






三维重建基础
深度相机给出相对位姿得到点云与深度信息;数据源;点云配准;后期视觉处理;动态更新;局部特征汇总;
传统方法用激光雷达(万元起步,所以目前多是以各个视图图像来做,从视图到视角)等设备获取深度信息比深度学习用估计的方法获取深度信息要好。
坐标系转化

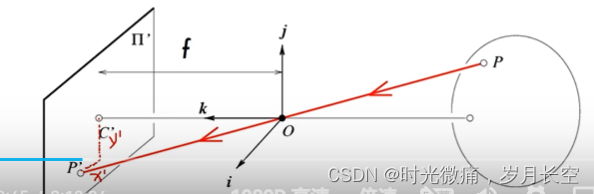
从世界坐标系到相机坐标系到像平面坐标系的转化。类似相识三角形。再由像平面坐标系转化为像素坐标系。k与l是米到像素的转化,如下图:
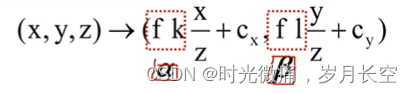
因为这里的z也在变化,对应的转化关系不是线性的,用齐次坐标解决
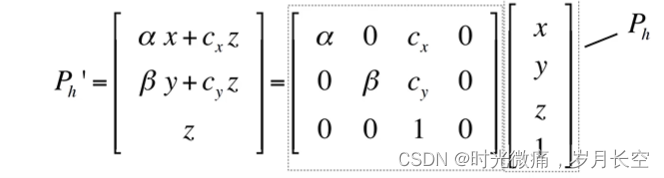
矩阵内对应相机内参。
世界坐标系到相机坐标系,需要提供相机位姿,位姿是由旋转与平移矩阵控制的,旋转平移就是外参。
相机标定:已知点的对应关系
TSDF(Truncated signed distance function)
已知:原始图像,对应深度信息,每张图的相机位姿,相机内参。
TSDF是一个不断更新的过程,一步步计算各个体素(voxel )的TSDF再拼接。
TSDF计算
相机一般可以采集到面到相机的距离,可以从深度图中获取ds,体素到相机的距离dv,d=ds-dv。
1、传统方法
RGBD深度相机获取三维图像(深度相机分为结构光,ToF相机)
2011开始提出KinectFusion,2015年DynamicFusion ,最近提出BundleFusion
1.1、kinectFusion
论文名称:2011、Real-Time Dense Surface Mapping and Tracking
地址:豆丁破解下载的
kinect也就是一个RGBD的扫描仪,30fps,可获取深度图像与彩色图像
重点
舍弃了帧与帧之间的融合方法,使用追踪的方法;
ICP:两组点云之间的配对,根据估计距离误差。前提是点云的法向量可测。
SDF:常用的一种符号距离,曲面表示为0等值面
双边滤波器:双边滤波是在空间域加权平均的基础上再对值域加权平均,即像素灰度值越靠近中心像素的灰度值,权重越高。在边界附近,灰度值差异很大,所以虽然边界两边的像素在空间域靠在一起,但是由于灰度值差别非常大,对于互相的权重很低,所以可以保持清晰的边界。
算法过程
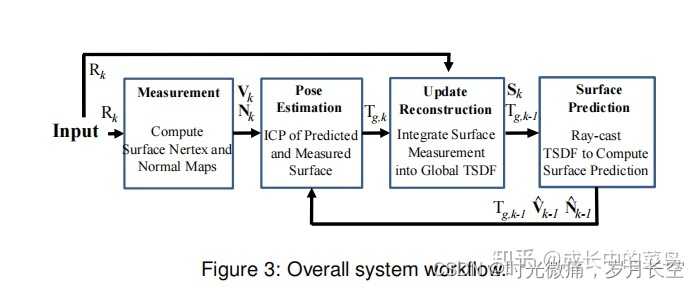
1、第一步是获取到kinect相机的带顶点与法向量图。
将深度图根据相机内参K进行反投影得到每个像素点的三维坐标vertex map,再根据临近点得到每个点的法向量。齐次坐标就是将一个原本是n维的向量用一个n+1维向量来表示,是指一个用于投影几何里的坐标系统,如同用于欧氏几何里的笛卡儿坐标一般。将生成的三维点云进行预处理,
2、将获取到的二维图fuse到全局三维TSDF中(Truncated Signed Distance Function)TSDF是由立方体珊格组成,有三个值,一是距离值F,一是权重值W,Flog表示体素是否有效。TSDF模型中存储的距离值,surface处值为零,传感器一侧的值为正,距离表面越远值越大,另一侧值为负,距离表面越远值越小。而权重值则与表面测量的不确定度有关,越靠近。单帧TSDF加权平均得全局TSDF。
3、通过光线投影方法对TSDF进行采样,计算出surface和normal。根据TSDF中存储的距离值合理的调整步长,快速找到表面。
4、通过ICP与上一帧的图像进行配准。这里并不是帧之间的点配准,而是将上一帧的预测面与当前帧的测试面进行配准,迭代估计出相机的位置。上面图中的循环就是一边注册一边融合的过程,最终得到一个整体点云
kinectFusion缺点:
1、位姿飘移
2、内存占用大
1.2、DynamicFusion
DynamicFusion方法构建了第一个能够实时重建非刚性变形动态场景的系统。
2、深度方法
单帧图像重建mesh模型 ;if-Net;PifuHD、
MVS重建深度图,MVSNet,P-MVSNet,Unsupervised MVSNet,Fast-MVSNet,JDACS-MS 无监督,PatchMatchNet 有监督
2021cvpr NeuralRecon
直接用单目摄像头就能做三维重建,直接用神经网络做深度估计做点云融合,也不需要点云信息,最大的贡献就是手机端就能玩三维重建。
sparse convolutions:稀疏卷积,许多三维点云中的体素是空的,传统卷积会增加许多计算量。1、建立输入哈希表。2、用卷积核中的权重建立输出哈希表.3、构建Ruleboook表。
3D卷积:3D卷积是针对多张图像或者是连续视频帧,增加了各帧之间的关联信息。
MarchingCubes(MC)算法:一种体素的等值面提取方法。
帧与帧之间不是孤立的,当前序列是以先前序列为基础的。
End2End框架用这个框架,不需要计算中间结果。
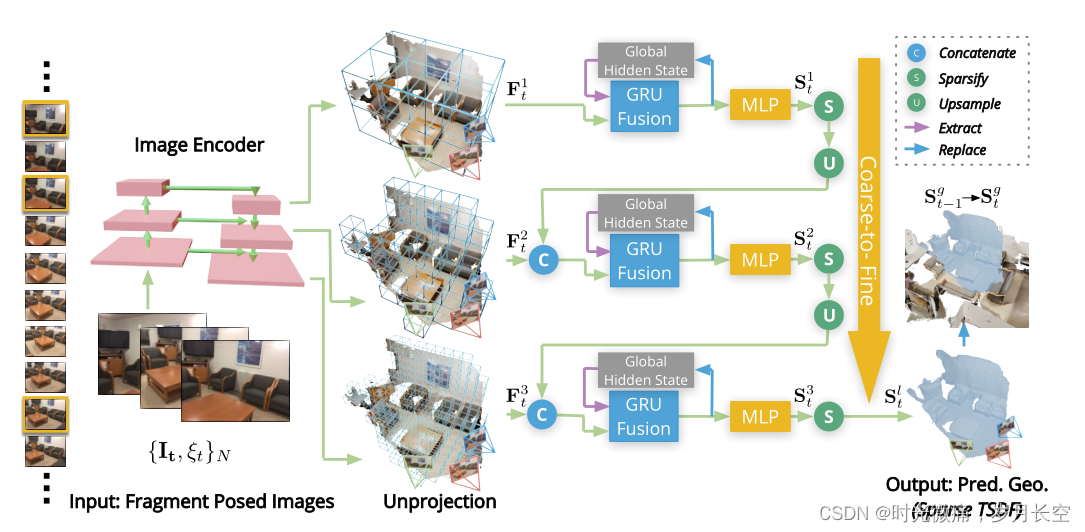
1、关键帧选择
并不是将所有的图像都进行重建,而是选择一些关键帧。关键帧需要提供足够的运动误差,每帧之间不能太近或太远。选取关键帧是根据相对平移Tmax和相对旋转角度Rmax。N张关键帧组成一个视图,
2、输入序列
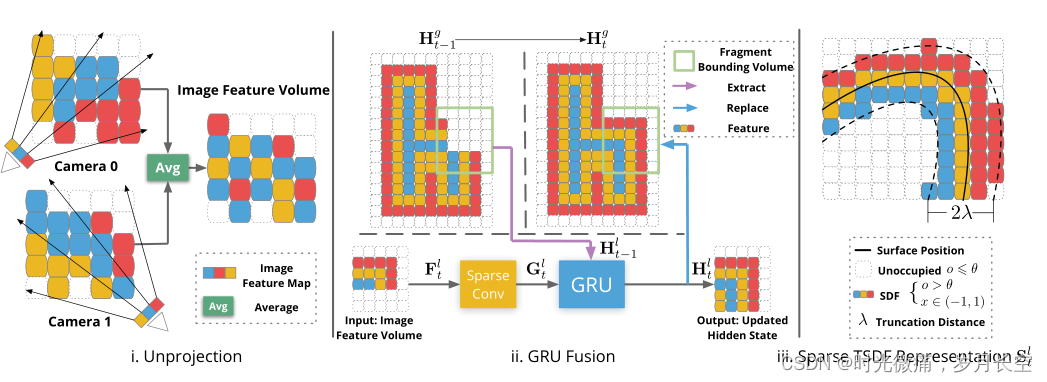
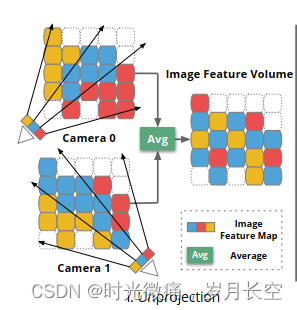
将某个部位的图像处理成一个批次。需要先进行相机坐标系到世界坐标系的转化,首先将输入序列中的像素对应到体素中,做的是加权平均。核心是特征映射,如何将图像的特征映射到重建的结果上。映射细节是,多张图像提取特征,对应体素求平均。
使用GUR融合TSDF,取代了传统的线性融合,GUR类似与RNN的思想,之中包含了一些更新门与遗忘门,会以先前的全局信息为约束,输出下一个时刻的全局信息。
3、片段重建
根据一个序列重建某个区域。
4、全局合成
根据片段进行全局融合。
















 8846
8846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









