







论文:AutoMedPrompt: A New Framework for Optimizing LLM Medical Prompts Using Textual Gradients
代码:https://github.com/SeanWu25/AutoMedPrompt
问1:AutoMedPrompt的主要目的是什么?
-
答1:可用自动化的文本梯度来优化提示词,使LLM在医学领域的性能更好。
-
通过文本梯度的反馈,让模型自动生成和微调提示词,从而提高回答准确度。
问2:“文本梯度”是指什么?
-
答2:它指的是模型根据生成的文字反馈,自动评估并迭代改进提示词,就像网络中反向传播那样,但这里用的是文字差异。
为什么“文本梯度”能够优化医学提示词?
-
LLM 的输出本质上包含自反馈信息,可以通过迭代提示词优化来增强医学回答的准确性。
-
传统的 CoT 仅依赖固定结构的推理链,而文本梯度可以根据数据动态优化提示词。
为什么 AutoMedPrompt 比手动优化提示词更有效?
-
-
人工优化提示词依赖专家经验,无法快速适配不同医学问答任务。
-
AutoMedPrompt 通过文本梯度计算,能够自动调整提示词,使其在不同数据集上适配性更高。
-
问3:为什么要进行提示词的自动优化,而不是手动编写提示?
-
答3:医学领域涉及专业知识,手动编写容易遗漏或不匹配特定题目,“自动优化”让提示词更能针对性地指导模型回答,提高准确率和一致性。
问4:它与传统的Fine-Tuning有何不同?
-
答4:Fine-Tuning需要改动模型参数,通常耗时且需要额外的硬件资源;而AutoMedPrompt只改进提示词,不动模型本身,成本更低,迭代更方便。
问5:AutoMedPrompt用在医学问答中有何独特优势?
-
答5:医学问答需要准确且专业的回答,自动优化的提示词能让模型更聚焦在医学证据、临床逻辑等关键点,从而提升临床问题回答的可靠性。
问6:它在与GPT-4等商业模型比较时表现如何?
-
答6:在文中测试的PubMedQA、MedQA等数据集上,结合了AutoMedPrompt的开源模型在准确率上能达到、甚至超过GPT-4等专有模型的水平。
问7:为什么说这个方法对医疗机构有吸引力?
-
答7:因为他们无需大量投入算力和数据对模型做微调,只需通过文本梯度迭代提示词就可显著提升性能,成本和技术门槛更低。
解法拆解:
├── AutoMedPrompt【整体解法】
│ ├── 子解法1:仅优化System Prompt【因为特征A:微调成本高】
│ │ ├── 不更新LLM权重,只迭代Prompt
│ │ └── 节省GPU/TPU资源,部署简单
│ │
│ ├── 子解法2:回答差异→文本梯度【因为特征B:自然语言Loss更灵活】
│ │ ├── LLM对比标准答案给出改进反馈
│ │ └── 用TextGrad解析反馈为可微梯度,修订Prompt
│ │
│ └── 子解法3:验证集回退+停止【因为特征C:梯度更新可能失控】
│ ├── 每轮更新后测准确率,若无提升则回退
│ └── 连续多轮无改进则停止迭代全流程分析:
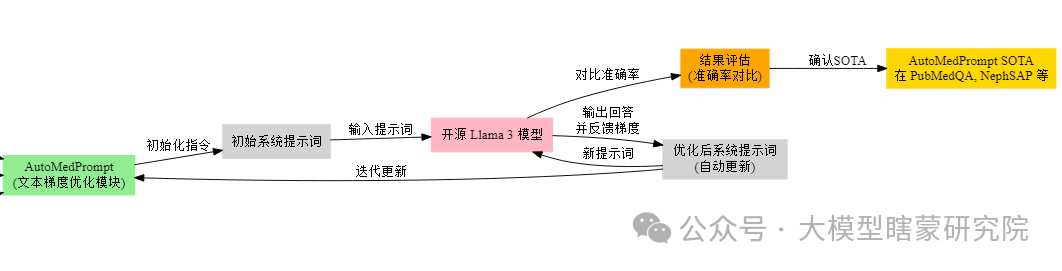
核心方法:AutoMedPrompt文本梯度优化【总体框架】
├── 输入【需要优化的对象】
│ ├── 医疗问答数据集【训练/验证用】
│ │ └── 提供医学题目及其标准答案,后续作为LLM优化依据【真值参照】
│ ├── 初始System Prompt【待自动迭代的目标】
│ │ └── 模型对话开头的指令性文本,决定回答风格与重点【模型行为约束】
│ └── LLM本体(如Llama 3 70B)【处理引擎】
│ └── 负责对输入Prompt与问题进行语言生成【核心推理模块】
│
├── 处理过程【如何完成优化】
│ ├── 1. 建立可反传的计算图【图结构搭建】
│ │ ├── 将Prompt、模型回答、评估反馈等节点视作“可微”组件【节点封装】
│ │ └── 为每轮训练构造forward流程:LLM读取Prompt后生成回答【数据流】
│ ├── 2. 计算自然语言Loss【关键评价指标】
│ │ ├── 将LLM回答与标准答案或医学评估函数进行比对【评估差距】
│ │ └── 用语言描述的形式(如“回答可更详细”)转化为文本梯度【自适应】
│ ├── 3. 生成文本梯度【梯度来源】
│ │ ├── 根据Loss反馈,LLM产生改进建议(对Prompt的修改指导)【文字化梯度】
│ │ └── 类似神经网络中的反向传播,只是以文本方式呈现【对Prompt的敏感度】
│ ├── 4. 更新System Prompt【参数更新】
│ │ ├── 将上一步的文本梯度解析并注入原Prompt【Prompt重写】
│ │ └── 迭代后得到新的Prompt,使LLM下轮回答更贴近标准【目标逼近】
│ └── 5. 终止条件与版本回退【优化结束策略】
│ ├── 若验证集准确率无提升,回滚到之前最佳Prompt【避免性能倒退】
│ └── 达到预设次数或稳定收敛后,停止自动迭代【收敛判定】
│
├── 输出【结果产物】
│ ├── 最优System Prompt【改进后】
│ │ └── 能针对特定医学问答场景生成更精准、符合标准的解答【目标实现】
│ └── 改进的医疗问答性能【模型表现提升】
│ └── 在测试集上准确率、医疗合理性等指标显著提高【效果衡量】
│
└── 技术衔接【方法内各步如何联动】
│ ├── 自然语言Loss与文本梯度互补【反馈环节】
│ │ ├── 评估时LLM用自然语言解释不足点【可读性】
│ │ └── 文本梯度再指导Prompt修改【可操作性】
│ ├── 自动迭代与LLM推理循环进行【动态优化】
│ │ ├── 每轮新Prompt即时被LLM使用进行回答【实时生效】
│ │ └── 评估完后再回到Prompt更新步骤【闭环】
│ └── 验证集监控准确率,若无改善则回滚【鲁棒性保证】
│
└── 整体意义【方法的价值】
├── 仅依靠Prompt更新即可让通用LLM快速适应医疗场景【轻量化】
└── 自动文本梯度避免大量人工提示工程与微调成本【高效性】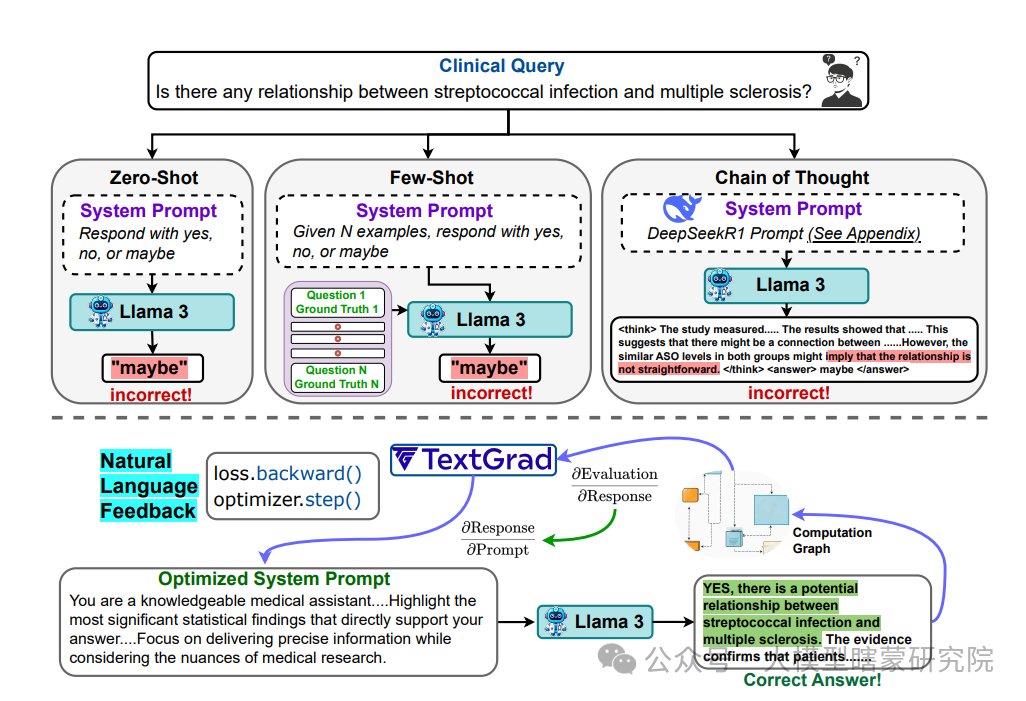
1. 设定场景
- 任务:回答 NephSAP(肾内科)的一道多选题。
- 正确答案(Ground Truth):选项 B。
- 初始系统提示词:
"你是一个通用医学助手。请阅读问题并给出正确答案。只需要回答 A/B/C/D/E 之一。"
2. 模型第一次回答
-
题目:
“某 65 岁男性,高血压史 10 年,突然出现肉眼血尿,伴随腰痛并且短期内血肌酐飙升。最可能的诊断是什么?
(A) 急性肾小球肾炎
(B) 肾动脉狭窄
(C) 慢性肾衰竭
(D) 急性肾盂肾炎
(E) 肾静脉血栓形成” -
模型回答:
<answer>A</answer>
显然,模型与 Ground Truth 不一致(正确答案是 B)。
3. 生成自然语言反馈(文本梯度)示例
为了让模型知道哪里出错,需要“文本梯度”做出明确的自然语言反馈,如下所示(仅作示例,实际可能更详细或结构化):
反馈:
“你的回答是 A,实际正确答案为 B。你需要更关注‘突然出现血尿+血肌酐飙升’所指向的肾血流动力学问题。
可以在提示词中加入:
更强调‘与肾血管异常相关’的线索;
明确‘腰痛、血尿伴高血压史’倾向于肾动脉狭窄或血管性病变的概率。”
在 TextGrad 框架中,这段自然语言反馈就相当于“梯度”的雏形。因为它告诉了模型“怎么改进回答”,实际上也为我们指示了“提示词该如何被修正”。
4. 将文本反馈解析为“梯度”
文本梯度模块会从上一步中提取与“系统提示词”相关的关键信息,例如:
- 在提示词中需强调‘与肾血管相关病变’。
- 提醒模型关注‘血尿 + 高血压史 + 突然加重’这种组合。
- 去弱化对‘肾炎’类关键字的优先权重(因为题干并没有典型肾炎特征)。
这就像一条“方向指引”或“梯度向量”,告诉提示词应该往哪方面修改。
5. 更新系统提示词
据此,我们在系统提示词中自动追加或调整内容,形成新的系统提示词。例如:
-
原提示词:
“你是一个通用医学助手。请阅读问题并给出正确答案。只需要回答 A/B/C/D/E 之一。”
-
更新后提示词:
“你是一名专业的肾内科医学助手,尤其擅长血管相关的肾脏病变。
-
请关注:血尿、腰痛、高血压史 与 血肌酐飙升 之间的联系。
-
判断是否存在血管性病变(如肾动脉狭窄)。
-
最终只回答 A/B/C/D/E 之一,并在思考时优先考虑血管因素。”
-
文本梯度解析出来的“如何改进”就体现在这段新的系统提示词中。
6. 再次让模型回答
-
使用更新后提示词再次让模型回答同一道题:
-
给定“血尿 + 血肌酐急速上升 + 高血压”更可能指向肾动脉狭窄;
-
提示词强调了“血管性病变”;
-
模型也会有更高概率注意到 B 选项。
-
-
模型第二次回答(示例):
<answer>B</answer>
这次与 Ground Truth 一致,说明调整提示词取得了预期效果。
总结
以上流程演示了TextGrad的基本思路:
- 收集模型回答 → 比对正确答案 → 得到自然语言的“差异反馈”。
- 解析反馈 中的关键信息,提炼改进方向(即“梯度”)。
- 更新提示词,在系统提示或上下文里强化或弱化相应要点。
- 多轮迭代,直到验证集准确率趋于稳定或达到设定目标。
这就是所谓的 “将语言模型输出变成梯度”的示例:并不需要像传统机器学习那样反向传播数值,而是利用文本自身提供的信息,来指导系统提示词的迭代优化。
数据来源
-
作者引用了多个公共医学问答数据集(如 PubMedQA、MedQA、NephSAP 等),这些数据集都来自公开的学术或医疗领域资源。
-
其中:
- MedQA
数据集:含有 1.27k 测试题,以及大约上万条训练样本。
- PubMedQA
数据集:训练集 500 条,测试集 500 条,另有 50 条用于验证。
- NephSAP
数据集:总计 858 道专科性肾内科多项选择题。
- MedQA
2. 数据全面性
-
这些数据集覆盖了不同难度和多样性的医学问答场景,从通用医学考试 (MedQA) 到研究文献 (PubMedQA),再到专科领域 (NephSAP)。
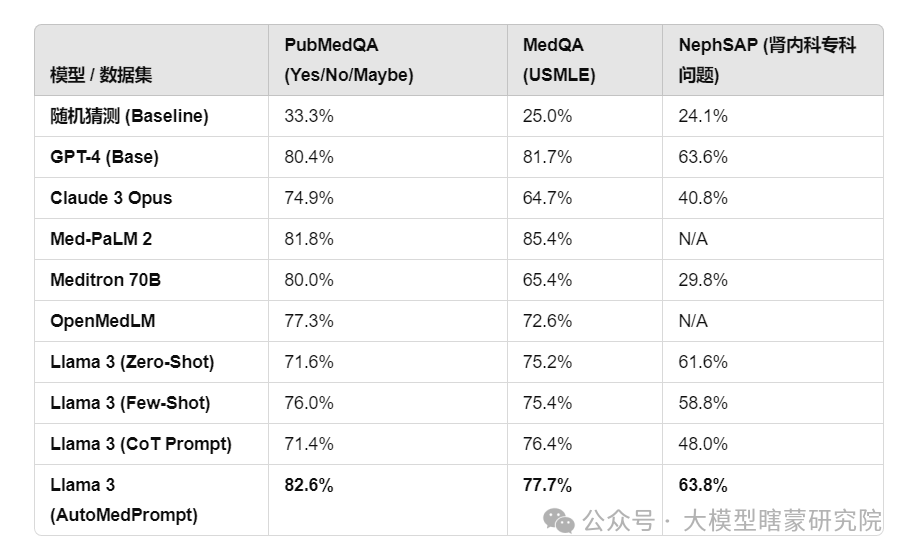
PubMedQA 提升最多(+11.0%),AutoMedPrompt 超过 GPT-4、Med-PaLM 2,创下 SOTA。
MedQA 提升有限(+2.5%),但在开源 LLM 里表现最佳。
NephSAP 提升显著(+15.8%),特别是在 Few-Shot、CoT 失败的情况下,AutoMedPrompt 显著提高了专科领域的表现。
提问
Q1:文本梯度在优化提示词时,如果多次迭代后模型结果反而变差,作者是如何处理这种“倒退”现象的?
-
A1:他们设置了回退策略。如果新提示词的验证集性能下降,则回滚到上一轮最佳提示词,避免过度优化或出现“提示词塌陷”。
Q2:在 NephSAP 这样的专业肾内科题库上,为什么 Few-Shot 的效果会比零样本和 CoT 还要差?
-
A2:因为 Few-Shot 所选示例并不总能匹配到专业领域的核心考点,反而会给模型带来误导或噪声,导致效果变差。
Q3:论文给出的实验结论中,为什么 MedQA(USMLE 考试题库)的提升幅度较小(仅 2.5%左右)?
-
A3:USMLE 题目相对标准化,模型在初始状态就能拿到较高分,而优化空间有限,所以相对提升幅度也就较小。
Q4:当研究者需要回答开放式病例分析(不是选择题)时,AutoMedPrompt 还能否发挥同样的效果?
-
A4:论文集中在多选或是 yes/no/maybe 等测试题;对于开放式问题,文本梯度同样适用,但需要更复杂的自动评价方法来产生“语言反馈”。
Q5:对于“文本梯度”要反复迭代多次,作者的实验中一般迭代了多少轮?
-
A5:论文中提到,通常十几到几十轮能达到收敛;具体迭代次数还依赖于验证集大小与任务复杂度。
-
每个数据集特征不同,手动给出“通用最优模板”不一定有效;使用者可以借助文本梯度在自己数据上自动找到最优提示词。
Q6:作者有没有讨论对失败案例的处理方式,比如提示词再怎么改都提升不了?
-
A6:文中提到如果经过多轮迭代准确率无法提升,应检查数据或任务本身;可能模型先天知识不足,需要补充外部知识或有限微调。
Q7:AutoMedPrompt 是否对每道题都单独生成提示,还是保持全局统一提示?
-
A7:作者多次强调统一的系统提示,但在内部会自动调参,最终形成适用于大多数题目的统一“最佳提示”,不针对单个题目分别生成。
Q8:在 NephSAP 数据集上,CoT 的准确率降得非常厉害(48%),作者认为原因是什么?
-
A8:NephSAP 提问形式和思路较专业,通用 CoT 一旦生成错误推理链,会不断累积误差,导致效果更差;这也印证了提示词的关键性。

















 27万+
27万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









