







《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
👍感谢小伙伴们点赞、关注!
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
引言
近年来,自注意力(self-sttention)和交叉注意力(cross-attention)已经成为计算机视觉领域的强大机制,在vison transformers(ViTs)和各种生成模型等模型的成功中发挥了关键作用。这些注意力机制使模型能够专注于输入图像的不同部分,改善机器感知和处理视觉信息的方式。在本文中,我们将探讨什么是自注意力和交叉注意力,它们是如何工作的,以及它们在计算机视觉中的具体应用。
深度学习中的注意力是什么?
在高层次上,注意力机制允许模型以不同的方式衡量不同输入数据的重要性。注意力不是平等对待所有输入,而是帮助模型专注于与手头任务更相关的特定区域或特征。这首先是在自然语言处理(NLP)中引入的,但后来被应用于计算机视觉任务,彻底改变了深度学习模型理解图像的方式。
自注意力:关注内部关系
自注意力是一种机制,模型计算单个输入(通常是计算机视觉中的图像)的所有部分之间的关系。术语“自我”指的是模型关注同一输入中的关系,允许它捕获局部和全局依赖关系。
自注意力是如何工作的?
在自注意力中,对于每个像素(或图像中的补丁),模型计算该像素与其他像素之间的“注意力得分”。这些分数帮助模型决定在对任何特定部分进行预测时对图像的不同部分给予多少关注。
这里有一个简化的过程:
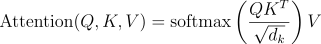
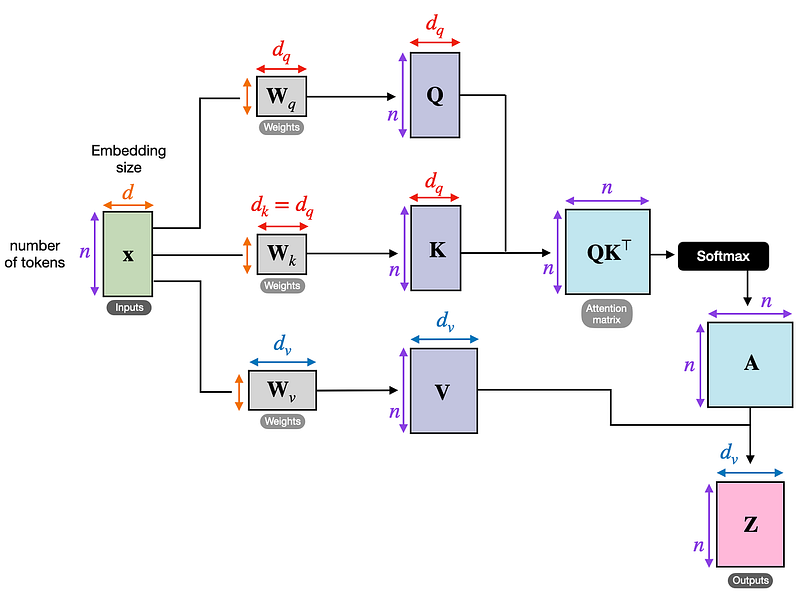
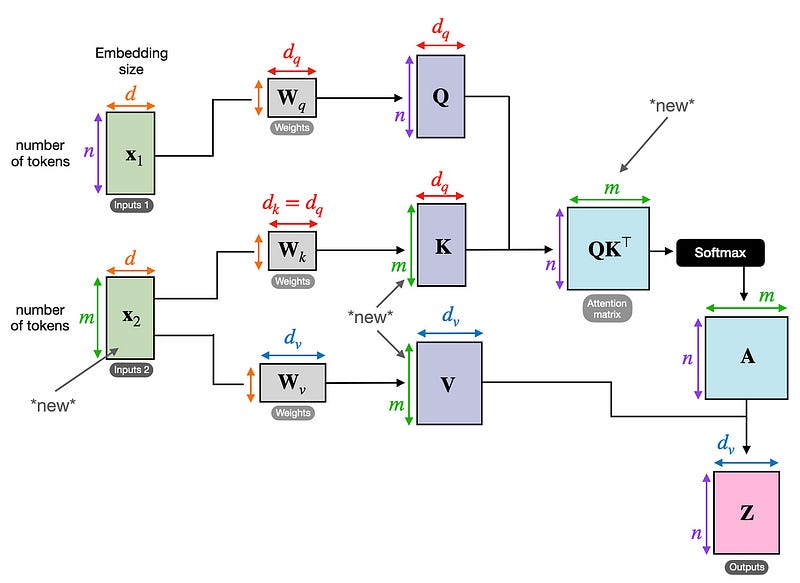
- Query、Key和Value:图像的每个部分都被投影到三个不同的向量中:Query(Q)、Key(K)和Value(V)。Query和Key用于计算注意力分数,而Value保存模型将向前传递的信息。
- 注意力分数计算:任何两个像素之间的注意力分数是通过取它们的Query和Key向量的点积来计算的,然后是一个softmax操作来规范化这些分数。
- 加权和:然后使用注意力分数来加权值向量。该模型输出每个像素的值向量的加权和,这使得它能够专注于图像中最相关的部分。
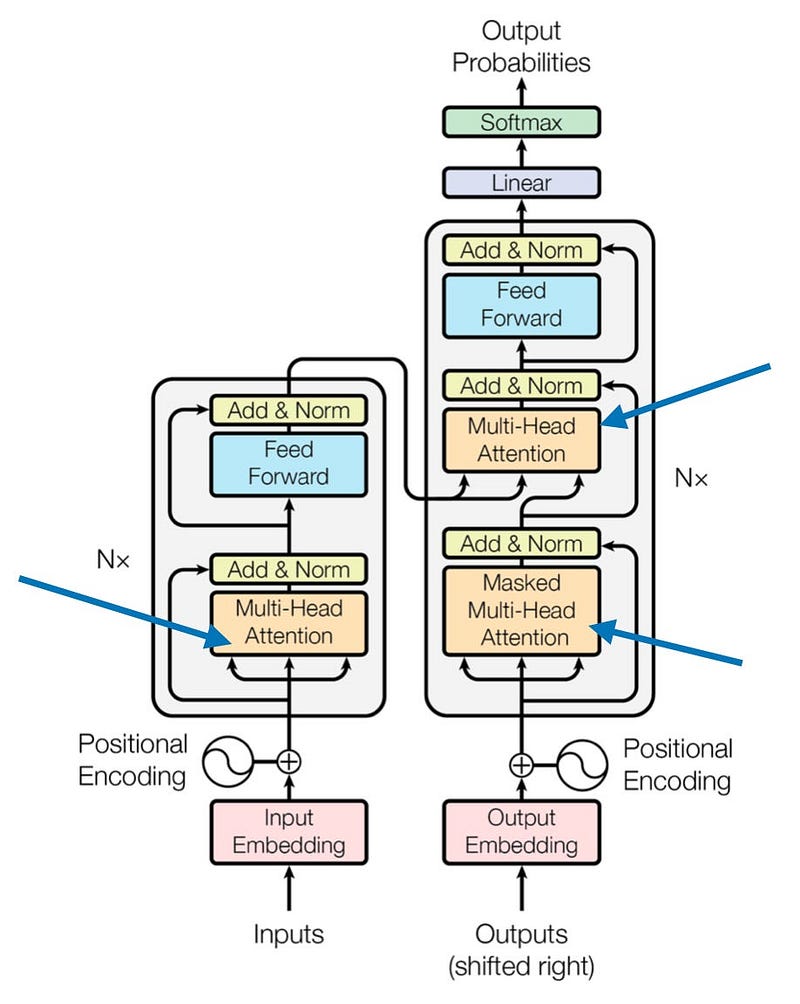
计算机视觉应用
自注意力是视觉转换器(ViTs)的核心,它将图像视为一系列补丁,而不是使用卷积。这种方法允许ViT捕获像素之间的长距离和短距离依赖关系,使其对于图像分类,对象检测和分割等任务非常有效。
交叉注意力:连接不同的模态
交叉注意力与自注意力的不同之处在于,它在两个不同的输入之间运行,而不是在一个输入内运行。在交叉注意力中,注意力机制允许模型基于来自另一个输入(例如文本提示或不同的图像)的信息来关注一个输入(例如图像)的相关部分。
交叉注意力是如何工作的?
与自我注意力类似,交叉注意力也使用Query、Key和Value向量,但这些向量来自两个不同的来源:
- 查询来自一个输入(例如,文本)。
- 键和值来自第二输入(例如,图像)。
然后,交叉注意力机制计算来自一个模态的查询和来自另一个模态的键之间的注意力分数。这允许模型关注一个输入中与另一个输入最相关的部分,从而弥合不同数据类型之间的差距。
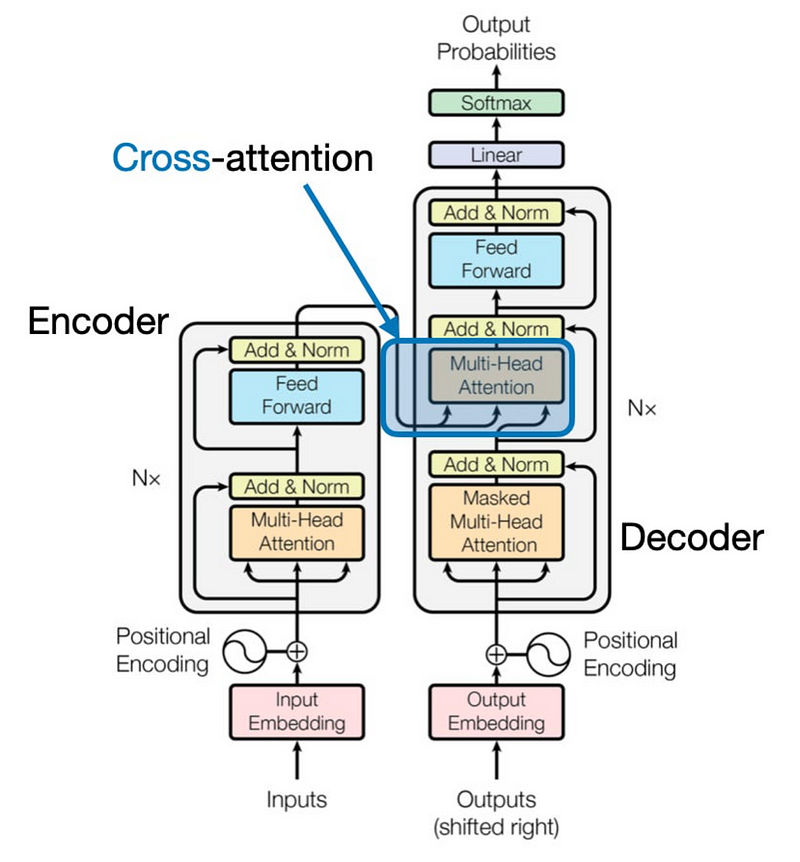
计算机视觉应用
交叉注意是多模态模型的基本组成部分,其中模型必须处理多种类型的输入。例如,在文本到图像生成(例如,DALL·E和稳定扩散),交叉注意力使模型能够将文本描述与相关视觉特征对齐。通过允许文本引导模型关注图像的特定区域,交叉注意确保生成的图像与文本提示准确匹配。
另一个令人兴奋的应用是图像引导的图像合成或视频生成,其中图像或一组图像可以引导新图像或帧的合成。在这里,交叉注意力帮助模型混合来自不同来源的信息,确保输出的一致性。
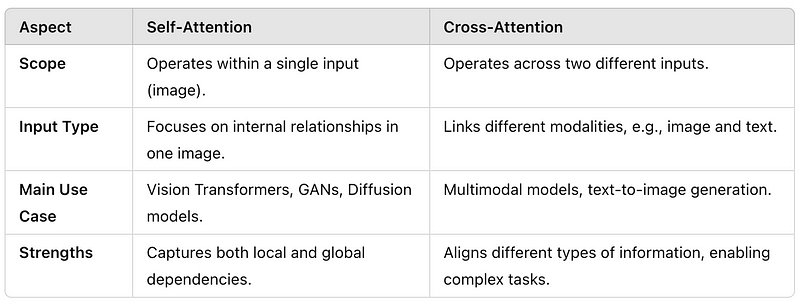
自注意力与交叉注意力主要区别
虽然自注意力和交叉注意力在现代计算机视觉模型中起着关键作用,但它们的区别在于它们所捕捉的关系的性质:
为什么注意力在计算机视觉中很重要
注意力机制,无论是自注意力还是交叉注意力,都提供了灵活性和可扩展性,使模型能够更有效地处理复杂的视觉任务。随着计算机视觉的不断发展,基于注意力的模型有望在广泛的应用中扩大其影响力,从自动驾驶汽车和医学成像到生成令人惊叹的视觉内容的创意工具。
自我注意力和交叉注意力都为模型提供了更智能地“看”世界的能力。自我注意使他们能够专注于图像中的重要细节,而交叉注意使他们能够联合收割机从多种模态中获得见解,从而对视觉信息产生更深入、更细致的理解。
结论
自注意力和交叉注意力是重新定义计算机视觉领域的变革机制。它们使机器能够更有效地理解视觉数据,无论是通过关注图像内的关系,还是将图像与文本等其他形式联系起来。随着注意力机制的不断成熟,它们在推动基于视觉的应用程序创新方面的潜力是无限的,使其成为人工智能未来的重要工具。


好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











