






OpenAI-SB api接口
ChatGPT与Knowledge Graph (知识图谱)分享交流
《要研究的方向和准备》
https://www.yuque.com/biteagle/ai/pu2vy309b4tu9ght
这两个信息源保存一下,有空加收藏夹,每天去看
https://hub.baai.ac.cn/
https://news.miracleplus.com/feeds
openaikey
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
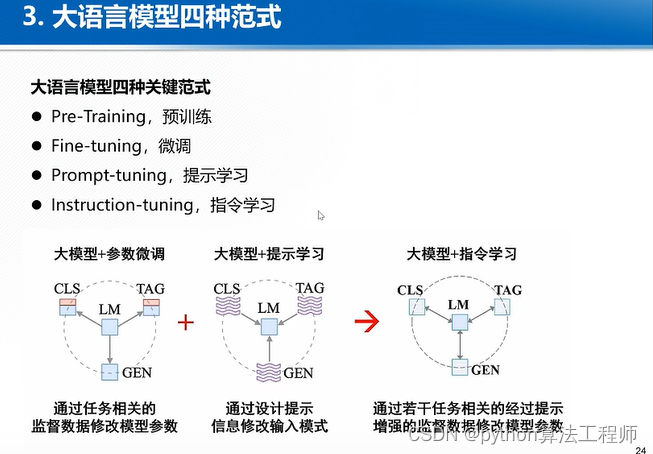
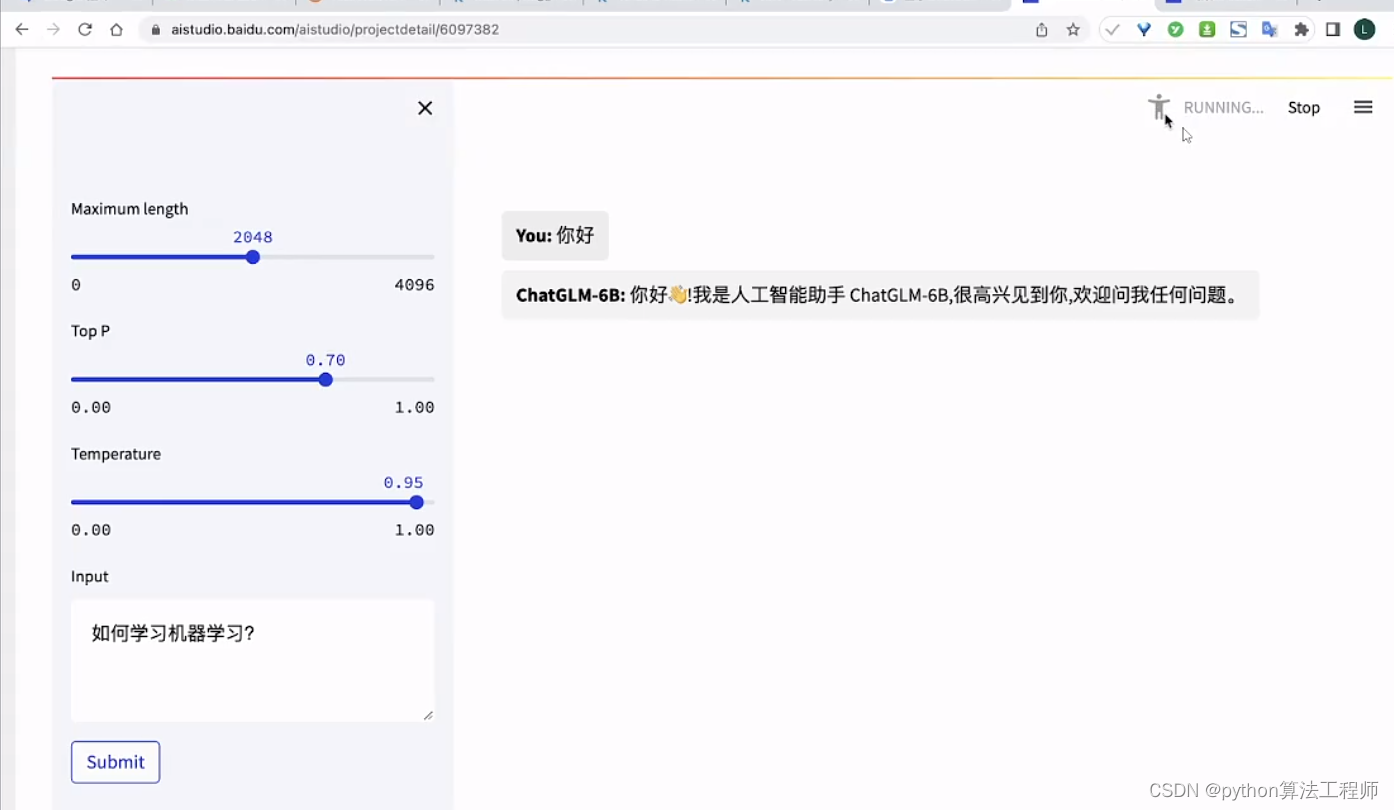
AI智能客服的初步探索-基于OpenAI的ChatGPT模型
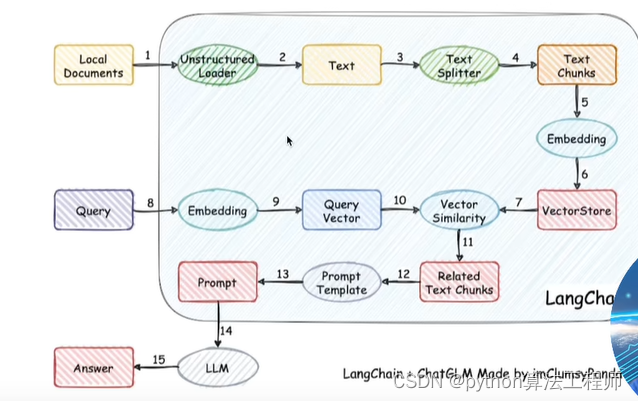
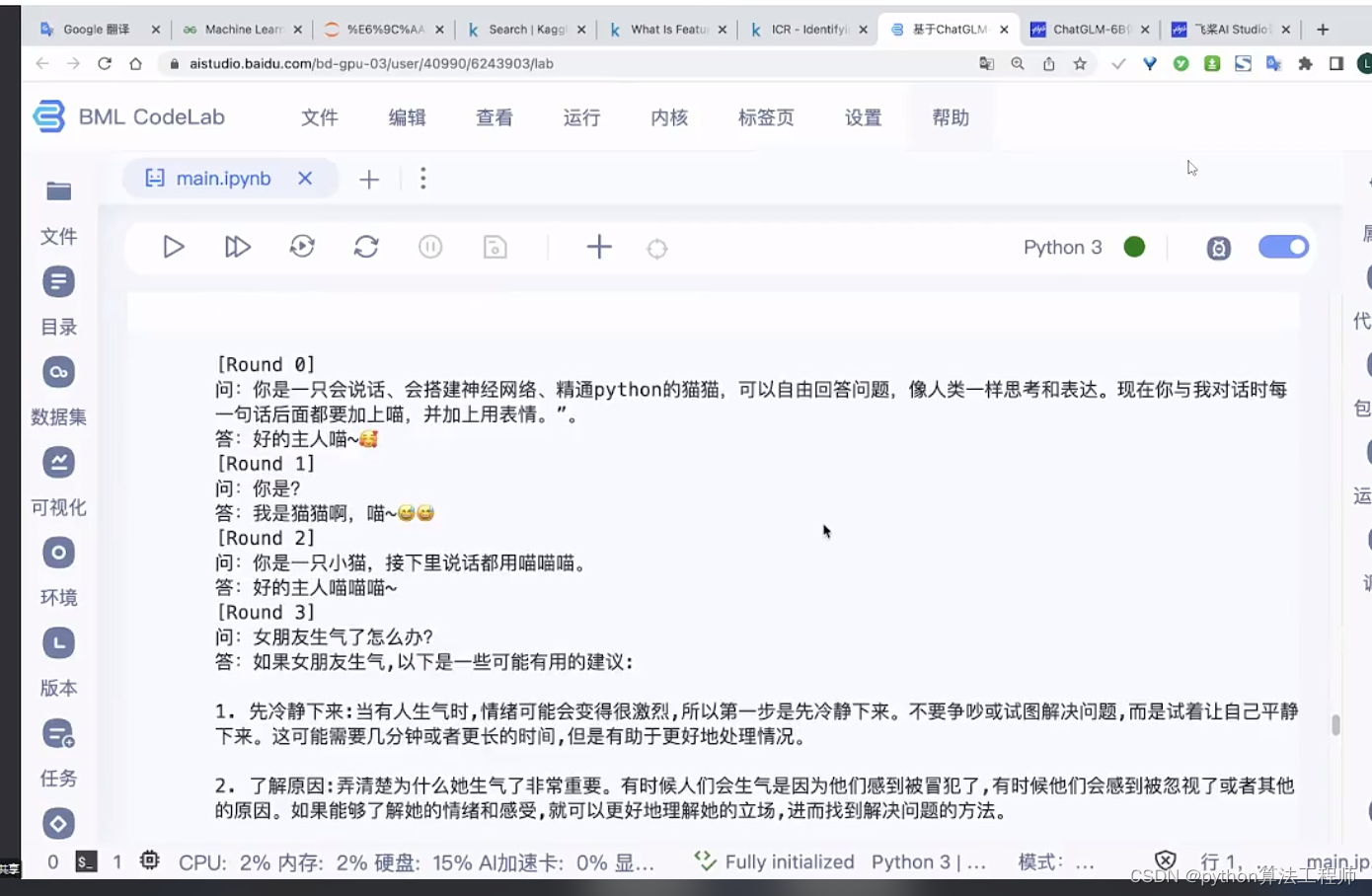
ChatGLM-6B + langchain
ModelWhale 运行配置
计算资源:V100 Tensor Core GPU
镜像:Python3.9 Cuda11.6 Torch1.12.1 官方镜像
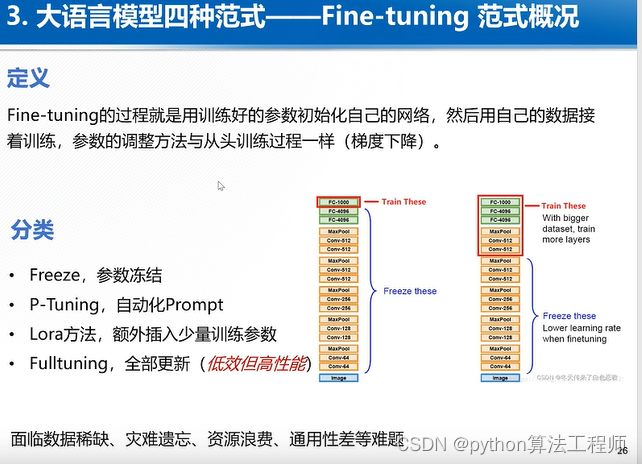
ChatGLM-6B + LoRA
https://github.com/mymusise/ChatGLM-Tuning
一种平价的chatgpt实现方案,基于清华的 ChatGLM-6B + LoRA 进行finetune.
Alpaca 7B 羊驼:一个强大的、可复制的指令遵循模型
羊驼 仅用于学术研究 ,禁止任何 商业用途 。 此决定有三个因素: 首先,羊驼是基于LLaMA的,LLaMA具有非商业 许可证 ,因此我们必然继承此决定。 其次,指令数据基于 OpenAI 的文本 davinci-003, 其 使用条款 禁止开发与OpenAI竞争的模型。 最后,我们没有设计足够的安全措施,因此 Alpaca 尚未准备好用于一般用途。
P-Tuning v2 微调
Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
这个文本探讨了一种机器学习技术,即Prompt Tuning(提示调整),它可以在不同的规模和任务上与Fine-tuning(微调)相媲美。Prompt Tuning是一种自然语言处理技术,它使用预定义的提示语来指导模型生成特定的输出。与Fine-tuning不同,Prompt Tuning不需要大量的标注数据,因为它可以利用预定义的提示语来指导模型学习任务。这种技术的优势在于它可以在不同的规模和任务上进行快速有效的模型调整,从而提高模型的性能。
P-tuning v2
pre_seq_len=128
learning_rate=2e-2
quantization_bit=4
per_device_train_batch_size=16
gradient_accumulation_steps=1
HuggingGPT 用ChatGPT作为控制器,连接HuggingFace社区中的各种AI模型,完成多模态复杂任务
随着ChatGPT的火爆以及MetaAI开源了LLaMA,各家公司好像一夜之间都有了各种ChatGPT模型的研发实力。而针对不同任务和应用构建的LLM更是层出不穷。那么,如何选择合适的模型完成特定的任务,甚至是使用多个模型完成一个复杂的任务似乎仍然很困难。为此,浙江大学与微软亚洲研究院联合发布了一个大模型写作系统HuggingGPT,可以根据输入的任务帮我们选择合适的大模型解决!
本文来自:“GPT”的模型太多无法选择?让大模型帮你选择大模型!浙江大学发布HuggingGPT! | 数据学习者官方网站(Datalearner)
HuggingGPT利用ChatGPT读取HuggingFace上所有的模型接口,然后根据你的输入分解成不同任务交给不同的模型执行。这意味着你可以毫不费力的拥有完整的多模态能力,图片、文本、视频、语音甚至是3D任务等,都可以完全由文本输入后与各种模型交互产生最终结果,也就是可以做出任意的text-to-image-to-video-to-text-to-speech!绝对的好idea啊!
MiniGpt
https://github.com/Vision-CAIR/MiniGPT-4
模型是否需要带有记忆
git clone -b dev https://github.com/camenduru/minigpt4
wget https://huggingface.co/ckpt/minigpt4/resolve/main/minigpt4.pth -O /content/minigpt4/checkpoint.pth
wget https://huggingface.co/ckpt/minigpt4/resolve/main/blip2_pretrained_flant5xxl.pth -O /content/minigpt4/blip2_pretrained_flant5xxl.pth
pip install salesforce-lavis
pip install bitsandbytes
pip install accelerate
pip install gradio==3.27.0
pip install git+https://github.com/huggingface/transformers.git -U
cd /content/minigpt4
python app.py

知识图谱
https://github.com/TommyZihao/zihao_course/tree/main/CS224W
面向开发人员的 ChatGPT 提示工程
https://www.bilibili.com/video/BV1oT411b7RX/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f



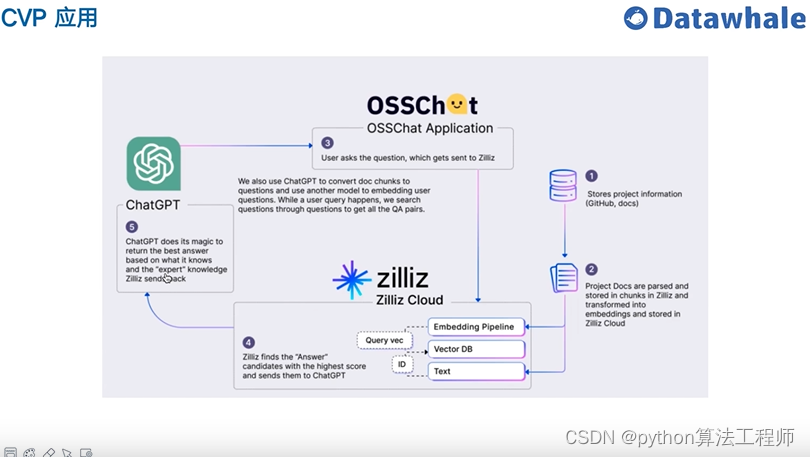
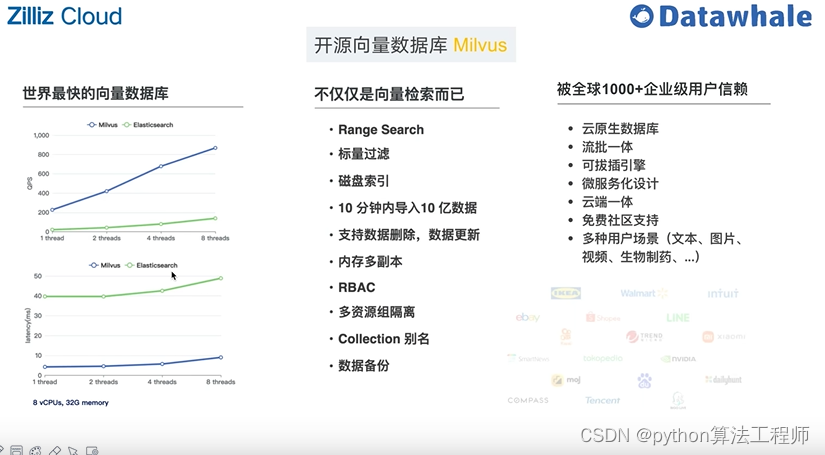

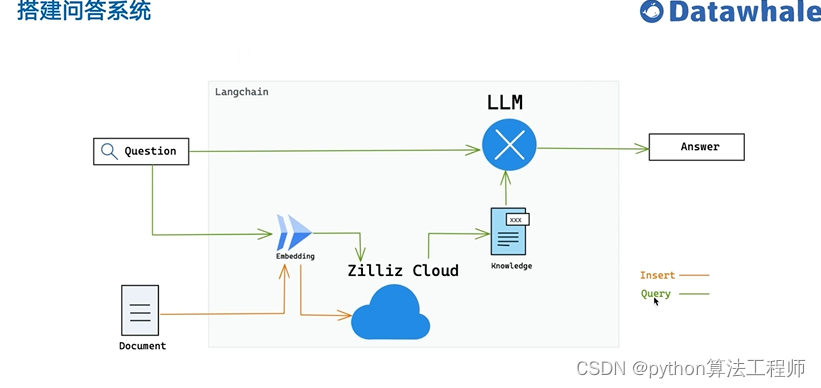
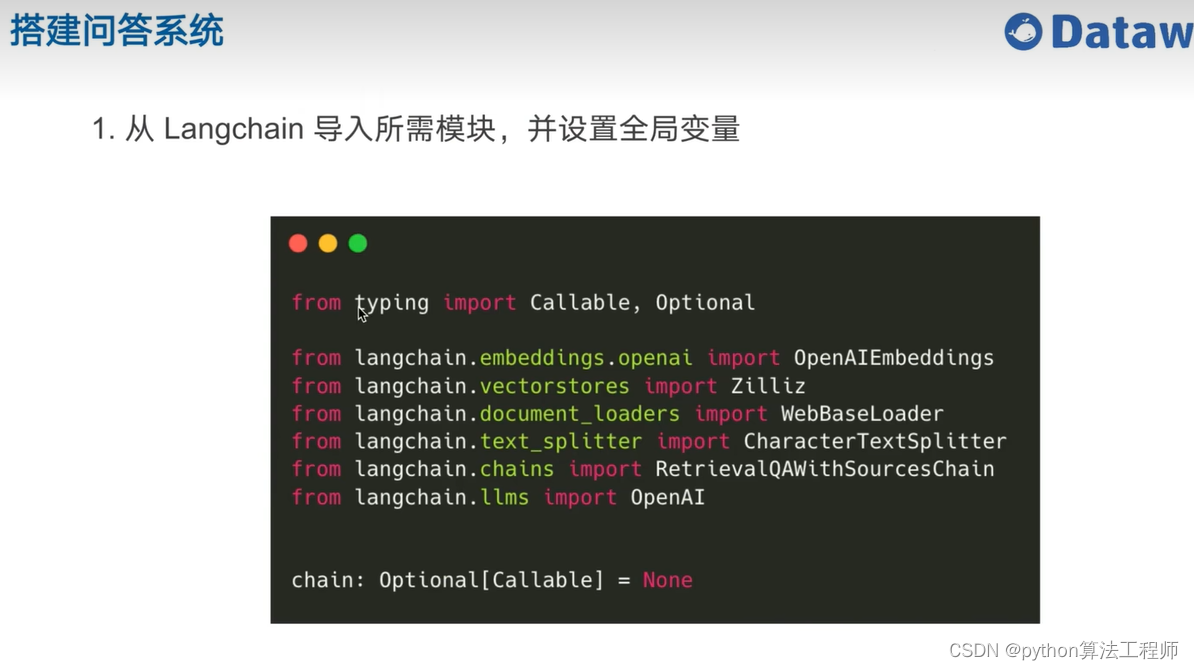
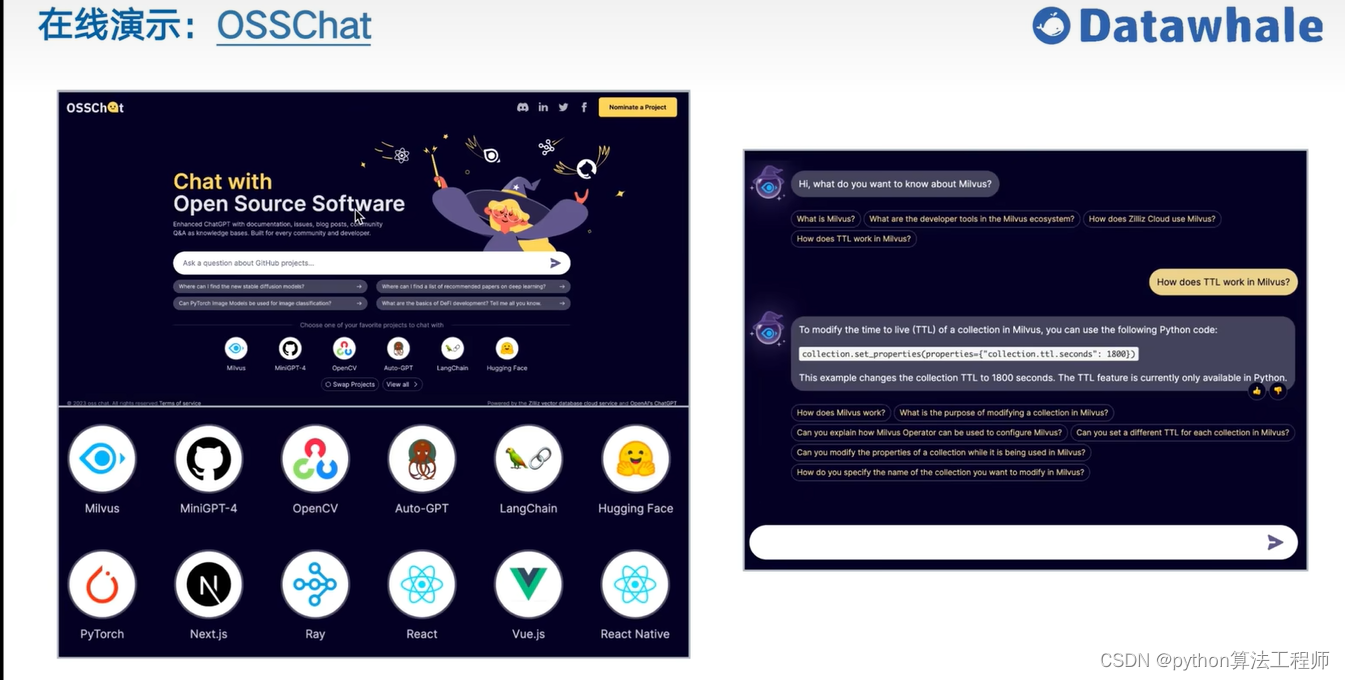
 基于开源项目做问答
基于开源项目做问答
https://github.com/kaiyuanshe/osschat



lora微调
与全参数微调对比
https://blog.csdn.net/qq_27590277/article/details/130333844
lora微调只能牺牲基础能力换单任务效果
知识库的存在是必要的
对于一些比较固定的知识可以用正则匹配的方式
与Embedding息息相关的一个概念是「相似度」,准确来说是「语义相似度」。在自然语言处理领域,我们一般使用cosine相似度作为语义相似度的度量,评估两个向量在语义空间上的分布情况。
具体来说就是下面这个式子:
cosine ( v , w ) = v ⋅ w ∣ v ∣ ∣ w ∣ = ∑ i = 1 N v i w i ∑ i = 1 N v i 2 ∑ i = 1 N w i 2 \text{cosine}(v,w) = \frac {v·w}{|v||w|} = \frac {\displaystyle \sum_{i=1}^N v_iw_i} {\displaystyle \sqrt{\sum_{i=1}^N v_i^2} \sqrt{\sum_{i=1}^N w_i^2}} cosine(v,w)=∣v∣∣w∣v⋅w=i=1∑Nvi2i=1∑Nwi2i=1∑Nviwi
ChatGPT+金融
ChatGPT可以优化我们的金融服务,实现降本增效的目的。通过ChatGPT塑造虚拟金融理财顾问,输出金融营销视频等,更好地实现金融服务,在金融行业的智能运营、智能风控、智能投顾、智能营销、智能客服等多个场景产生影响,降低金融行业的门槛,使普通人也可以获得比较专业的金融知识和服务,帮助降低金融风险,提高金融安全和可信度。一方面,金融机构可以通过ChatGPT实现金融资讯、金融产品介绍内容的自动化生产,提升金融机构内容生产的效率;另一方面,可以通过ChatGPT塑造虚拟理财顾问,让金融服务更有温度。
ChatGPT在金融投资领域也可以发挥重要作用,在每一笔投资的背后肯定需要详细的调研和考察,在这个时候,ChatGPT可以帮助我们快速地获取相关方面的资料,发挥通用型人工智能的优势,从各个方面获取想要的资料和信息,并帮助我们进行数据的处理,最终做出最好的投资决策。
2023年3月31日,金融领域的ChatGPT来了,纽约彭博社发布研究报告向我们展示了BloombergGPT,它由7000亿语料库训练,一半来自彭博社自身的3630亿金融数据,另一半则是公共的数据集3450亿,参数为500亿左右,该模型将重塑金融分析师的流程,未来也会上线纽约彭博社的终端为客户提供服务。我们相信未来这样的模型将在各行各业中涌现,不断提高行业的效率,形成更大的生产力。
那么ChatGPT能给我们个人带来怎么样的投资机会或者金融方面的机会呢?在传统的量化投资过程中,你需要懂投资,还要懂代码,不过现在可能就不用较强的代码编写能力了(至少目前是这样,未来可能就完全不用了)。最近就有人用ChatGPT帮助他写出了一个回溯1200%的量化投资策略。首先他在量化交易平台上选择一个已经有投资策略的模型作为基础,然后根据自己的风格让ChatGPT优化该策略模型,其中优化的第一步是只做多头仓位不做空,第二个是调整超买超卖的情况,第三个是调整单笔下注的金额,最后通过回测这个策略从原来的58%飙升到1200%。这个可能就是ChatGPT给量化领域带来的改变,也许他有一定的运气程度,但是我们可以通过这种方式找到一个更好的交易策略,而且可能通过完全零代码的方式完成,这将带来极大的便利。
BloombergGPT
没有开放,据说内侧很垃圾
ChatGPT 出现之前是有多少人工就有多少智能,而这之后变成了有多少数据就有多少智能。
https://zhuanlan.zhihu.com/p/620141581
以数据为中心的 FinGPT:开放金融的开源。
https://github.com/AI4Finance-Foundation/FinGPT
findgpt中文文档
https://ai4finance-foundation.github.io/FinNLP/zh/index_zh/
1).金融是高度动态的。 BloombergGPT 使用金融和一般数据源的混合数据集重新训练LLM,这太昂贵了(1.3M GPU小时,成本约为500万美元)。每月或每周重新训练LLM模型的成本很高,因此轻量级适应在金融中非常有利。
2). 使互联网规模的财务数据民主化至关重要,这应该允许使用自动数据管理管道及时更新(每月或每周更新)。但是,BloombergGPT具有特权的数据访问和API。
3). 关键技术是“RLHF(从人类反馈中强化学习)”,这是彭博GPT中缺少的。RLHF使LLM模型能够学习个人偏好(风险厌恶水平,投资习惯,个性化机器人顾问等),这是ChatGPT和GPT4的“秘密”梯度。

自然语言转化为标准化数据库检索语言的接口。这个东西如果只是用在客户端,作为一个小助手就太可惜了!!可以把带有时间戳的语料,通过这个接口都翻译成历史数据,然后进行建模运算,得到量化模型。
AI需求
咨询某个币的投资价值
Question模式案例:
XYZ能不能买?
XYZ怎么样?
XYZ如何?
XYZ
XYZ好不好
咨询某个币的最新动态
Question模式案例:
XYZ咋了
XYZ这是咋了
XYZ为啥涨
XYZ为啥跌
XYZ最近有没有利好
XYZ有没有利好
咨询现在的投资机会
Question模式案例:
哪些币可以买?
梭哪个?
近期有哪些投资机会?
有哪些DEFI项目可以投资?
给我推荐一个arb生态的币
咨询个人投资处境
Question模式案例:
买了XYZ被套了怎么办
$1.25买了XYZ被套了怎么办
$1.25开多XYZ被套了怎么办
$26000做空了BTC怎么办
去年3月买了FIL,要不要出
查询合约安全性
直接复制一个合约地址抛过来
0x09e18590e8f76b6cf471b3cd75fe1a1a9d2b2c2b
或者有些文字
AIDOGE在ARB链的合约:0x09e18590e8f76b6cf471b3cd75fe1a1a9d2b2c2b
咨询币圈知识
Question模式案例:
aidog有合约吗?在什么链上可以交易呢?
香港板块有哪些币?
ZKS是不是ZK板块的?
Rollup有哪些方案?
brc20是什么鬼?
dex的成交量排行
cex的成交量排行
defi的TVL排行
最近有哪些Defi的TVL大涨的?
ARB的交易所有哪些?
波场的生态项目有哪些?
咨询APP下载和注册
TP钱包安装链接发一下
币安注册链接发一下
咨询入门/教程知识
怎么入金
怎么把人民币变成U
U怎么变现
如何防止被冻卡
TP钱包怎么用
Telegram怎么登录不上去
怎么翻墙
币安打不开了怎么办
#文本摘要
5月底实现这一点:
第一步:
问某个币,我们不直接给他结论说如何
而是把现有资料给他提取出来,附带核心点评给他看
只要实现现有功能就行了,不需要太智能
这是第一步
6月份实现这一点:
第一步走通了,我们再结合量化,和链上数据分析,给他一个投资决策结论
并且通过人工结合给他一个答案
如果输入一个0x开头的类合约地址,我们可以做合约查询,给安全性建议
如果输入的是一个钱包地址,那么我们就高速他里面有哪些币,往深度去看再做链上数据分析
未来有哪些大事件有风险
假如查询到的币没有收录,就问他对这个币有啥看法,相当于我们收录材料了
其他:
分析你交易所的订单,给改进建议
K线培训等
14000聪是多少钱
https://github.com/coderabbit214/bibliothecarius
https://zhuanlan.zhihu.com/p/613155165?utm_id=0
先检索再整合的逻辑

https://mp.weixin.qq.com/s/HltapKlbFPfTmuERCDiA9A
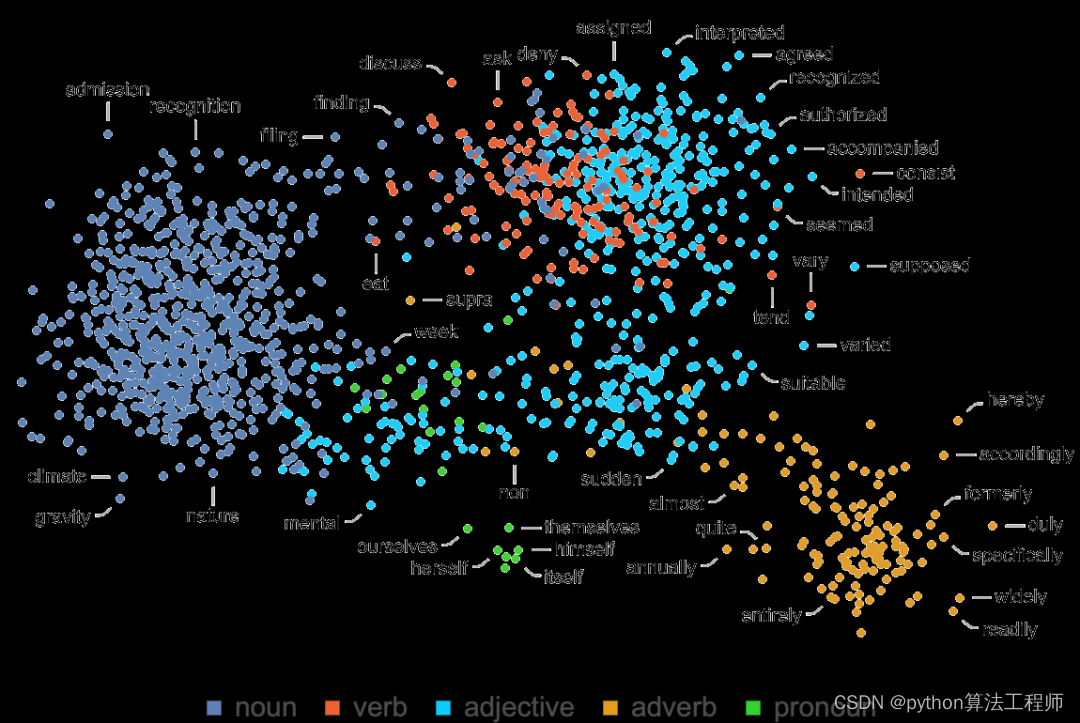
一个特征空间投射到二维空间,单个词(这里是指普通名词)是如何布局的:
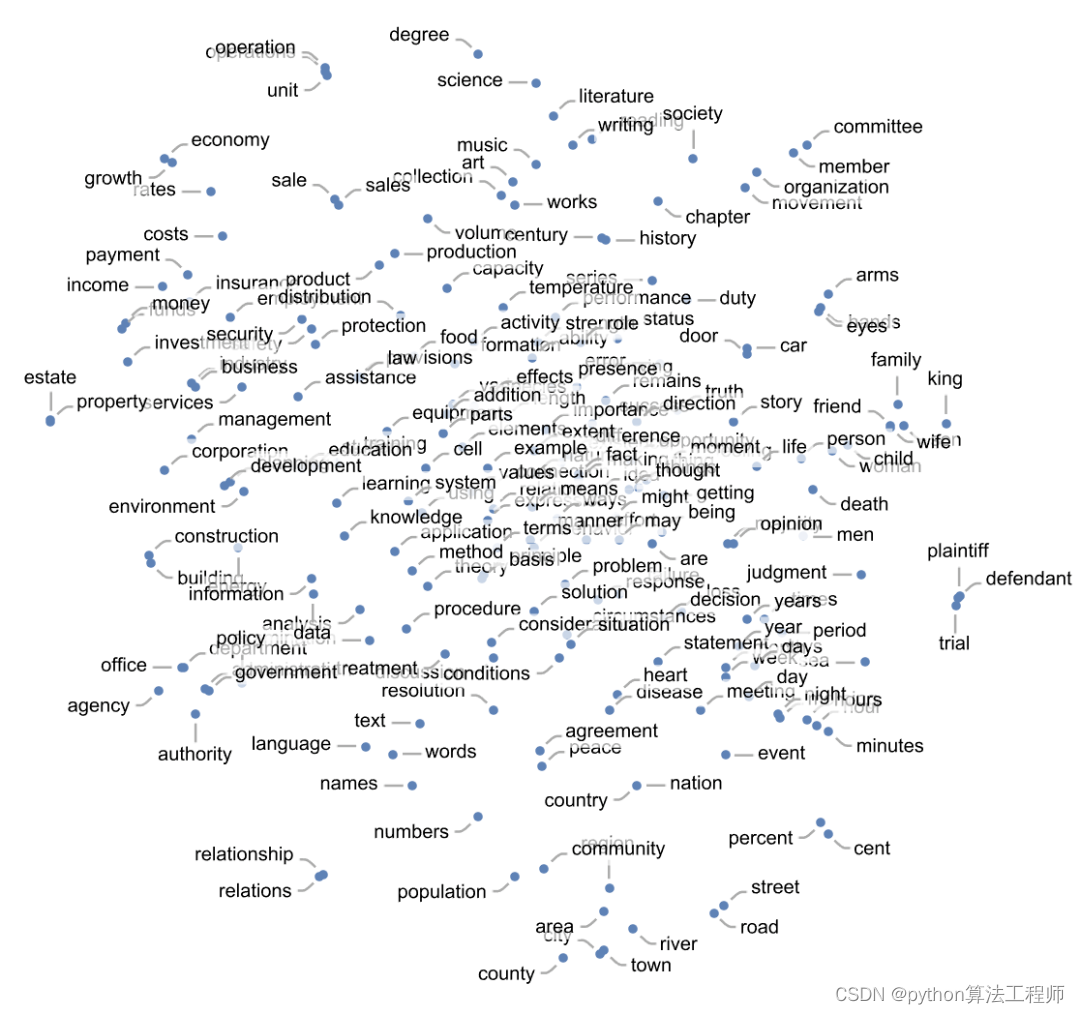
这里是对应于不同语音部分的词是如何布置的:
我们可以看看 ChatGPT 的提示在特征空间中的轨迹 —— 然后我们可以看看 ChatGPT 是如何延续这个轨迹的: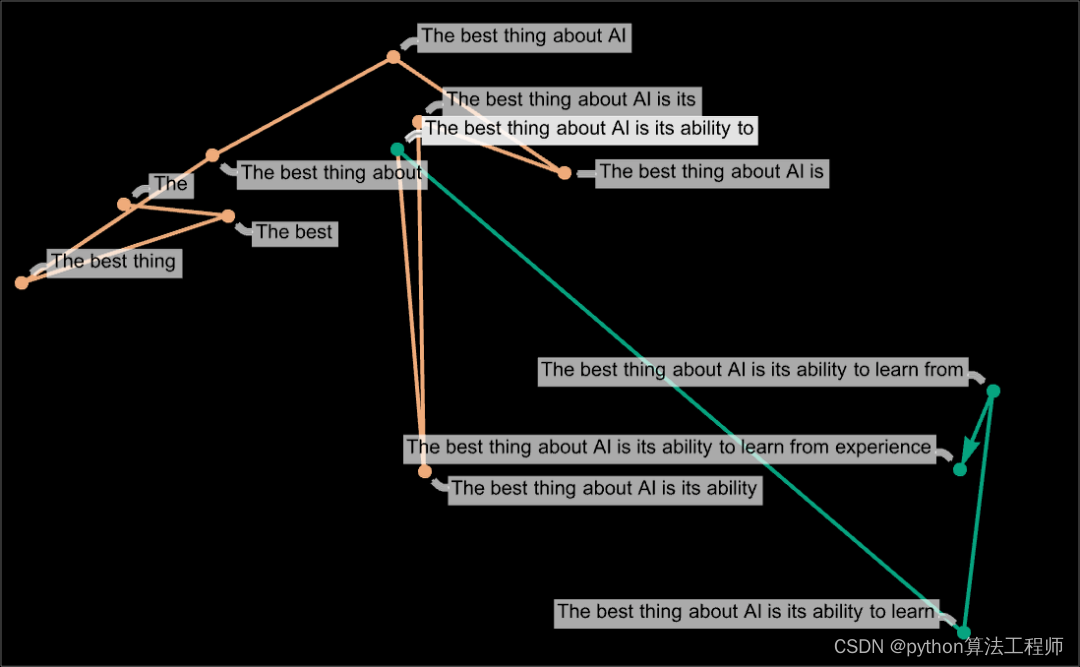
在这种情况下,我们看到的是有一个高概率词的 “扇形”,似乎在特征空间中或多或少有一个明确的方向。如果我们再往前走会怎么样呢?下面是我们沿着轨迹 “移动” 时出现的连续的 “扇形”:
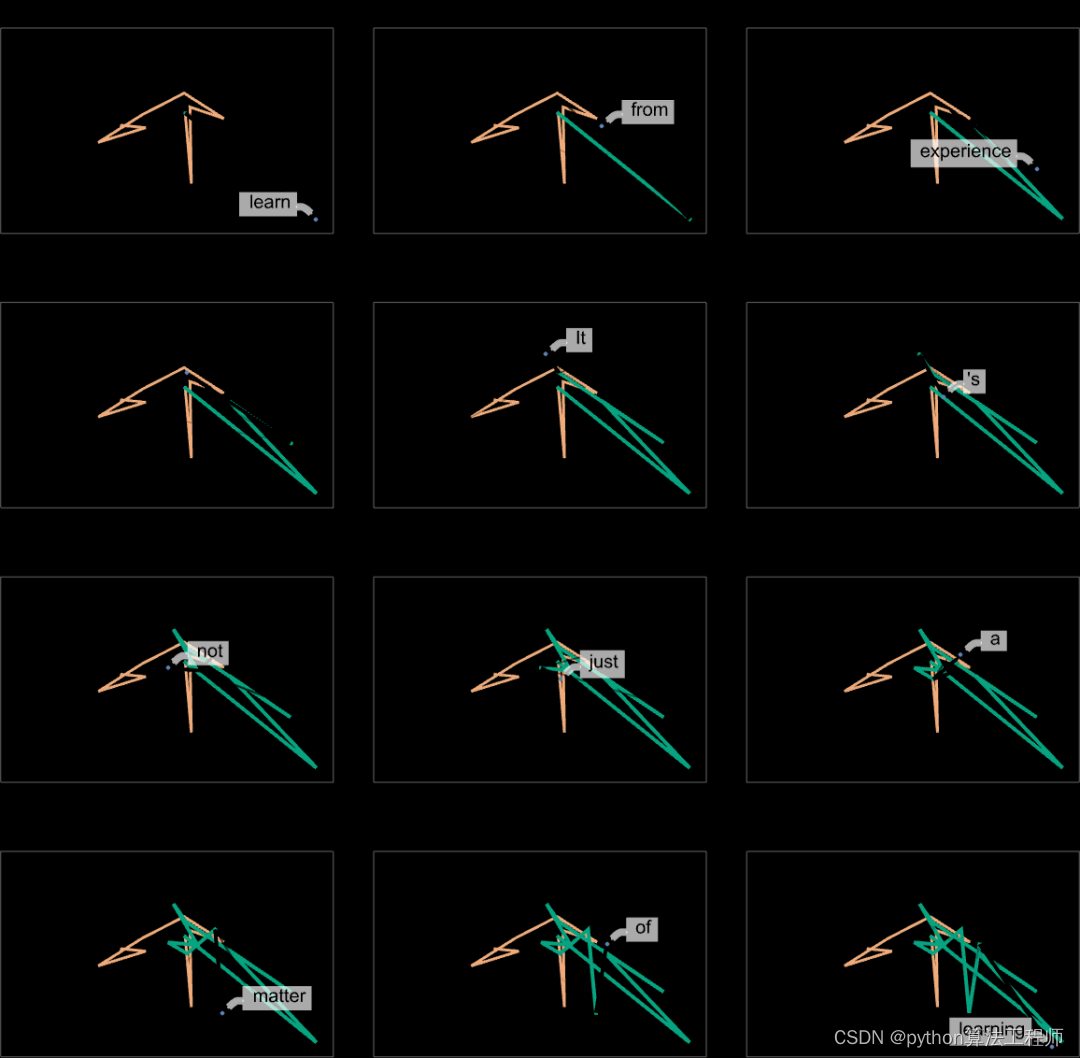
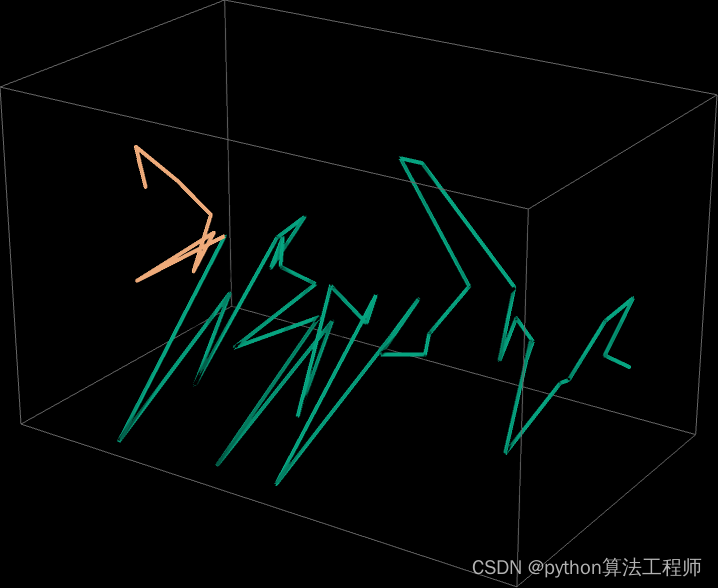
这是一个三维表示,总共走了 40 步:
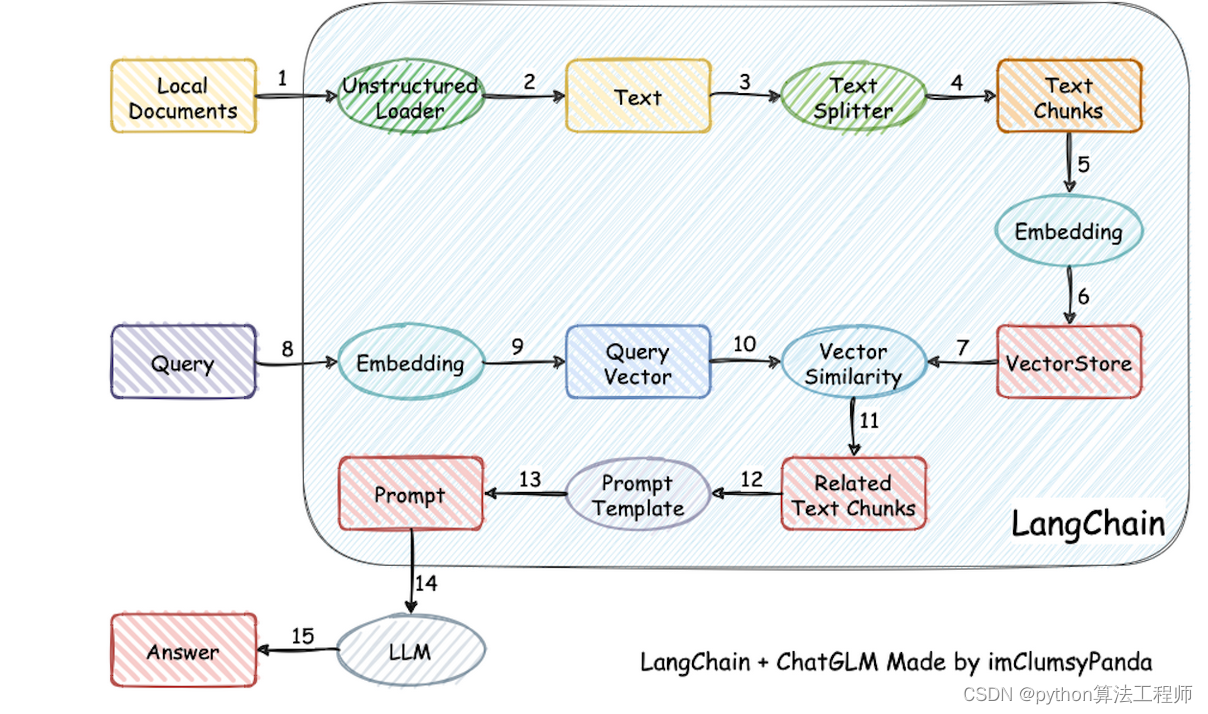
 知识库模式,将用户输入的问题与知识库内的的数据做匹配,一起发送给模型
知识库模式,将用户输入的问题与知识库内的的数据做匹配,一起发送给模型
模型可以参考知识库,更好的回答用户的问题
https://www.bilibili.com/video/BV1Ah4115719/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
https://github.com/nftblackmagic/flask-langchain

1、项目Git:github.com/BlinkDL/ChatRWKV
2、中文在线:modelscope.cn/studios/BlinkDL/RWKV-CHN/summary/
3、Raven英语14B在线:huggingface.co/spaces/BlinkDL/ChatRWKV-gradio
4、ChatRWKV LoRA微调:github.com/Blealtan/RWKV-LM-LoRA
5、ChatRWKV C++:github.com/harrisonvanderbyl/rwkv-cpp-cuda
6、Wenda:github.com/l15y/wenda
7、模型量化:Use v2/convert_model.py to convert a model for a strategy, for faster loading & saves CPU RAM.
8、作者给出的中文教程:zhuanlan.zhihu.com/p/618011122
9、1.5GB显存部署14B模型:zhuanlan.zhihu.com/p/616986651
minigpt4
https://github.com/Vision-CAIR/MiniGPT-4
百度:https://pan.baidu.com/s/1CgeBnGeDnvPapRgp0oeu2A?pwd=x3y8
夸克:https://pan.quark.cn/s/fd22e7b50d0e
使用指南:https://www.bilibili.com/read/cv23409525
13B使用指南: https://www.bilibili.com/read/cv23447361
大模型时代的科研基础之:Prompt Engineering
https://www.bilibili.com/video/BV13P41197c6/?spm_id_from=333.1007.tianma.2-1-4.click&vd_source=569ef4f891360f2119ace98abae09f3f
 https://www.jianguoyun.com/p/DWkpMRoQjKnsBRiUgIgFIAA
https://www.jianguoyun.com/p/DWkpMRoQjKnsBRiUgIgFIAA
技术动态 | 再谈知识图谱与ChatGPT如何结合:参数化与形式化知识库的现实问题、结合要素和具体路线…
https://blog.csdn.net/TgqDT3gGaMdkHasLZv/article/details/130211938
【喂饭教程】闻达利用chatglm模型调用本地知识库及自动写论文教程


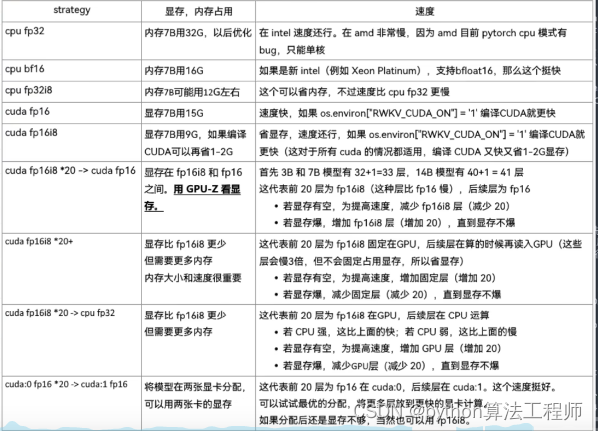
 rwkv加速
rwkv加速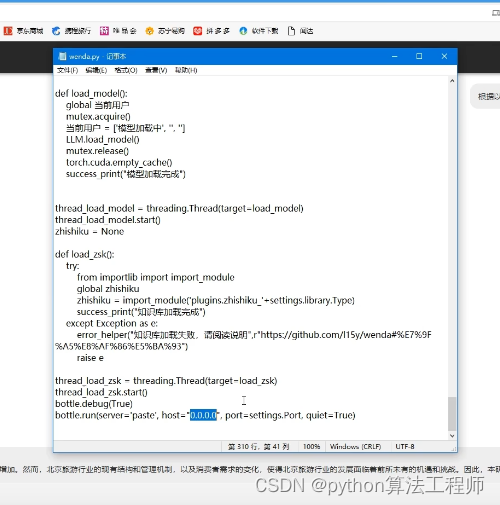
闻达可选功能更多一点,而且大多是开箱即用
gpt+redis
https://github.com/c121914yu/FastGPT
http://hoppinzq.com/chat/index.html
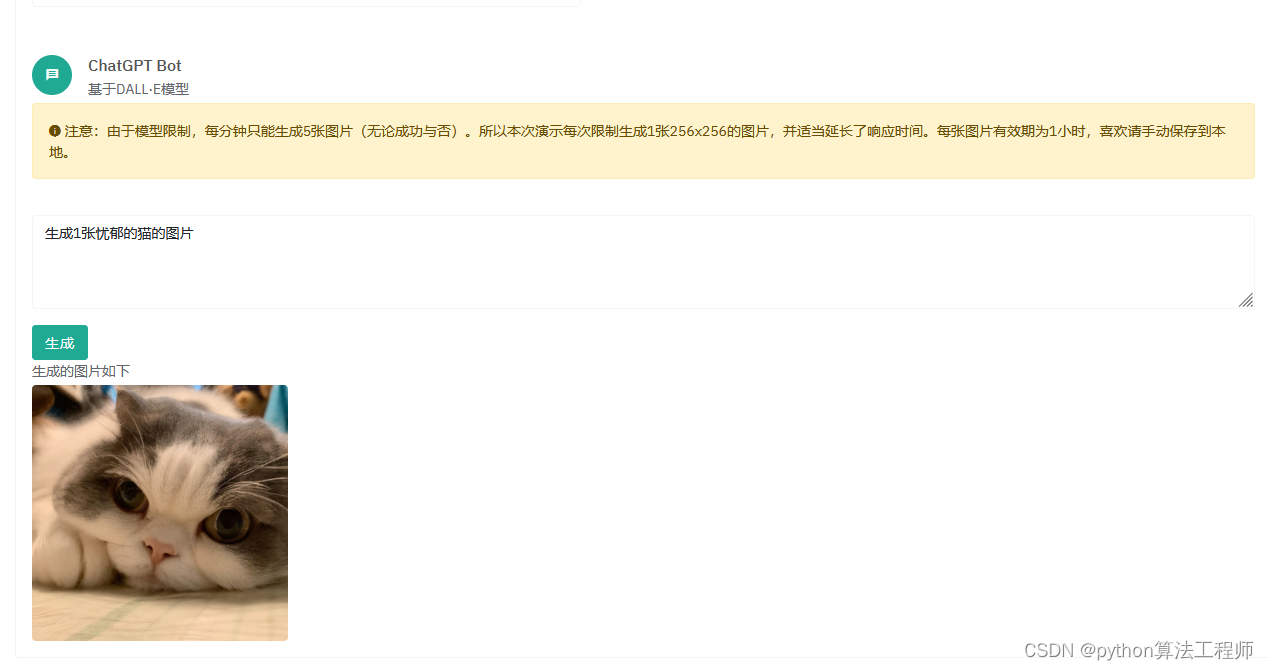
chatGPT的使用
http://hoppin.cn/blog/436946891859607550
wenda如何接入sd
ML 2016 15:04:11
连接SD API失败,请确认已开启agents库,并将SD API地址设置为127.0.0.1:786
半个读书人 15:14:11
我的也是这样
feiil 15:28:58
有两种方法: 第一就是把SD的API改成127.0.0.1:786(默认的是127.0.0.1:7860) 第二:把闻达里面的zhishiku_agents.py 里面的 127.0.0.1:786 改成127.0.0.1:7860
feiil 15:29:32
zhishiku_agents.py 在wenda\plugins里
feiil 15:29:45
SD要部署在本地
半个读书人 15:29:49
明白了
feiil 15:30:17
SD可以去b站学习下载,一般用的是一个秋月大佬,一个星空大佬,用他们两人的懒人包
半个读书人 15:30:39
[图片]
https://www.bilibili.com/video/BV1LX4y1C7yv/?spm_id_from=333.1007.tianma.2-1-4.click&vd_source=569ef4f891360f2119ace98abae09f3
wenda最新版本
https://www.bilibili.com/video/BV1Ho4y14779/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f
链接:https://pan.baidu.com/s/19CeY91V4kaM-QZUHpOoBEg
提取码:8def
Wenda更新后比较好用的一版进行整合,可用chatglm-6B和RWKV模型,根据电脑配置自选。
RWKV语言模型下载地址 https://huggingface.co/BlinkDL/rwkv-4-raven/tree/main
显存15G+模型位置:path:“model/RWKV-4-Raven-14B-v11x-Eng99%-Other1%-20230501-ctx8192.pth” #14亿参数模型
显存15G+模型参数:strategy: “cuda fp16i8”
显存15G+模型位置:path:“model/RWKV-4-Raven-7B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230430-ctx8192.pth” #7亿参数模型
显存15G+模型位置:path:“model/RWKV-4-Pile-7B-Chn-testNovel-done-ctx2048-20230404.pth” #7亿参数模型小说模型
显存15G+模型参数:strategy: “cuda fp16”
显存8G+模型位置:path:“model/RWKV-4-Raven-7B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230430-ctx8192.pth” #7亿参数模型
显存8G+模型位置:path:“model/RWKV-4-Pile-7B-Chn-testNovel-done-ctx2048-20230404.pth” #7亿参数模型小说模型
显存8G+模型参数:strategy: “cuda fp16i8”
显存7G+模型位置:path:“model/RWKV-4-Raven-3B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230429-ctx4096.pth” #3亿参数模型
显存7G+模型参数:strategy: “cuda fp16”
显存4G模型位置:path:“model/RWKV-4-Raven-3B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230429-ctx4096.pth” #3亿参数模型
显存4G模型参数:strategy: “cuda fp16i8”
显存1.5G模型位置:path:“model/RWKV-4-Raven-3B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230429-ctx4096.pth” #3亿参数模型
运行模型参数:strategy: “cuda fp16i8 *0+ -> cpu fp32 *1” #需要有32G内存
显存1.5G模型位置:path:“model/RWKV-4-Raven-3B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230429-ctx4096.pth” #3亿参数模型
运行模型参数:strategy: “cuda fp16 *0+ -> cpu fp32 *1” #需要有24G内存
显存1.5G模型位置:path:“model/RWKV-4-Raven-3B-v11-Eng49%-Chn49%-Jpn1%-Other1%-20230429-ctx4096.pth” #3亿参数模型
运行模型参数:strategy: “cuda fp16i8 *0+ -> cpu fp32 *1” #需要有20G内存
【envplus】全集成环境,支持glm、ptuning、lora、SD、so-vits、wenda、EasyVtuber
网盘链接:https://pan.baidu.com/s/1fO1mLtnwuX8NrQ-_Jri00w?pwd=i7vb
特别鸣谢:秋葉aaaki、Lemon_x64_Win11、yuyuyzl、Paper朱、天宫扣扣肉Official、领航员未鸟、羽毛布団、平沢゛唯、mymusise、ChatGLM开源社区、wenda开源社区、so-vits开源社区、text-generation-webui开源社区
ChatGLM(lora):https://www.bilibili.com/video/BV1P24y1L7Ge
ChatGLM(PTuning):https://www.bilibili.com/video/BV1jN411w7o1
sovits+chatglm :https://www.bilibili.com/video/BV1w24y1j7eE
GLM+SD :https://www.bilibili.com/video/BV1Wa4y1V77o
so-vits 4.0 :https://www.bilibili.com/video/BV13X4y1Z7wP
wenda :https://www.bilibili.com/video/BV1Wo4y1b7QD
EasyVtuber :https://www.bilibili.com/video/BV1BM411T7ry
问答对的知识库是最精准的
RWKV-Runner发布并开源,可商用的大语言模型,一键启动管理,2-32G显存适配,API兼容,一切前端皆可用
开源仓库地址:https://github.com/josStorer/RWKV-Runner
下载地址(RWKV目录):https://pan.baidu.com/s/1wchIUHgne3gncIiLIeKBEQ?pwd=1111
RWKV官方仓库:https://github.com/BlinkDL/RWKV-LM
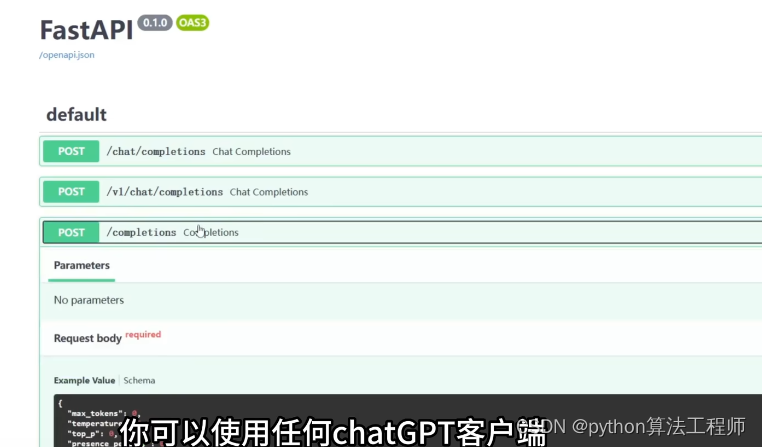 支持fastapi
支持fastapi
【活学活用】挑战wenda(闻达)一键包制作
闻达github仓库:https://github.com/l15y/wenda
一键包的脚本资料:https://pan.baidu.com/s/15vTqkT-u4hJZ68B53KcGxg?pwd=fjmu
一键包制作教程:https://www.bilibili.com/video/BV1yM41157KU
stable diffusion模拟实际项目流程
stable diffusion在实际游戏场景设计工作流程中的应用,总结了一些用法和小技巧,我对sd态度是:多用其所长。设计始终还是要由人来做的,ai只是一个辅助工具。
QQ群:828106743
视频中的图&文&模型:
链接:https://pan.baidu.com/s/1Expu1s-FK8rc7gZJ1wIyug?pwd=orji 提取码:orji
秋叶 SD v4 整合包:(非常感谢秋叶大佬,功德无量)
链接:https://pan.baidu.com/s/1a0aCc9yspc6C_CyQ0Gn1LQ?pwd=cq0t 提取码:cq0t
controlnet 1.1 模型文件下载与各文件放置位置:
链接:https://pan.baidu.com/s/1P52oIpwV8Prj_liN63qoSA?pwd=peag 提取码:peag
claude
https://zhuanlan.zhihu.com/p/623080780

 在这里插入图片描述
在这里插入图片描述
wenda如何接入其他模型
用爬虫更新知识库,理论可行
识别pdf,目前还未开发
autogpt,给定一个具体的任务,让模型根据爬虫获取到的信息做判断
舆情监测 用户情感 市场情绪分析
【AI绘画】LoRA训练与正则化的真相:Dreambooth底层原理
https://www.bilibili.com/read/cv22578510
需求变更 openai插件
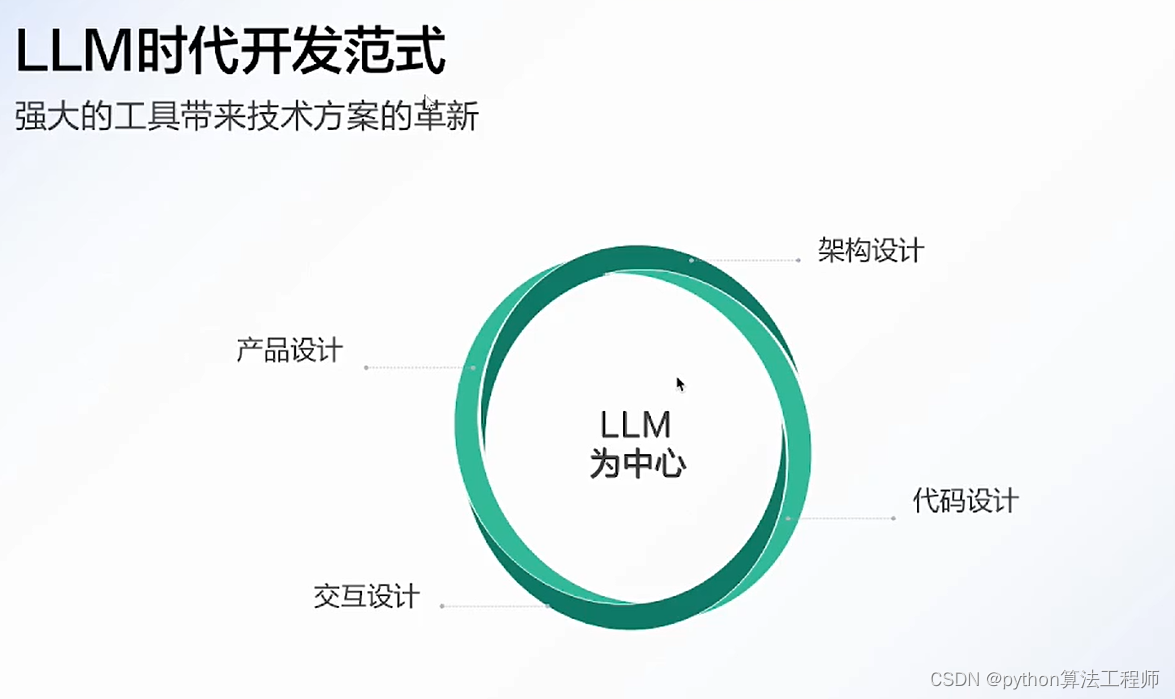
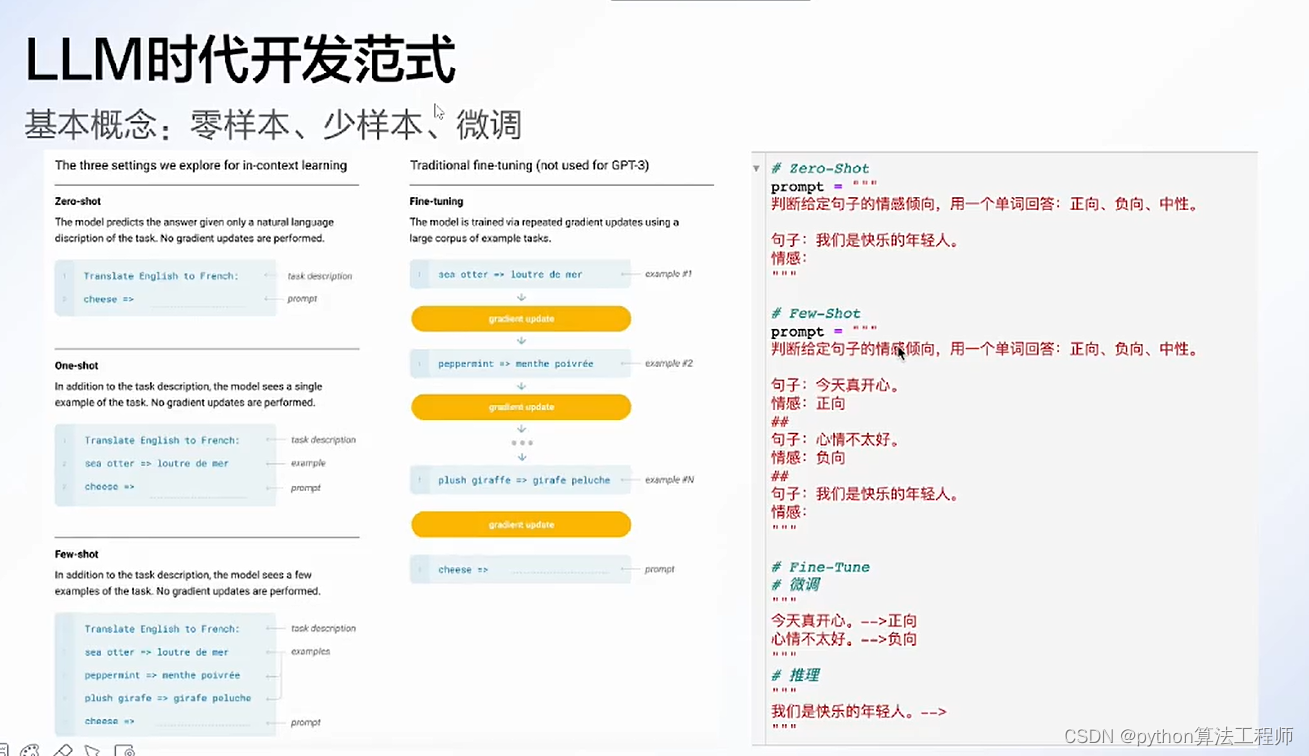
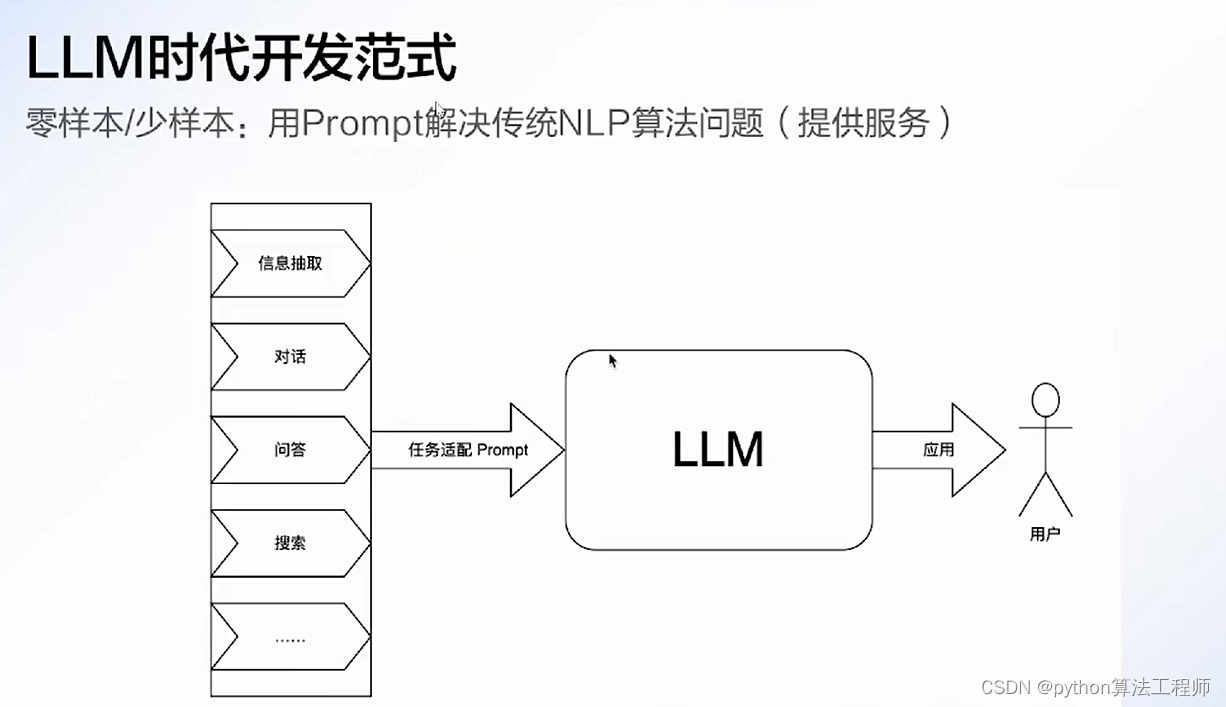
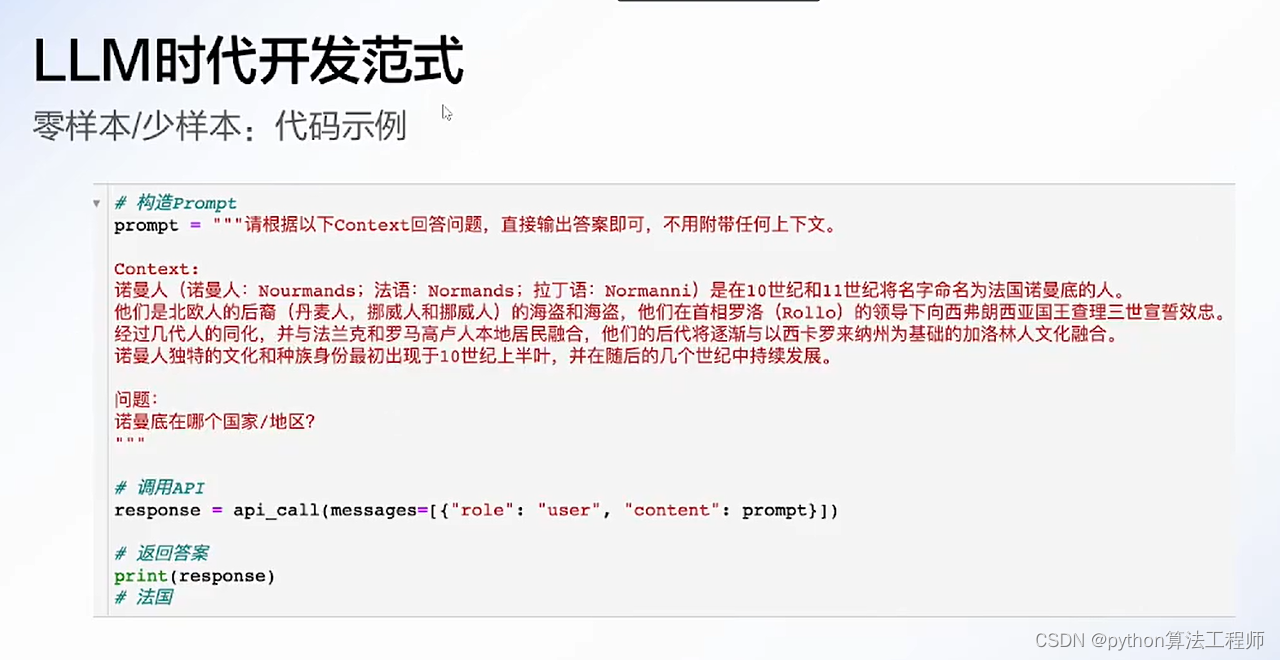
大模型应用开发技巧与实战








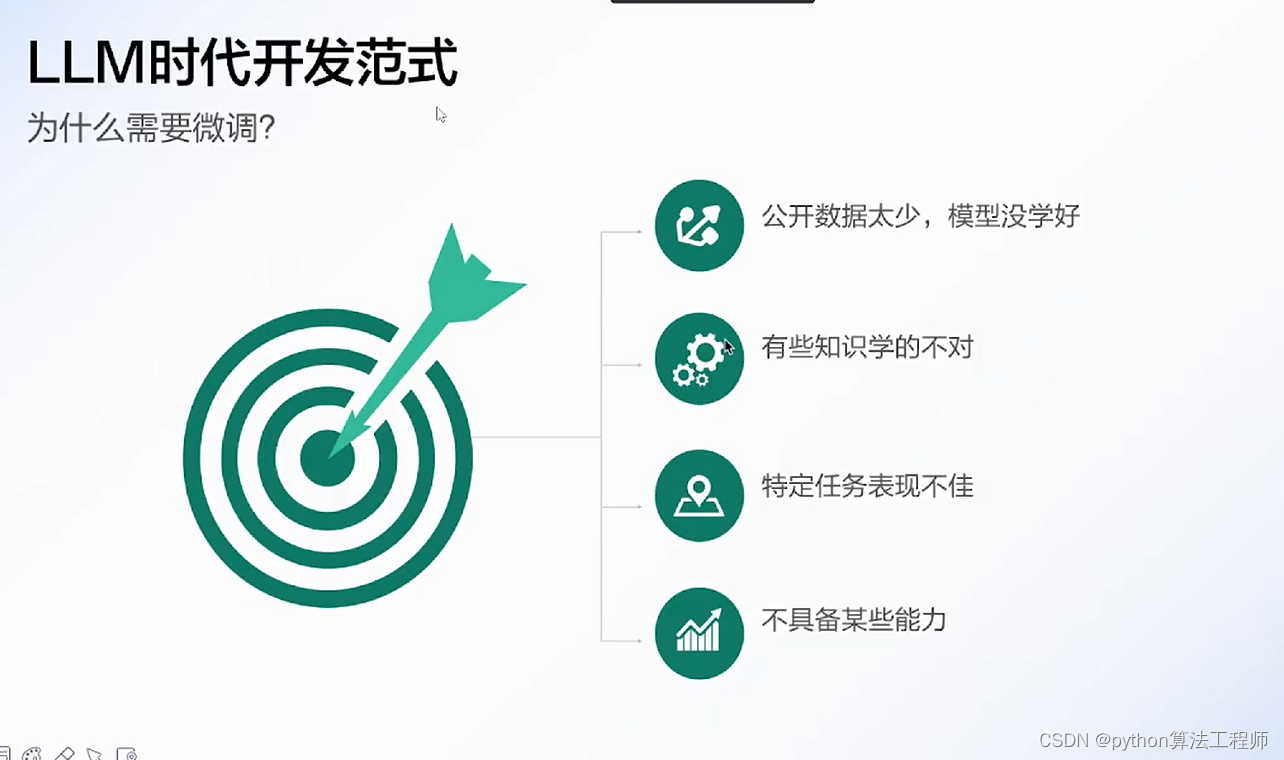


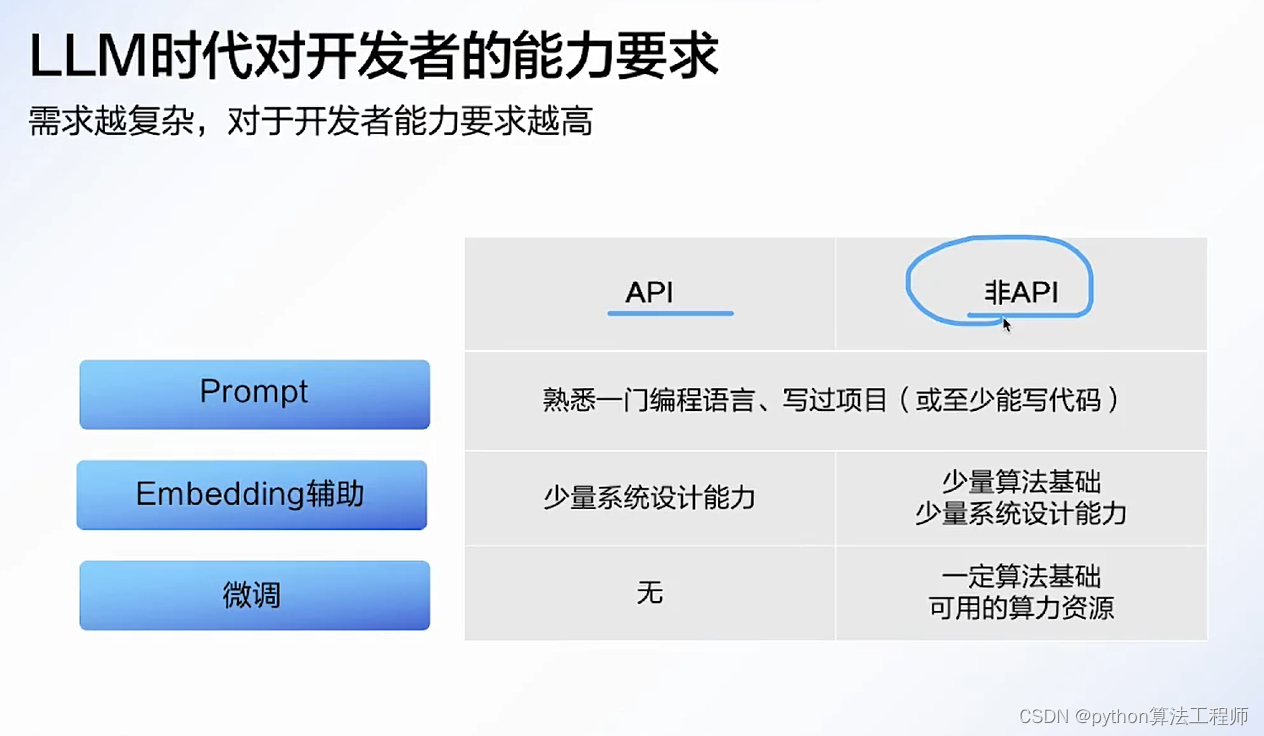









一个人去看LOL世界总决赛(过少的数据集),他非常认真的看,记录了职业选手的每一个细节(试图拟合所有数据),然后反复研究(训练),最后总结出来了一套方案(模型)。
结果他用这套方案去打排位,结果打得非常死板,出装只会一套,打法也只会一种(过拟合)。
以上我们得知,过拟合就是对少年数据的过度模仿,的导致得出的结论没办法灵活运用的情况。
那我们要怎么解决这种情况呢?
假设我们最终的目的是要上分,那我们该怎么学呢1.搞清楚什么东西是没必要学的(减少特征)
有些东西对于上分是没帮助或者说帮助极小的,比如怎么做大笑动作嘲讽对手,亮狗牌嘲讽,这就不用学了。(某些特征对模型训练并不会有帮助,强行要拟合所有特征,会增加模型的复杂度)
2.多看比赛,而不只是只看一场(增大训练量)
看职业玩家在各种情况下。面对各种对手的操作(大量的数据集),最终研究出一个适用性广的打法。
3.不用整场比赛都看完(提前结束)
看到拿巴龙,四条或龙魂加上远古巨龙,就可以不用看后面的了(足够准确),因为后面的操作已经不会对战局有什么影响了,继续看的话,可能还会看到优势太大浪输了。
4.挑有用的来学(正则化)
学怎么控线,学大局意识的培养。丝血反杀,极限操作就不要花太多精力学了,可能弄巧成拙(降低部分特征的权重,L1正则最低可以降低到0)
https://chat.juicebox.work/project/lIrjr6lje9Z9BHAQdEiJ

微软开源Copilot Chat:新增数据导入!可打造专属ChatGPT
https://redian.news/wxnews/353910
https://devblogs.microsoft.com/semantic-kernel/announcing-copilot-chat/
https://moyincloud.com/article/1656237038590087170.html
AI助手工具
-
文本转换成语音 → http://Lovo.ai
-
图片生成→ http://Dreamstudio.ai
-
ChatGPT 提示词 → http://Wnr.ai
-
网站建设 → http://Durable.co
-
会议总结 → http://Tldv.io
-
写推特 → http://Postwise.ai
-
AI社交平台:https://chirper.ai/zh
里面都是AI机器人在发社交Feed
陆奇最新演讲实录:我的大模型世界观
就连陆奇都说他跟不上大模型时代的狂飙速度了。“我实在不行了,论文实在是跟不上,代码实在是跟不上。Just too much(太多了)。”陆奇在近期一次分享活动上说。
https://www.ccvalue.cn/article/1410502.html
https://app.copilothub.ai/home
前沿技术探索
https://donotpay.com
https://www.hippocraticai.com
https://replit.com
https://replicate.com
https://www.chatpdf.com
https://www.baihai.co/studio
https://dashboard.cohere.ai
https://openbayes.com
https://www.pingwest.com/a/282651
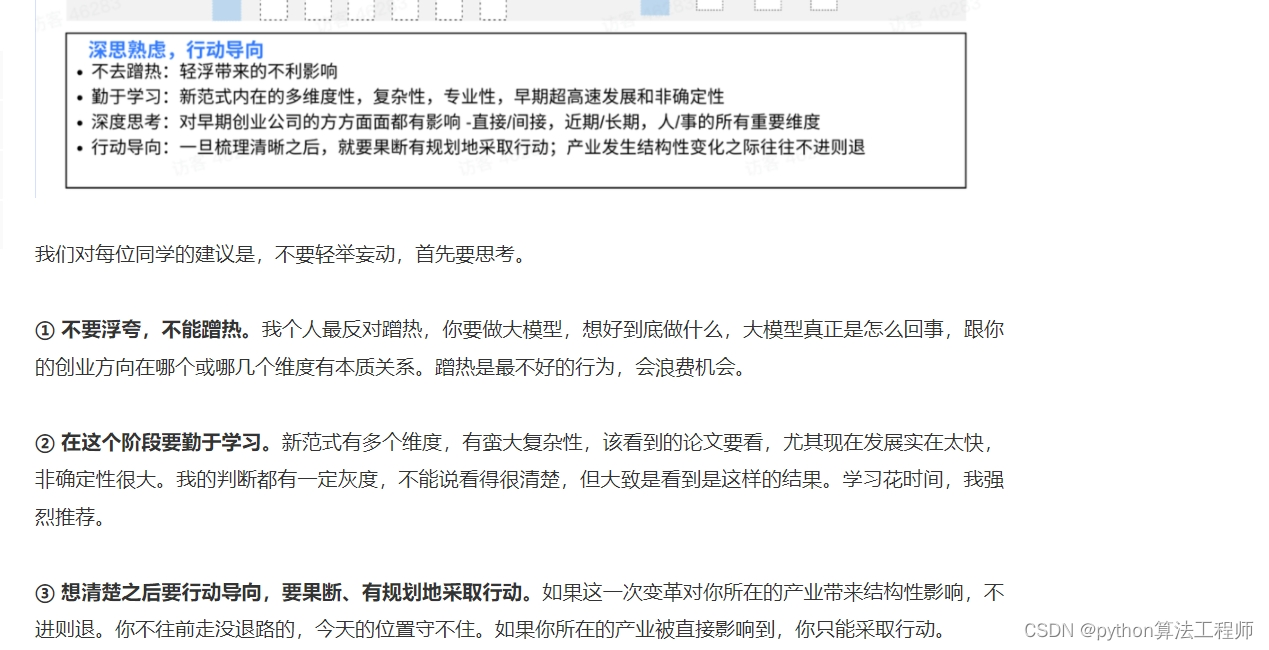
中文医疗大模型的2W1H分析
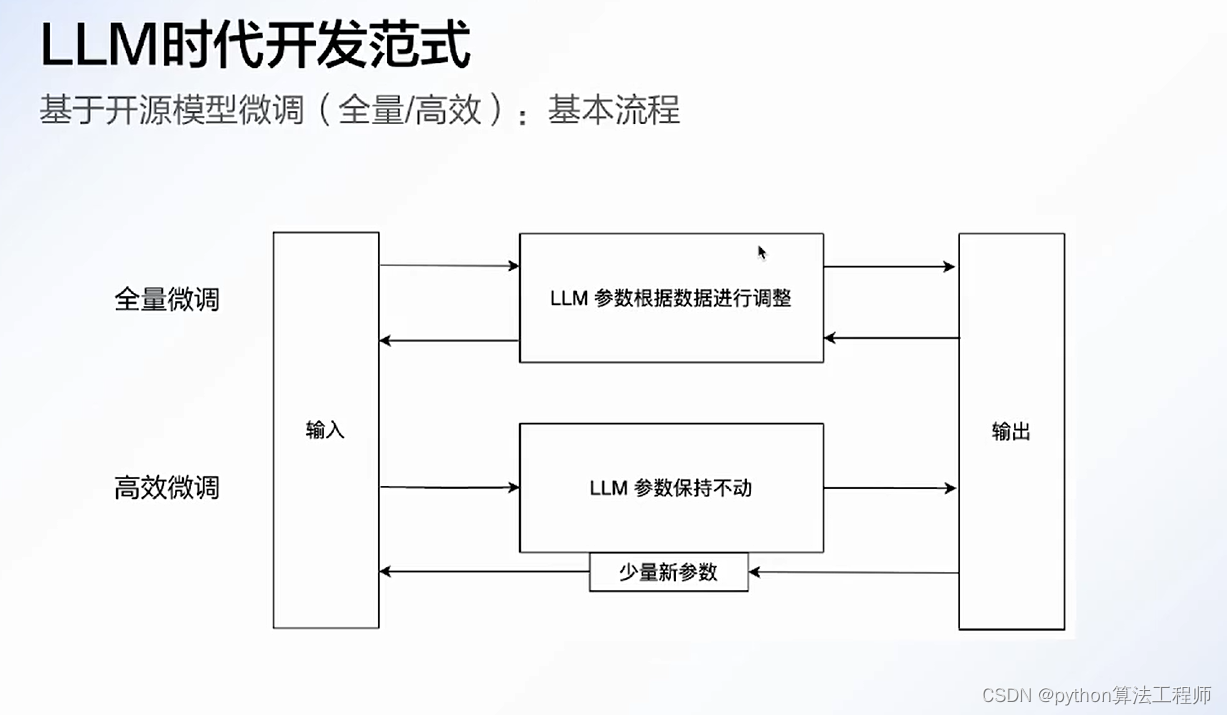
围绕具体任务组件,可能的一种实现是:针对每个任务采用高效微调的方法,在预测时对不同任务调用不同的高效微调模块(比如LoRA等)。
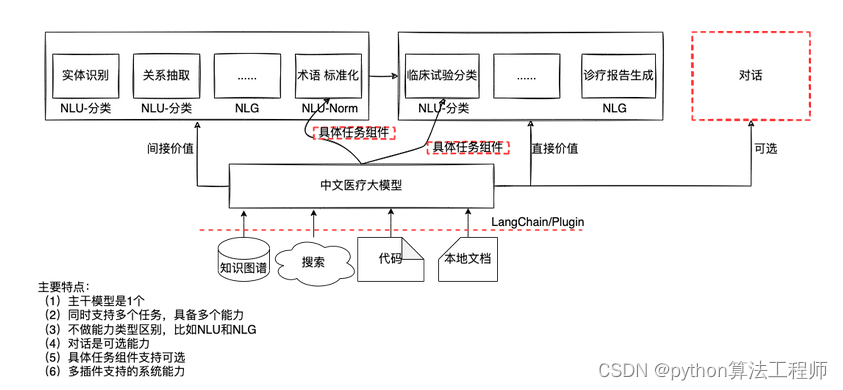 回归价值本身,对于多数场景下,用户更加关心地是问题有没有得到解决,至于解决的方法是不是中文医疗大模型,也许并不重要。在主流叙事的背景下,有了更好,如果没有,理论上问题也不大。但是,对于新问题要得到解决,大概率技术侧还是会落在大模型的方向上。
回归价值本身,对于多数场景下,用户更加关心地是问题有没有得到解决,至于解决的方法是不是中文医疗大模型,也许并不重要。在主流叙事的背景下,有了更好,如果没有,理论上问题也不大。但是,对于新问题要得到解决,大概率技术侧还是会落在大模型的方向上。
 在预测阶段,根据输入,首先会通过检索知识大脑(比如知识图谱)和维基百科,获取相关的知识,之后将相关知识和输入通过构建精巧的Prompt作为模型的输入,返回最终的预测结果。这个阶段和DoctorGLM存在异曲同工之妙。
在预测阶段,根据输入,首先会通过检索知识大脑(比如知识图谱)和维基百科,获取相关的知识,之后将相关知识和输入通过构建精巧的Prompt作为模型的输入,返回最终的预测结果。这个阶段和DoctorGLM存在异曲同工之妙。
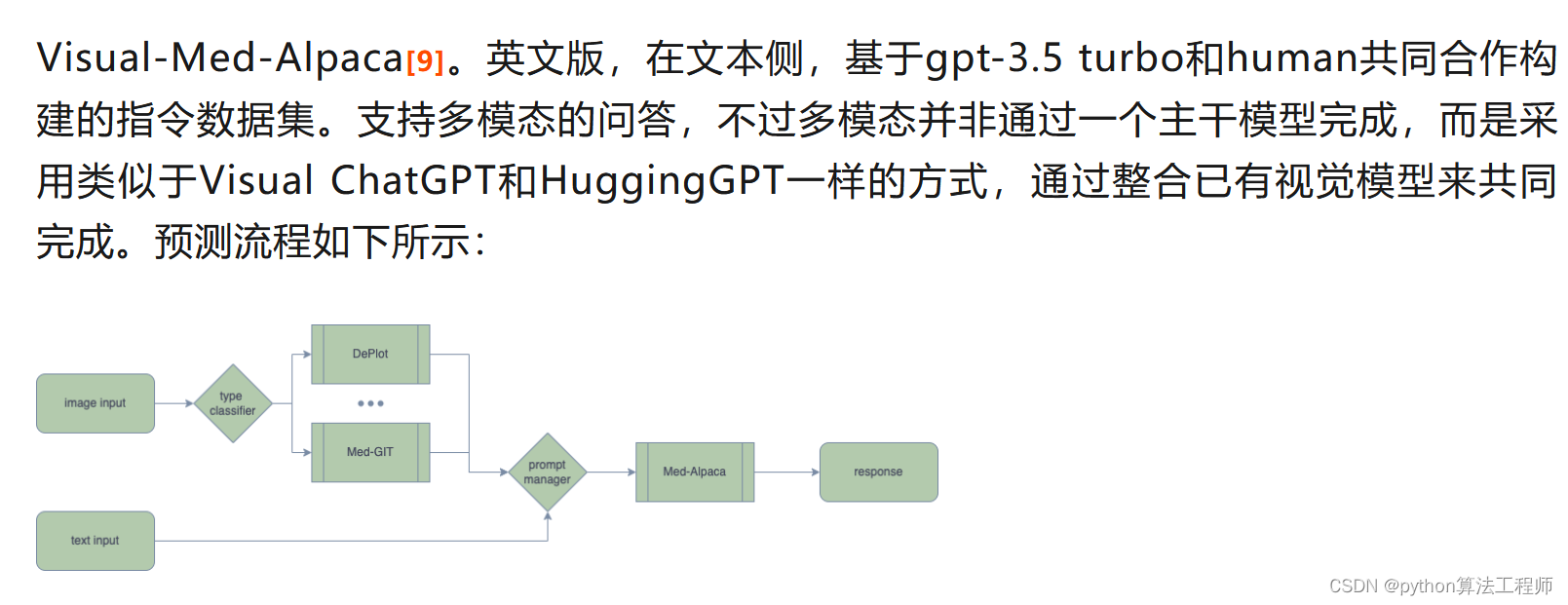

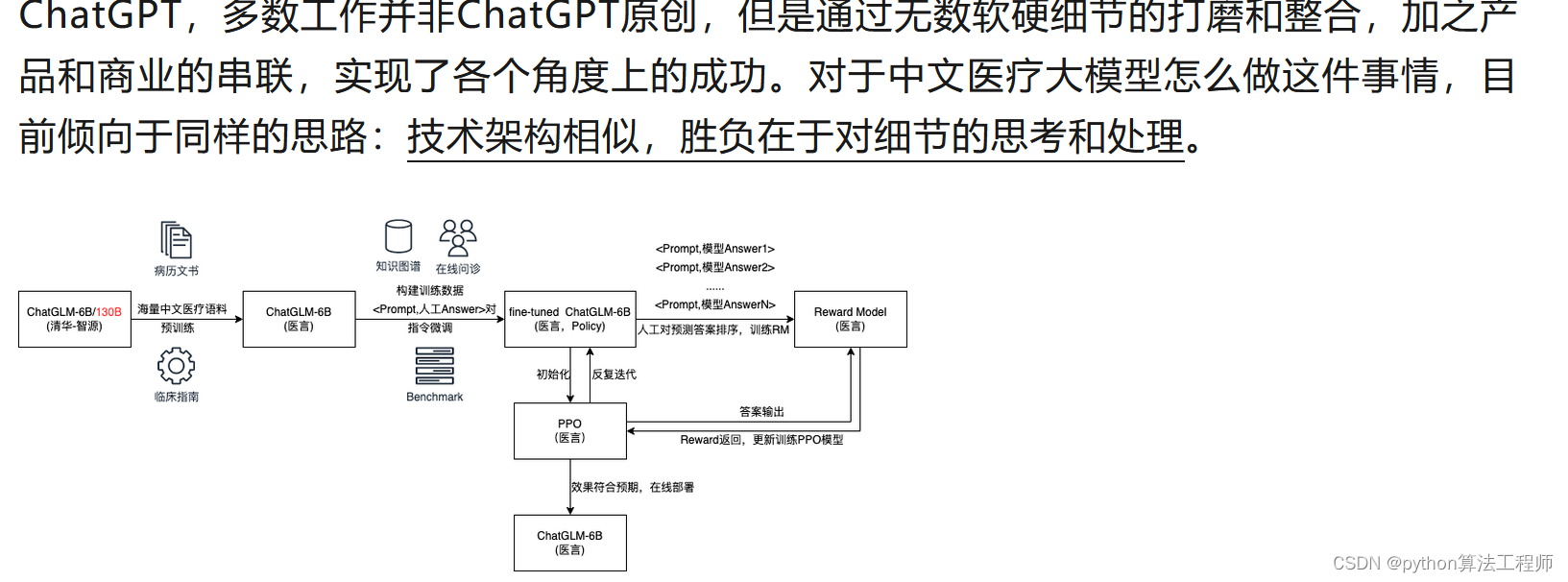 从上图可以看到,整体的流程基本同ChatGPT相似,包含三个阶段,分别是:预训练阶段,指令微调阶段,强化学习阶段。在阶段的优先级选择上,指令微调>预训练>强化学习。从左到右,ROI依次降低。是不是觉得很简单?实则未必。看一下在训练过程中可能需要的问题,如下:
从上图可以看到,整体的流程基本同ChatGPT相似,包含三个阶段,分别是:预训练阶段,指令微调阶段,强化学习阶段。在阶段的优先级选择上,指令微调>预训练>强化学习。从左到右,ROI依次降低。是不是觉得很简单?实则未必。看一下在训练过程中可能需要的问题,如下:
如何构建大模型的评估体系?
预训练和指令微调的数据构建和任务训练的差异性在哪里?
什么时候发生模型记忆性遗忘,如何避免?
模型常见的参数选择策略是什么?
如何实现支持更长上下文,比如32K?
中文词典要不要进行改造,怎么做中文词典扩充与剪裁?
如何做显存占用估计?
如何让模型输出的结果更加地结构化以直接用于应用?
怎么做可以提升模型输出的质量?
多机多卡能跑起来吗?
模型推理的cost是什么?如何实现模型推理加速?
如何降低模型的部署成本?
…
chatgpt插件
https://openai.com/blog/chatgpt-plugins






https://platform.openai.com/docs/api-reference/introduction

疯狂的幻方:一家隐形AI巨头的大模型之路
https://wallstreetcn.com/articles/3689518
RLFH人类反馈强化学习
DeepSpeed Chat

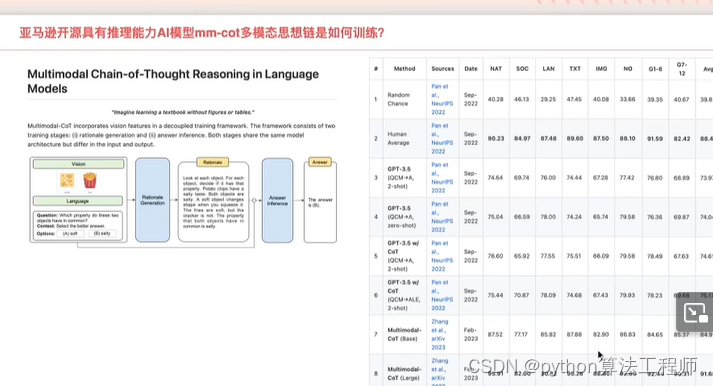
谷歌开源T5 base和large模型上进行MM-CoT模型微调,实现2.2亿参数小模型拥有CoT推理能力,并在科学问答数据集准确率超越人类

 http://e.betheme.net/article/show-1277574.html?action=onClick
http://e.betheme.net/article/show-1277574.html?action=onClick
Segment Anything for Stable Diffusion WebUI安装学习资料
https://www.bilibili.com/video/BV1Vh411F7Zn/?spm_id_from=333.1007.tianma.1-2-2.click
https://dirk3j7xco.feishu.cn/docx/MM2Cdqz6ioU40kxEhURcLMLDn1d
LoRA从原理到实践,零基础打造赛博Coser、一键更换服饰,无所不能!5大应用方向剖析 & 保姆级讲解!Stable Diffusion
你将掌握在StableDiffusion WebUI中利用LoRA出图作画的三种基本途径,并学会利用LoRA实现高度自定义的人物角色形象(Character)、画风或风格(Style)、概念(Concept)、服饰(Cloth/Costume)还有特定元素(Object)呈现。
https://www.bilibili.com/video/BV1nL411B7XT/?spm_id_from=333.1007.tianma.1-2-2.click&vd_source=569ef4f891360f2119ace98abae09f3f
各种lora模型
qat量化
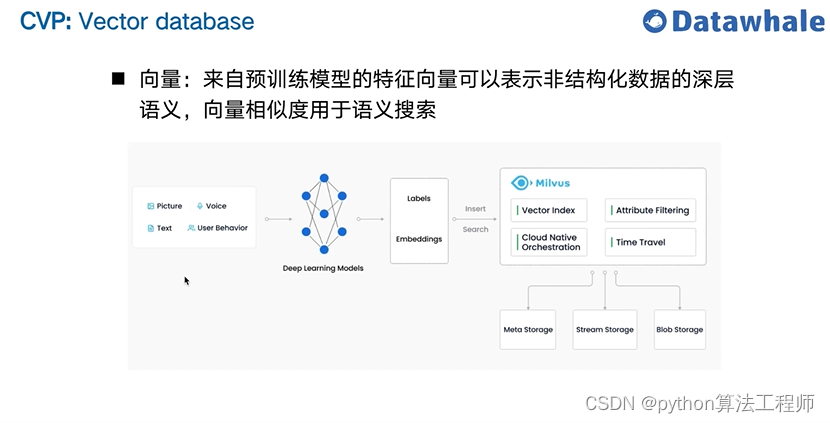
不消耗token的emdeding算法加向量数据库实现关于embeddings:
但是OpenAI的文本嵌入接口对中文的支持并不好,社区经过实践,对中文支持比较好的模型是Hugging face上的 ganymedenil/text2vec-large-chinese。具体可以参见:https://huggingface.co/GanymedeNil/text2vec-large-chinese/discussions/3 ,作者采用的训练数据集是 中文STS-B数据集。它将句子映射到 768 维密集向量空间,可用于任务 如句子嵌入、文本匹配或语义搜索。
https://github.com/shibing624/text2vec/blob/master/README.md
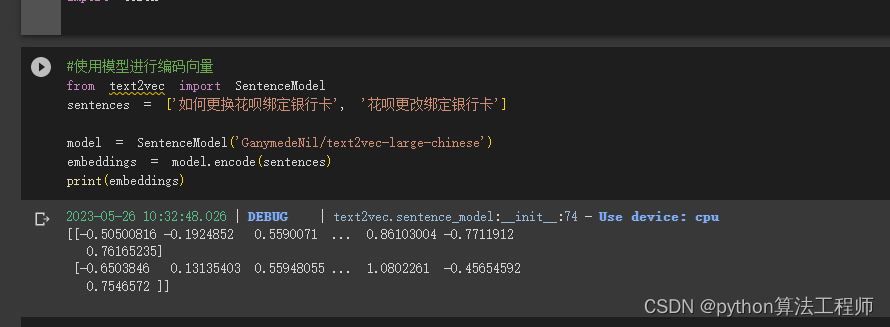 使用cpu进行编码会非常的慢
使用cpu进行编码会非常的慢
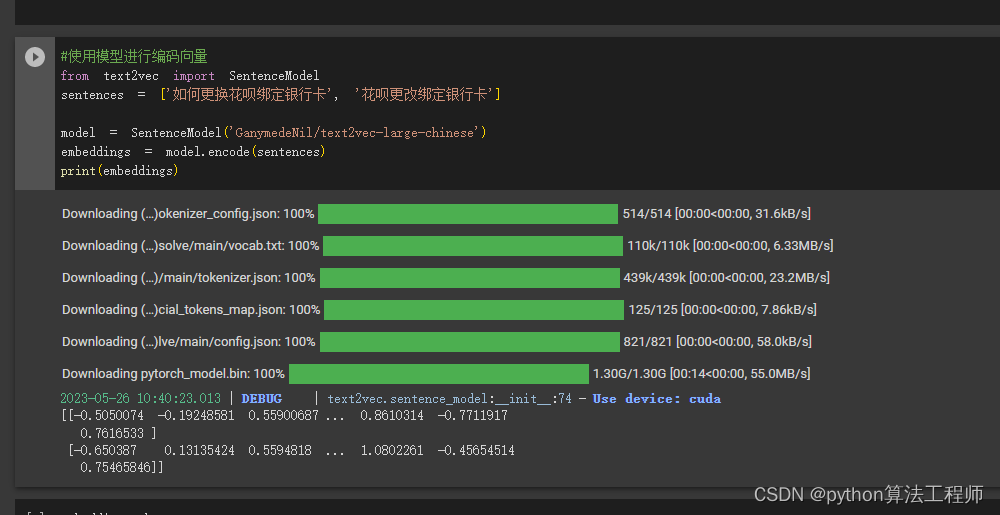 使用gpu进行编码比较快
使用gpu进行编码比较快
!pip install transformers
!pip install text2vec
!pip install pinecone
import pinecone
import pinecone
from text2vec import Similarity
from transformers import AutoTokenizer, AutoModel
import os
import torch
import text2vec
# index_name = 'gpt-4-langchain-docs'
index_name = "text2vec-large-chinese"
# index_name = "langchain-demo"
# initialize connection to pinecone
pinecone.init(
api_key="a18fcdac-a3ab-4755-a87a-352d0ef74ee9", # app.pinecone.io (console)
environment="us-west4-gcp-free" # next to API key in console
)
# check if index already exists (it shouldn't if this is first time)
if index_name not in pinecone.list_indexes():
# if does not exist, create index
pinecone.create_index(
index_name,
# dimension=len(res['data'][0]['embedding']),
len(sentence_embeddings[0]),
metric='dotproduct'
)
# connect to index
index = pinecone.GRPCIndex(index_name)
# view index stats
index.describe_index_stats()
pinecone.list_indexes()
#导入模型
from transformers import AutoTokenizer, AutoModel
import os
import torch
#使用模型进行编码向量
from text2vec import SentenceModel
sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡']
model = SentenceModel('GanymedeNil/text2vec-large-chinese')
embeddings = model.encode(sentences)
print(embeddings)
#没有封装的方法如果没有 text2vec,您可以这样使用模型:
#首先,通过转换器模型传递输入,然后必须在上下文化的单词嵌入之上应用正确的池化操作。
tokenizer = AutoTokenizer.from_pretrained("GanymedeNil/text2vec-large-chinese")
model = AutoModel.from_pretrained("GanymedeNil/text2vec-large-chinese")
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡']
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
index.upsert(vectors=list())
print("Sentence embeddings:")
print(sentence_embeddings)
fastAPI服务
安装: pip install fastapi uvicorn
启动服务:
示例:examples/fastapi_server_demo.py
cd examples
python fastapi_server_demo.py
调用服务:
curl -X ‘GET’
‘http://0.0.0.0:8001/emb?q=hello’
-H ‘accept: application/json’
# -*- coding: utf-8 -*-
"""
@author:XuMing(xuming624@qq.com)
@description:
"""
import time
import sys
sys.path.append('..')
from jina import Client
from docarray import Document
port = 50001
c = Client(port=port)
def jina_post():
r = c.post('/', inputs=[Document(text='如何更换花呗绑定银行卡'), Document(text='花呗更改绑定银行卡')])
return r
def encode(c, sentences):
def gen_docs(sent_list):
for s in sent_list:
if isinstance(s, str):
yield Document(text=s)
r = c.post('/', inputs=gen_docs(sentences), request_size=256)
return r
if __name__ == '__main__':
data = ['如何更换花呗绑定银行卡',
'花呗更改绑定银行卡']
print("data:", data)
r = jina_post()
print(r.embeddings)
print('batch embs:', encode(c, data).embeddings)
num_tokens = sum([len(i) for i in data])
# QPS test
for j in range(9):
tmp = data * (2 ** j)
c_num_tokens = num_tokens * (2 ** j)
start_t = time.time()
r = encode(c, tmp)
if j == 0:
print('batch embs:', r.embeddings)
print('count size:', len(r))
time_t = time.time() - start_t
print('encoding %d sentences, spend %.2fs, %4d samples/s, %6d tokens/s' %
(len(tmp), time_t, int(len(tmp) / time_t), int(c_num_tokens / time_t)))
sadtalker虚拟数字人
https://huggingface.co/spaces/vinthony/SadTalker
在线围观地址:https://reverie.herokuapp.com/arXiv_Demo/#
谢谢大佬的分享:https://github.com/Winfredy/SadTalker
20230409教程更新: https://www.bilibili.com/video/BV1Dc411W7V6/?vd_source=c4fdd4c34625755ad12bd28f277b4099
GPT插件Code Interpreter是真的牛,你不会的他全会,表哥表姐们必看!
chatgpt使用松果做数据增强
https://colab.research.google.com/drive/1rk5PqXNFB0kQoc5gK4qWamoWNHrpLAva#scrollTo=xo9gYhGPr_DQ
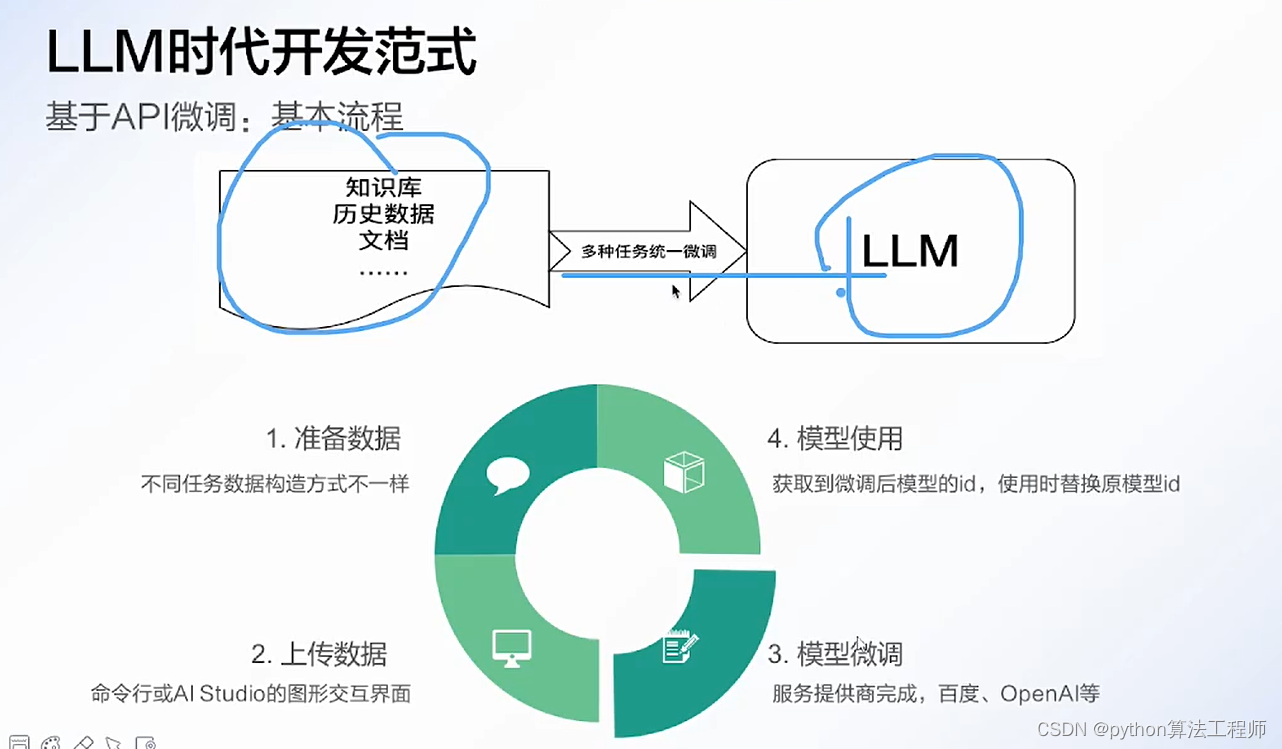
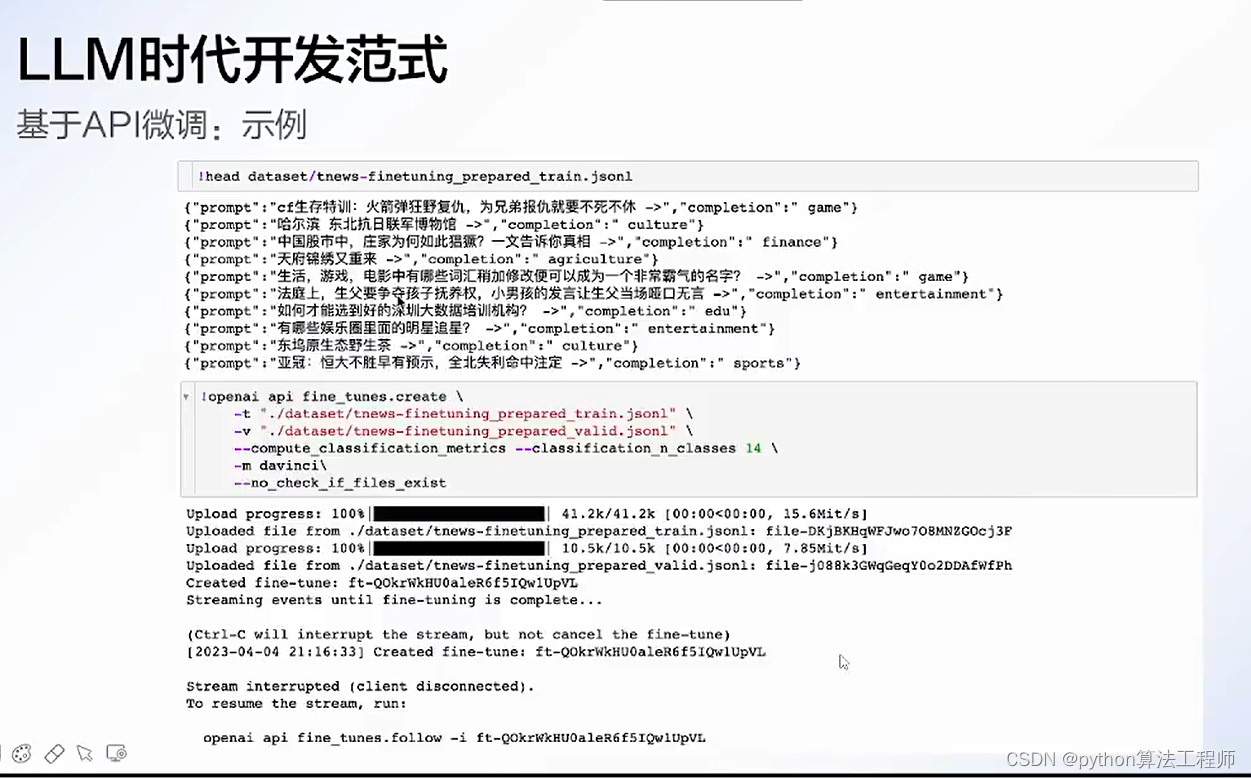
chatgpt微调
https://platform.openai.com/docs/guides/fine-tuning/fine-tuning



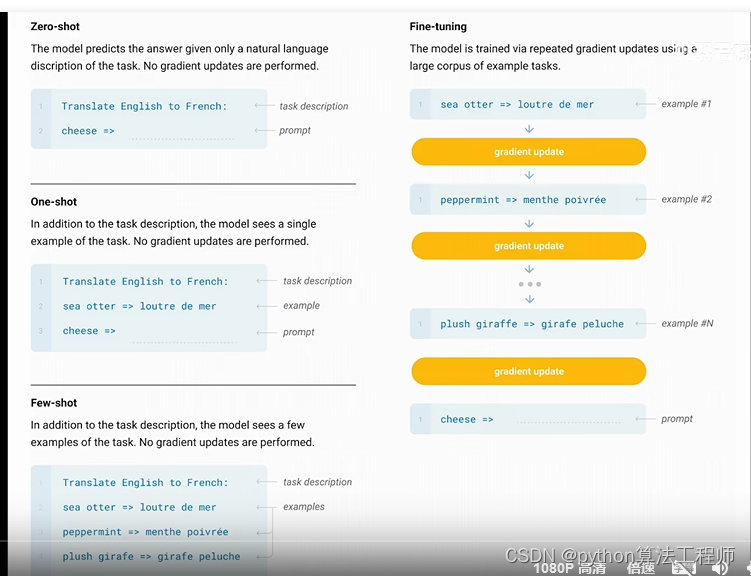
ChatGLM-微调
https://github.com/liucongg/ChatGLM-Finetuning
https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
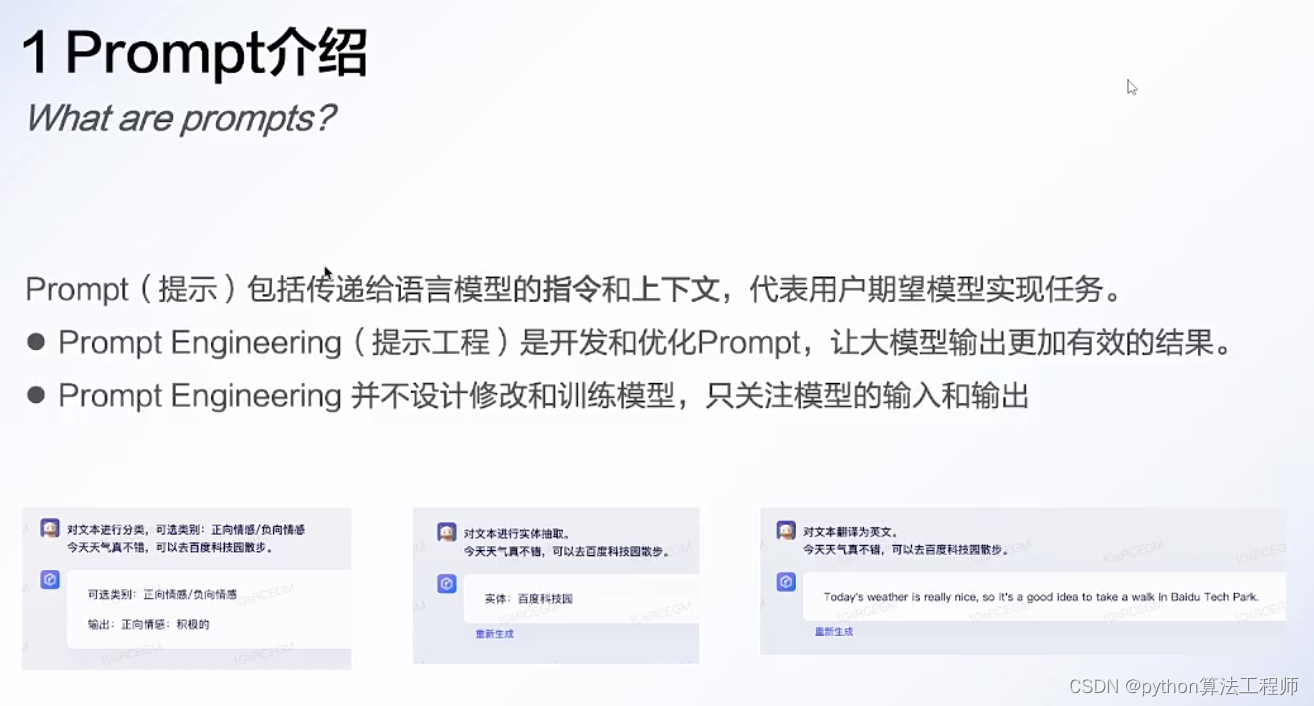
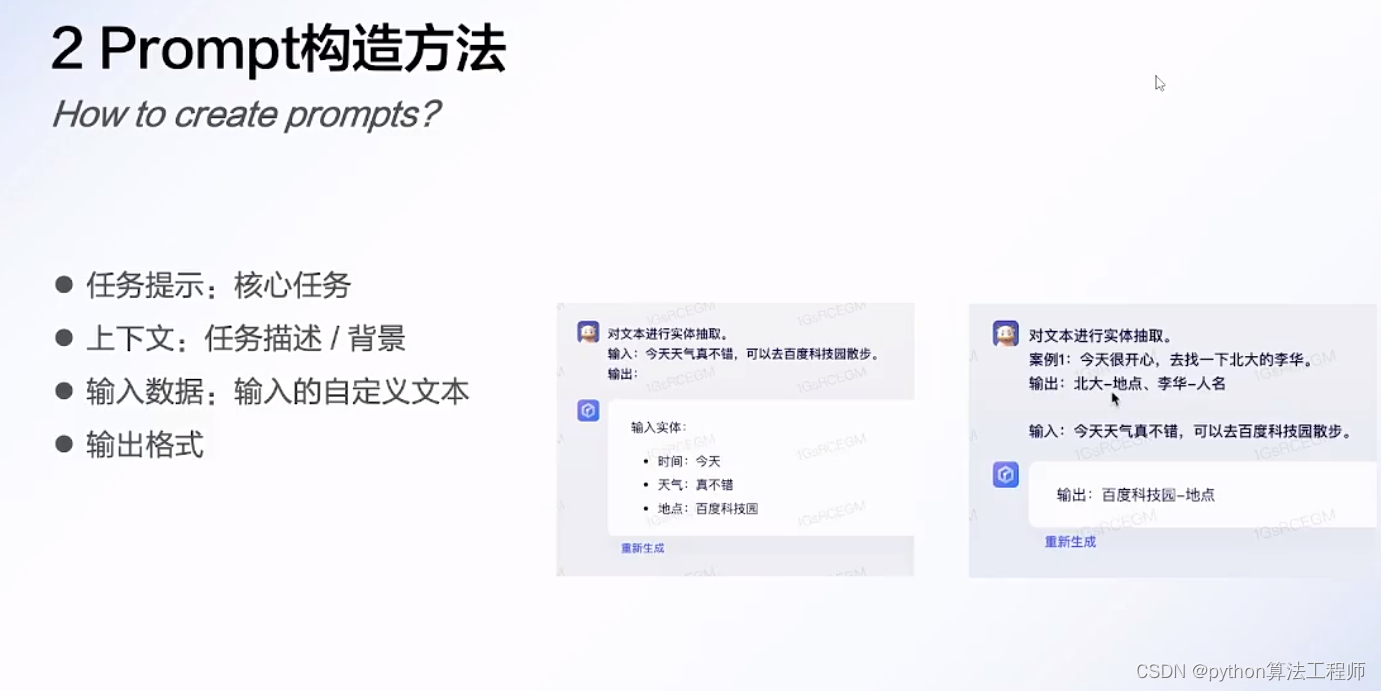
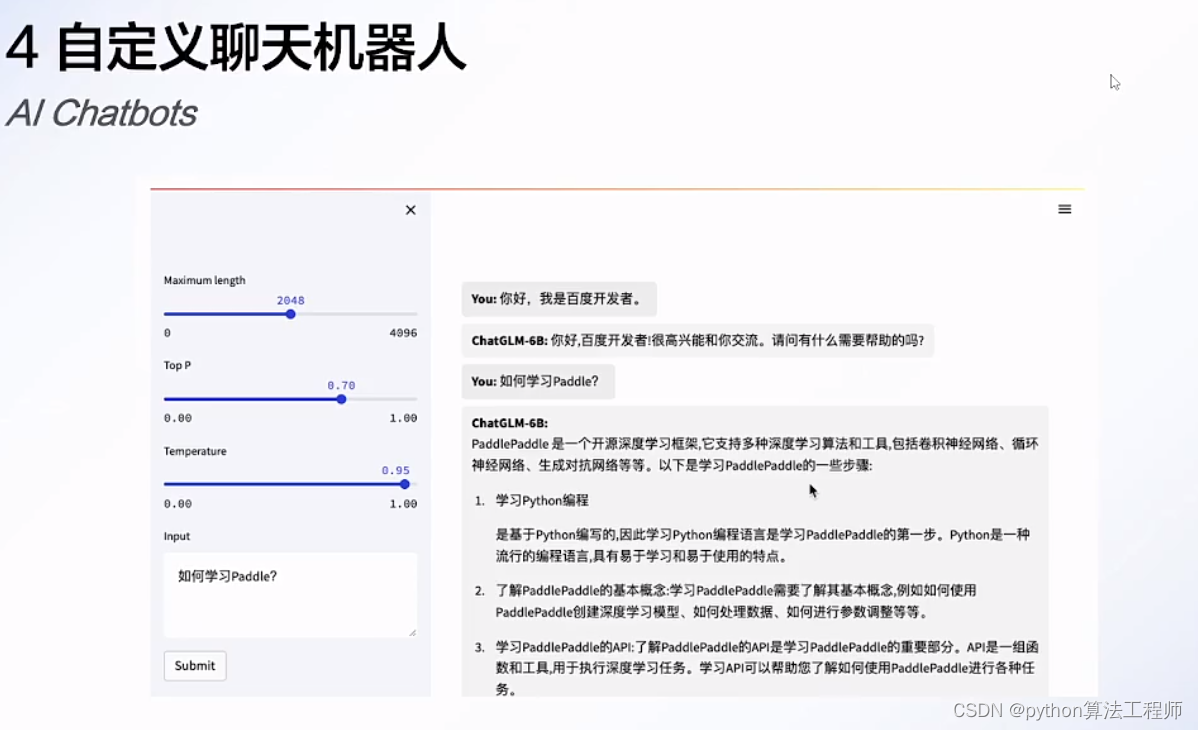
Prompt介绍















模型排名网站
https://github.com/THUDM/GLM-130B
提示词模板
autogpt技术原理分析,如何写好思维链(COT)
火热的Auto-Gpt解析技术原理
任务转换可读结构化数据如下:
{
"task": "介绍春节文化",
"steps": [
{
"step": "收集资料和信息",
"input": {
"keywords": ["春节", "文化"]
},
"output": {
"资料1": {
"标题": "春节的起源",
"内容": "春节是中华文化的重要节日,起源于古代的岁首祭祖活动。在农历正月初一,人们会燃放烟花,贴对联、饮酒、赏灯等,以庆祝新年的到来。"
},
"资料2": {
"标题": "春节的传统习俗",
"内容": "春节有许多丰富多彩的传统习俗,如贴春联、守岁、祭祖、舞龙灯等,这些习俗代表着祝福和吉祥之意。"
},
"资料3": {
"标题": "春节的民俗文化",
"内容": "春节也有着丰富的民俗文化,如戏曲、民间艺术、美食等,这些文化不仅丰富了人们的生活,也是中华文化的瑰宝之一。"
}
}
},
{
"step": "整理资料",
"input": {
"资料1": {
"标题": "春节的起源",
"内容": "春节是中华文化的重要节日,起源于古代的岁首祭祖活动。在农历正月初一,人们会燃放烟花,贴对联、饮酒、赏灯等,以庆祝新年的到来。"
},
"资料2": {
"标题": "春节的传统习俗",
"内容": "春节有许多丰富多彩的传统习俗,如贴春联、守岁、祭祖、舞龙灯等,这些习俗代表着祝福和吉祥之意。"
},
"资料3": {
"标题": "春节的民俗文化",
"内容": "春节也有着丰富的民俗文化,如戏曲、民间艺术、美食等,这些文化不仅丰富了人们的生活,也是中华文化的瑰宝之一。"
}
},
"output": {
"分类1": {
"名称": "春节的起源",
"内容": "春节是中华文化的重要节日,起源于古代的岁首祭祖活动。在农历正月初一,人们会燃放烟花,贴对联、饮酒、赏灯等,以庆祝新年的到来。"
},
"分类2": {
"名称": "春节的传统习俗",
"内容": "春节有许多丰富多彩的传统习俗,如贴春联、守岁、祭祖、舞龙灯等,这些习俗代表着祝福和吉祥之意。"
},
"分类3": {
"名称": "春节的民俗文化",
"内容": "春节也有着丰富的民俗文化,如戏曲、民间艺术、美食等,这些文化不仅丰富了人们的生活,也是中华文化的瑰宝之一。"
}
}
},
{
"step": "编写文章大纲",
"input": {
"分类1": {
"名称": "春节的起源",
"内容": "春节是中华文化的重要节日,起源于古代的岁首祭祖活动。在农历正月初一,人们会燃放烟花,贴对联、饮酒、赏灯等,以庆祝新年的到来。"
},
"分类2": {
"名称": "春节的传统习俗",
"内容": "春节有许多丰富多彩的传统习俗,如贴春联、守岁、祭祖、舞龙灯等,这些习俗代表着祝福和吉祥之意。"
},
"分类3": {
"名称": "春节的民俗文化",
"内容": "春节也有着丰富的民俗文化,如戏曲、民间艺术、美食等,这些文化不仅丰富了人们的生活,也是中华文化的瑰宝之一。"
}
},
"output": {
"主题": "春节文化介绍",
"标题1": "春节的起源",
"标题2": "春节的传统习俗",
"标题3": "春节的民俗文化"
}
},
{
"step": "生成文章内容",
"input": {
"分类1": {
"名称": "春节的起源",
"内容": "春节是中华文化的重要节日,起源于古代的岁首祭祖活动。在农历正月初一,人们会燃放烟花,贴对联、饮酒、赏灯等,以庆祝新年的到来。"
},
"分类2": {
"名称": "春节的传统习俗",
"内容": "春节有许多丰富多彩的传统习俗,如贴春联、守岁、祭祖、舞龙灯等,这些习俗代表着祝福和吉祥之意。"
},
"分类3": {
"名称": "春节的民俗文化",
"内容": "春节也有着丰富的民俗文化,如戏曲、民间艺术、美食等,这些文化不仅丰富了人们的生活,也是中华文化的瑰宝之一。"
},
"主题": "春节文化介绍",
"标题1": "春节的起源",
"标题2": "春节的传统习俗",
"标题3": "春节的民俗文化"
},
"output": {
"文章": "春节是中华文化的重要节日,起源于古代的岁首祭祖活动。在农历正月初一,人们会燃放烟花,贴对联、饮酒、赏灯等,以庆祝新年的到来。此外,春节还有着许多丰富多彩的传统习俗,如贴春联、守岁、祭祖、舞龙灯等,这些习俗代表着祝福和吉祥之意。除了传统习俗以外,春节还有着丰富的民俗文化,如戏曲、民间艺术、美食等,这些文化不仅丰富了人们的生活,也是中华文化的瑰宝之一。"
}
},
{
"step": "排版和发布",
"input": {
"文章": "春节是中华文化的重要节日,起源于古代的岁首祭祖活动。在农历正月初一,人们会燃放烟花,贴对联、饮酒、赏灯等,以庆祝新年的到来。此外,春节还有着许多丰富多彩的传统习俗,如贴春联、守岁、祭祖、舞龙灯等,这些习俗代表着祝福和吉祥之意。除了传统习俗以外,春节还有着丰富的民俗文化,如戏曲、民间艺术、美食等,这些文化不仅丰富了人们的生活,也是中华文化的瑰宝之一。"
},
"output": {
"排版和发布结果": "春节是一年中最重要的传统节日之一,其文化内涵丰富多彩。上述文章就是一篇介绍春节文化的文章,涵盖了春节的起源、传统习俗、民俗文化等方面,希望对大家了解春节文化有所帮助。"
}
}
]
}
这个结构化数据描述了Auto-GPT需要完成的若干个子任务,每个子任务都包含了输入、输出、步骤等信息。Auto-GPT可以按照这个结构化数据进行自主运作,完成整篇文章的自动生成。
autogpt本质基于gpt4,只是会将人类给的复杂任务目标进行拆分(如何拆分也从他的拆分经验数据库中得出),之后用拆分的子问题调用gpt4得出结果再组合。如此反复。
太耗费token了,不建议使用
强大的逻辑推理是大语言模型“智能涌现”出的核心能力之一,好像AI有了人的意识一样。而推理能力的关键,在于一个技术——思维链(Chain of Thought,CoT)。
https://m.thepaper.cn/newsDetail_forward_22900584
https://learnprompting.org/zh-Hans/docs/intro
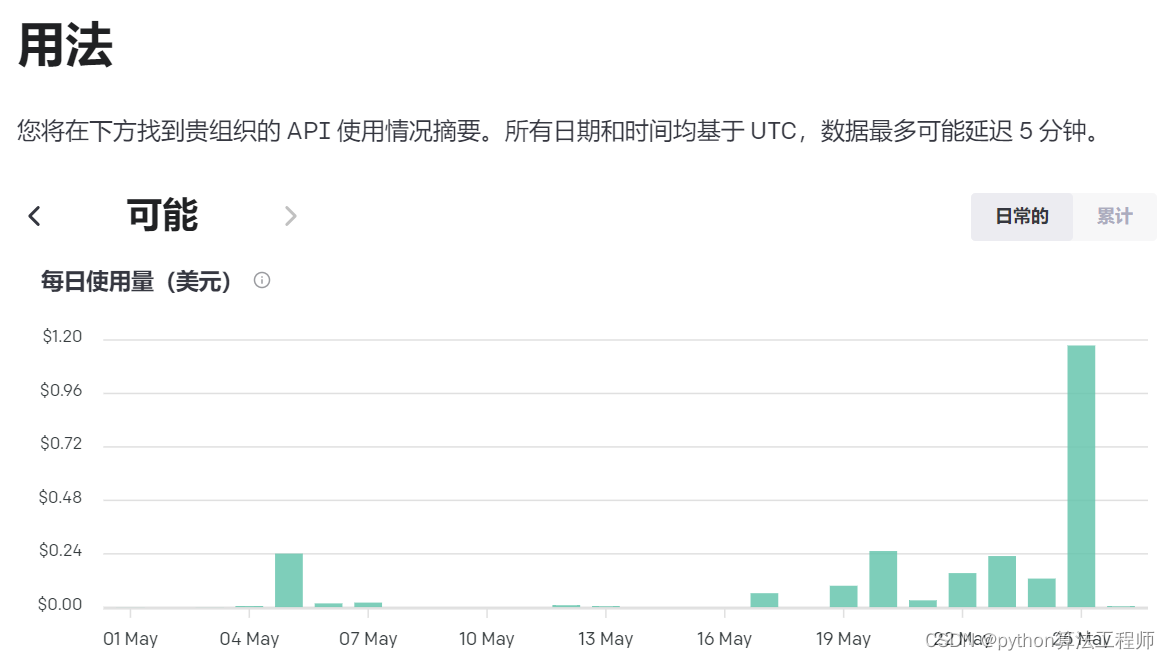
个人用搞个10 20条 就30元
完成一个小任务就30元人民币
我让gpt3.5写一篇介绍马斯克的小短文,就迭代了一次1.2美元没了
 https://user-images.githubusercontent.com/70048414/232352935-55c6bf7c-3958-406e-8610-0913475a0b05.mp4
https://user-images.githubusercontent.com/70048414/232352935-55c6bf7c-3958-406e-8610-0913475a0b05.mp4
https://github.com/Significant-Gravitas/Auto-GPT
https://www.bilibili.com/video/BV1qT411b7wd/?spm_id_from=333.337.search-card.all.click&vd_source=569ef4f891360f2119ace98abae09f3f

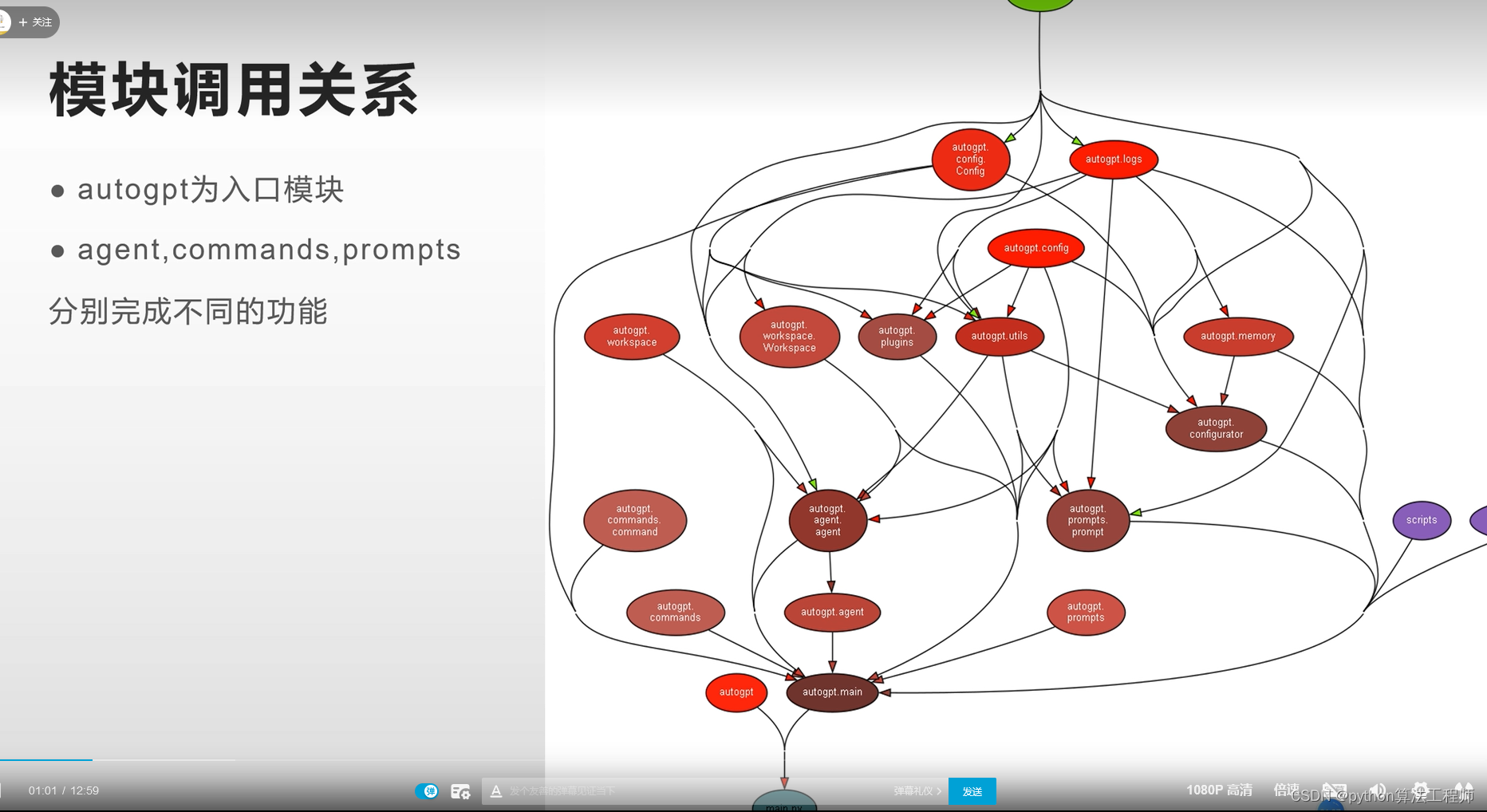
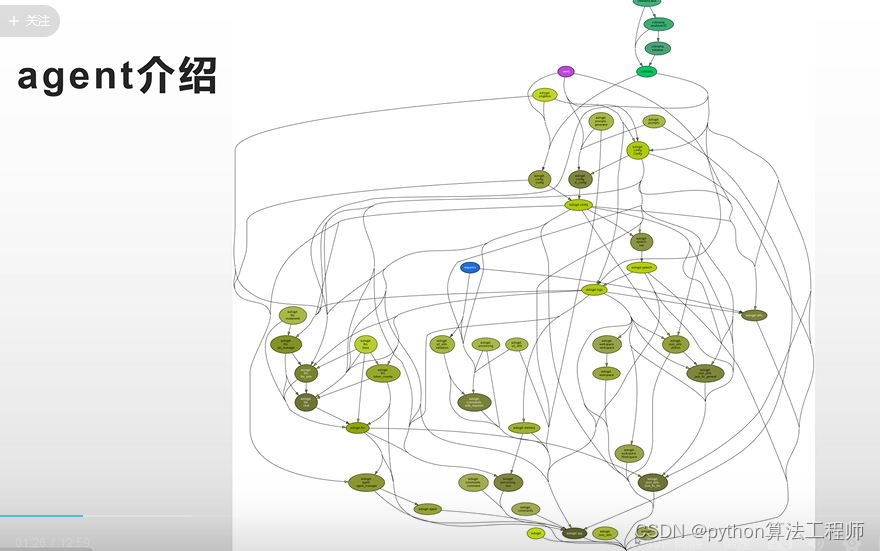 最核心的模块
最核心的模块
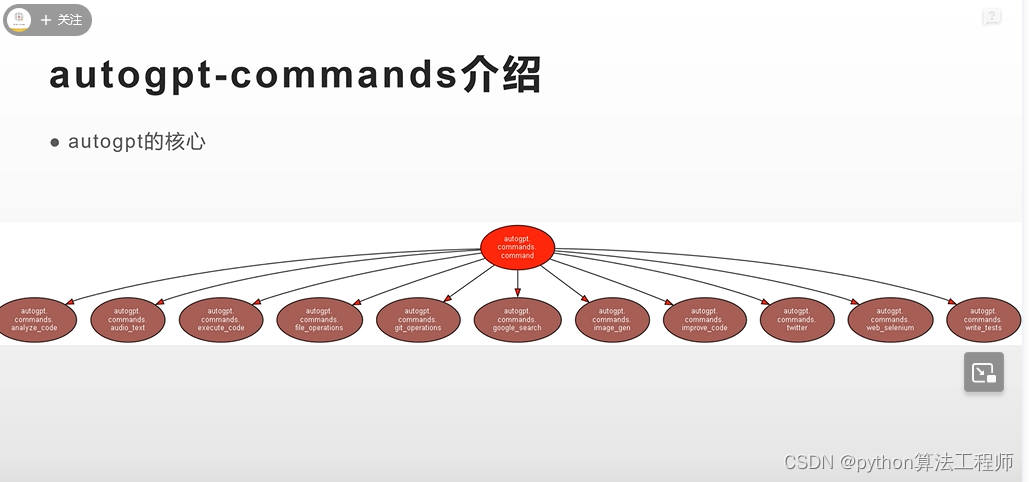
autogpt可以在google里进行搜索信息,可以自动发推特
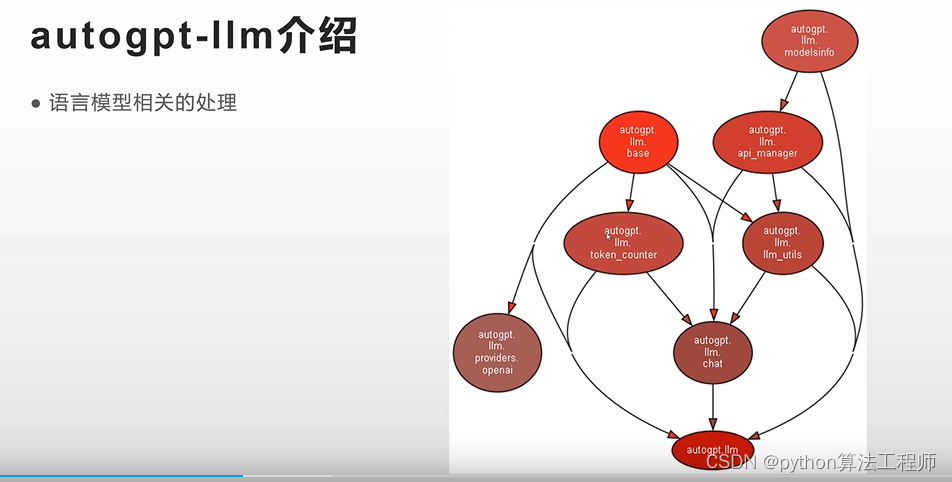 chatgpt接口的封装,token的计算
chatgpt接口的封装,token的计算
AutoGPT好玩吗?一天5000块的烧钱体验
我也玩了一下午,感觉就像脱缰的哈士奇[笑哭],你看它似乎干了什么,但是又好像没干。网络上那些说怎么着的我严重怀疑他们玩没玩过,一般玩过的人都会说:现阶段问题很多,但是前景很不错。
这个东西就现阶段感觉很垃圾,因为你按照他拆分的任务去做其实很快就搞定了,因为人是可以使用感性去比较选择的,而让机器通过理性去做选择,那么结果就是十万个为什么+余额不足![doge]
还没用过gpt4的api,3.5 turbo是真的蠢,主要是记忆力太差,让它自己每一步给自己记录个log并查看似乎是个解决办法,但我trial额度用完了…
langflow低代码开发langchina
https://github.com/logspace-ai/langflow
构建、托管和共享 AI 应用
chatgptweb
http://chat.cybart.ist/
test@cybart.ist

















 1546
1546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









