






今天要说的是PCoA (Principal Coordinates Analysis),即主坐标分析,也是一种降维分析方法。与t-SNE类似,可以简单地看为是一种聚类,但其更偏向于生态领域的应用,用于探究样品之间的物种组成相似性。好了,它与t-SNE的差异我们文末再说,我们先看一下核心思路和实例。
01 PCoA的核心思想
PCoA是通过比较样本之间的相似性来帮助我们更好地理解数据。想象一下,如果我们有一组样本,每个样本都有自己的特点,比如不同的物种组成。我们基于这些数据可以计算出每个样本之间的“距离”(比如欧氏距离或Bray-Curtis距离),这种距离可以反映它们有多相似或多不同。
然后,PCoA会把这些“距离”转化为一个坐标系中的点。这个坐标系就像一个地图,每个点代表一个样本。如果两个样本之间的距离很近,这表示它们很相似;反之,如果它们在地图上距离很远,说明它们差异较大。这样,我们就能直观地看到哪些样本更相似,哪些样本有显著差异。
02 PCoA案例
图1A是我们拿到手的一份数据,代表的是每一个站点的不同物种的个数,图1B是站位的一个归属,我们可以把不同分组看作不同区域。当然如果站位没有归属的话也是可以的,那就相当于探索哪些站点的组成是相似的。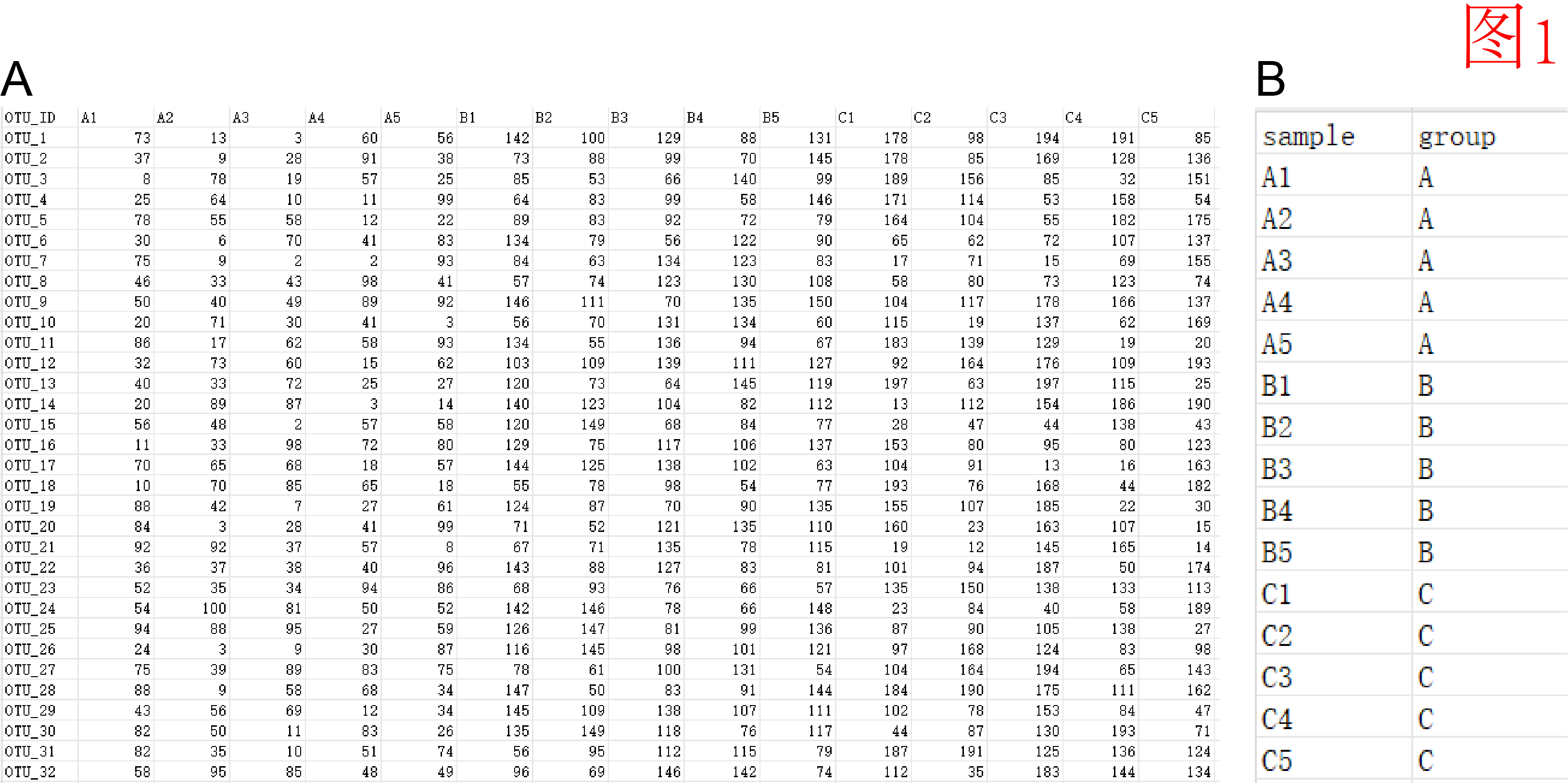
在结果的可视化方面,基于本数据站位有分组的情况,我们需要看两项内容:PCoA1和PCoA2百分比之和(上限为100%,越高越好,表示的是数据变异程度);同组站位在同一置信区间(圆圈)内,证明组成类似。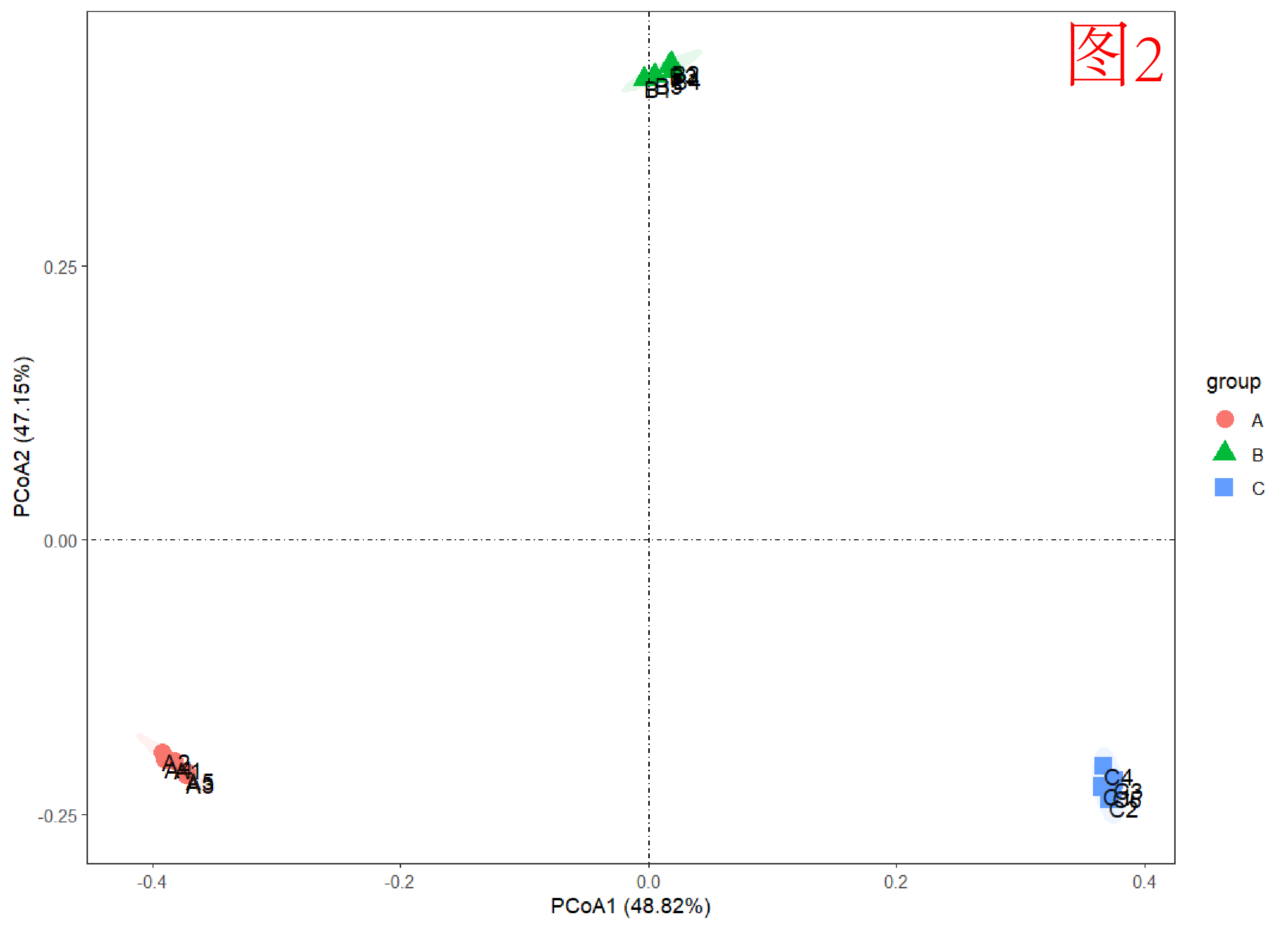
而结果往往分上(图2)、中(图3)、下(图4)三等。上等是百分比够高、点位分得开;中等是百分比稍低,但点位也分得开;下等是百分比低、点位分不开。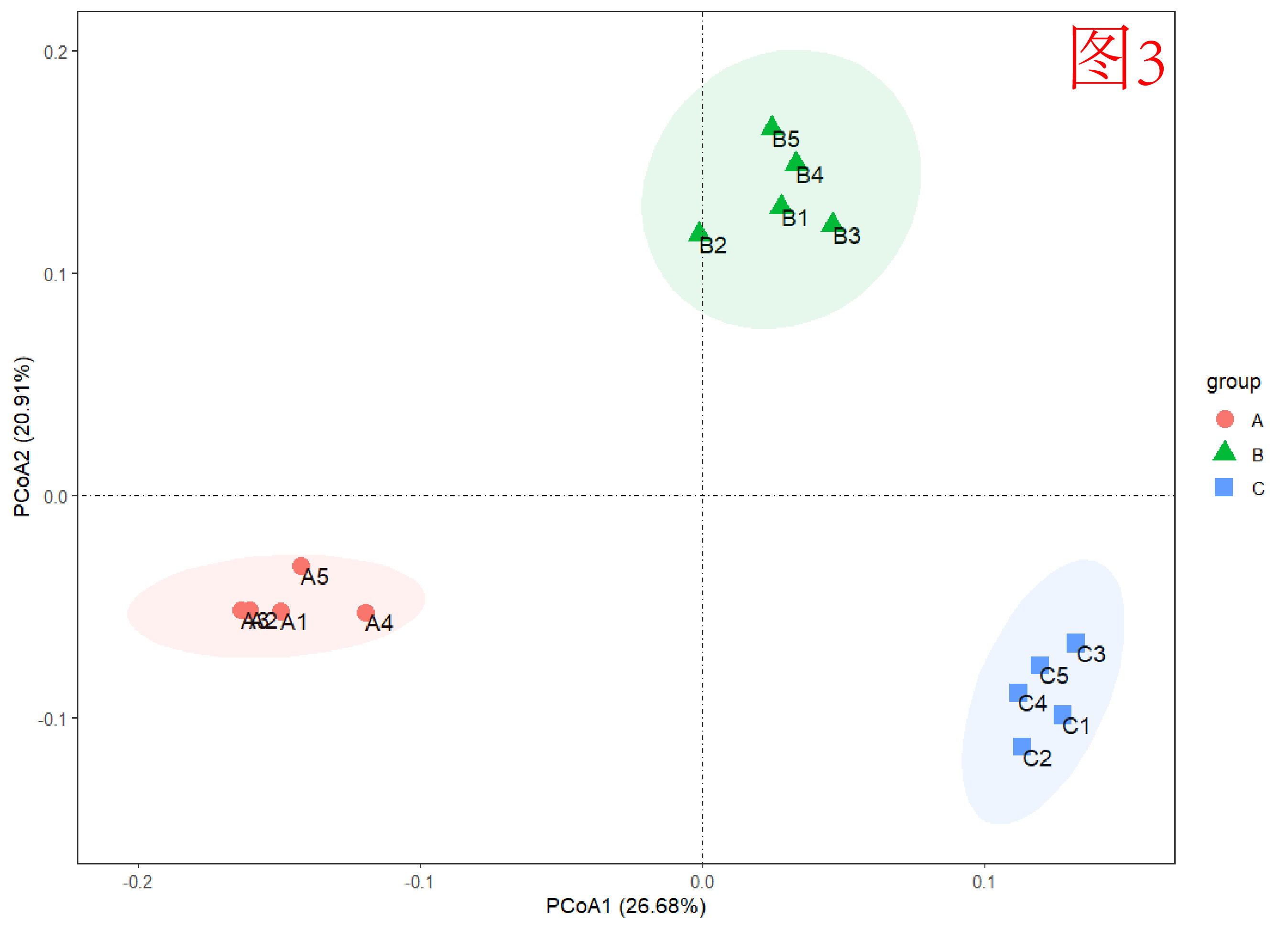
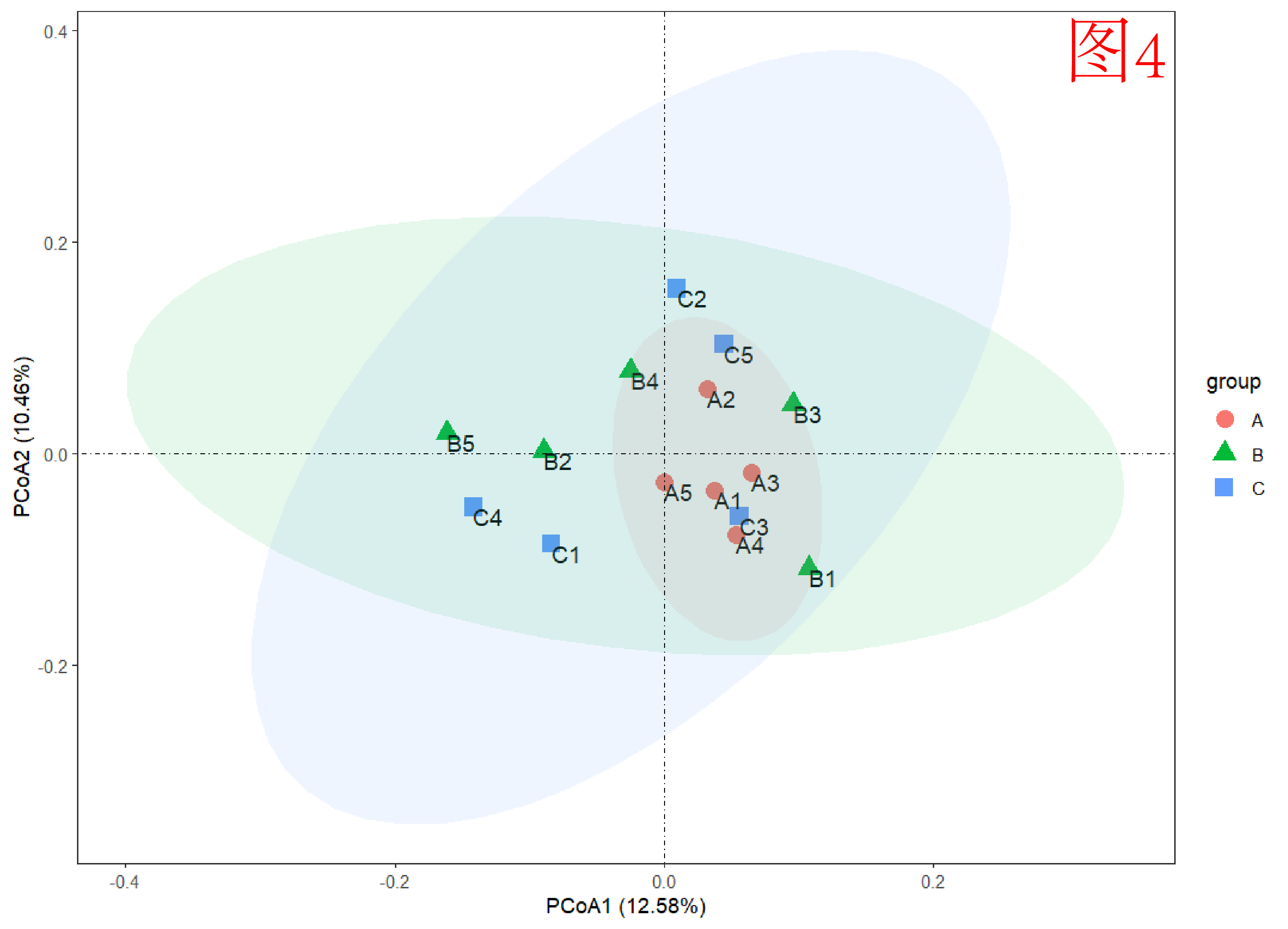
03 PCoA与t-SNE的差异
- PCoA通常用与生态分析,比较样品/站位相似性;t-SNE则更像是一种分类方法,将一堆数据按照特征进行分类。
- PCoA需要参考轴的方差贡献;而t-SNE则无该指标,只关注聚类情况。
TomatoSCI科研数据分析平台,欢迎大家来访!数据分析无需登录,专业在线客服答疑,还可在线传输文件,五折优惠码“tomatosci”开放使用中。

















 8169
8169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









