训练来识别出疾病相关的特定区域,如视网膜液体积聚或病变。
这样的算法不需要成千上万的标记图像,而是通过自己的尝试和经验来学习。
这种方法不仅节省了大量的时间和资源,也使得算法在处理新的、未见过的数据时更加有效和灵活。
手术
原因: 强化学习能够处理复杂的手术决策,适用于多阶段的手术过程
- 子问题: 手术前的优化规划
- 子解法: 强化学习辅助确定最佳手术时机
- 子问题: 手术中的决策支持
- 子解法: 强化学习用于自动化手术流程,提供即时反馈,避免并发症
- 子问题: 手术训练和全球卫生组织的支持
- 子解法: 强化学习辅助手术训练,减少早期手术并发症,支持低资源环境下的手术教学
强化学习在眼科手术中的应用,特别是在从术前规划到术后管理的全过程中,展示了其独特的优势。
如果我们将整个眼科手术过程比作一个复杂的游戏,强化学习就像是在这个游戏中学习和优化每一步的高级玩家。
首先,在术前阶段,强化学习可以帮助确定手术的最佳时间。
这就像游戏中的战略规划,算法通过分析以往患者的手术结果和恢复情况,来学习什么时候进行手术最合适。
这不仅可以提高手术的成功率,还能更好地安排医院资源。
在手术过程中,决策通常是复杂且多变的。
强化学习在这里的角色可以类比于一个高级的游戏辅助工具,它能够在多种可能的手术步骤和策略中选择最优的一种。
例如,使用现代的3D手术显微镜,强化学习算法可以通过分析大量的3D手术视频来学习手术中每个步骤的最佳做法。
这就像在游戏中通过观察和实践来掌握每个关卡的最佳策略。
特别是在复杂的手术步骤,如撕囊或视网膜外膜剥离中,强化学习算法能够识别和奖励执行得最好的手法。
然后,这些信息可以被内置到手术显微镜中,通过指示灯或声音警告来指导外科医生。
这就好比在游戏中有一个提示系统,能实时告诉玩家最佳的操作方法。

















 228
228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









