







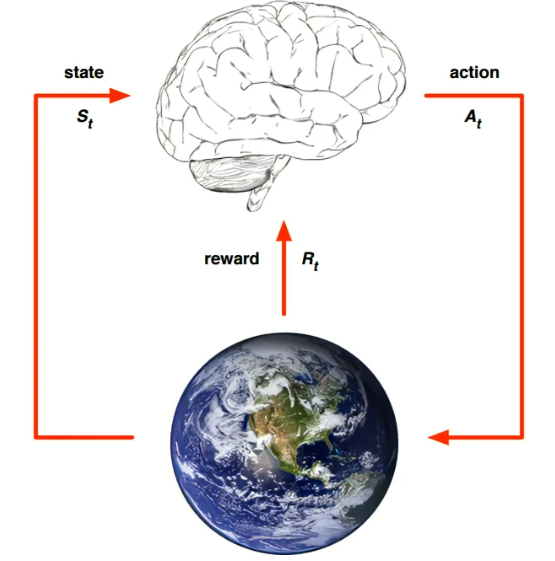
1基本概念
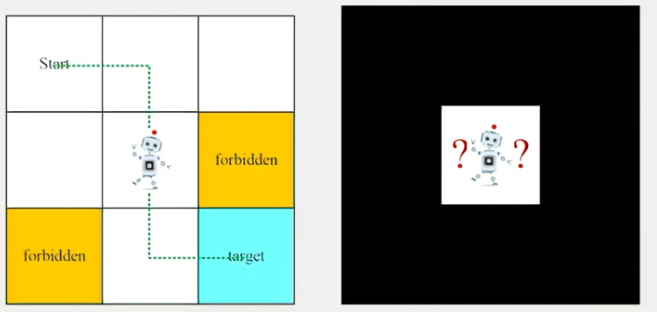
下面用一个网格世界的例子来解释相关概念。网格世界中,有一个机器人在里面走,需要从Start到达target,中间需要避开forbidden,和boundary。
-
Agent(智能体):机器人
-
状态(State):每个网格代表一个状态,状态空间 S = { s i } i = 1 9 S=\{s_i\}_{i=1}^9 S={si}i=19
-
动作(Action):动作空间 A = { a i } i = 1 5 A=\{a_i\}_{i=1}^5 A={ai}i=15, a 1 a_1 a1(向上移动), a 2 a_2 a2(向右移动), a 3 a_3 a3(向下移动), a 4 a_4 a4(向左移动), a 5 a_5 a5(原地不动)
-
奖励(Reward):智能体执行一个动作后,会得到的一个奖励,该值是标量。如果智能体尝试越过边界,则得到一个奖励为-1。Reward可以引导Agent该怎么做,不该怎么做。
-
策略(Policy):智能体会用策略来选取下一步的动作。分为确定性策略和随机性策略。
确定性策略 a = π ( s ) a=\pi(s) a=π(s)。
随机性策略: π ( a ∣ s ) = P ( A = a ∣ S = s ) \pi(a|s)=P(A=a|S=s) π(a∣s)=P(A=a∣S=s) -
状态转移(state transition):在确定性情况(deterministic case)中
-
状态转移概率(state transition probability):在随机性的情况中,用条件概率描述状态转移,比如有风向下吹的情况下 P ( s 2 ∣ s 1 , a 2 ) = 0.5 , P ( s 5 ∣ s 1 , a 2 ) = 0.5 P(s_2|s_1,a_2)=0.5,P(s_5|s_1,a_2)=0.5 P(s2∣s1,a2)=0.5,P(s5∣s1,a2)=0.5
-
轨迹(trajectory):是一条state-action-reward 链:

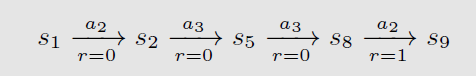
-
回报(Return):把一个轨迹(trajectory)上所有的奖励加起来。直觉上return可以反映决策的好坏。
-
折扣回报(Discounted return):
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + . . . + γ t − 1 R T = ∑ i = 0 γ i R T + i + 1 , γ ∈ [ 0 , 1 ] G_t=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+...+\gamma^{t-1}R_{T}=\sum_{i=0}^{}{\gamma^iR_{T+i+1}},\gamma \in [0,1] Gt=Rt+1+γRt+2+γ2Rt+3+...+γt−1RT=∑i=0γiRT+i+1,γ∈[0,1]
折扣回报中 γ \gamma γ的大小决定了智能体更加近视,或者更加远视
2强化学习分类
可以通过智能体到底有没有学习环境模型来进行分类。针对是否需要对真实环境建模,强化学习可以分为有模型强化学习和免模型强化学习。
- 有模型(model-based) 强化学习:它通过学习状态的转移来采取动作
- 免模型(model-free)强化学习智能体:它没有去直接估计状态的转移,也没有得到环境的具体转移变量,它通过学习价值函数和策略函数进行决策。
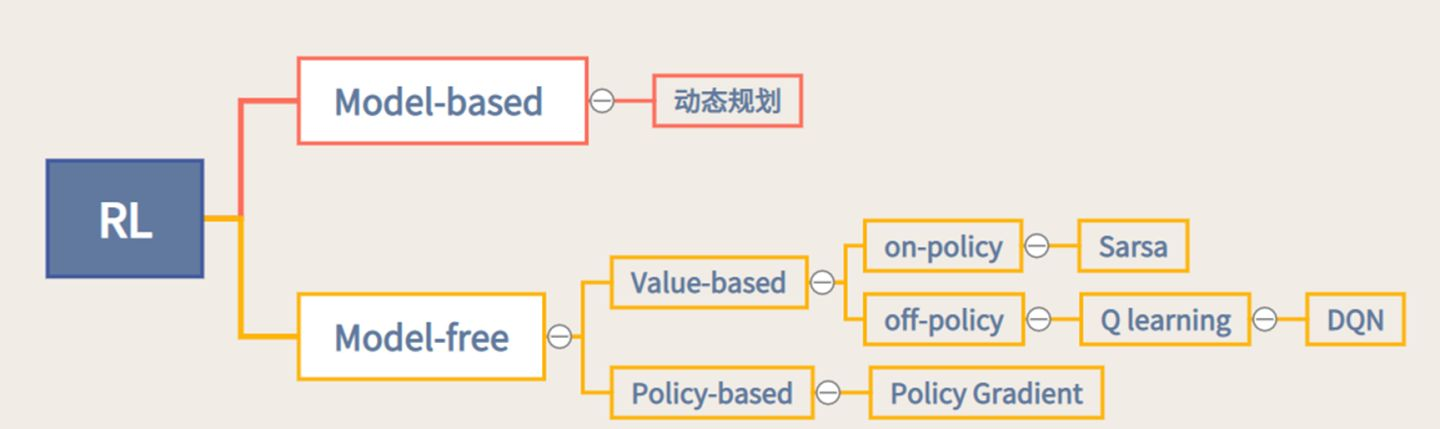
根据智能体学习的事物不同,我们可以把智能体进行归类。
- 基于价值的学习(value-based RL):在基于价值的强化学习方法中,智能体不需要制定显式的策略,它维护一个价值表格或价值函数,并通过这个价值表格或价值函数来选取价值最大的动作。基于价值迭代的方法只能应用在不连续的、离散的环境下(如围棋或某些游戏领域)。代表方法有:Q-learning、Sarsa。
- 基于策略的学习(policy-based RL):在基于策略的强化学习方法中,智能体会制定一套动作策略(确定在给定状态下需要采取何种动作),并根据这个策略进行操作。强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励。代表方法是策略梯度算法。对于动作集合规模庞大、动作连续的场景(如机器人控制领域),基于策略迭代的方法能够根据设定的策略来选择连续的动作。
- 演员-评论员算法(actor-critic algorithm):演员-评论员算法同时使用策略和价值评估来做出决策。其中,智能体会根据策略做出动作,而价值函数会对做出的动作给出价值,这样可以在原有的策略梯度算法的基础上加速学习过程,取得更好的效果。















 2114
2114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









