







 本文介绍了一种名为VDO-SLAM的SLAM系统,它利用语义信息估计场景中动态对象的运动,融合静态与动态结构进行高精度定位。系统通过联合光流估计增强鲁棒性,尤其在处理复杂动态环境和物体遮挡时表现出色。实验对比显示,该方法在单目相机位姿估计和动态目标跟踪上优于CubeSLAM,并在真实世界场景中展示了实际应用效果。
本文介绍了一种名为VDO-SLAM的SLAM系统,它利用语义信息估计场景中动态对象的运动,融合静态与动态结构进行高精度定位。系统通过联合光流估计增强鲁棒性,尤其在处理复杂动态环境和物体遮挡时表现出色。实验对比显示,该方法在单目相机位姿估计和动态目标跟踪上优于CubeSLAM,并在真实世界场景中展示了实际应用效果。
2020 VDO-SLAM: A Visual DynamicObject-aware SLAM System
Jun Zhang et al. “VDO-SLAM: A Visual Dynamic Object-aware SLAM System” arXiv: Robotics (2020): n. pag.
源代码:https://github.com/halajun/VDO_SLAM
作者介绍:https://halajun.github.io
摘要
VDO-SLAM是一个鲁棒性高的目标感知动态SLAM系统,它利用语义信息来估计场景中刚性对象的运动,而不需要任何对象形状或运动模型的先验知识。该方法将环境中的动态结构和静态结构集成到一个统一的估计框架中,从而获得准确的机器人位姿和时空地图估计
1 引言
常规SLAM处理动态场景:
- 将动态目标设为外点,从估计过程中移除
- 基于传统多目标跟踪方法的运动目标检测与跟踪,该方法的精度取决于相机位姿估计的准确性(假设相邻帧位姿矩阵误差较大,对目标的运动预测影响较大),而对于复杂动态环境下,相机位姿准确性是易受影响的
用显著点表述环境:点容易被检测、跟踪和集成
用线、面表示可以提供更丰富地图信息
语义信息和对象分割可以为场景中动态对象的识别提供重要的先验信息
为了将语义信息合并到现有的几何SLAM算法中,场景中每个对象的3D模型的数据集是可用的?
显然需要一种算法,该算法可以利用现代深度学习算法的强大检测和分割能力,而不依赖于额外的位姿估计或对象模型先验
本文提出了一种新颖的基于特征的双目/RGB-D动态SLAM系统,该系统利用基于图像的语义信息来同时定位机器人,映射静态和动态结构,跟踪场景中刚体物体的运动。本文工作的贡献:
- 提出了一种在机器人姿态、静态和动态三维点以及物体运动的统一估计框架中对动态场景进行建模的新公式
- 对动态物体SE(3)姿态变化的精确估计优于最先进的算法,并提供了一种提取场景中物体速度的方法
- 提出了利用语义信息来跟踪移动目标的一种鲁棒方法,该方法可以处理由于语义分割对象失败而导致的间接遮挡??
- 一个在复杂和引人注目的真实世界场景中可演示的系统
该系统实现了运动分割、动态目标跟踪和结合静态动态结构进行相机位姿估计,完整地提取了场景中每个刚体目标的姿态变化,提取了速度信息,并在真实的室外场景中进行了演示。
3 方法论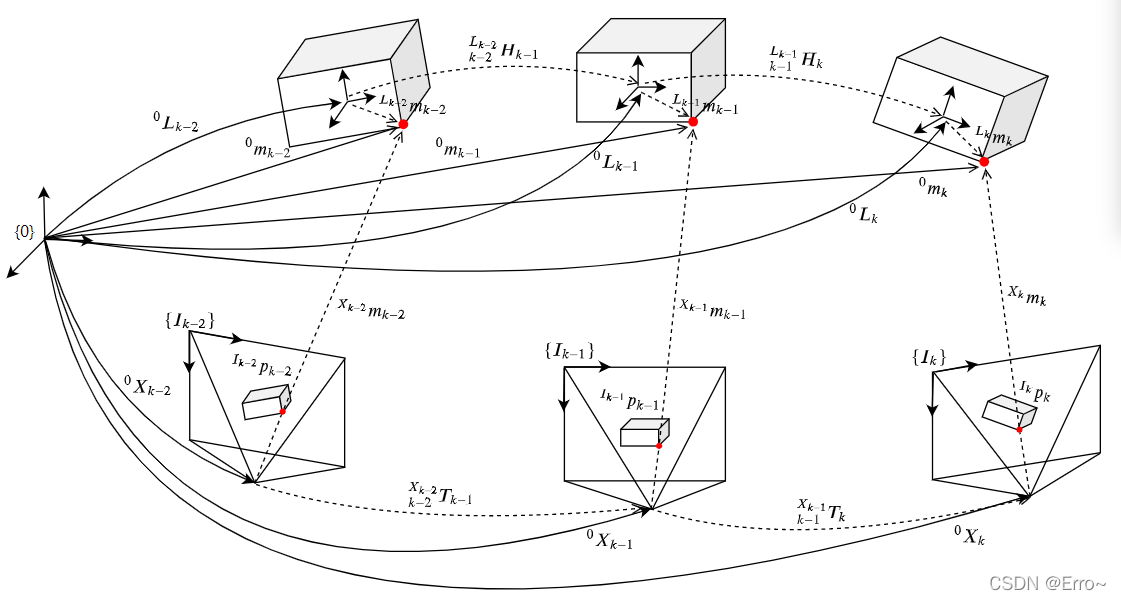
三个变换关系:
- 相邻坐标系之间的变换关系 k − 1 L k − 1 H k ^{L_{k-1}}_{k-1}H_k k−1Lk−1Hk
- 世界坐标系与相机坐标系之间的变换关系 0 L k − 1 k − 1 L k − 1 H k {^{0}L_{k-1}} ^{L_{k-1}}_{k-1}H_k 0Lk−1k−1Lk−1Hk
- 世界坐标系下不同时刻同一空间点间的变换关系 k − 1 0 H k ^{0}_{k-1}H_k k−10Hk,运动估计方法的核心速度估计?
相机位姿和物体运动估计
相机位姿估计:


物体运动位姿估计:


联合光流估计:将运动估计和光流估计相结合来提高鲁棒性



图优化

将四种类型的测量/观测集成到一个联合优化问题中:
- 3D点观测模型误差(3D点的观测):图中白色圆圈为3D点的观测因子

- 视觉里程计模型误差(视觉里程计测量):两帧间变换关系矩阵的误差

- 运动模型误差(动态物体上点的运动):即Object点实际观测与通过上一帧预测的值之间的差

- 平滑度误差(object平滑运动观测):物体变化的连续性

图优化

4 system
系统的整体框架
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PvTcptcB-1646099188340)(文献阅读笔记.assets/image-20220225095106207.png)]](https://i-blog.csdnimg.cn/blog_migrate/4cb8478ff07db6de906b86d40f2aef42.png#pic_center)
Input
输入是RGB-D数据形势的,对于双目,需采用立体视觉获取深度相机,对于单目,充分利用图像的语义信息,采用了单幅图像深度估计来获取单目的深度信息??
Pre-processing
为了保证鲁棒的分离静态场景和objects、确保长期跟踪动态objects,采用实例级别的语义分割和稠密光流估计
Object Instance Segmentation(对象实例分割)
语义信息是静态点和运动对象点分离过程中的重要先验,实例分割有利于将语义前景进一步划分为不同的实例掩码,这使得跟踪每个单独的对象变得更容易,此外,分割掩码提供了object的精确边界信息,这使得对object的点的跟踪更加鲁棒
Optical Flow Estimation
稠密光流用来最大化移动objects上跟踪点的数量(增加特征点),因为移动的物体通常只占据图像的一小块,因此,使用若使用稀疏的特征点匹配不能保证鲁棒地、长期的跟踪。
本文方法利用稠密光流,通过对语义掩模内的所有点进行采样,大大增加了目标点的数量;稠密光流可以给object掩码上每个点设置一个唯一的标识符来进行多目标跟踪;此外,它允许在语义分割失败的情况下恢复对象掩码;这是使用稀疏特征匹配极难实现的任务
Tracking
Feature Detection
采用稀疏角点来进行光流跟踪以满足相机位姿估计速度,只有内点才适合相机运动估计,并将内点保存到地图用于跟踪下一帧中的对应关系,当内点数目低于一定标准时,进行新的特征提取,这些稀疏的内点来自静态区域
Camera Pose Estimation:
相机位姿估计可以使用上一节介绍的3D和2D对应的那种计算方法得到。为了保证估计是鲁棒的,应用了一个模型生成方法用于初始化。特别地,该方法生成两个模型,并基于再投影误差比对内部点的个数。一个是利用之前的运动来计算,另一个是利用P3P的方法。产生最多内在点的运动模型将会被选择用来初始化
Dynamic Object Tracking:
由上一步得到相机的位姿后,定义一个场景光流:

理论上静止的object的场景光流的摸应该等于零,但由于实际环境有噪声的影响,可以设置一个阈值来判断是否为动态object上的点,本文设置的阈值为0.12,如果一个object中”动态“点数的占比超过某一水平(总体的30%),则object被认为是动态的,否则为静态的,这也解决了object中,如car,可能有静止的,也可能有动态的 的情况,低于阈值的也不能一棍子打死,可以保守地任务是运动的object,然后再估计它是不是0运动,到底有多保守呢??看代码
一个比喻:为了防止同一辆车,因为运动,使得再两帧之间被认为是不同的object,本文采用光流跟踪再帧间关联点标签,同一个object上的点的点标签相同,先检测到的移动object的标签为
l
=
1
l=1
l=1,静态的点的标签为0,具体的标签管理得看代码
Object Motion Estimation
目标一般在场景中很小的区域出现,这将会导致稀疏特征点不充足,进而影响跟踪和运动估计阶段。作者对每个目标mask采样了3个点,并进行跟踪。
Mapping
Local Batch Optimisation:
确保精确的相机位姿估计,以用于全局batch优化,只选择局部优化相机位姿和静态结构
Global Batch Optimisation
在所有帧输入处理完后进行全局图构建一个因子图,只有用于跟踪超过3个实例的点将会被加进全局图中
From Mapping to Tracking
什么时候会全局BA结束,并将结果传递到Tracking模块?
5 Experiments
System Setup系统设置
用Mask R-CNN网络进行实例分割, 用PWC-Net进行稠密光流跟踪,获取单目的深度信息,采用 MonoDepth2,使用FAST进行特征提取
Oxford Multimotion Dataset


如上图,我们关闭全局优化与MVO(Multimotion Visual Odometry)进行公平对比,结果表明当观测到物体的旋转运动(自转)时,特别是上右摆动和旋转的盒子和下右旋转的盒子,我们会得到稍高的误差。因为该算法是为相对较大的户外物体的运动设计的,光流算法没有很好地优化旋转物体。其结果是对点运动的估计较差,从而导致目标跟踪性能的下降。
KITTI Tracking Dataset

CubeSLAM的平移和旋转误差都在3米和3度以上,在极端情况下误差分别达到32米和5度;
我们的之间,而在基于学习的单目情况下,平移误差在0.1-0.3米之间,旋转误差在0.4-3度之间

图7给出了在所有测试序列中,一些选中对象(跟踪超过20帧)的目标跟踪长度和目标速度的结果。我们的系统能够跟踪大多数对象超过80%的发生序列。此外,我们估计的物体速度始终与地面真实情况接近


单独进行相机运动和object运动估计情况下跟踪得到的点数比联合光流估计方法少了一个数量级,而且求解得到的误差还要大一些

白色面包车分割失败??(图中看不出来哪里有东西遮挡了啊),本系统可以传播先前跟踪的特征结果
A:就是下面红的的区域没有识别出来,所以靠前面的先验来跟踪
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LgSSUJLu-1646099188341)(文献阅读笔记.assets/image-20220227123716014.png)]](https://i-blog.csdnimg.cn/blog_migrate/33d577dae85ba94abc1af5296250c04b.png#pic_center)

初始的object运动估计在帧间是独立的,它只与传感器的测量有关,不是很理解这里的初始运动估计,是初速度??
采用因子图对静态动态结构一起优化,能够对object的全局细化

个人总结
算法核心还是是传统方法,重点是设计了联合光流法进行图优化,改进的地方:
- 在与CUbeSALM比较中,本文方法在计算单目相机位姿时,结果并不理想
- 计算实时性

















 1385
1385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









