






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
题目:Efficient Frequency-Domain Image Deraining with Contrastive Regularization
高效频域图像去雨与对比正则化
作者:Ning Gao, Xingyu Jiang, Xiuhui Zhang, and Yue Deng
源码:https://github.com/deng-ai-lab/FADformer
论文创新点
提出了一种高效的频率感知去雨框架(FADformer):作者提出了一个名为FADformer的新型框架,该框架通过在频域中捕获特征来实现高效的雨迹去除,这与仅依赖于空间域特征的方法相比,提供了一种新的视角和解决方案。
构建了融合傅里叶卷积混合器(FFCM):FADformer框架中的关键组件之一,FFCM,能够在空间和频域中进行卷积操作,这使得它在保持效率的同时具备了局部-全局特征捕获的能力,与自注意力机制相比,具有更高的计算效率。
引入了先验门控前馈网络(PGFN):PGFN通过引入残差通道先验(RCP)信息,以门控方式增强了局部细节和结构特征的恢复能力,这种结合先验知识的方法在去雨任务中显示出了其有效性。
开发了频域对比正则化(FCR):作者开发了一种新的频域对比正则化方法,该方法利用频域特征作为对比空间,有效地利用了负样本信息,并显著提高了去雨性能,这一方法在多个数据集和任务中都显示出了其普遍的有效性。
摘要
大多数当前的单图像去雨(SID)方法都是基于Transformer,通过全局建模实现高质量的重建。然而,它们的架构仅从空间域构建长距离特征,这在保持有效性的同时带来了显著的计算负担。此外,这些方法要么在训练中忽视了负样本信息,要么未能充分利用负样本中存在的雨迹模式。为了解决这些问题,作者提出了一种频率感知去雨变换框架(FADformer),它完全捕获频域特征以实现高效的雨迹去除。具体来说,作者构建了FADBlock,包括融合傅里叶卷积混合器(FFCM)和先验门控前馈网络(PGFN)。与自注意力机制不同,FFCM在空间和频域中进行卷积操作,使其具有局部-全局捕获能力和效率。同时,PGFN以门控方式引入残差通道先验以增强局部细节并保留特征结构。此外,作者在训练期间引入了频域对比正则化(FCR)。FCR促进了频域中的对比学习,并利用负样本中的雨迹模式来提高性能。广泛的实验表明了作者的FADformer的效率和有效性。
关键词
SID · 频率学习 · 对比正则化
3 方法
3.1 概述
我们的目标是两个:(1)建立一个既高效又擅长全局-局部建模的去雨网络,(2)创建一个利用负样本增强去雨性能的对比正则化。提出的频率感知去雨(FAD)框架的工作流程如图3所示。为了实现第一个目标,我们构建了一个名为FADformer的层次变换器类网络,它考虑了频域信息和先验知识。对于第二个目标,我们开发了一个使用频域作为对比空间的对比正则化项。
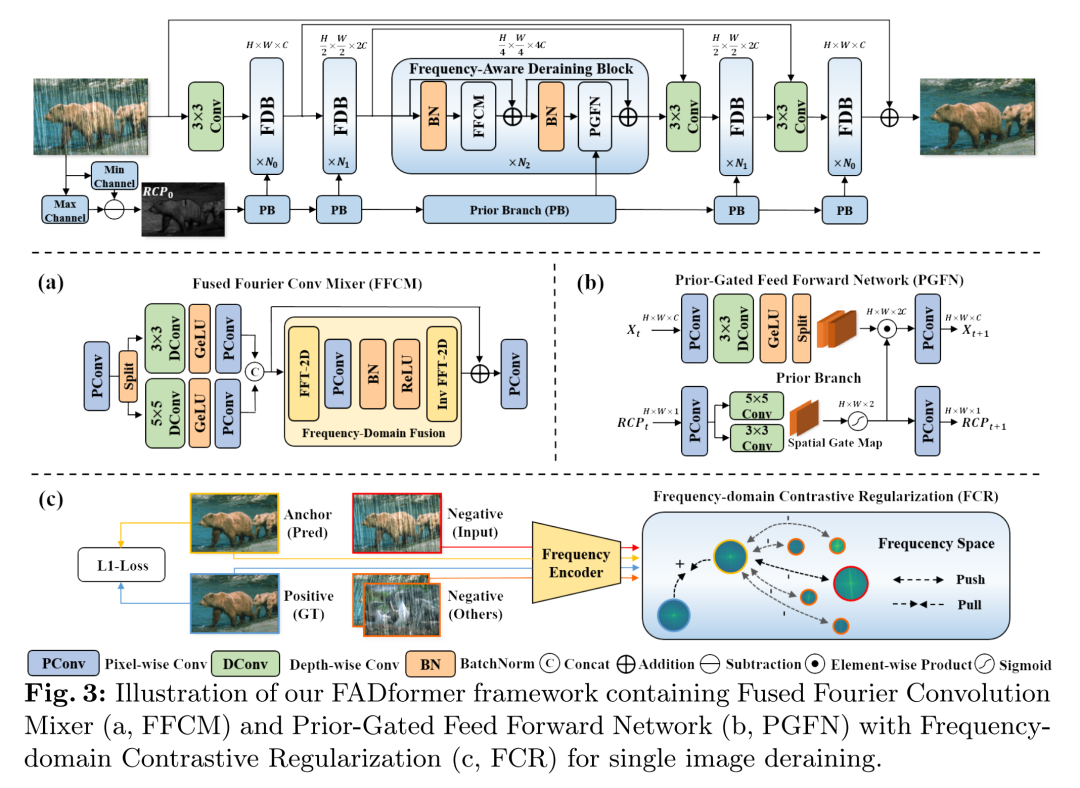
3.2 主干管道
给定一个雨天图像 ,我们首先使用卷积提取浅层特征 ,同时通过残差通道先验(RCP)计算结构先验图 。随后,我们将特征 通过一个三阶段的编码器-解码器网络进行深度特征提取。每个阶段由不同数量的FADBlocks堆叠而成,具有不同的空间分辨率域和通道维度,以提取多尺度特征。在每个FADBlock中,与自注意力机制不同,我们采用FFCM进行全局建模,仅涉及卷积和傅里叶变换操作。然后,PGFN被用来进一步丰富特征,以增强局部细节和纹理结构,由 指导,其中 是从轻量级先验分支(PB)编码浅层先验图 获得的。特征的下采样和上采样涉及像素重组和像素洗牌操作[39]。跳跃连接[38]被用来融合来自同一阶段的编码器和解码器特征,然后通过逐点卷积进行通道压缩[12]。最后,一个 卷积将特征转换到图像空间,产生残差图像 。最终重建结果是通过 获得的,其中 表示FADformer的输出。
3.3 频率感知去雨块
FADBlock遵循变换器块[7]的范式,通过令牌混合器实现长距离特征感知,然后通过前馈网络(FFN)增强局部特征。不同之处在于,在全局特征处理阶段,FADBlock利用FFCM通过提取频域特征来实现空间域特征的全局建模,这比自注意力机制更高效。对于局部特征处理,根据去雨任务的先验知识,我们引入了PGFN,利用RCP先验作为门控特征,以协助增强FFN的结构恢复能力。数学上,给定特征 作为第 个FADBlock的输入,程序表示为:
其中 表示BatchNorm; 和 分别表示FFCM和PGFN的输出。此外, 表示RCP的特征图,其中 是通过雨天图像 计算的。融合傅里叶卷积混合器(FFCM)。回顾离散傅里叶变换(DFT),给定一个特征图 ,DFT可以形式化为如下:
其中 基于傅里叶空间作为复数分量; 和 是傅里叶空间的坐标。如图2和方程(3)所示,傅里叶变换为图像去雨提供了两个优势。首先,它具有分离图像退化组件的能力,其中雨迹模式在频域中持有显著且不变的特征。其次,变换后的频率分量是从所有空间分量计算的,自然充当全局特征提取器。
因此,提出的FFCM有效地利用这两个优势。它具有与自注意力机制相似的全局感受野,但仅具有卷积的计算成本。FFCM架构,如图3.a所示,采用空间-频率concatenation设计来处理不同的雨迹特征,并实现局部-全局特征融合。在空间域操作中,该方法最初使用点卷积来提升输入特征 并将其分成两组以提取多尺度局部特征,最终获得 。形式化为如下:
其中 表示空间域中不同核大小的 和 深度卷积[8]。 是点卷积, 是GeLU激活。在频域操作中, 经历DFT转换为实部和虚部分量。这些连接的分量经过 核大小的卷积操作。调制后,实部和虚部分量被分割,逆DFT 将频域特征转换回空间域:
最后,通过残差结构和PWConv获得FFCM的输出:
FFCM在设计和应用上与其他最近的频域方法不同:1)与FFTformer[20]不同,后者结合了卷积定理和自注意力进行高效的全局建模,我们引入了可学习的参数直接在频谱中提取特征;2)与Fourmer[56]不同,后者只关注频域,我们使用了空间-频率concatenation结构进行混合特征提取,以改善复杂场景中的去雨。先验门控前馈网络(PGFN)。先前的工作通常使用基于深度特征的标准FFN进行局部特征提取,忽视了任务特定去雨先验的潜在指导。实际上,这些先验可以被整合到深度网络中,并已证明其有效性。在这里,我们首次提出了先验门控前馈网络(PGFN),以门控方式将先验知识整合到FFN中,以改善局部细节和结构恢复。具体来说,我们引入了残差通道先验[22,51],它通过计算雨天图像的最大和最小通道分量之间的方差来有效保留清晰结构(如图3中的灰度图所示),无需学习参数:
如图3.a所示,PGFN展示了两个并行分支。主分支遵循DConv前馈网络[24](DFN)的结构。给定特征 ,我们首先通过PConv扩展通道维度,然后使用DConv细化局部细节。同时,先验分支引入扩展的RCP特征作为组间门控权重。这一增加显著加强并重建了被雨迹干扰的背景信息:
X_t^f = PConv(\sigma \cdot DConv(PConv(X_{t-1}^2)) \odot X_{t-1}^2^{RCP}) \quad (10)
其中 是Hadamard积,X_{t-1}^2^{RCP} 是门控图。先验分支被引入以在方程(10)中提供扩展的RCP特征。首先,RCP特征通过PConv处理以提取高维特征。然后,应用不同核大小的组卷积以生成组间门控权重,这些权重被DFN使用。认识到直接将原始RCP特征应用于深层时的潜在干扰[51],我们采用了迭代编码方法。这种方法逐渐减少门控图的通道维度,并将其作为RCP特征输出到下一个PGFN块,促进其深层表示:
X_{t-1}^2^{RCP} = Sigmoid(Convgroup(PConv(X_{t-1}^{RCP}))) \quad (11)
X_t^{RCP} = \sigma \cdot PConv(X_{t-1}^2^{RCP}) \quad (12)
其中 表示不同核大小的组卷积。
3.4 频率对比正则化
损失函数[2,4,18]如L1/L2距离和SSIM损失在当前SID中被广泛使用。然而,它们仅测量输出与正样本之间的距离,忽视了使用负样本作为下限的信息。受对比学习启发,目前监督SID中有一些对比感知学习(CPL)方法[13, 55]。它们使用VGG[40]构建对比空间特征以提高去雨性能,但仍存在问题:语义信息主要依赖于清晰图像,缺乏对不同雨迹模式的区分识别,限制了CPL在去雨中的有效性。为了解决这个问题,我们提出了频域对比正则化(FCR),通过将DFT与对比学习相结合,如图3.c所示。具体来说,FCR使用真实图像作为正样本,雨天图像作为负样本,同时使用FADformer的输出作为锚点。利用雨迹模式在频域中的显著特征,我们使用DFT进行特征提取,而不是很少考虑雨迹特征的网络如VGG。这种方法捕获了图像的频域信息,并在频域空间测量L1距离。值得注意的是,我们使用与随机选择的其他雨天图像配对的雨天图像来形成一个负样本组,这提供了多种雨迹模式的信息。为了使锚点更接近正样本同时推开负样本,我们通过测量锚点与正/负样本之间的L1距离并计算它们的比率来构建FCR,如下所示:
其中 是真实图像, 是负样本的数量。频域中的对比正则化提供了两个优势:(1)正样本与负样本之间以及不同负样本之间的差异在频域中显著不同。这种差异性有利于对比学习。(2)DFT可以通过快速傅里叶变换(FFT)[9]加速,几乎不影响训练速度。最后,我们将总体损失函数制定如下:
其中 表示L1损失, 设置为0.1以平衡损失项。
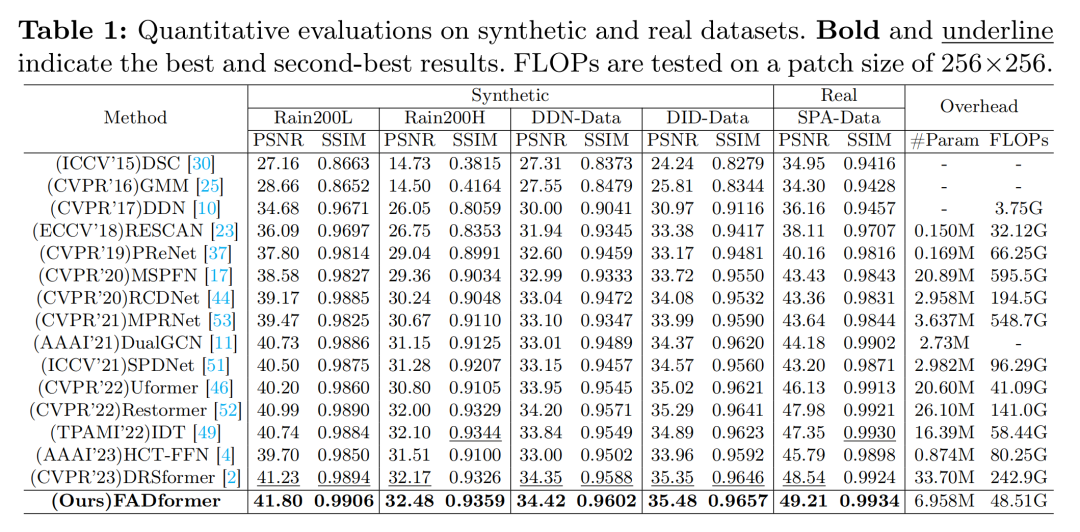
4 实验和讨论


声明
本文内容为论文学习收获分享,受限于知识能力,本文对原文的理解可能存在偏差,最终内容以原论文为准。本文信息旨在传播和学术交流,其内容由作者负责,不代表本号观点。文中作品文字、图片等如涉及内容、版权和其他问题,请及时与作者联系,作者将在第一时间回复并处理。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









