






点击下方“ReadingPapers”卡片,每天获取顶刊论文解读
论文信息

摘要
视觉变换器在高光谱图像(HSI)分类中得到了广泛应用,其核心特征提取器是自注意力。自注意力比卷积具有更广的感受野。然而,现有的视觉变换器在对具有大量波段的HSIs进行分类时,通常存在高计算复杂性和大量的参数需求。在本文中,我们提出了一种超轻量级特征压缩多头自注意力学习网络(UFMS-LN),主要包括一种新颖的压缩特征多头自注意力(CF-MHSA)、空间特征增强增强变换降低(SFE-ETR)和空间-光谱混合化-接收场注意力卷积操作(SH-RFAConv)。通过在空间-光谱维度有效地压缩特征图,CF-MHSA实现了与最先进的自注意力机制相同的特征提取能力,其浮点运算(FLOPs)和参数比最先进的自注意力机制低两个数量级。SH-RFAConv旨在强调局部特征,具有同时提取空间-光谱特征的能力,并且比传统卷积操作具有更广的感受野。此外,SFE-ETR是UFMS-LN的预处理模块,它结合了全局空间特征增强方法和增强变换降低(ETR)。在四个基准HSI数据集上进行的广泛实验表明,该方法比现有的最先进的HSI分类网络取得了更优越的结果。
关键词
注意力
深度学习
高光谱图像(HSI)分类
遥感
提出的方法
A. 整体框架

所提出的UFMS-LN模型由两层单分支结构组成,特征图维度逐层减少(如图1所示)。在此框架中,SFE-ETR作为预处理模块,CF-MHSA作为提取全局特征的核心操作员,SH-RFAConv作为提取局部特征的模块。具体来说,I ∈ RH×W×D表示原始HSI数据,其中H×W表示HSI块的空间尺寸,D表示光谱带数。预处理后的HSI表示为X ∈ RH×W×C,其中C(C ≪ D)是预处理后的光谱带数。X作为输入特征图通过网络进行处理,通过SH-RFAConv模块、CF-MHSA模块L1、包括线性化层和激活函数高斯误差线性单元(GELU)的全连接层,以及CF-MHSA模块L2。当然,值得注意的是,全连接层用于降低特征图的维度,而L1和L2用于处理不同维度的特征图。
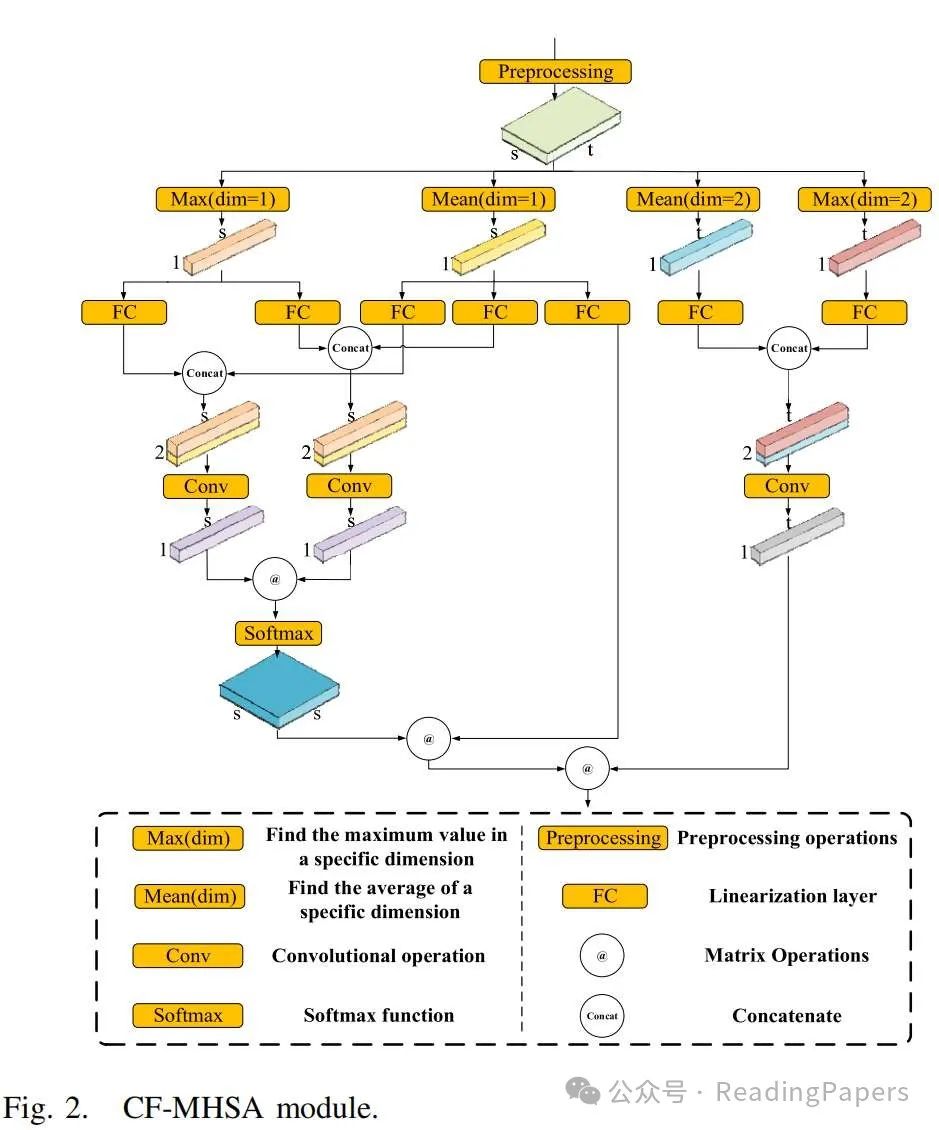
B. CF-MHSA
传统变换器中的自注意力可以通过压缩输入特征数据的空间维度来获得2-D输入矩阵X ∈ Rs×d。其中s和d分别代表X的维度,s = H × W,d代表特征图的光谱维度。以展平的特征图X ∈ Rs×d作为输入,多头自注意力(MHSA)块用M个头表示为
这里, 和 是投影矩阵, 表示softmax函数。n 表示头的数量, 是每个头的维度, 表示第n个头的嵌入输出。 分别表示查询、键和值嵌入。Concat{·} 表示沿指定维度连接。MHSA 应用于全局上下文可能导致高计算成本,因为每个位置都需要考虑其与所有其他位置的关系。为了缓解这个问题,所提出的 CF-MHSA 通过在不同维度压缩特征图大大减少了计算的复杂性和参数的数量,如图 2 所示。给定输入数据 ,它可以被视为 ,其中 。在第一步中,计算第i个向量的最大值 、最小值 和均值 。然后,将每个向量的最大值和最小值替换为 如下:
这里,、 和 分别表示获取最大值、最小值和均值的函数。在执行上述操作后,获得矩阵 并使用以下方式归一化 :
上述步骤的目的是替换输入数据中的任何异常大或小的值。这样做是为了防止这些异常值影响后续步骤中特征向量的提取。通过将这些异常值替换为更具代表性的值,可以确保更健壮和可靠的特征提取。此外,特征图中的所有值均为非负数,以供后续任务使用。接下来,我们沿光谱维度将 分割成 n 部分,其中 n 是注意力头的数量,,,。对于每个 ,分别计算光谱和空间维度的最大值和均值如下:
向量 、、、 分别表示每个头在不同维度中的最大值和均值。这里, 表示空间维度, 表示光谱维度。计算这些向量的目的是为了通过在后续步骤中用它们替换相应的矩阵来进行特征压缩。随后,将向量 和 分组,并且每组分别映射,将它们投影到新空间如下:
这里, 表示矩阵乘法。 和 是将 、 映射到不同新空间的投影标量。注意我们使用 标量而不是 或 矩阵进行映射,以减少计算复杂性。此外,通过映射 1-D 向量,计算复杂性降低到 和 ,取代了原始自注意力机制中的 。
接下来,我们通过连接可以代表原始矩阵特定维度的向量,然后使用卷积操作进行压缩来实现 和 。具体计算如下:
其中 表示卷积操作,核大小为 ;Concat{·} 表示沿指定维度连接,得到大小为 和 的特征图; 和 分别代表计算出的 和 的值。为了提高 CF-MHSA 的鲁棒性并防止特征提取能力的下降[40],我们选择 和 通过处理获得 和 ,而不是参数量更小的 和 。值得注意的是, 不被压缩的目的是保留原始特征矩阵的更多特征。随后,使用 和 计算注意力分数。由于 和 都是一维特征压缩向量,获得注意力分数的计算复杂性仅为
softmax 函数,表示为 ,用于获取注意力分数。最后,提出了一种新的压缩特征向量的操作顺序如下:
其中 是输出特征图。与 相比,计算复杂性为 ,我们提出的方法的计算复杂性为 。在大多数情况下, 比 小得多。
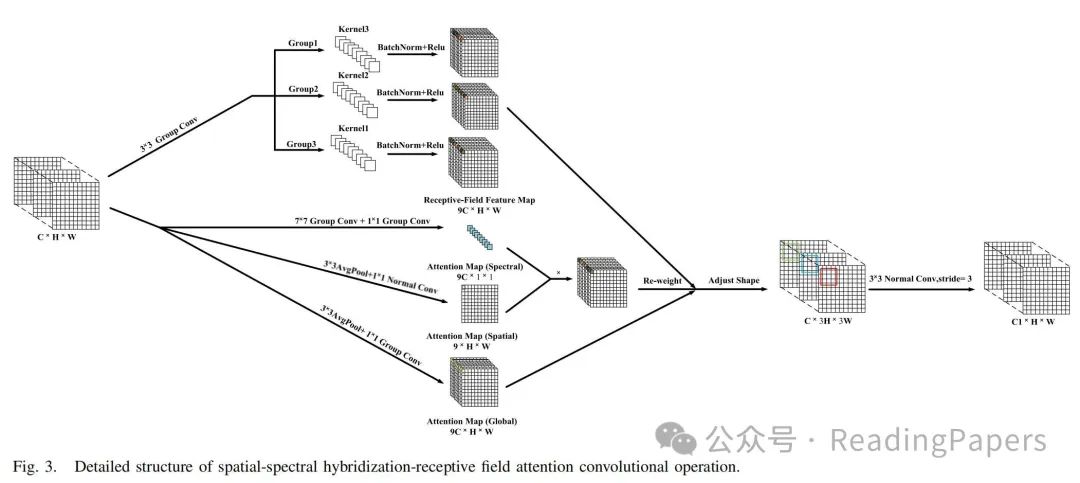
C. SH-RFAConv
为了增强 UFMS-LN 模型的空间-光谱特征提取能力,受接收场注意力卷积操作(RFAConv)[41] 的启发,我们设计了一个专门针对 HSI 特征的结构,称为 SH-RFAConv,如图 3 所示。它通过结合空间-光谱注意力具有更强的空间-光谱特征提取能力。在 SH-RFAConv 中,使用了一种称为 Group Convolution 的快速方法来提取接收场的特征,该方法通过分组卷积操作有效地减少了所需参数的数量,使 SH-RFAConv 成为一种轻量级方法,用于捕获交互信息。Group Convolution 中的组数设置为初始输入特征图中的带数。对于 SH-RFAConv,利用交互接收场特征信息来学习注意力图可以增强网络性能。SH-RFAConv 可以分为两部分:接收场特征图特征提取和特征注意力图获取。设 表示输入特征图,B 表示批次大小,C 表示输入带数,H 和 W 分别是特征图的高度和宽度。一方面,我们使用 Group Convolution 与核大小为 并将组数设置为 C 来提取特征图特征,如下所示。
这里, 表示核大小为 且输出光谱大小为 的分组卷积。 表示获得的接收场特征图, 表示归一化, 表示ReLU激活函数。另一方面,接收场的特征注意力图通过以下方式获得
其中, 表示平均池化操作,卷积核大小为 ,输出维度为 C。 表示核大小为 且输出光谱大小为 的常规卷积。使用常规卷积的原因是输入和输出维度要求更加灵活,不受组数的限制。 表示特征注意力图。在操作 中,从左到右依次获得的是光谱维度的注意力图 ,空间维度的注意力图 ,和全局注意力图 。通过 (11),我们可以发现 和 分别通过对 X 进行类似的通道注意力[42]和空间注意力处理获得,为 SH-RFAConv 提供了空间-光谱注意力。在 和 操作后并加到 上,通过 Softmax 函数获得特征注意力图。值得注意的是,在设计 和 特征图融合的过程中,我们通过实验发现乘法融合方法效果更好,因此我们选择使用乘法方法。F 通过将注意力图 与特征图 相加获得。值得注意的是,通过 SH-RFAConv 获得的特征图 F ,在被“重塑”后不会重叠,使得学到的注意力图能够聚合特征图中的所有特征信息。重塑后的特征图 F 需要经过一个步长为 3 的 卷积操作,以实现不重叠的特征提取。具体操作如下:
其中 是输出特征图, 是输出的光谱维度。SH-RFAConv 可以有效地捕获由空间变化引起的信息差异,通过强调接收场内不同特征的重要性来实现。
D. SFE-ETR
ETR[43]是一种新的预处理方法,它通过将主要特征信息转移到另一个子空间来降低输入数据的维度,增强变换并使数据更平滑。然而,ETR 缺乏提取空间特征的能力,面临降维后显著丢失空间特征的挑战。因此,我们通过结合具有总结能力的空间信息方法,有效地提取空间特征,命名为 SFE-ETR。SFE-ETR 结构是一个双分支处理结构,分别扮演降维、分布增强和空间特征增强的角色。ETR 可以分为两个步骤:降维和增强变换。在第一步中,我们采用主要输入数据集 ,其中 b 代表像素数量,q 代表带数。协方差矩阵根据每个变量的均值计算距离值,从而增强输入特征之间的变化,如下式所示:
其中 是 X 的均值; 是增强协方差矩阵,; 是属于范围 的微小值。它们是根据像素之间的相关性从皮尔逊相关系数计算出来的。简单来说,如果相关系数高, 的值就大,反之亦然。linalgeig 是指线性特征分解,用于计算特征矩阵 。接下来,我们从 中取出前 k 维的向量权重矩阵 。最后,通过将 W 与 X 相乘,获得映射到新子空间的最终新子空间维度,提取主要输入数据集的特征。值得注意的是,k 通常小于 q 以实现降维,如下所示:
其中 是 X 被映射到新子空间的数据。下一步是增强变换。这部分产生形态学重建方法(MRM)的输出。MRM 主要由形态学膨胀和侵蚀重建组成,本研究采用形态学膨胀方法。形态学膨胀操作(MDO)依赖于两个图像(数据集),掩码(S)和标记(R)图像,它们必须具有相同的大小。前一部分的输出作为掩码图像。这部分的主要挑战在于获取标记图像。此外,在 MDO 中,标记图像的值必须小于或等于掩码图像的值,即 。设 为第二部分的初级输入数据,其中 b 代表实例数量,k 代表特征(带)数量。本研究通过使用该部分中每个实例的平均值或最大值来增强类别内的变化。因此,在创建 R 图像之前存在两种状态:
其中 R 是创建的标记图像, 是用于缩放 R 图像中值的常数值。由于选择了 MDO,需要 。计算 S 中每一列的平均值,得到 。然后,我们重复向量 M k 次,将一维向量 (M) 转换为二维矩阵 R 。获得标记图像后,使用 MDO 获得传输图像的过程定义如下:
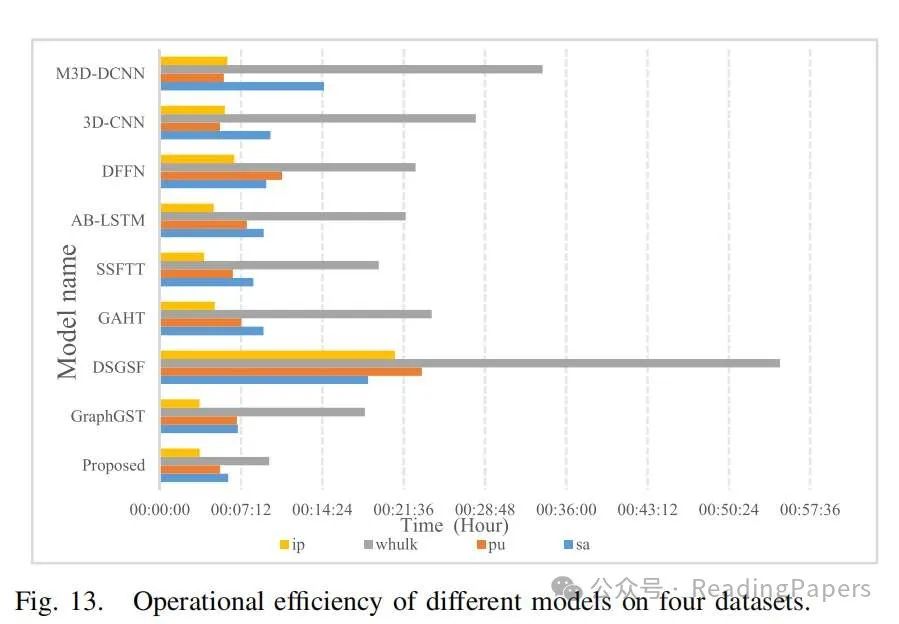
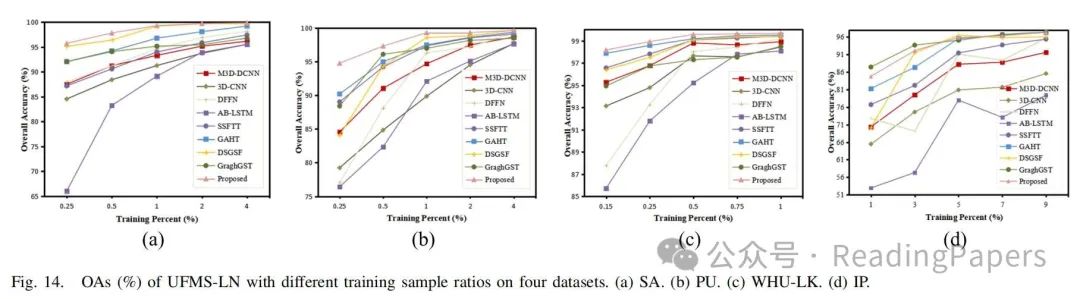
III. 实验
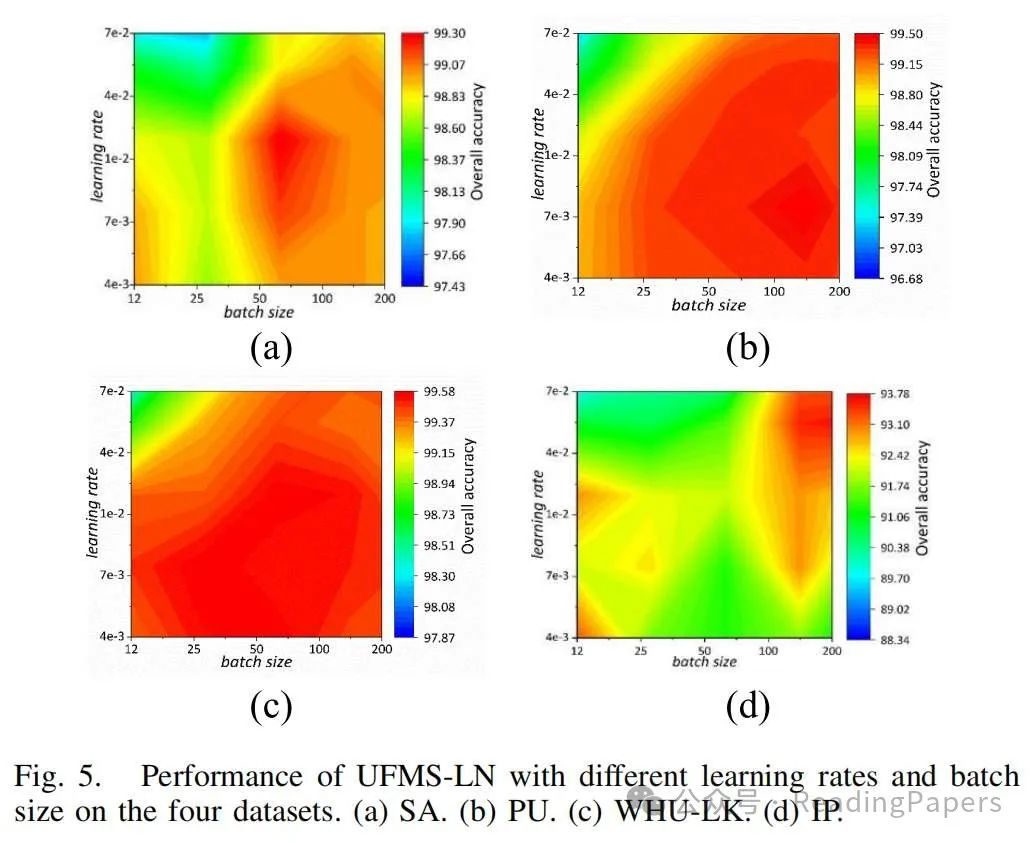
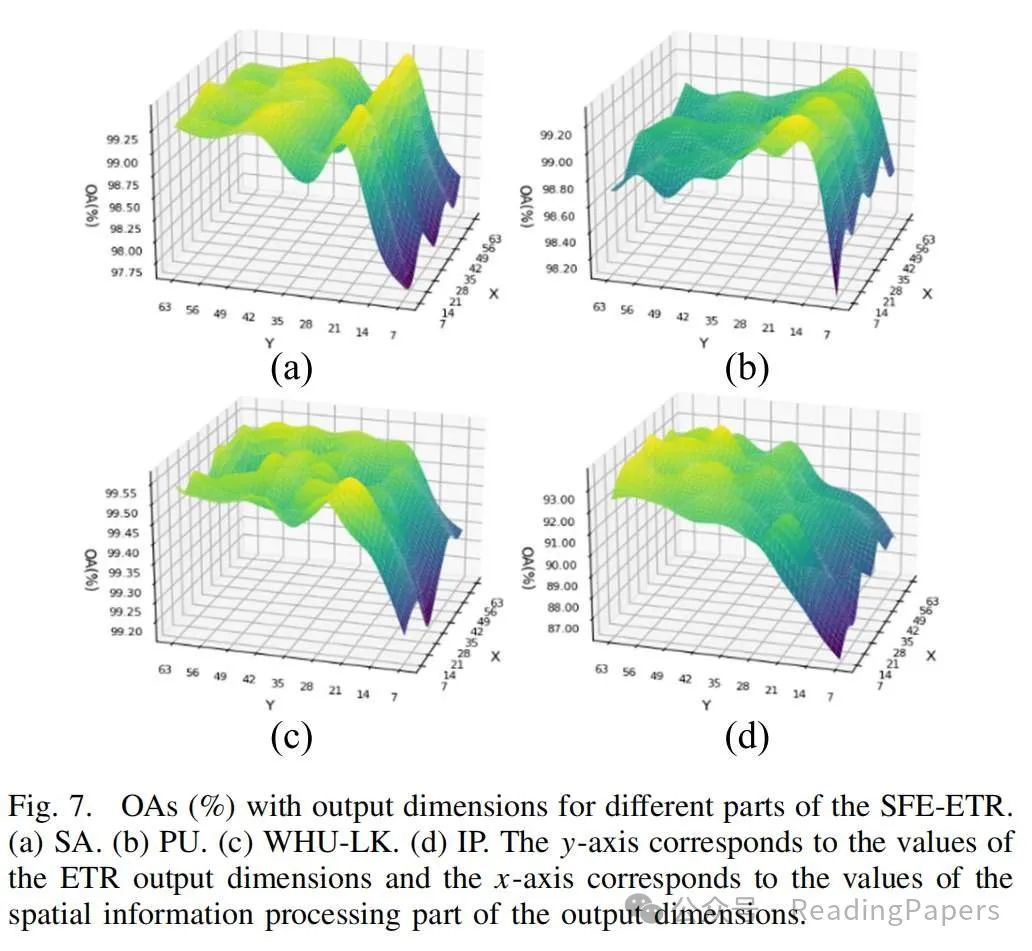
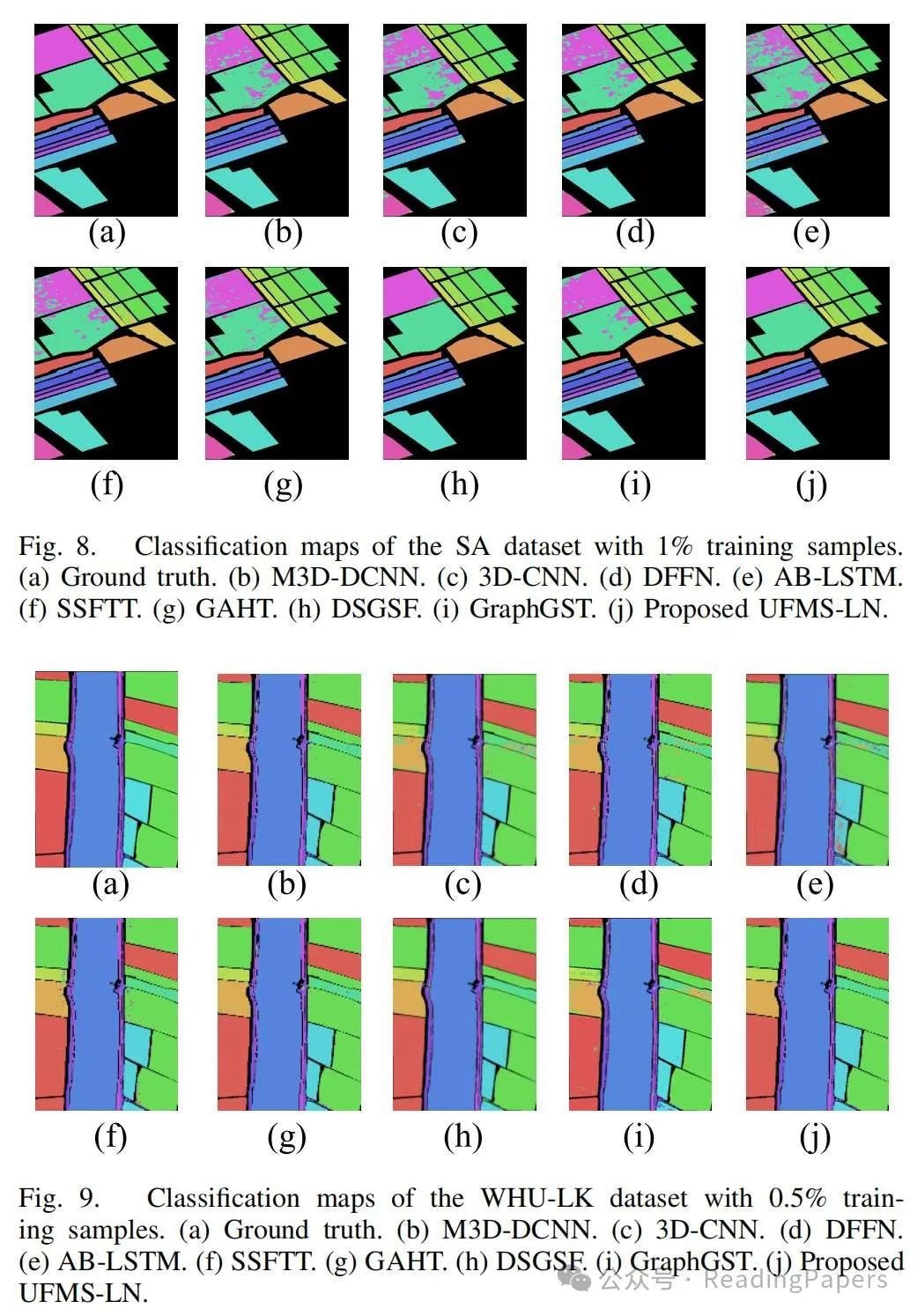

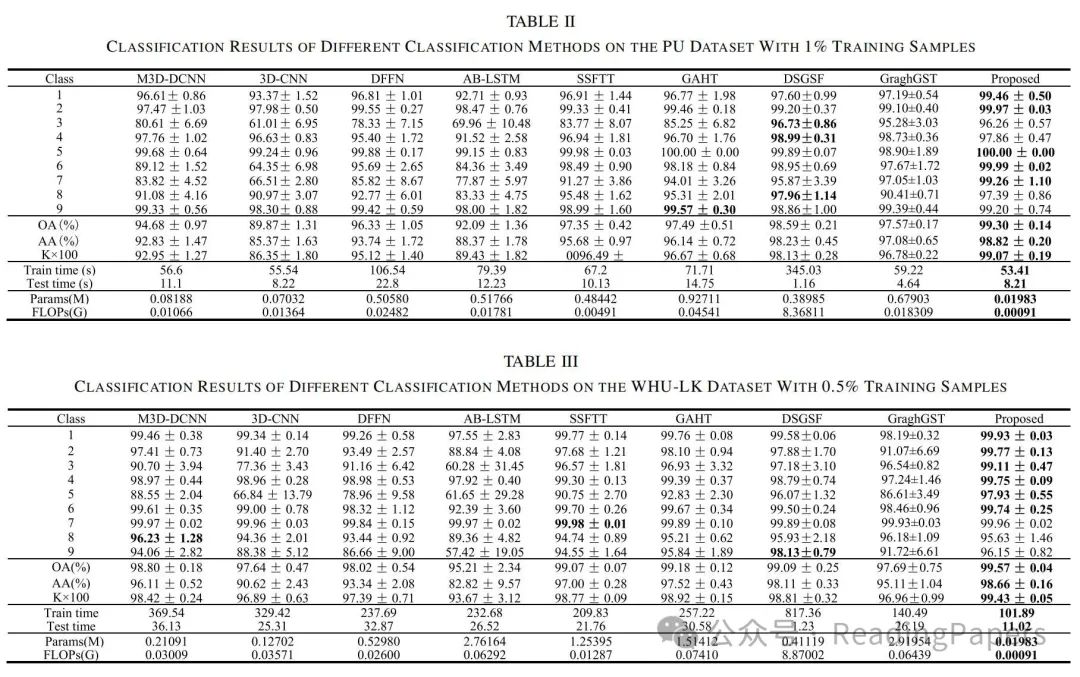
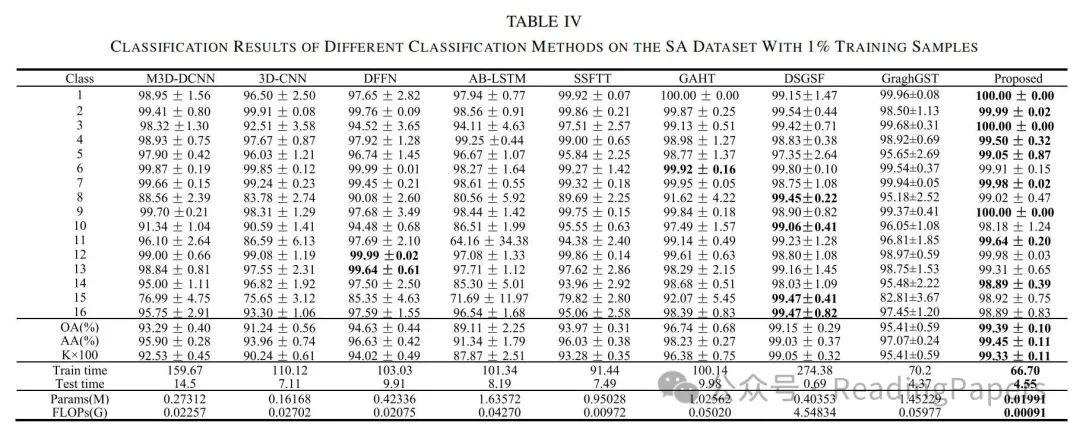

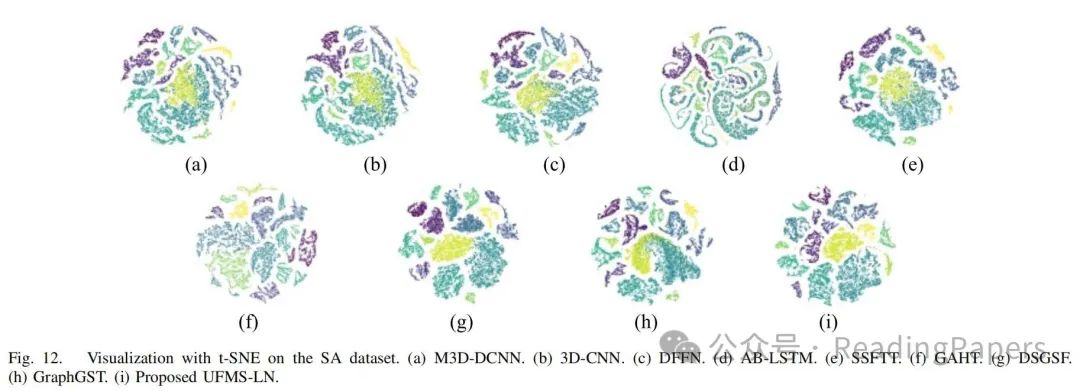
声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与我们联系,我们将在第一时间回复并处理。
















 1766
1766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









