






三维重建场景常用指标汇总
【0】欧氏距离
欧氏距离(Euclidean Distance)是空间中两点之间的直线距离,也称为欧几里得距离。它是最常用的距离度量方式之一,用于计算点之间的距离,通常用于多维空间中。
欧氏距离的计算方法如下:
假设有两个点 A 和 B,它们分别在多维空间中的坐标表示为 (x1, y1, z1, …) 和 (x2, y2, z2, …)。这两点之间的欧氏距离 D 计算如下:
D = √((x2 - x1)² + (y2 - y1)² + (z2 - z1)² + …)
在二维空间中,欧氏距离的计算简化为:
D = √((x2 - x1)² + (y2 - y1)²)
在三维空间中,欧氏距离的计算包括 x、y 和 z 三个坐标的差的平方和的平方根。
在更高维度的多维空间中,欧氏距离的计算依然是将各维度坐标的差的平方和取平方根。
欧氏距离常用于多种领域,包括数据挖掘、机器学习、统计学、图像处理、空间分析和工程学等。它可以用于度量数据点之间的相似性或差异,以及用于聚类、分类、回归和距离度量等任务。
【1】Chamfer Distance(CD) 钦佛距离
也称Chamfer Matching或Chamfer Metric,是一种用于测量两个点云或形状之间相似性的距离度量方法。它经常用于计算机视觉和图像处理领域,特别是在三维形状比较和匹配方面。Chamfer Distance的主要应用包括目标检测、物体识别、图像分割、三维重建等领域。
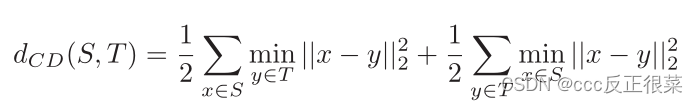
Chamfer Distance的计算方法通常涉及以下步骤:
-
定义参考点云和目标点云:首先,定义一个参考点云(通常是模型的理想或标准点云)和一个目标点云(通常是从实际场景或数据中获取的点云)。
-
对每个参考点计算到最近目标点的距离:对于每个参考点,计算它到目标点云中最近的点之间的距离。
-
对每个目标点计算到最近参考点的距离:对于每个目标点,计算它到参考点云中最近的点之间的距离。
-
将这些距离值累加或平均:通常,这些距离值会累加或平均,形成一个综合的Chamfer Distance。
Chamfer Distance的计算可以用于找到与参考点云最匹配的目标点云,或者用于测量两个点云之间的相似性。它在点云匹配、物体识别和三维模型比较中有着广泛的应用,因为它能够有效地测量点云之间的形状差异。不过,Chamfer Distance的计算也受到噪声和不完整数据的影响,因此在实际应用中需要谨慎使用,并根据具体情况进行参数调整。
【2】Mean Squared Error (MSE) 均方误差
通常用来评估生成的三维模型与真实或标准模型之间的差异。MSE是一种用于测量两个数据集之间的平均差异的常见指标。
对于三维重建,MSE通常按照以下步骤进行计算:
- 定义真实模型和生成模型:首先,需要有一个真实的或标准的三维模型(通常由人工创建或来自激光扫描等方法),以及一个生成的或重建的三维模型(由三维重建技术生成)。
- 对每个对应点计算距离:对于每个真实模型中的点和生成模型中的对应点,计算它们之间的距离,通常使用欧氏距离。这表示每个点的误差。
- 计算平方误差:对每个点的误差进行平方,得到每个点的平方误差。
- 对所有点的平方误差求和:将所有点的平方误差相加,得到总的平方误差(SSE,Sum of Squared Errors)。
- 计算平均均方误差:将总的平方误差除以点的数量(样本数),得到平均均方误差(MSE),通常表示为 MSE = SSE / n,其中 n 表示点的数量。
MSE的值越小,表示生成的三维模型与真实模型之间的差异越小,模型性能越好。MSE通常用于三维重建的质量评估,以确定生成的模型与真实模型之间的一致性和准确性。然而,需要注意MSE也受到异常值的影响,因为它对平方误差敏感。在某些情况下,可能需要考虑使用其他指标来衡量模型性能,以减小异常值的影响。
【3】Mean Normalized Error (MNE)
用于评估生成的三维模型与真实或标准模型之间的差异的指标。与MSE(均方误差)类似,MNE也用于测量模型的准确性,但它经常用于考虑到不同模型尺度的情况。
MNE的计算方法如下:
-
定义真实模型和生成模型:首先,需要有一个真实的或标准的三维模型(通常由人工创建或来自激光扫描等方法),以及一个生成的或重建的三维模型(由三维重建技术生成)。
-
对每个对应点计算距离:对于每个真实模型中的点和生成模型中的对应点,计算它们之间的距离,通常使用欧氏距离。
-
计算均方误差(MSE):计算每个点的误差,并计算平方误差(SSE,Sum of Squared Errors),方法与MSE相同。
-
计算平均均方误差(MSE):将总的平方误差除以点的数量(样本数),得到均方误差(MSE),通常表示为 MSE = SSE / n,其中 n 表示点的数量。
-
计算均方误差的平方根(RMSE):RMSE 是均方误差的平方根,它考虑了误差的尺度,但通常不考虑模型的尺度问题。
-
计算均方归一化误差(MNE):计算RMSE与真实模型的对角线距离之比,通常表示为 MNE = RMSE / D,其中 D 是真实模型的对角线距离,表示为点云或模型的两个最远点之间的距离。
MNE通常用于考虑到不同尺度的三维模型之间的比较,因为它通过将RMSE除以对角线距离来对误差进行归一化。较小的MNE值表示生成的模型与真实模型之间的差异较小,模型性能较好。这种指标有助于更全面地评估三维重建模型的准确性,尤其在考虑到尺度差异的情况下。
【4】Completeness Rati (CR) 完整性比率
完整性比率是用于评估三维重建质量的指标之一,它衡量了重建结果中包含的真实物体表面或点云的百分比。完整性比率通常是通过比较重建结果中的点云或三维模型与真实或标准点云或模型之间的重叠来计算的。
具体计算步骤可能如下:
-
定义真实模型和重建模型:首先,需要有一个真实的或标准的三维模型或点云,以及一个重建的三维模型或点云(由三维重建技术生成)。
-
计算重建模型中与真实模型的重叠部分:通过计算重建模型中的点云或模型与真实模型的重叠部分,确定重建模型包含了多少真实模型的内容。
-
计算完整性比率:将重建模型中与真实模型的重叠部分的点数除以真实模型的点数,以计算完整性比率。通常以百分比表示。
完整性比率的值越接近100%,表示重建结果包含了真实物体的大部分表面或点云,表明重建质量较高。然而,如果存在遮挡、噪声或重建算法的限制,完整性比率可能会较低。这个指标通常用于评估三维重建算法的性能,特别是在需要准确重建物体的应用中,如文物保护、医学成像、建筑重建等领域。
【5】Peak Signal-to-Noise Ratio(PSNR) 均方根信噪比
PSNR 是均方根信噪比(Peak Signal-to-Noise Ratio)的缩写,它是一种用于测量图像或音频的质量损失的指标,通常用于评估压缩或传输后的数据与原始数据之间的相似程度。
PSNR的计算方法如下:
-
定义原始数据和重建数据:首先,需要有原始数据(通常是未经压缩或处理的数据)和重建数据(经过压缩或传输后的数据)。
-
计算均方误差(Mean Squared Error,MSE):MSE是原始数据和重建数据之间每个像素或样本值的平方差的平均值。MSE 计算如下:
MSE = (1 / (m * n)) * Σ[Σ[(I(i, j) - K(i, j))^2]]
其中,m 和 n 分别是图像的宽度和高度,I(i, j) 是原始数据中的像素值,K(i, j) 是重建数据中的像素值。 -
计算峰值信噪比(Peak Signal-to-Noise Ratio,PSNR):PSNR 是将最大可能的信号功率(通常是原始数据的范围的平方)除以均方误差的对数,然后取负值。PSNR 计算如下:
PSNR = 10 * log10((R^2) / MSE)
其中,R 是数据的动态范围或最大可能像素值。
PSNR的结果通常以分贝(dB)为单位,它是一个指示重建数据与原始数据之间相似性的指标。PSNR的值越高,表示两者之间的相似性越高,因此数据质量损失越小。通常,PSNR越接近无穷大(通常在 20 dB 以上),表示数据的重建质量越好。
PSNR在图像处理、视频压缩、音频编解码和通信领域经常用于评估数据质量,但需要注意,它对于人眼或听觉感知的差异并不总是完全准确,因此在一些情况下可能需要结合其他质量指标来进行全面评估。
【6】 Learned Perceptual Image Patch Similarity(LPIPS)
它是一种用于衡量两个图像之间的感知相似性的指标,基于计算机视觉和深度学习技术。LPIPS 旨在模拟人类视觉系统对图像相似性的感知。
LPIPS 是一个深度学习模型,它使用卷积神经网络(CNN)来提取图像特征,然后计算这些特征之间的距离以评估图像的相似性。与传统的像素级差异度量不同,LPIPS 更加注重人类感知,可以更好地捕捉图像中的结构和内容相似性。
LPIPS 主要用于以下方面:
图像质量评估:LPIPS 可以用于评估不同图像处理或生成方法的输出与原始图像之间的质量差异。它可以帮助确定哪个图像处理方法生成的图像更接近原始图像。
图像生成对抗网络(GAN)评估:在生成对抗网络中,LPIPS 可用于评估生成的图像与真实图像之间的相似性,以指导 GAN 训练和生成更逼真的图像。
图像超分辨率:LPIPS 可用于评估超分辨率算法生成的高分辨率图像与低分辨率输入图像之间的相似性。
图像检索:LPIPS 可用于图像检索任务,帮助确定检索结果与查询图像之间的相似性,以提高检索效果。
LPIPS 是一个强大的工具,因为它能够更好地模拟人类感知,而不仅仅是基于像素级的差异。这使它在许多图像相关任务中非常有用。
【7】Structural Similarity Index(SSIM)结构相似性指数
它是一种广泛用于比较两幅图像之间的相似性和差异的指标,特别是在图像压缩、图像处理和图像传输等领域。
SSIM 的计算基于以下三个方面的图像信息:
亮度(Luminance):亮度表示图像的亮暗程度,通常通过亮度分量(Y)来表示。
对比度(Contrast):对比度表示图像中的颜色和亮度变化程度,它可以反映图像的清晰度。
结构(Structure):结构表示图像中的纹理和细节。它考虑了图像中像素之间的相关性和结构。
SSIM 的计算方法如下:
- 首先,将两幅图像分别划分为多个局部块,通常是 8x8 或 16x16 的大小。
- 对每个块,计算亮度、对比度和结构的指标,分别表示为 Y、C1、C2、和 C3。
- 使用这些指标来计算结构相似性指数(SSIM):
SSIM = (2 * Y1 * Y2 + C1) * (2 * C2 + C3) / ((Y1^2 + Y2^2 + C1) * (C2^2 + C3))
其中,Y1 和 Y2 是两幅图像的亮度,C1、C2、C3 是常数,用于稳定计算。
SSIM 的结果通常在 -1 到 1 之间,越接近1表示两幅图像越相似,越接近-1表示差异越大。一个高 SSIM 值表示图像之间的结构和亮度非常相似,而一个低 SSIM 值表示它们之间有较大的差异。
SSIM 是一种受欢迎的图像质量评估指标,因为它能够捕捉到人类视觉系统对图像质量的感知,特别是在压缩和失真方面,它能够提供有用的信息。不过,需要注意的是,SSIM 也有一些局限性,不适用于所有类型的图像和失真类型。在某些情况下,可能需要结合其他指标来全面评估图像质量。
【8】Mean Absolute Error(MAE)平均绝对误差
它是一种用于测量预测值与实际值之间的平均绝对差异的统计指标。MAE通常用于评估回归模型的性能,其中模型的目标是根据输入数据预测一个连续数值。平均绝对误差表示平均预测误差的绝对值。
MAE 的计算方法如下:
- 对于每个数据点,计算预测值与实际值之间的差异,即误差(error),通常表示为 e(i)。
- 计算每个误差值的绝对值,即 |e(i)|。
- 对所有数据点的绝对误差值求和,得到总的绝对误差(Sum of Absolute Errors,SAE):SAE = Σ|e(i)|,其中Σ 表示对所有数据点求和。
- 计算平均绝对误差(Mean Absolute Error),即将总的绝对误差除以数据点的数量(样本数),通常表示为 MAE = SAE / n,其中 n 表示数据点的数量。
MAE 的值越小,表示模型的平均绝对误差越小,模型性能越好。MAE是一种常见的回归模型性能评估指标,它对误差的绝对值敏感,因此不会受到正负误差的相互抵消影响。这使得它在一些回归任务中更容易解释和使用。但需要注意的是,MAE没有考虑误差的权重,因此对于不同数据点的重要性一视同仁,对于一些特殊需求可能需要其他指标。
【9】Normalized Mean Error(NME)归一化平均误差
它是一种常见的统计指标,通常用于衡量预测值与实际值之间的平均误差,同时考虑了数据的范围。
计算 NME 的一般步骤如下:
1.对于每个数据点,计算预测值与实际值之间的差异,即误差,通常表示为 e(i)。
2.对每个误差值进行标准化,以考虑数据的范围。这通常包括将误差值除以某种范围或标准差。标准化的误差通常表示为 ne(i)。
3.对所有数据点的标准化误差值求和,得到总的标准化误差。
计算平均标准化误差,即将总的标准化误差除以数据点的数量(样本数),通常表示为 NME = Σne(i) / n,其中 n 表示数据点的数量。
NME 的值越小,表示模型的标准化平均误差越小,模型性能越好。NME通常用于回归问题的性能评估,特别是在需要考虑数据范围和标度的情况下。NME可以确保不同数据集的标准化误差可以进行比较,而不受数据范围的影响。
需要注意的是,具体的标准化方法和数据范围的定义可能因应用而异。因此,在使用 NME 时,应该清楚地了解如何进行标准化和范围的定义。
【10】(RMSE)平方根误差
RMSE 是均方根误差(Root Mean Square Error)的缩写,它是一种用于测量预测值与实际值之间差异的统计指标,通常用于评估回归模型的性能。均方根误差是均方误差的平方根。
均方根误差的计算方法如下:
- 对于每个数据点,计算预测值与实际值之间的差异,即误差(error),通常表示为 e(i)。
- 将每个误差值平方,得到误差的平方值,即 e(i)^2。
- 对所有数据点的平方误差值求和,得到总的平方误差,通常表示为 SSE(Sum of Squared Errors):SSE = Σ(e(i)^2),其中Σ 表示对所有数据点求和。
- 计算均方误差(MSE),即将总的平方误差除以数据点的数量(样本数),通常表示为 MSE = SSE / n,其中 n 表示数据点的数量。
- 最后,计算均方根误差(RMSE),即将均方误差的平方根,通常表示为 RMSE = √(MSE)。
RMSE 的值通常与预测值和实际值的单位相同,它衡量了预测值与实际值之间的平均差异,以及它们的相对大小。RMSE 越小,表示模型的预测值与实际值之间的差异越小,模型性能越好。
RMSE 是回归模型性能评估的常见指标之一,它对异常值(离群值)敏感,因为它是平方误差的平方根,所以大的异常值将对RMSE产生较大的影响。在一些情况下,可能需要考虑使用其他指标来减小异常值的影响。
【11】Cross-Entropy(CE)交叉熵损失
它是一种用于衡量两个概率分布之间的相似性的损失函数,经常用于分类问题中,特别是在深度学习和神经网络中。
在分类问题中,交叉熵损失(Cross-Entropy Loss)通常用于衡量模型的输出概率分布与真实标签(实际类别)的分布之间的差异。它的计算方法取决于问题的具体形式:
-
二元分类问题:对于二元分类,交叉熵损失通常定义为:
CE = -[y * log§ + (1 - y) * log(1 - p)]
其中,CE 是交叉熵损失,y 是真实标签(0或1),p 是模型的预测概率值。 -
多类分类问题:对于多类分类,交叉熵损失通常定义为:
CE = -Σ[y_i * log(p_i)]
其中,CE 是交叉熵损失,y_i 是真实标签的独热编码(one-hot encoding),p_i 是模型的预测概率分布中的第 i 个元素。
交叉熵损失在分类问题中被广泛使用,它对于正确分类的预测有较小的损失,对于错误分类的预测有较大的损失,因此鼓励模型更准确地进行分类。在深度学习中,交叉熵损失通常与 softmax 激活函数结合使用,以产生类别概率分布,然后计算损失。通过最小化交叉熵损失,可以训练神经网络以提高分类性能。
交叉熵损失还可以用于其他任务,如文本生成和自然语言处理中的语言模型训练。在这些情况下,它可以用于比较生成的文本分布与实际文本分布之间的相似性。
【12】(AUC)曲线下面积
AUC 是指 ROC 曲线下面积(Area Under the ROC Curve),它是一种用于评估二元分类模型性能的常见指标。ROC 曲线(Receiver Operating Characteristic curve)是一种图形工具,用于可视化二元分类模型在不同阈值下的性能。
AUC 衡量了 ROC 曲线下的面积,具体来说,它表示在所有可能的分类阈值下,模型将正类别样本排在负类别样本前面的概率。AUC 的取值范围通常在 0 到 1 之间,其中:
AUC = 0.5 表示模型的性能与随机猜测没有区别。
AUC < 0.5 表示模型性能不佳,可能比随机猜测还差。
AUC > 0.5 表示模型性能优于随机猜测,AUC 越接近 1,性能越好。
在二元分类问题中,AUC 是一个重要的性能指标,它独立于分类阈值的选择,因此能够全面评估模型在不同工作点下的性能。通常情况下,AUC 越高,表示模型越能够将正例排在负例前面,即具有更好的分类性能。
ROC 曲线是通过在不同阈值下计算真正例率(True Positive Rate,也称为召回率)和假正例率(False Positive Rate)而绘制的。AUC 是 ROC 曲线下的积分面积,它表示了模型在整个 ROC 空间中的性能。 AUC 的计算通常使用积分或近似方法进行。
AUC 是分类模型评估的一种常用指标,特别适用于不平衡数据集的情况,它提供了一个综合的性能度量,可以帮助选择最适合任务需求的模型。
【13】Intersection over Union(IoU)并集交集
它是一种用于评估对象检测和分割模型性能的指标。交并比衡量了模型预测的区域与实际目标区域之间的重叠程度,通常用于确定检测或分割的准确性。
IoU 的计算方法如下:
首先,确定模型预测的区域和实际目标区域。
计算两个区域的交集(Intersection,通常表示为 “I”)。
计算两个区域的并集(Union,通常表示为 “U”)。
最后,计算交并比(IoU):IoU = I / U。
IoU 的值范围通常在 0 到 1 之间,其中:
IoU = 0 表示模型的预测区域与实际目标没有重叠。
IoU = 1 表示模型的预测区域完全与实际目标区域重叠,即完美匹配。
在对象检测中,IoU 常用于确定模型的定位精度。通常,当 IoU 大于某个阈值(例如,0.5)时,将模型的预测视为正确的检测。这个阈值通常根据特定任务和数据集的要求而定。
在图像分割中,IoU 通常用于衡量模型生成的分割掩模与实际目标的重叠程度。较高的 IoU 值表示分割质量更高。
IoU 是一种常见的评估指标,特别适用于计算机视觉领域中的目标检测、实例分割和语义分割任务。它用于量化模型的性能,帮助确定模型的准确性和鲁棒性。
【14】Receiver Operating Characteristic curve(ROC)接收算子特征
它是一种用于评估二元分类模型性能的图形工具和指标。
ROC 曲线通常用于以下情境:
-
二元分类问题:ROC 曲线适用于二元分类问题,其中模型试图将样本分为两个类别,如正类别和负类别、真实类别和假类别等。
-
不同分类阈值:ROC 曲线显示了模型在不同分类阈值下的性能。通过在不同阈值下评估真正例率(True Positive Rate,也称为召回率)和假正例率(False Positive Rate),可以获得不同工作点下的性能度量。
-
比较模型性能:ROC 曲线允许比较不同模型在相同数据集上的性能。一条 ROC 曲线更靠近左上角(具体地说,更靠近 (0,1) 点)通常表示模型的性能更好。
-
选择分类阈值:ROC 曲线的形状和曲线下面积(AUC,Area Under the ROC Curve)可以帮助确定哪个分类阈值最适合特定任务需求。
ROC 曲线的绘制方式如下:
-
首先,根据分类模型的输出,根据不同的分类阈值将数据划分为真正例、假正例、真负例和假负例。
-
计算不同阈值下的真正例率(True Positive Rate,TPR)和假正例率(False Positive Rate,FPR)。TPR 表示正确识别正例的比例,而 FPR 表示错误将负例分类为正例的比例。
-
绘制 ROC 曲线,横轴表示 FPR,纵轴表示 TPR。ROC 曲线是以不同阈值下的 TPR 和 FPR 绘制的曲线。
-
计算 ROC 曲线下的面积(AUC),AUC 是一个综合性能指标,通常用于比较不同模型的性能。
ROC 曲线和 AUC 是用于评估二元分类模型性能的有力工具,它们能够帮助你了解模型的性能在不同工作点下的表现,以便更好地理解和选择模型。
【15】adversarial loss 对抗性损失
是一种在生成对抗网络(GAN)和对抗性训练(Adversarial Training)中常见的损失函数。它的目的是通过引入对抗性成分来提高模型的性能和鲁棒性。
在生成对抗网络(GAN)中,对抗性损失是由生成器和判别器之间的竞争来定义的。生成器试图生成伪造数据,使其足够逼真,以欺骗判别器。判别器则试图区分真实数据和伪造数据。对抗性损失的目标是最小化判别器能够正确区分的伪造数据的概率,从而使生成器生成更逼真的数据。
具体来说,对抗性损失通常采用以下形式:
-
对抗性损失的生成器部分:对生成器 G 的输出进行评估,目标是最大化判别器 D 无法区分生成数据和真实数据的概率。生成器的目标是最小化这一概率,因此生成器的对抗性损失通常定义为负对数概率,即 -log(1 - D(G(z))),其中 z 是生成器的输入噪声。
-
对抗性损失的判别器部分:对判别器 D 的目标是最大化其正确分类数据的能力,因此判别器的对抗性损失通常定义为最小化伪造数据被正确分类的概率,即 -log(D(G(z)))。
-
通过最小化生成器和判别器的对抗性损失,GAN 的训练目标是实现平衡,使生成器生成逼真的数据,同时使判别器难以区分真实和伪造数据。
-
在对抗性训练中,对抗性损失也常用于增强模型的鲁棒性。模型受到对抗性示例的攻击时,对抗性损失可以帮助模型抵御攻击并提高性能。例如,在对抗性训练中,对抗性损失可以鼓励模型在面对具有微小扰动的输入时保持稳定性。
对抗性损失在深度学习领域中具有重要意义,因为它推动了生成模型和鲁棒性改进的研究,尤其是在图像生成、自然语言处理和计算机视觉等领域。

















 2266
2266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









