







一般情况下,我们保存模型的格式都是pth的,最近根据一个项目需求,需要把pth格式转换为onnx格式,方便后面的调取,故此学习理解了一下,记录将SAM模型导出为onnx的过程。
SAM系列篇:
【技术追踪】SAM(Segment Anything Model)代码解析与结构绘制之Image Encoder
【技术追踪】SAM(Segment Anything Model)代码解析与结构绘制之Prompt Encoder
【技术追踪】SAM(Segment Anything Model)代码解析与结构绘制之Mask Decoder
【SAM综述】医学图像分割的分割一切模型:当前应用和未来方向
0、所需安装
要使用导出的onnx模型,需要安装onnxruntime库:
pip install onnxruntime-gpu # 安装GPU版本
pip install onnxruntime # 安装普通版本
1、SAM的onnx模型导出
onnx模型导出采用torch中的onnx.export
import torch
from segment_anything import sam_model_registry, SamPredictor
from segment_anything.utils.onnx import SamOnnxModel
import warnings
# 加载原来的pth模型
checkpoint = "sam_vit_b_01ec64.pth" # 参数路径
model_type = "vit_b" # 模型类
sam = sam_model_registry[model_type](checkpoint=checkpoint) # sam创建与预训练参数加载
onnx_model_path = "sam_onnx_example.onnx" # onnx模型输出路径
onnx_model = SamOnnxModel(sam, return_single_mask=True) # 一个新模型,输入为加载预训练参数的sam
# 动态轴定义,表示模型输入点个数可变
dynamic_axes = {
"point_coords": {1: "num_points"},
"point_labels": {1: "num_points"},
}
embed_dim = sam.prompt_encoder.embed_dim # 嵌入维度: 256
embed_size = sam.prompt_encoder.image_embedding_size # 嵌入的图像大小 [64,64]
mask_input_size = [4 * x for x in embed_size] # 输入mask的大小 [256, 256]
# onnx的输入参数名称、大小与类型定义
dummy_inputs = {
"image_embeddings": torch.randn(1, embed_dim, *embed_size, dtype=torch.float), # 图像嵌入维度
"point_coords": torch.randint(low=0, high=1024, size=(1, 5, 2), dtype=torch.float), # 输入点的坐标
"point_labels": torch.randint(low=0, high=4, size=(1, 5), dtype=torch.float), # 输入点的标签
"mask_input": torch.randn(1, 1, *mask_input_size, dtype=torch.float), # 输入mask
"has_mask_input": torch.tensor([1], dtype=torch.float), # 是否有mask输入
"orig_im_size": torch.tensor([1500, 2250], dtype=torch.float), # 图像原始大小
}
# onnx的输出参数名称
output_names = ["masks", "iou_predictions", "low_res_masks"]
# 利用torch.onnx.export导出onnx模型
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=torch.jit.TracerWarning)
warnings.filterwarnings("ignore", category=UserWarning)
with open(onnx_model_path, "wb") as f:
torch.onnx.export(
onnx_model, # 要导出的PyTorch模型
tuple(dummy_inputs.values()), # 模型的输入数据
f, # noox模型的数据将被写入这个文件
export_params=True, # 是否导出模型参数, 默认为True。
verbose=False, # 是否打印日志信息
opset_version=17, # noox操作符集(opset)的版本
do_constant_folding=True, # 是否执行常量折叠优化,这可以简化模型并可能提高性能。
input_names=list(dummy_inputs.keys()), # 输入的名称列表
output_names=output_names, # 输出的名称列表
dynamic_axes=dynamic_axes, # 动态轴定义。动态轴允许在模型运行时改变某些维度的大小。这是一个字典,其键是输入或输出的名称,值是一个字典,表示哪些维度是动态的。
)
导出成功显示如下,在当前路径中会生成onnx模型。
整个模型导出过程,还是非常简洁明了的,最主要的关键地方是采用了一个SamOnnxModel类,这个类是官方实现的,对sam模型进行了一个封装。
来看看SamOnnxModel如何封装的sam吧!
import torch
import torch.nn as nn
from torch.nn import functional as F
from typing import Tuple
from ..modeling import Sam
from .amg import calculate_stability_score
class SamOnnxModel(nn.Module):
def __init__(
self,
model: Sam, # 输入带预训练参数的模型
return_single_mask: bool, # True 输出单张mask
use_stability_score: bool = False, # 计算一批mask的稳定性评分
return_extra_metrics: bool = False, #
) -> None:
super().__init__()
self.mask_decoder = model.mask_decoder # 模型的mask decoder
self.model = model # SAM
self.img_size = model.image_encoder.img_size # 1024 image encoder 输入图像的大小
self.return_single_mask = return_single_mask # True 返回单张图像
self.use_stability_score = use_stability_score # False
self.stability_score_offset = 1.0
self.return_extra_metrics = return_extra_metrics # False
@staticmethod
def resize_longest_image_size(
input_image_size: torch.Tensor, longest_side: int
) -> torch.Tensor:
input_image_size = input_image_size.to(torch.float32)
scale = longest_side / torch.max(input_image_size)
transformed_size = scale * input_image_size
transformed_size = torch.floor(transformed_size + 0.5).to(torch.int64)
return transformed_size
# 输入点嵌入
def _embed_points(self, point_coords: torch.Tensor, point_labels: torch.Tensor) -> torch.Tensor:
point_coords = point_coords + 0.5
point_coords = point_coords / self.img_size
point_embedding = self.model.prompt_encoder.pe_layer._pe_encoding(point_coords)
point_labels = point_labels.unsqueeze(-1).expand_as(point_embedding)
point_embedding = point_embedding * (point_labels != -1)
point_embedding = point_embedding + self.model.prompt_encoder.not_a_point_embed.weight * (
point_labels == -1
)
for i in range(self.model.prompt_encoder.num_point_embeddings):
point_embedding = point_embedding + self.model.prompt_encoder.point_embeddings[
i
].weight * (point_labels == i)
return point_embedding
# 输入mask嵌入
def _embed_masks(self, input_mask: torch.Tensor, has_mask_input: torch.Tensor) -> torch.Tensor:
mask_embedding = has_mask_input * self.model.prompt_encoder.mask_downscaling(input_mask)
mask_embedding = mask_embedding + (
1 - has_mask_input
) * self.model.prompt_encoder.no_mask_embed.weight.reshape(1, -1, 1, 1)
return mask_embedding
# mask输出后处理
def mask_postprocessing(self, masks: torch.Tensor, orig_im_size: torch.Tensor) -> torch.Tensor:
masks = F.interpolate(
masks,
size=(self.img_size, self.img_size),
mode="bilinear",
align_corners=False,
)
prepadded_size = self.resize_longest_image_size(orig_im_size, self.img_size).to(torch.int64)
masks = masks[..., : prepadded_size[0], : prepadded_size[1]] # type: ignore
orig_im_size = orig_im_size.to(torch.int64)
h, w = orig_im_size[0], orig_im_size[1]
masks = F.interpolate(masks, size=(h, w), mode="bilinear", align_corners=False)
return masks
def select_masks(
self, masks: torch.Tensor, iou_preds: torch.Tensor, num_points: int
) -> Tuple[torch.Tensor, torch.Tensor]:
# Determine if we should return the multiclick mask or not from the number of points.
# The reweighting is used to avoid control flow.
score_reweight = torch.tensor(
[[1000] + [0] * (self.model.mask_decoder.num_mask_tokens - 1)]
).to(iou_preds.device)
score = iou_preds + (num_points - 2.5) * score_reweight
best_idx = torch.argmax(score, dim=1)
masks = masks[torch.arange(masks.shape[0]), best_idx, :, :].unsqueeze(1)
iou_preds = iou_preds[torch.arange(masks.shape[0]), best_idx].unsqueeze(1)
return masks, iou_preds
@torch.no_grad()
def forward(
self,
image_embeddings: torch.Tensor, # 经过image encoder的图像嵌入: [1,256,64,64]
point_coords: torch.Tensor, # 给定point经过映射后的坐标: [1,2,2]
point_labels: torch.Tensor, # point是前景还是背景的标注: [1,2]
mask_input: torch.Tensor, # mask输入, 设置为全0
has_mask_input: torch.Tensor, # 0
orig_im_size: torch.Tensor, # 原始图像大小: [1365, 2048]
):
# _embed_points实现point和box嵌入
sparse_embedding = self._embed_points(point_coords, point_labels)
# _embed_masks实现mask嵌入
dense_embedding = self._embed_masks(mask_input, has_mask_input)
# mask_decoder分割结果
masks, scores = self.model.mask_decoder.predict_masks(
image_embeddings=image_embeddings,
image_pe=self.model.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embedding,
dense_prompt_embeddings=dense_embedding,
)
# False/pass
if self.use_stability_score:
scores = calculate_stability_score(
masks, self.model.mask_threshold, self.stability_score_offset
)
# True
if self.return_single_mask:
masks, scores = self.select_masks(masks, scores, point_coords.shape[1])
# 后处理,恢复到原图大小
upscaled_masks = self.mask_postprocessing(masks, orig_im_size)
# False/pass
if self.return_extra_metrics:
stability_scores = calculate_stability_score(
upscaled_masks, self.model.mask_threshold, self.stability_score_offset
)
areas = (upscaled_masks > self.model.mask_threshold).sum(-1).sum(-1)
return upscaled_masks, scores, stability_scores, areas, masks
return upscaled_masks, scores, masks
2、SAM导出的onnx模型测试
模型导出了,可以使用onnx格式的模型测试一下了:
import numpy as np
import cv2
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
import onnxruntime
def show_mask(mask, ax):
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
# 测试图像加载
image = cv2.imread('./test image/image dog.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure()
plt.imshow(image)
plt.axis('off')
plt.show()
# 原始模型加载
checkpoint = "sam_vit_b_01ec64.pth"
model_type = "vit_b"
sam = sam_model_registry[model_type](checkpoint=checkpoint)
sam.to(device='cuda')
predictor = SamPredictor(sam)
predictor.set_image(image)
image_embedding = predictor.get_image_embedding().cpu().numpy() # 模型经过image encoder的嵌入
print(image_embedding.shape) # (1, 256, 64, 64)
# onnx模型加载
onnx_model_path = "sam_onnx_example.onnx"
ort_session = onnxruntime.InferenceSession(onnx_model_path)
# 输入点(两个点)
input_point = np.array([[1300, 800], [1600, 850]])
input_label = np.array([1, 1])
onnx_coord = np.concatenate([input_point, ], axis=0)[None, :, :]
onnx_label = np.concatenate([input_label, ], axis=0)[None, :].astype(np.float32)
onnx_coord = predictor.transform.apply_coords(onnx_coord, image.shape[:2]).astype(np.float32)
onnx_mask_input = np.zeros((1, 1, 256, 256), dtype=np.float32)
onnx_has_mask_input = np.zeros(1, dtype=np.float32)
ort_inputs = {
"image_embeddings": image_embedding, # 经过image encoder的图像嵌入: [1,256,64,64]
"point_coords": onnx_coord, # 给定point经过映射后的坐标: [1,2,2]
"point_labels": onnx_label, # point是前景还是背景的标注: [1,2]
"mask_input": onnx_mask_input, # mask输入, 设置为全0
"has_mask_input": onnx_has_mask_input, # 0
"orig_im_size": np.array(image.shape[:2], dtype=np.float32) # 原始图像大小: [1365, 2048]
}
# 模型推理
masks, _, _ = ort_session.run(None, ort_inputs) # masks:[1,1,1365,2048]
masks = masks > predictor.model.mask_threshold
plt.figure(dpi=300)
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()
输出为:

当然啦,也可以point和box一起用:
import numpy as np
import cv2
import matplotlib.pyplot as plt
from segment_anything import sam_model_registry, SamPredictor
import onnxruntime
def show_mask(mask, ax):
color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels == 1]
neg_points = coords[labels == 0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',
linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0][0], box[0][1]
w, h = box[0][2] - box[0][0], box[0][3] - box[0][1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
image = cv2.imread('./test image/image dog.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure()
plt.imshow(image)
plt.axis('off')
plt.show()
checkpoint = "sam_vit_b_01ec64.pth"
model_type = "vit_b"
sam = sam_model_registry[model_type](checkpoint=checkpoint)
sam.to(device='cuda')
predictor = SamPredictor(sam)
predictor.set_image(image)
image_embedding = predictor.get_image_embedding().cpu().numpy()
print(image_embedding.shape) # (1, 256, 64, 64)
onnx_model_path = "sam_onnx_example.onnx"
ort_session = onnxruntime.InferenceSession(onnx_model_path)
input_box = np.array([[700, 500, 1900, 1100]])
input_point = np.array([[1300, 800], [1600, 850]])
input_label = np.array([1, 1])
onnx_box_coords = input_box.reshape(2, 2)
onnx_box_labels = np.array([1, 1])
onnx_coord = np.concatenate([input_point, onnx_box_coords], axis=0)[None, :, :]
onnx_label = np.concatenate([input_label, onnx_box_labels], axis=0)[None, :].astype(np.float32)
onnx_coord = predictor.transform.apply_coords(onnx_coord, image.shape[:2]).astype(np.float32)
onnx_mask_input = np.zeros((1, 1, 256, 256), dtype=np.float32)
onnx_has_mask_input = np.zeros(1, dtype=np.float32)
ort_inputs = {
"image_embeddings": image_embedding, # 经过image encoder的图像嵌入: [1,256,64,64]
"point_coords": onnx_coord, # 给定point经过映射后的坐标: [1,2,2]
"point_labels": onnx_label, # point是前景还是背景的标注: [1,2]
"mask_input": onnx_mask_input, # mask输入, 设置为全0
"has_mask_input": onnx_has_mask_input, # 0
"orig_im_size": np.array(image.shape[:2], dtype=np.float32) # 原始图像大小: [1365, 2048]
}
masks, _, _ = ort_session.run(None, ort_inputs) # masks:[1,1,1365,2048]
masks = masks > 0.8
plt.figure(dpi=300)
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()
输出为:
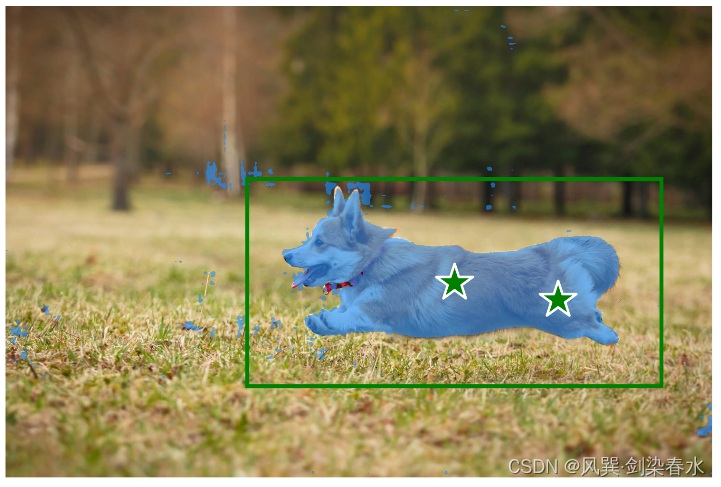
emmm,好像没有只使用point效果好,叠buff也不好使呢…
此外,还有个问题是,官方的这个打包没有把image encoder也包括进去,不过理解了这个流程,后面可以改一改,这样在推理的时候就只用一个onnx模型了。
值得注意的是,虽然打包onnx时,输入设置的都是tensor形式,但onnx推理时输入都是numpy形式的。
参考官方资料:onnx_model_example
理解了sam的onnx导出及使用,后面自己的模型也可以进行相应操作啦~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









