







已剪辑自: https://mp.weixin.qq.com/s/3zHRuKKexffJQ7JkhzGhtA
本文选自极术专栏“IC设计”,授权转自微信公众号芯工阿文,本篇将给大家梳理一下硬件虚拟化及其相关逻辑的内容,帮助大家更容易理解虚拟化的定义。
前段时间在梳理一些概念时,突然对虚拟化有一种新的认识,之后再去了解相关的概念或技术,能够推测某个技术是为了解决什么问题和如何实现的。
本文将对硬件虚拟化及其相关逻辑进行罗列,可能会对理解虚拟化有一些帮助。
Virtualization is the application of the layering principle through enforced modularity, whereby the exposed virtual resource is identical to the underlying physical resource being virtualized.
虚拟化通过模块的方式来进行分层,使得暴露出来的虚拟资源和物理资源相似。
——《Hardware and Software Support for Virtualizaton》
上述定义中,使用分层原则,使用模块进行隔离,从某个接口来看,保证虚拟出来的资源与物理资源类似。支持虚拟化技术后,下层资源可以被调度到多个上层虚拟资源使用。下层和上层定义是相对的,存在不同技术,也存在软件和硬件的虚拟化技术,如Docker就属于软件层面的虚拟化技术,是操作系统的虚拟化。
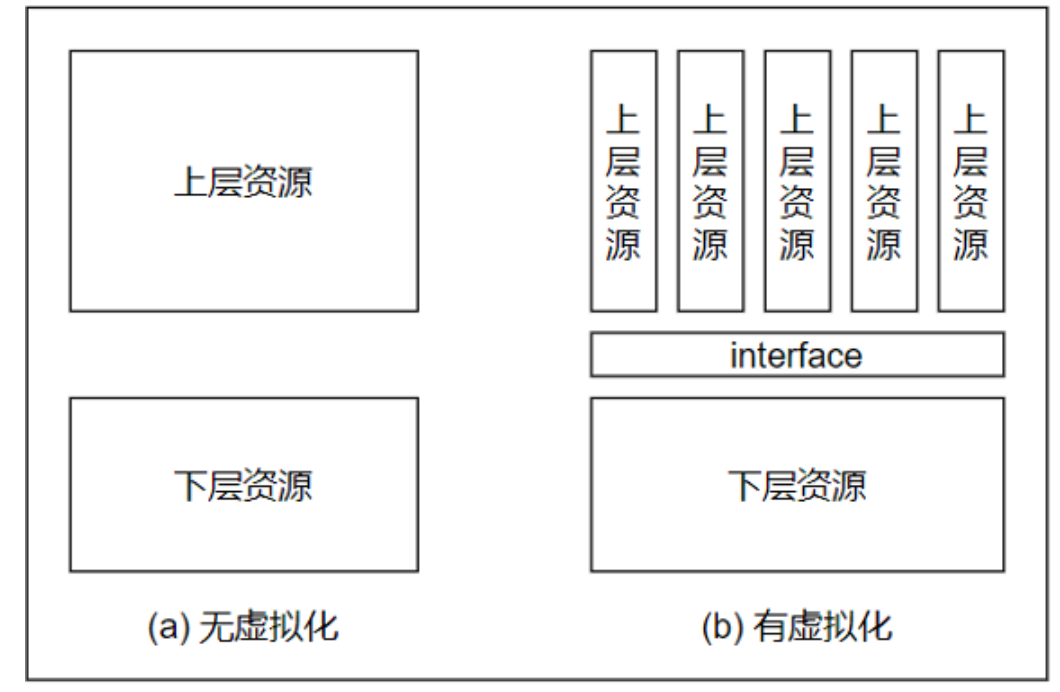
虚拟化技术非常广泛,本文仅描述硬件虚拟化,且是硬件辅助的虚拟化技术。
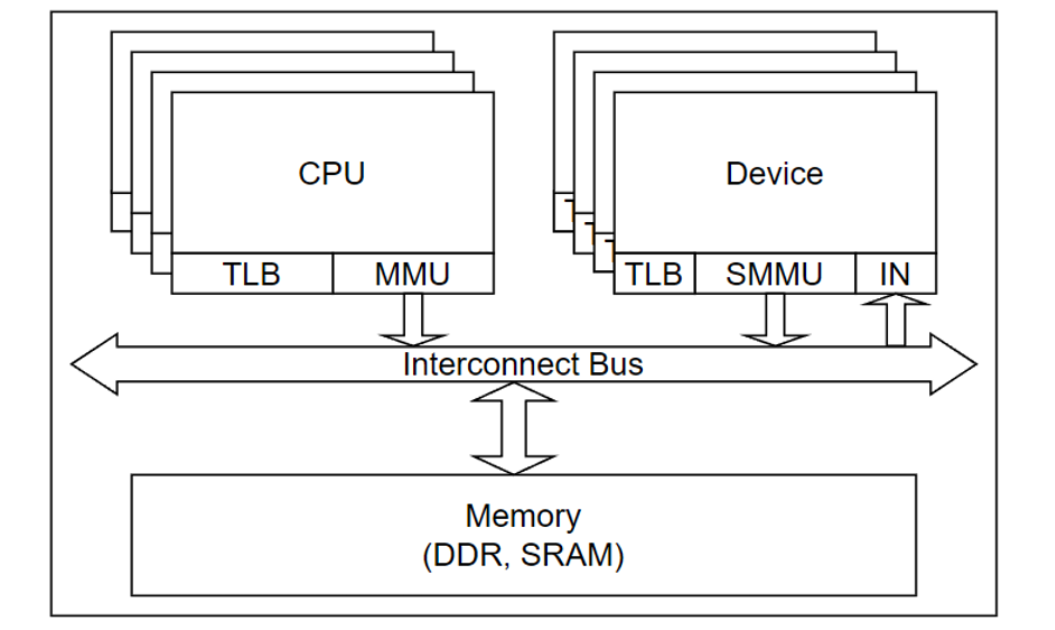
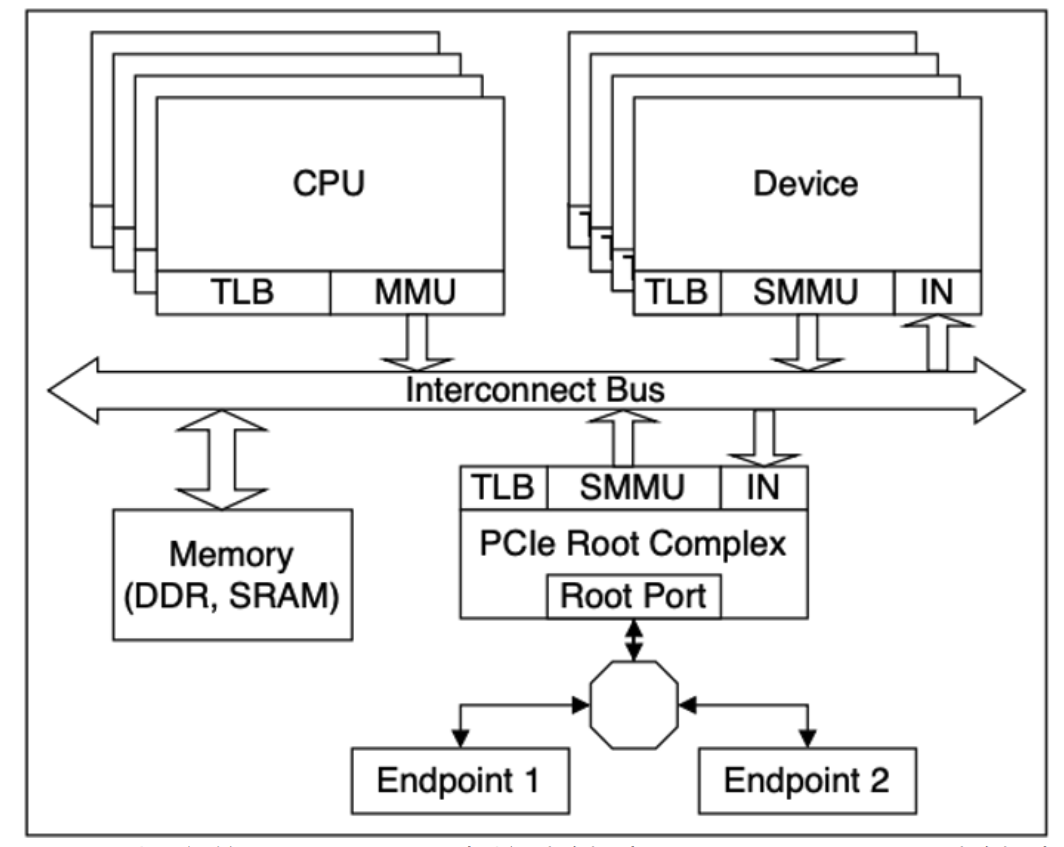
在极简的系统结构模型中,SoC系统可以划分为三部分,分别是广义DMA、存储体和连接通道。在数据传输一文中,描述了模块的两种启动方式,一种是自启动,典型例子是DMA,另一种是被启动,典型例子是DMA、加速器,这两种方式的模块均属于广义DMA。至此,SoC系统包括自启动DMA、被启动DMA、存储体和互联总线,如下图所示。
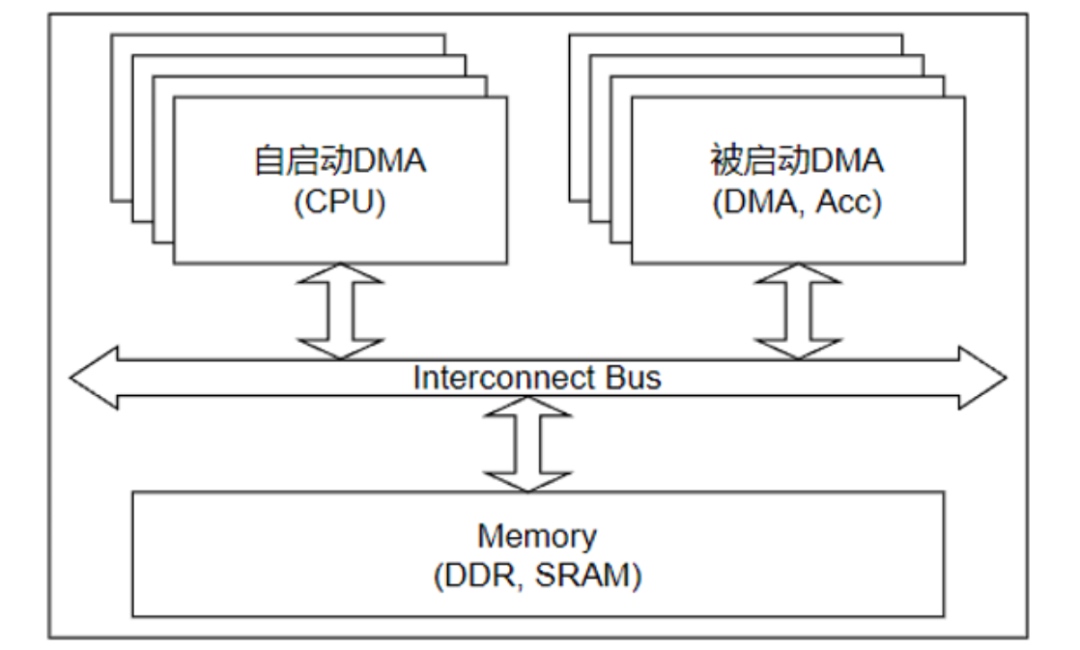
我的理解,硬件系统结构基本等效为如上模型。其余的模块,都是为了加速上述元素中某一方面的性能而引入的,如Cache就是为了加速DMA访问Memory的延时性能。该硬件系统的上层就是软件操作系统,虚拟化技术,就是将这一套硬件结构能够被多个操作系统进行调用。
在之前的文章有提到过,统一的语言是对话的前提,系统内的语言就是地址。分析地址域是了解系统的重要环节,相同地址域直接进行数据传输,不同地址域之间的数据传输需要经过翻译转换;若不同地址域之间不存在转换机制,两者不可直接进行数据交互,进而实现隔离与安全。
存在虚拟机的场景下,地址域的分析可近似如下图所示。地址信号是二进制数,区分不同的地址域,无非也就是扩展其位宽,同时赋予其新的名词,在这里就是Virtual Machine Identifier(VMID)和Address Space Identifier(ASID)。进程内使用的地址为Virtual Address(VA),在系统内标记为vmid + asid + va,存在转换关系(vmid + asid + va) -> pa(后续简化为VA->PA),将进程内的虚拟地址与实际物理地址进行映射,这个转换关系称为页表。
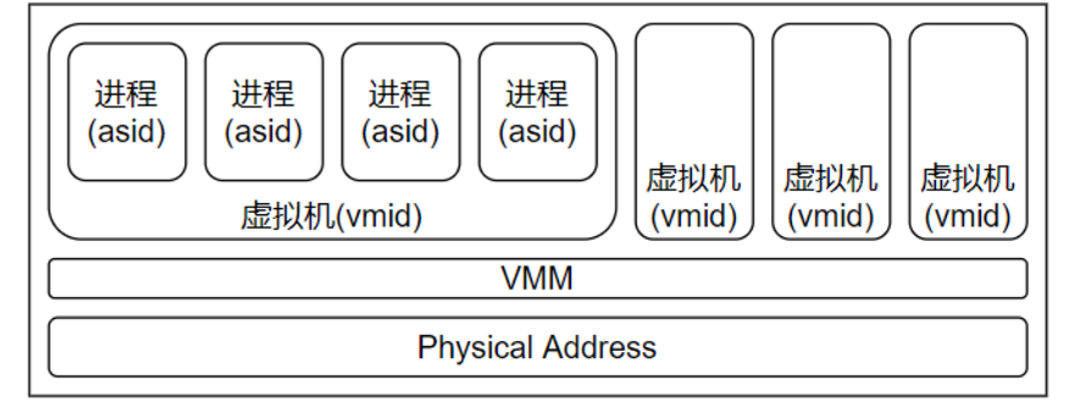
再来看硬件系统的互联总线,不同模块之间进行数据传输,必须有相同的地址域,也就是图中的Physical Address(PA)。
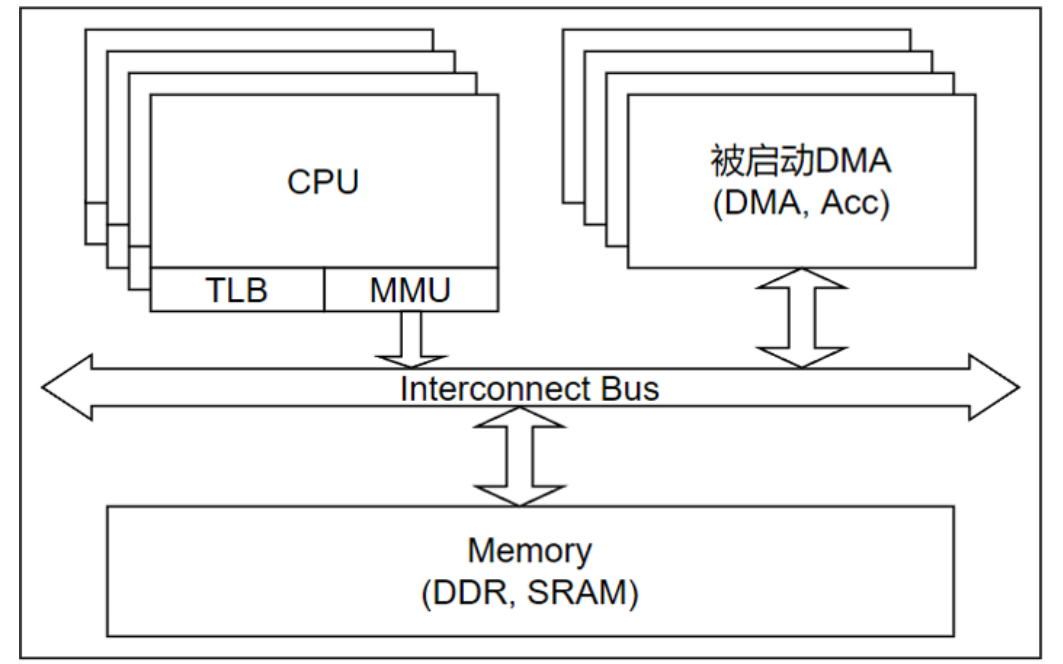
实际上,上述的VM和进程均属于软件层面的概念,存在于CPU内部。若进程内使用VA访问Memory系统时,必须进行地址转换,而负责这一转换的硬件逻辑是MMU。
至此,硬件系统结构模型如下,MMU将CPU当前进程的虚拟地址转换为PA,再发送至互联总线访问其余模块。由于VA->PA的页表保存于Memory内存,为避免每次转换都需要查询内存的页表,增加了Cache进行加速,也即Translation Lookaside Buffer(TLB)。
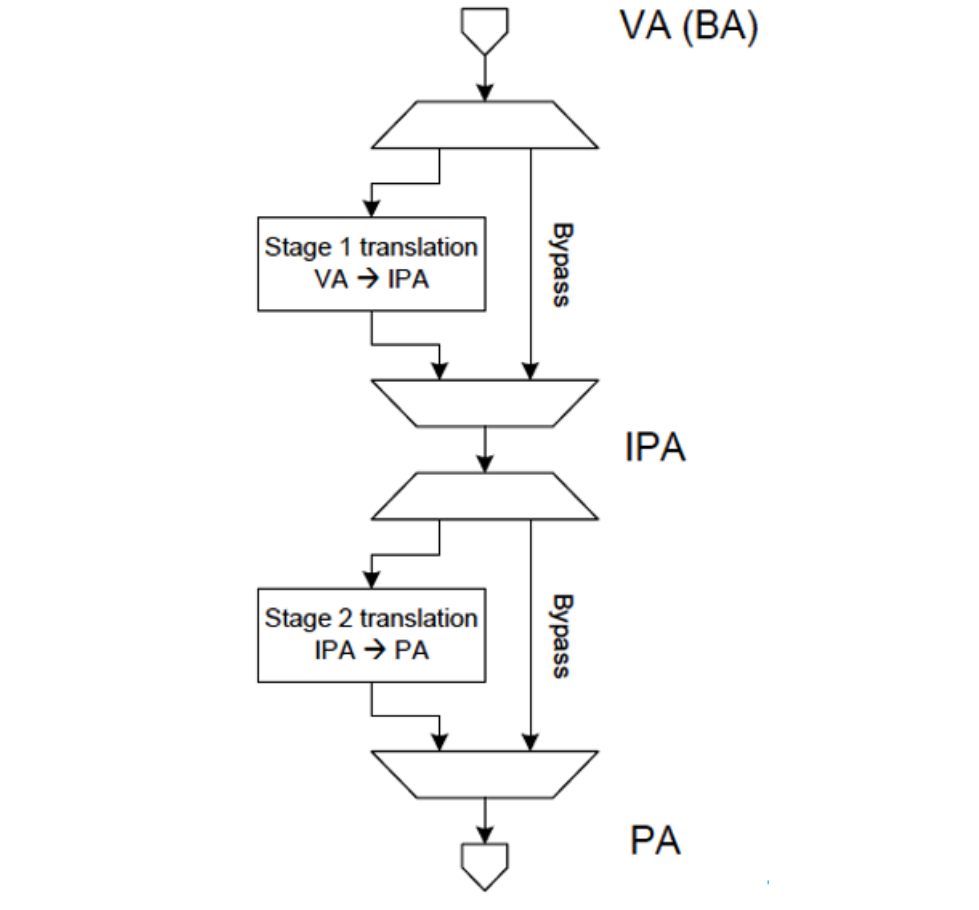
注意到地址域分析图,进程内的应用基于物理地址访问Memory,需要经过两级地址转换,Stage 1是将VA转换为对应虚拟机内的地址,称为Intermediate Physical Address(IPA),Stage 2是将IPA转换为PA。这两级的地址转换由MMU完成,还有各种权限及属性相关内容。根据不同的场景,两级地址转换均可进行Bypass处理,其转换关系如下图所示。另外,系统内的很多特性均是构建于该地址转换流程的,如隔离和安全,进程使用VA访问,若没有相关页表,就无法访问。
被启动DMA,包括片上设备和PCIe设备,其中片上设备为芯片内部集成的硬件加速器或IO口,PCIe设备为通过PCIe接口连接的设备。设备虚拟化,也即是一个物理设备,对上层软件系统呈现为多个逻辑设备,可以被虚拟机及其进程直接使用。
在数据传输一文有描述,设备工作需要接收其余模块的配置请求,也能够访问系统内的其余模块。配置请求的上游是互联总线,使用的是PA,因此每个逻辑设备的配置空间地址是真实存在的,有多少逻辑设备,就需要在系统的物理地址内分配多少的配置空间。VMM会先将配置空间的PA转换为VA,虚拟机及其进程可使用该VA直接访问设备,MMU将该地址转换为PA再发送至互联总线。
设备直接接收虚拟机及其进程的配置请求,拿到的是VA,再使用该VA访问其余模块,必须先上互联总线,因此设备的访问出口与互联总线之间必须引入地址转换模块,将VA转换为PA。
通过扩展信号位宽来区分其地址域,设备也是采用相同的策略,只是其名称有所区别。在ARM体系中,命名为StreamID和SubstreamID;在PCIe体系中,命名为RequesterID和PASID;实际上两者是等价的。该地址转换模块就是将(StreamID + SubstreamID + VA)转换为PA,再发送至互联总线访问其余模块,该模块就是SMMU或IOMMU。
硬件系统结构模型如下,与MMU类似,SMMU也同样存在TLB,其作用是相同的,存在细节差异(注:若系统内不存在SMMU,那么设备无法直接使用VA,操作系统需要将VA转换为PA再发送至设备)。
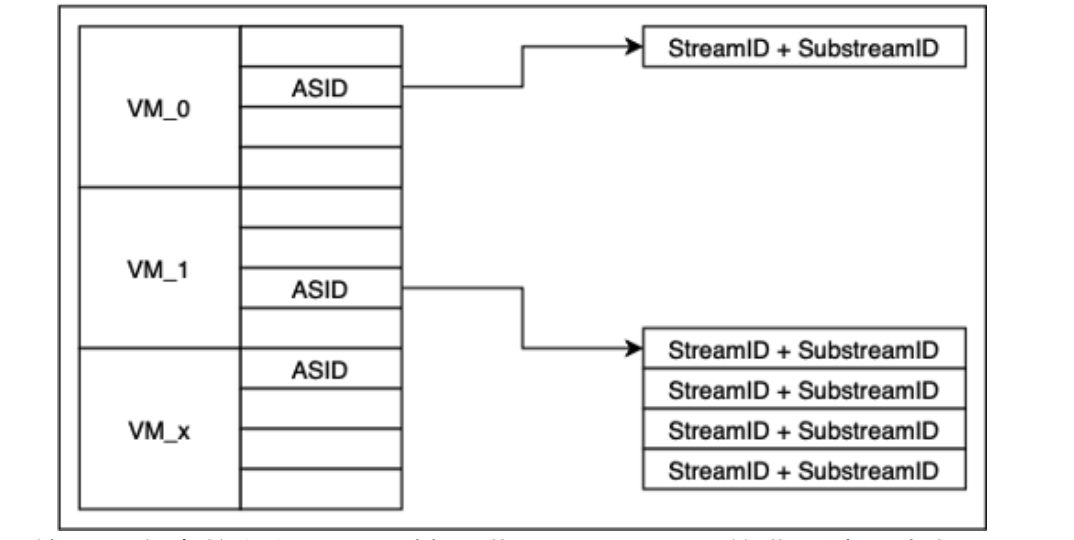
系统基本是以CPU为核心,Device属于被启动或被调用的模块,因此从逻辑来看,每个进程可以绑定一个或多个设备Substream,但每个设备Substream只能与一个进程绑定,其逻辑关系如下图所示。
综上,在虚拟化场景下,某个进程调用Device的典型流程有如下几个步骤。
-
进程,标记为VMID+ASID,申请Device资源,与StreamID+SubstreamID进行绑定,并获得该设备配置地址窗口的虚拟地址,同时在内存中记录进程与Device的映射关系;
-
该进程申请Memory空间,获得其进程内的虚拟地址,并将该地址通过设备配置窗口的虚拟地址下发至Device;
-
Device再基于该虚拟地址进行读写访问,SMMU将VA转换为PA发送至互联总线。
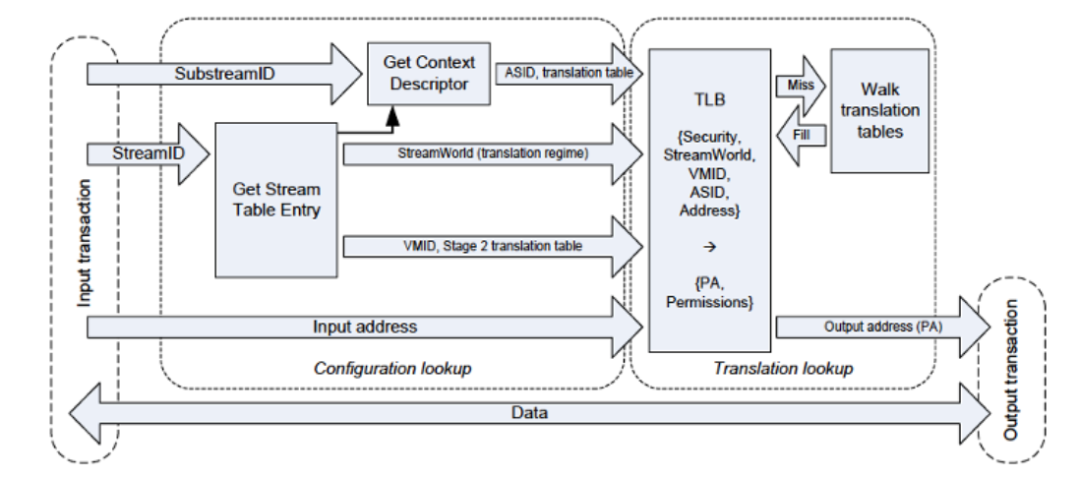
SMMU的地址转换流程就是上述的逆过程,Arm官方文档有相关描述,下图非常清晰的描述其先后关系。MMU与SMMU非常类似,同样存在两级地址转换,根据具体场景需求可分别进行Bypass,其差别是图中的Configuration lookup流程,将StreamID + SubstreamID转换为VMID + ASID。
前面的硬件系统结构模型中,Device包含了PCIe设备,如果把PCIe设备单独拿出来,其结构如下所示。
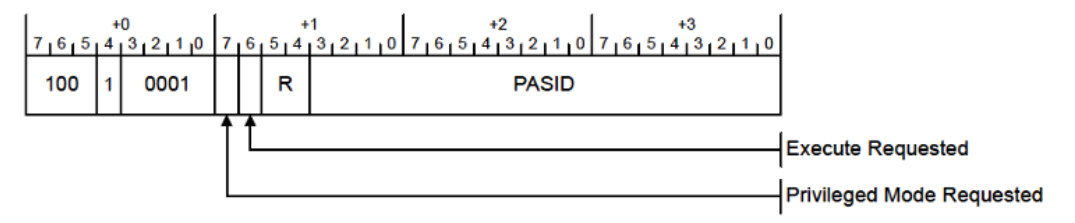
PCIe报文的RequesterID直接映射到StreamID,PASID映射到SubstreamID,接收到报文之后,先将(RequesterID,PASID)转换为(vmid,asid),Stage 1基于(vmid,asid)将VA转换为IPA,Stage 2基于vmid将IPA转换为PA,再发送至互联总线。PCIe PASID属于报文的Prefix,长度为1DW(32bit),需占用32bit的链路带宽,其格式如下所示。
实际上,当前绝大部分的PCIe设备是不支持PASID,也就是SMMU无需处理Stage 1的地址转换。因此,进程应用在将VA下发至PCIe设备时,需要虚拟机将该VA转换为IPA,再下发至PCIe设备,后续SMMU接收到报文后,仅处理Stage 2的地址转换。与上述类似,两级地址转换也会基于具体场景需求进行Bypass处理。
PCIe Endpoint通过SR-IOV支持设备虚拟化,使得一个PCIe物理设备可以映射为多个逻辑设备,可以被一个或多个操作系统和进程进行调用,如下图所示。
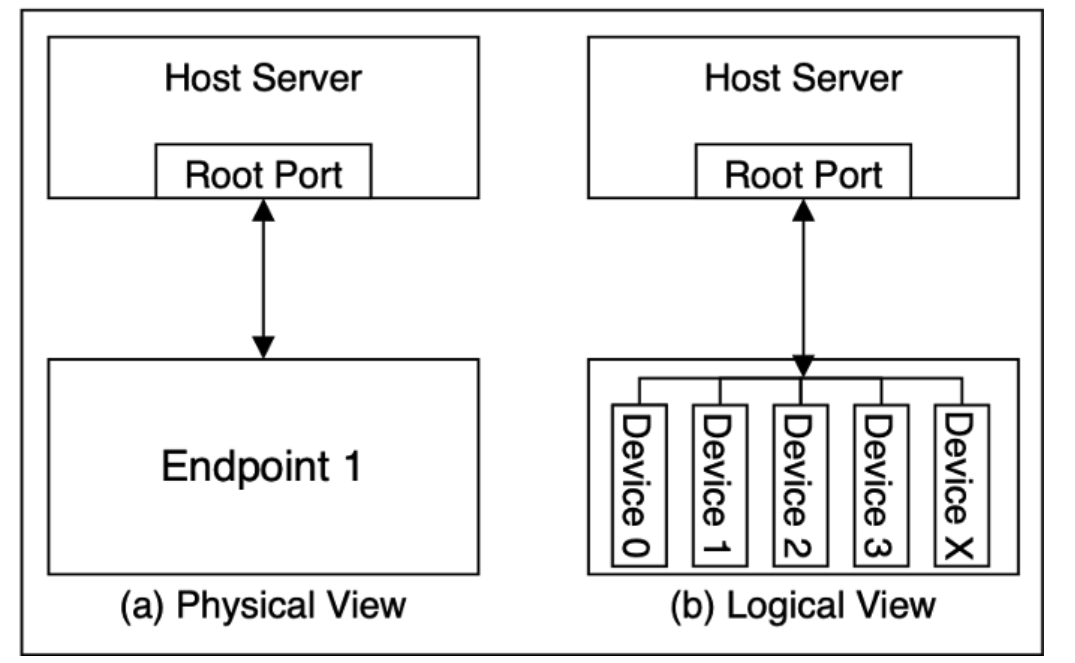
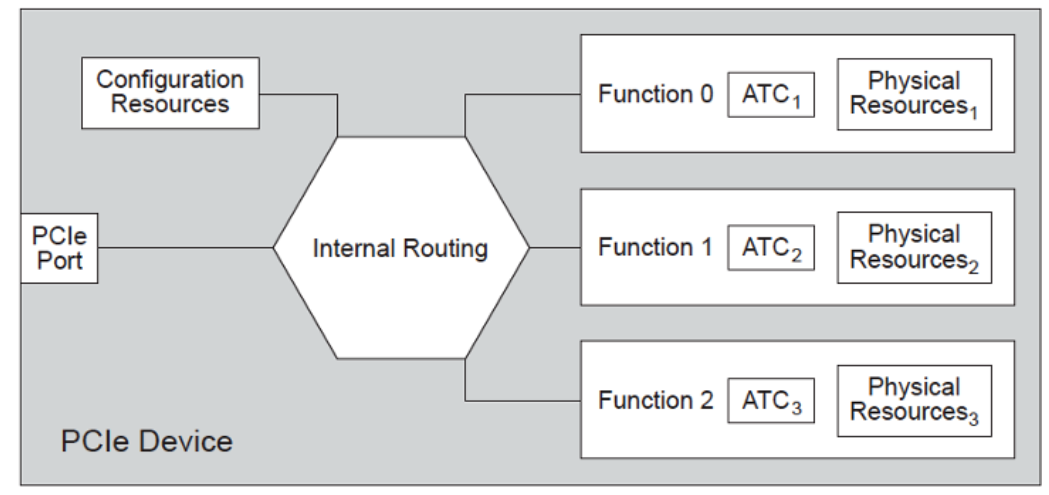
从软件视角来看,该设备呈现为多个Device,每个Device是互相独立的。在PCIe协议内,图中的Device称为Function,每个Function都分配一个独有的16bit ID,发出读写访问请求时使用该ID作为RequesterID。注意,每个Function之间是独立的,其在系统的Memory视角,每个Function均必须有其独立的配置空间,该物理设备可以共享,但其BAR空间的分配是无法被多个Function共享的。
Root Port接收到请求后,发送至SMMU做地址转换,再发送至互联总线。这一过程中,地址转换是需要时间的,也就是SMMU使能与Bypass相比,增加了地址转换的延时。如果对应页表不在TLB内,还需要到内存进行检索,非常影响性能。另外,如果连接了较多的设备,还会有大量的转换请求,而且这些设备还会发出大量的小粒度请求(512Byte),这些都会对SMMU和系统形成压力。
在具体实现中,使用了各种手段解决该问题,如将固定页表分配给Device使用。实际上,某些情况下,Device早已拿到访问请求的地址,只是处理任务未完成,还不能直接发出读写请求。
PCIe ATS就是用于解决该问题,将地址转换流程挪至Device侧,内部集成Address Translation Cache(ATC),ATS协议用于维护该ATC及其相关流程。PCIe Device在发出读写请求时,将VA转换为PA再进行发送,到Host侧则不再需要进行地址转换,直接发送至互联总线。
实际上,当前的PCIe设备都不支持ATS机制,主要还有较多的问题无法解决,如安全问题,Cache维护的问题,等等。
页表维护
所有页表均保存在Memory内,若没有TLB,所有查表请求均需要在Memory进行查找。虚拟机或进程申请Memory空间时,获取到其虚拟地址,同时在Memory内建立页表,也就是VA->PA的映射关系;释放Memory空间时,则对应为删除页表关系。
为加快地址转换流程,MMU/SMMU实现了TLB,缓存了部分页表。若接收到的请求在TLB命中,直接返回转换结果,否则需要在Memory进行查找。一般来说,系统会维护多级页表,每级页表之间使用指针进行索引,在Memory查找时需要多次访问才能拿到结果,这一过程也叫Page Table Walk。
既然有Cache,那么在删除页表关系时,同时也要将TLB Cache的页表关系也一并删除,否则会造成内存踩踏。SMMU协议内定义了大量的TLB invalidation命令,较为复杂,在之前参与的项目中,使用了大量的逻辑来处理这一命令。若在PCIe设备内实现了ATC,还需要同时Invalid该Cache缓存的页表关系。
页表属性
除了实现VA->PA转换外,页表还定义了各种属性和权限信息,如对应Memory空间的属性为Device、Cacheable等等,该虚拟机或进程是否允许使用该页表。
缺页异常
若虚拟地址的访问请求无法访问到正确的地址,将产生缺页异常,page fault。产生缺页异常的原因较多,其处理流程也有所区别。举个例子,若进程应用访问了非法地址,没有落在该进程的合法地址区间内,就会出现缺页异常。
相关设想
虚拟化技术是云计算的关键技术之一,且占据有非常重要的分量,虚拟化技术也成就了云计算。但是,无论软件还是硬件的虚拟化,实现都较为复杂,从硬件角度来看,需要大量的硬件资源,从软件角度来看,支持虚拟化之后,需要占用部分的硬件性能。我相信后续的云计算会往以数据为中心、Serverless等方向发展,基于函数提供服务,那么虚拟化技术是否可以做一些简化?甚至不使用虚拟化技术?

















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











