







弄懂Fast-lio2需要看的学习资料
感谢知乎Poao的文章,给我学习起到了很大帮助!
总览
雷达惯性里程计论文阅读笔记—FAST-LIO (一)
雷达惯性里程计论文阅读笔记—FAST-LIO2 (二)
卡尔曼滤波
FAST-LIO的状态估计过程与卡尔曼滤波过程是高度相似的!
卡尔曼滤波实际上是一种优化估计算法,不是我们通俗意义上理解的滤波。
假设我们拥有一个机器人,如何估算这个机器人在tk时刻的位姿?
我们有两种手段
1、通过机器人上一时刻t(k-1)的位姿来估计当前时刻的位姿
2、通过机器人上携带的传感器来测量当前时刻的位姿
得到的估计值和观测值是相互独立的,并且二者都符合高斯分布(正态分布)
但是如果我们只采用1,假设t(k-1)时刻的位姿不准确,那么这个估计就是错误的;如果只采用2,假设我们的传感器坏掉了, 那么这个估计也是错误的,卡尔曼滤波实际上就是融合了这两个估计,使得该时刻的估计更加准确。
因为二者都是独立的正态分布,所以这里的融合其实就是两个正态分布相乘,得到一个新的正态分布。
KD-Tree
在Fast-LIO2中采用了一种新的数据结构,iKD-Tree,这种数据结构是来自KD-Tree
为了搞清楚ikdtree是个什么东西,我们首先需要理解KD-Tree。
KD-Tree实际上是一种搜索算法,给定一空间中的一簇点集N,给定一个坐标点p,如何快速找到距离坐标点p最近的点n且n属于N?KD-Tree就是这样的算法。
主要步骤
1、空间划分
通过点集N中所有点的坐标,将整个空间划分成不同的区域,对一个树干下每次只划分两个树枝,划分依据为在同一坐标轴下所有点中中位数的那个点,分成两个区域后,再对每个区域下进行同样的划分。
2、找到最近邻点
首先根据点p的坐标,沿着根节点开始寻找,循着树枝依次找到最后,最后的点成为s。
3、回溯
因为只通过2找到的最近邻点不一定是真正的最近邻,需要回溯寻找,回溯的方式是“画圆”,然后看看有没有其他的划分线和这个圆相交,如果有的话,看看有没有点在圆内,如果有,这说明s不是距离p最近的在N上的点,假设在园内这个点为k,重复这个过程;否则这说明找到的点s就是点集N上距离p最近的点。
流形
流形-Manifold(1)
浅谈流形学习
对流形(Manifold)的最简单快速的理解
在loam系列的的论文中,毫无例外都提到了流形这一概念,所以必须要学习流形。
1、流形是什么?
流形取自文天祥取的“天地有正气,杂然赋流形”,英文Many Flods,意为许多褶皱。
首先我们要明确,流形是一个空间,不是形状,地球其实就可以看做是一个嵌入在三维空间中的二维流形。
2、流形的作用是什么?
(1)流形其实为了避免冗余的表示出现的。
比如地球是一个三维空间,我们为了表示三维空间中的一个点,会用直角坐标系或者球坐标系,但是对于地球上的某个地点,实际有用的坐标信息其实只有经度和纬度,比如我们要表示北京,只需要(东经116°20′;北纬39°56′)就可以在地球这个三维空间中定位北京的位置,但是如果采用直角坐标系,那么我们就需要(x,y,z)三个参量来确定北京的位置,可是我们采用经纬度只需要两个参量就可以确定北京的位置,经纬度其实就是一种流形的表示方法。
比较直观的一个例子就是球坐标系:
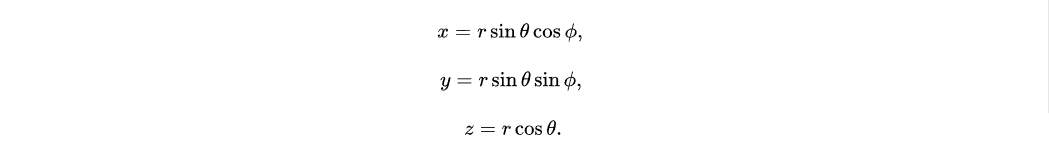
如上所示的球坐标系,针对地球的点,地球的半径是固定的r = r0,由此可以看到x,y,z三个参数就会完全被两个角度参数确定,从这里也可以直观地得到,地球球面上的点是一个二维流形在三维空间的嵌入。
(2)流形可以应用于机器学习中
流形有两种用法
- 将原来在欧氏空间中适用的算法加以改造,使得它工作在流形上,直接或间接地对流形的结构和性质加以利用
- 直接分析流形的结构,并试图将其映射到一个欧氏空间中,再在得到的结果上运用以前适用于欧氏空间的算法来进行学习
- losmap的应用
雅克比矩阵J
对雅可比矩阵的理解
首先膜拜写这篇文章的巨佬,写文章时作者竟然才高二,吾等是在是自愧不如~
该篇文章中:
- 不能再用一个常数矩阵来描述了
是指的从空间a到空间b的线性变换 f(·) 可以用一个常数矩阵来描述,但是如果这个变换是一个非线性变换 g(·),那么这个变换不能用常数矩阵来描述
- 每一个不同向量都有自己的矩阵变换,
其实意思就是在如果是线性变换的话,对任意一个向量a,在经过f(·)的变换后,映射到另外一个空间的向量b,这个映射可用一个常数矩阵来表示,但是如果是非线性映射g(·),每个向量对应的常数矩阵就是不一样的了,也就是每个不同向量都有自己的矩阵变换。
- 因为是“附近”,所以这个向量在邻域内张成的空间可以看作是线性变换的,所以可以用一个特定的矩阵来描述。
类似是求导那里,非线性函数在很短的一段deltax中是线性的,非线性线性化了
n是向量m经过线性变换之后得到向量,如果说我们在空间中的向量是
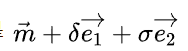
那么经过变换之后,得到的向量应该是n撇,又因为在m很小的邻域内进行的这个变换是一个线性变换,那么必然存在一个矩阵J使得
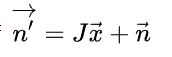
推导J的过程如下

李群与李代数
李群与李代数这一部分在高博的视觉slam十四讲里面讲解的很清楚,建议直接阅读高波的书,这里贴一个视觉slam十四讲李群李代数部分的知乎的分享笔记。
视觉SLAM-从零爬起打破秃头魔咒——(三)李群与李代数
先验分布、后验分布与似然函数
先验分布、后验分布、似然估计这几个概念是什么意思,它们之间的关系是什么?
如何理解似然函数?
1、先验分布
先验分布是指未知结果,根据经验直接确定原因的概率分布。
2、后验分布
后验分布是指已知结果,根据结果确定原因的概率分布
3、似然函数
似然函数与后验分布很像,都是已知结果,求解原因的概率分布,不同的在于似然函数认为原因是事件的一个固有属性,而后验认为原因只是一个概率。















 4152
4152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









