







创作日志:
下载的增强子数据文件里,没给增强子中包含的SNP信息,所以要自己写脚本补充。本来是想通过爬虫的方法在dbSNP的网站上边爬取边补充,但是谁知道dbSNP的搜索功能做得那么垃圾!于是就只能下载dbSNP的变异位点文件,然后再自己做处理。
当我经历了九九八十一难终于下载并解压好了120+G的vcf文件后,打印信息的时候tmd发现自己下载错了版本,我要用的是hg19,却下载成了hg38,欲哭无泪… 文件名不标版本真的很气人。于是读了读README文档,谁让以前不读呢。
具体步骤
注意:用python的PyVCF包可以直接读取vcf.gz文件,根本不需要解压。要解压的话得用linux的gunzip命令。
网址: https://www.ncbi.nlm.nih.gov/snp/
1、跳转至下载页面: 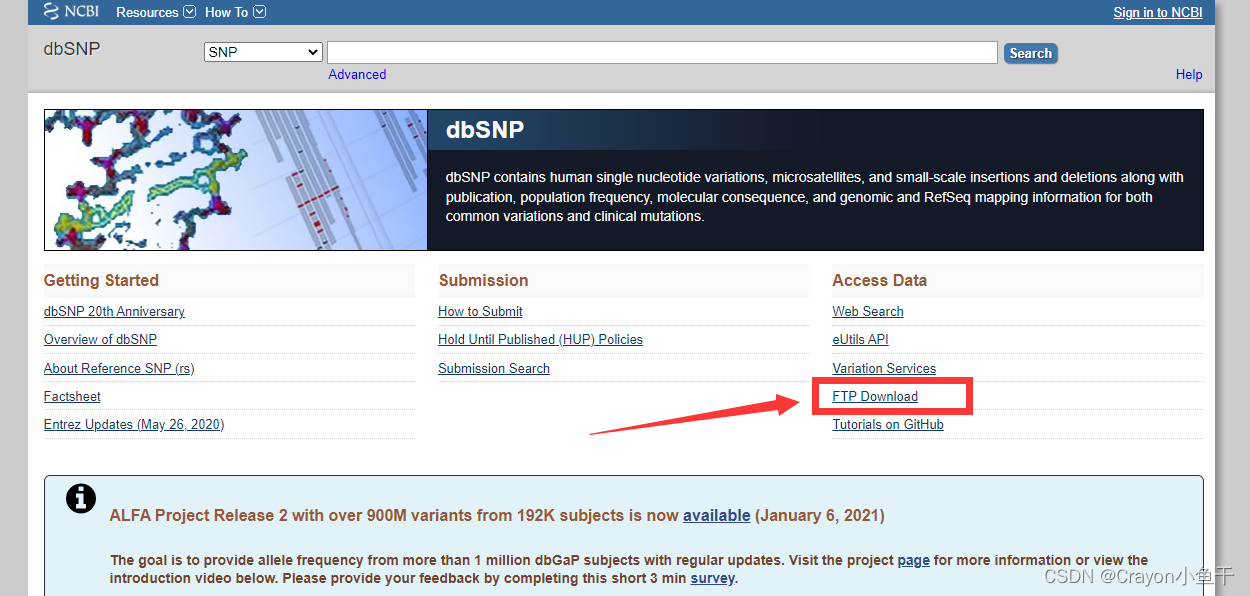
2、选择 organisms

3、根据需要选择文件夹
需要 hg19 的就选择 GRCh37,需要 hg38 的就选择 GRCh38。
至于 b150 和 b151 的区别 :b150 的 00-All.vcf.gz 文件大小都是约7G,b151 的约15G。我没有仔细调查具体为什么,下载15G的肯定就对了。所以不管是 GRCh37还是GRCh38,不懂的话就选择 b151 那个文件夹,发布时间也更新。
至于 human 9606 文件夹:我第一次下载的就是这里面的00-All.vcf.gz文件,最后在处理数据的时候发现是GRCh38.p7版本的,应该与下面那个human 9606 b151 GRCh38p7是一样的,都是15G的大小。

4、选择VCF文件夹

5、下载 00-All.vcf.gz 文件
这个是最全的。common貌似只包括了最“常见”的人种的SNP。
如果是在linux上下载的话,图中的文件链接就是 https://ftp.ncbi.nih.gov/snp/organisms/human_9606_b151_GRCh37p13/VCF/00-All.vcf.gz。需要你们自己构造,然后 wget + 链接。
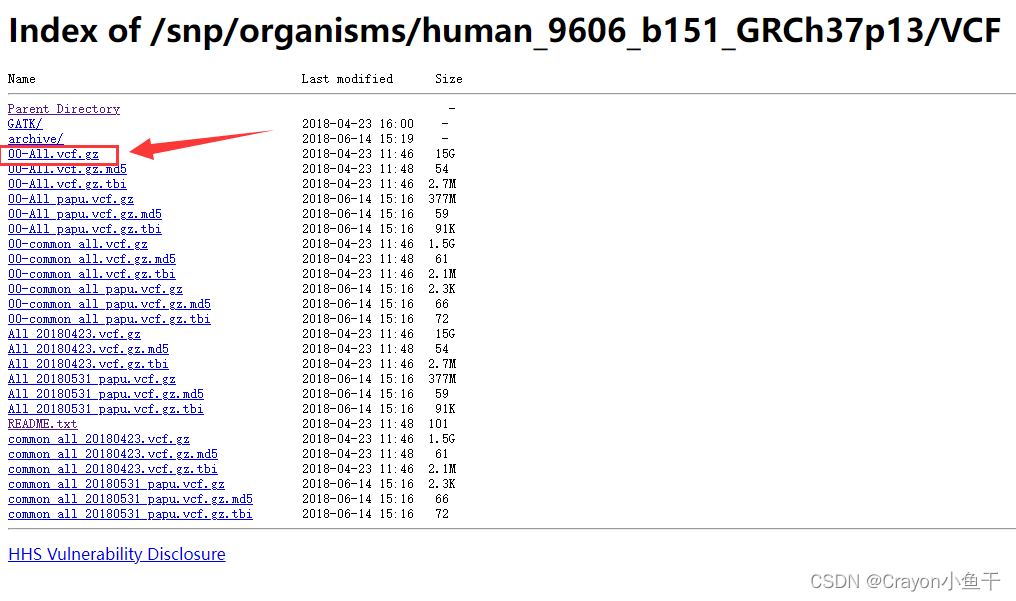
6、linux 解压vcf.gz文件
有必要解压的话:
刚开始我像个傻子一样地在windows上用360解压,过了一个小时,给我闪退了,我还以为是咋回事。我不知道到底能不能用windows解压,反正我尝试了几种都不行。
然后看到要用 linux 解压,因为我把文件下到了windows上,所以还得先把文件复制到 linux 服务器上,然后使用命令解压。命令如下:
gunzip 00-All.vcf.gz

















 1425
1425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









