






点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
Stable Diffusion 都用过吧?
大名鼎鼎的 ControlNet,可以控制图片生成的插件,应该也不陌生?
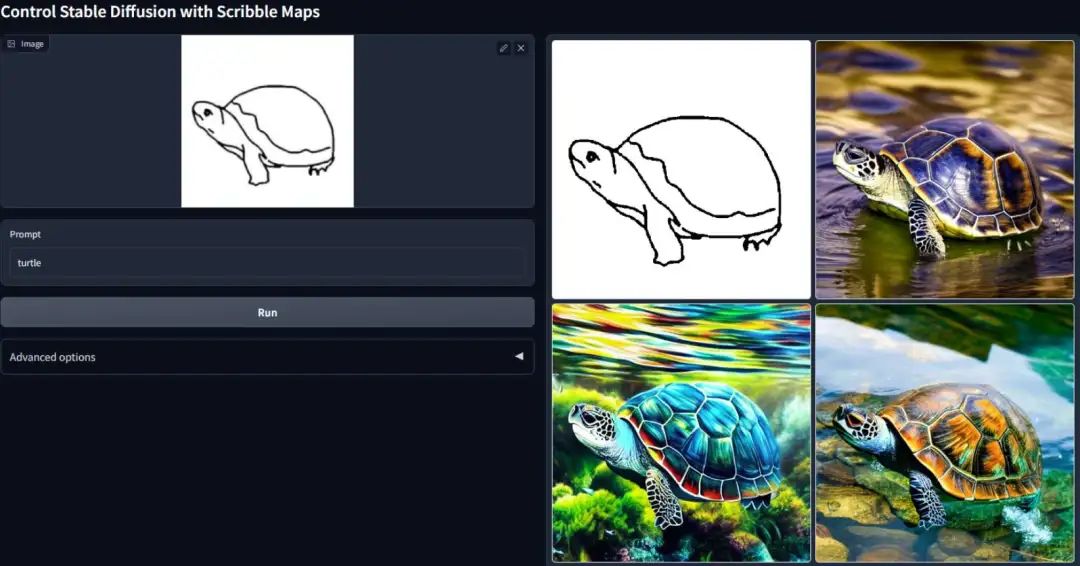
而它的作者 lllyasviel,现在又开源了一个 AI 视频生成算法 FramePack。
可以根据图片,生成对应的视频,这是动起来的水母:
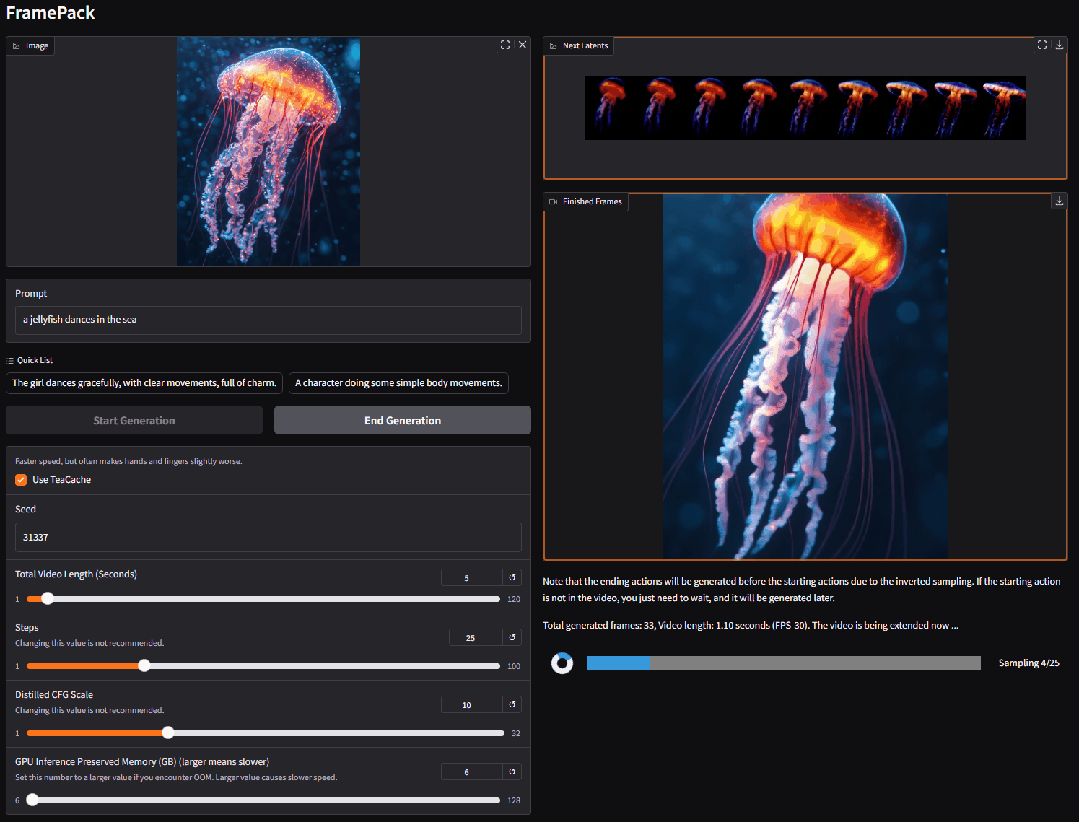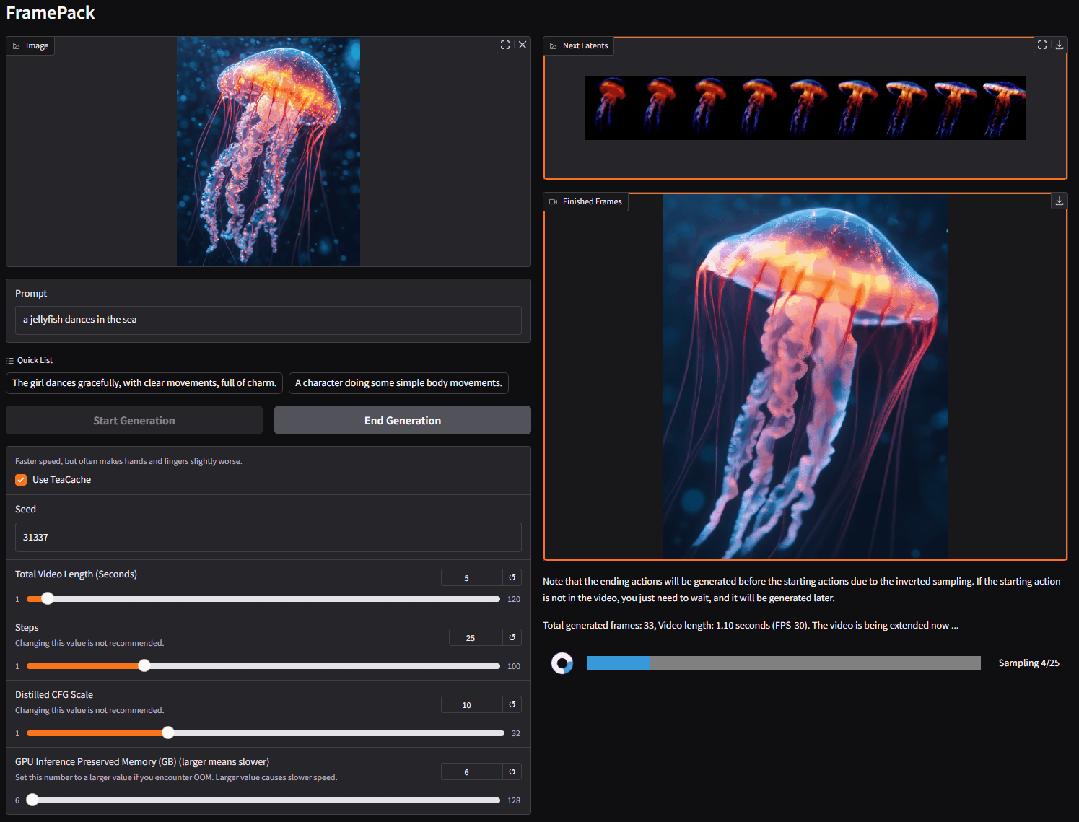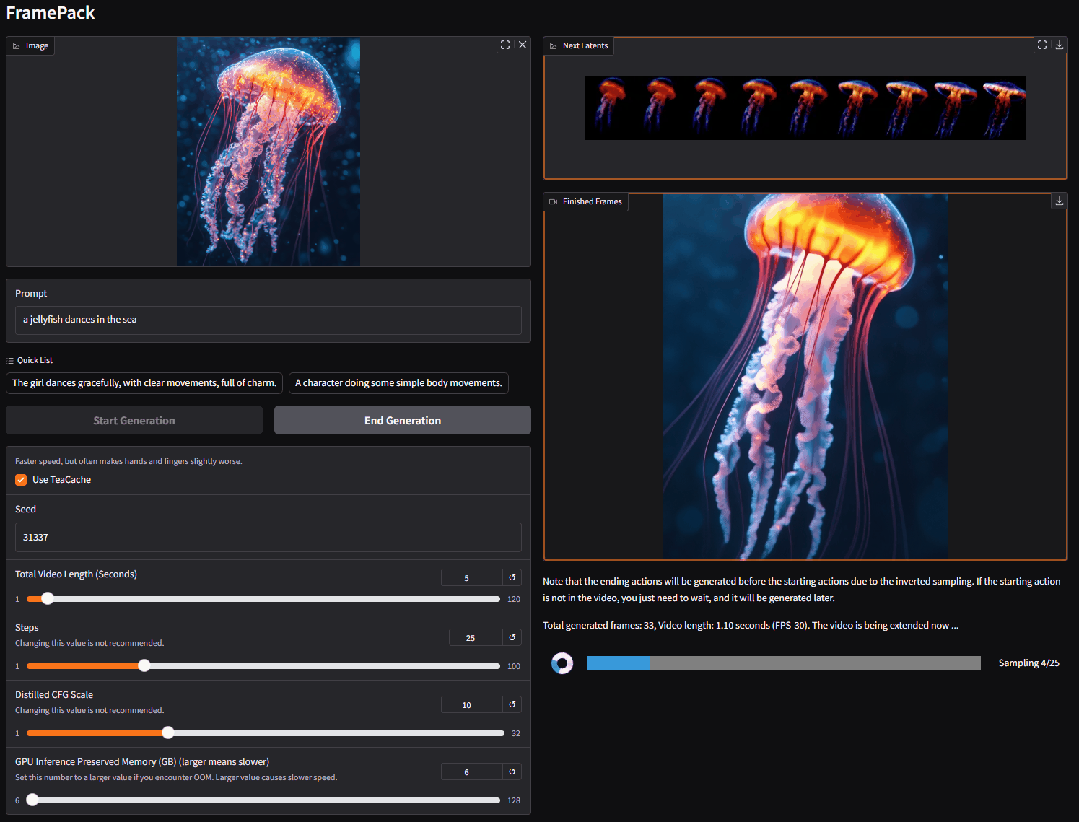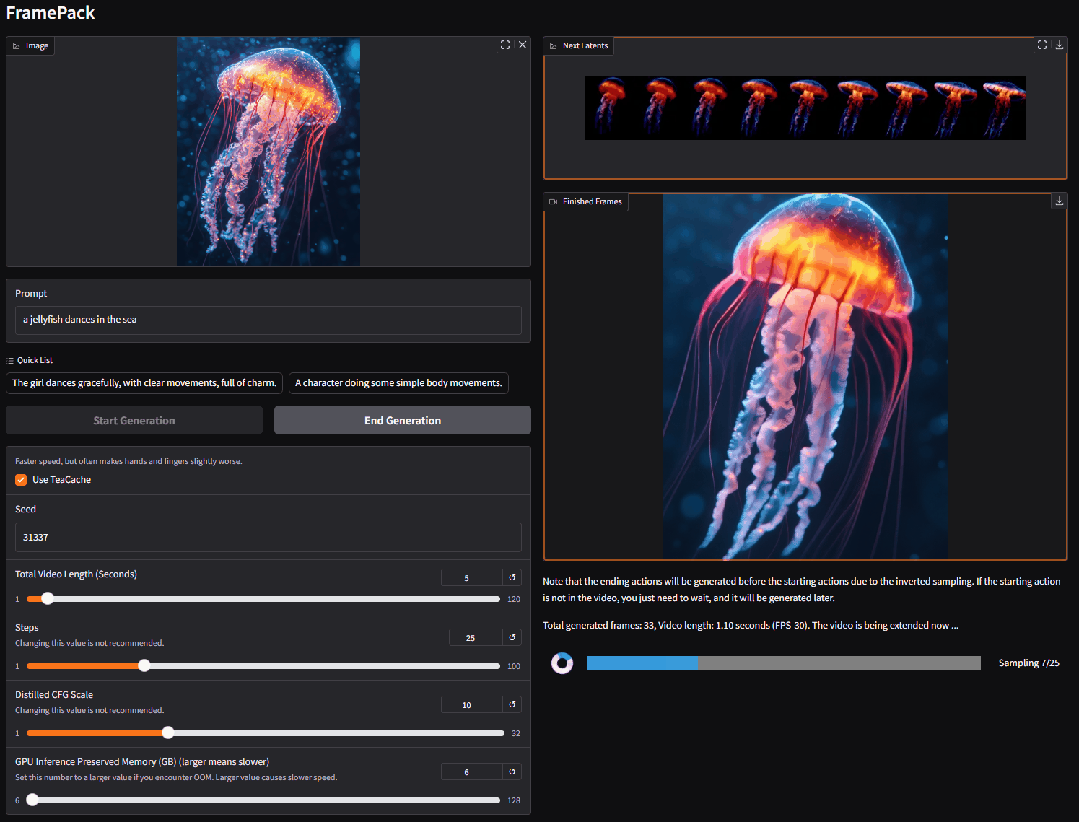
上传一张图片,然后设定提示词:
The girl dances gracefully, with clear movements, full of charm.
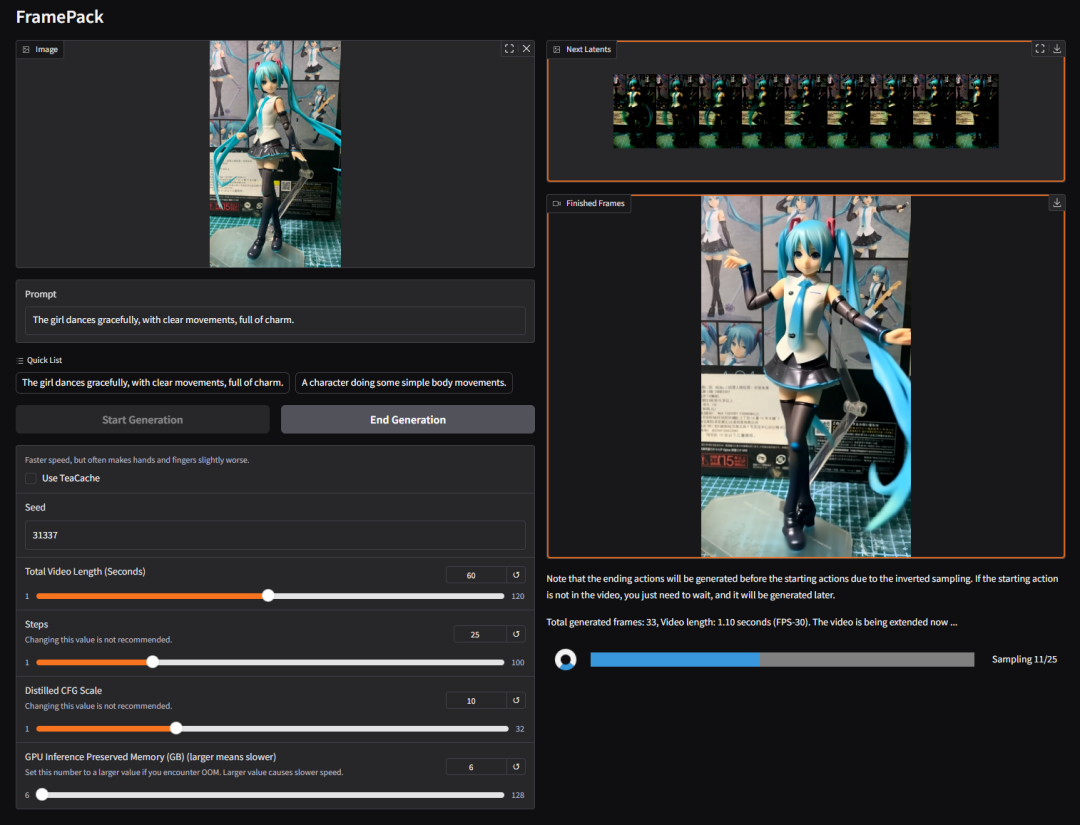
就能得到这样的视频:
我们再一起看下 FramePack 生成 AI 视频的其它效果:
5秒长的古画视频
2分钟长的赛博朋克2077宇宙
1分钟长的花样舞蹈
猜猜要生成上面的视频需要使用多少算力?
过去,答案往往是需要多张A100一起工作。
而现在,使用新发布的 FramePack,只需要一个带有 6GB GPU 内存的 RTX 3060 笔记本,就可以在本地流畅地生成。

FramePack一经发布,在外网上也是收获了一波好评。
接下来,让我们一起了解一下 FramePack 究竟是如何做到的。
项目地址:
https://lllyasviel.github.io/frame_pack_gitpage/
代码地址:
https://github.com/lllyasviel/FramePack
FramePack的原理及核心优势
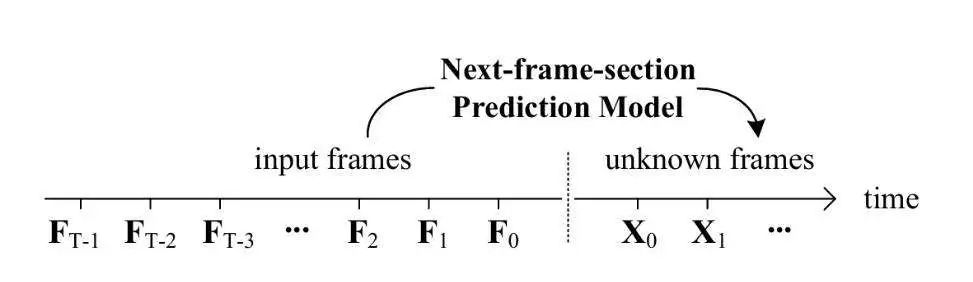
FramePack 是由斯坦福大学的 Lvmin Zhang 和 Maneesh Agrawala 联合发布的一种 next-frame(next-frame-section)预测神经网络结构,可以逐步生成视频。
顺便提一嘴,Lvmin Zhang 就是大名鼎鼎的ControlNet 的作者张吕敏。
FramePack 将输入上下文压缩为恒定长度,并且根据帧的重要性实现不同的压缩模式。

这样的操作显著降低了对 GPU 显存的要求,从而实现了与图片扩散模型相似的计算消耗。
为了缓解“漂移”现象,FramePack 提出了三种反漂移采样方法。
btw 漂移是指在下一帧预测模型中出现的视觉质量会随着视频长度的增加而下降的问题。
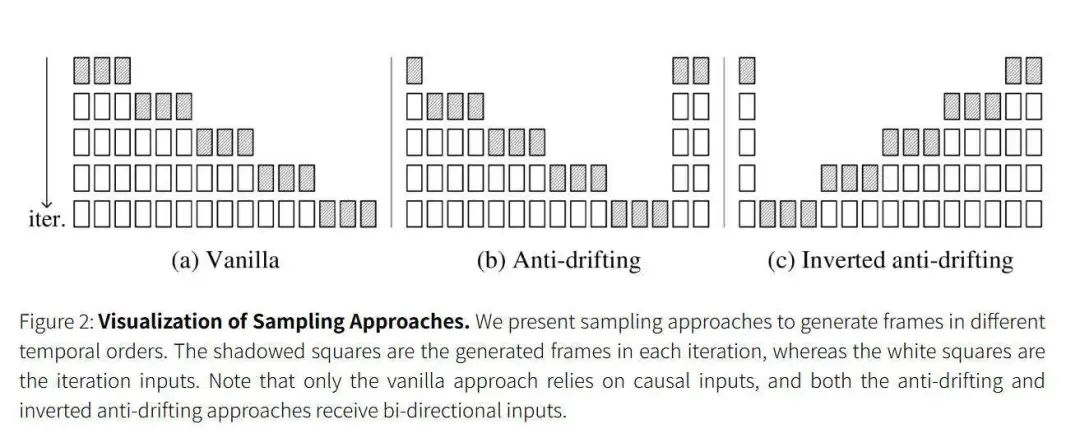
实验发现第三种采样方法可以将用户的输入视为高质量的第一帧,并不断优化生成以接近用户帧,从而可以获得整体高质量的视频。
这就意味着在不显著牺牲品质的情况下,FramePack 可以生成更长时间的视频。
并且用户能够即时查看每一帧生成后的画面,方便进行预览和调整。
所以如果你要生成一段120s 长的视频,在看到画面觉得不满意就可以停止重试,而不需要等到整个视频完成后,节约了用户时间。
接着,我们一起看看 FramePack 最突出的性能优势。
极小的硬件需求:可以仅仅使用笔记本电脑 6GB GPU 内存,驱动 13B 模型以 30 FPS 生成上千帧视频。目前已经测试的显卡系列包括 Nvidia GPU 中的 RTX 30XX、40XX、50XX 系列,支持 fp16 和 bf16。可在Windows及Linux操作系统上使用。
微调高速:在单个 8xA100/H100 节点上以 64 的批量大小微调 100B 视频模型,用于个人/实验室实验。
生成速度快:个人版 RTX 4090 的生成速度为2.5秒/帧,使用 teacache 优化后可以达到1.5秒/帧。
FramePack 的安装和使用非常便捷。
快速安装与使用FramePack
Windows 系统用户直接点击下面的链接,会自动开始下载。
https://github.com/lllyasviel/FramePack/releases
下载后,对文件进行解压缩。
先运行 update.bat 进行更新,然后使用 run.bat 运行。
对于 Linux 系统用户,建议使用独立的 Python 3.10。
安装使用的命令如下:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126pip install -r requirements.txt然后使用下面的命令启动GUI:
python demo_gradio.py安装好后就可以亲自上手试试。
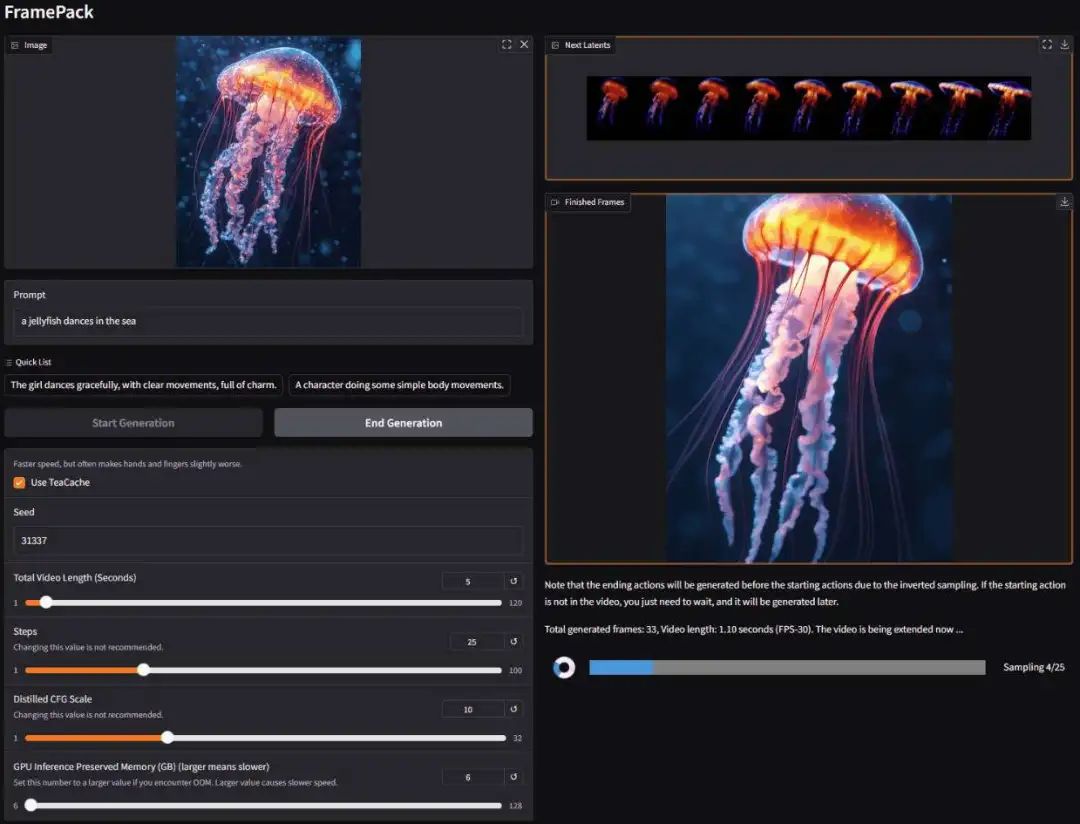
GUI 左侧用来上传图像和输入 prompt。右侧是生成的视频。你也能在看到下一部分的预览以及各个部分的进度条
值得注意的是因为这是一个 next-frame-section 预测模型,所以视频的生成时间会越来越长。
并且初始进度可能比后期扩散慢,因为设备可能需要一些预热。
写在最后
FramePack 的出现非常重要,不仅是对技术本身的突破,而是在大幅度降低本地 AI 视频创作硬件需求的情况下,让 AI 视频生成技术变得更加更加容易上手玩,让更多人可以享受到 AI 视频创作的乐趣。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:前沿论文1000篇
在「小白学视觉」公众号后台回复:1000paper,即可下载最新的前沿顶会顶刊1000篇论文,涵盖:医学图像处理、目标检测、语义分割、扩散模型、大模型、自动驾驶、具身智能、超分辨率、图像去噪等多个领域。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
















 1797
1797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









