







验证曲线是什么?
验证曲线和学习曲线的区别是,横轴为某个超参数的一系列值,由此来看不同参数设置下模型的准确率(评价标准),而不是不同训练集大小下的准确率。
从验证曲线上可以看到随着超参数设置的改变,模型可能从欠拟合到合适再到过拟合的过程,进而选择一个合适的设置,来提高模型的性能。
需要注意的是如果我们使用验证分数来优化超参数,那么该验证分数是有偏差的,它无法再代表模型的泛化能力,我们就需要使用其他测试集来重新评估模型的泛化能力。不过有时画出单个超参数与训练分数和验证分数的关系图,有助于观察该模型在相应的超参数取值时,是否有过拟合或欠拟合的情况发生。
怎么解读?
Python代码如下:
from sklearn.model_selection import validation_curve
train_scores, test_scores = validation_curve(classifier,
train_feat,
train_target,
param_name=param_name,
param_range=param_range,
cv=cvnum,
scoring='accuracy',)
print(train_scores)
print(test_scores)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)[[0.34 0.33 0.33]
[0.34 0.33 0.33]
[0.67 0.77 0.81]
[0.96 0.98 0.98]
[0.97 0.98 0.99]
[0.96 0.98 0.98]
[0.96 0.98 0.99]]
[[0.32 0.34 0.34]
[0.32 0.34 0.34]
[0.7 0.86 0.8 ]
[1. 0.96 0.96]
[1. 0.96 0.96]
[0.98 0.94 0.98]
[0.98 0.96 0.98]]
validation_curve参数解读:
classifier:估计器 train_feat:训练集特征数据 train_target:训练集特征数据对应的标签 param_name:可视化参数的名称 param_range=param_range可视化参数的取值范围-列表num cv:交叉验证的折数k (每折采用默认比例分割),也可以传入分割方式 scoring:评价方式返回值解读:
train_scores:如上图:num列k行的训练集评价分数
test_scores:如上图:num列k行的验证集评价分数
Python完整代码:
import matplotlib.pyplot as plt
import numpy as np
import warnings
warnings.filterwarnings("ignore")
from sklearn.datasets import load_iris # 自带的样本数据集
from sklearn.linear_model import LogisticRegression
iris = load_iris()
X = iris.data # 150个样本,4个属性
y = iris.target # 150个类标号
# 绘制验证曲线
# 可以通过绘制验证曲线,可视化的了解调参的过程
# 对进行网格调参
def grid_plot(train_feat,
train_target,
classifier,
cvnum,
param_range,
param_name,
param=None):
from sklearn.model_selection import validation_curve
train_scores, test_scores = validation_curve(classifier,
train_feat,
train_target,
param_name=param_name,
param_range=param_range,
cv=cvnum,
scoring='accuracy',)
print(train_scores)
print(test_scores)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.title("Validation Curve with " + param_name)
plt.xlabel(param_name)
plt.ylabel("Score")
plt.xlim(1, 100)
plt.ylim(0.0, 1.1)
plt.semilogx(param_range,
train_scores_mean,
label="Training score",
color="r")
plt.fill_between(param_range,
train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std,
alpha=0.2,
color="r")
plt.semilogx(param_range,
test_scores_mean,
label="Cross-validation score",
color="g")
plt.fill_between(param_range,
test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std,
alpha=0.2,
color="g")
plt.legend(loc="best")
plt.show()
# 对逻辑回归的max_iter情况进行查看
# grid_plot(train_feat,classifier,3,[10,20,40,80,200,400,800],'n_estimators',param=params)
model = LogisticRegression(penalty='l2')
grid_plot(X, y, model, 3, [1, 2, 5, 10, 20, 40, 50], 'max_iter', param=None)绘制结果如图:
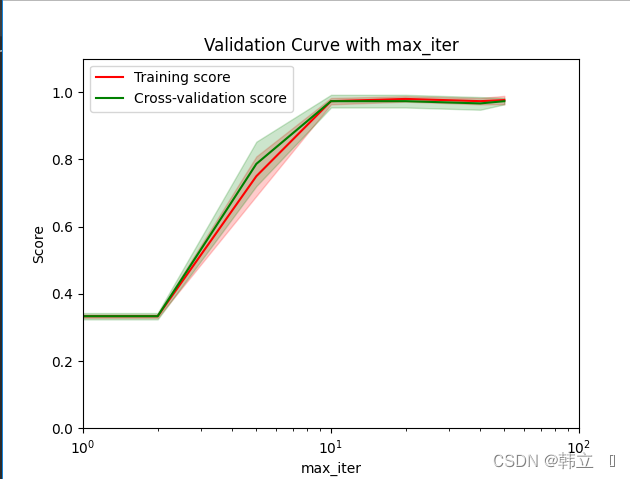
结论:max_iter选择10以上都可以,因为在训练集和验证集分数上都趋于一致稳定















 1060
1060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









