







目录
代码已经封装好,对小白友好。
想要更换数据集,参考readme文件摆放好数据集即可,可以一键训练!!
1.代码介绍
整体特点:
-
技术先进性:结合了Swin Transformer和注意力机制,利用了当前先进的深度学习技术。
-
完整流程:覆盖了从数据准备、模型训练到应用部署的完整流程。
-
模块化设计:各组件职责明确,耦合度低,便于维护和扩展。
-
可视化丰富:提供多种训练过程和数据分布的可视化,便于模型分析和调试。
-
用户友好:通过GUI界面降低了使用门槛,使技术成果更易于实际应用。
-
文档完整:代码结构清晰,注释充分,便于理解和二次开发。
这套系统适合作为图像分类任务的基础框架,可以根据具体需求进行调整和扩展,具有较强的实用性和灵活性。
1. 主训练脚本train.py
train.py是系统的核心训练脚本,实现了完整的深度学习模型训练流程。
该脚本基于PyTorch框架,结合了Swin Transformer和CBAM注意力机制、多尺度特征融合,构建了一个强大的图像分类系统。
class SwinTransformerWithCBAM(nn.Module):
def __init__(self, num_classes=10, pretrained=False):
super(SwinTransformerWithCBAM, self).__init__()
self.swin = models.swin_b(weights='IMAGENET1K_V1' if pretrained else None)
# 获取各stage的实际输出通道数
self.stage_channels = [128, 256, 512, 1024]
# 添加CBAM模块
self.cbam1 = CBAM(self.stage_channels[0])
self.cbam2 = CBAM(self.stage_channels[1])
self.cbam3 = CBAM(self.stage_channels[2])
self.cbam4 = CBAM(self.stage_channels[3])
# 多尺度特征融合
self.multi_scale_fusion = MultiScaleFusion(
in_channels_list=self.stage_channels,
out_channels=256
)
# 分类头
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.head = nn.Linear(256, num_classes)
def forward(self, x):
features = []
# Stage 0: Patch Embedding
x = self.swin.features[0](x)
# Stage 1
x = self.swin.features[1](x)
x = x.permute(0, 3, 1, 2) # (B, C, H, W)
x = self.cbam1(x)
features.append(x)
x = x.permute(0, 2, 3, 1) # (B, H, W, C)
# Stage 2
x = self.swin.features[2](x) # Patch Merging
x = self.swin.features[3](x) # Stage2 blocks
x = x.permute(0, 3, 1, 2)
x = self.cbam2(x)
features.append(x)
x = x.permute(0, 2, 3, 1)
# Stage 3
x = self.swin.features[4](x) # Patch Merging
x = self.swin.features[5](x) # Stage3 blocks
x = x.permute(0, 3, 1, 2)
x = self.cbam3(x)
features.append(x)
x = x.permute(0, 2, 3, 1)
# Stage 4
x = self.swin.features[6](x) # Patch Merging
x = self.swin.features[7](x) # Stage4 blocks
x = x.permute(0, 3, 1, 2)
x = self.cbam4(x)
features.append(x)
# 多尺度特征融合
fused_features = self.multi_scale_fusion(features)
# 分类
x = self.avgpool(fused_features[-1])
x = torch.flatten(x, 1)
x = self.head(x)
return x主要功能包括:
-
参数配置与初始化:使用argparse模块处理命令行参数,包括模型选择、训练参数、数据路径等。创建保存结果的目录结构,记录训练配置信息。
-
数据准备:通过
data_trans()函数定义训练和验证数据的预处理流程,包括随机旋转、中心裁剪等增强操作。get_data()函数加载ImageFolder格式的数据集,并生成数据加载器。 -
模型构建:调用
create_model()函数创建Swin Transformer与CBAM、多尺度特征融合结合的混合模型,计算并记录模型参数量和计算量(FLOPs)。 -
训练流程:
- 使用Focal Loss作为损失函数,解决类别不平衡问题
- 实现余弦退火学习率调度策略
- 记录训练过程中的损失、准确率等指标
- 保存最佳模型和最后模型
-
评估与可视化:
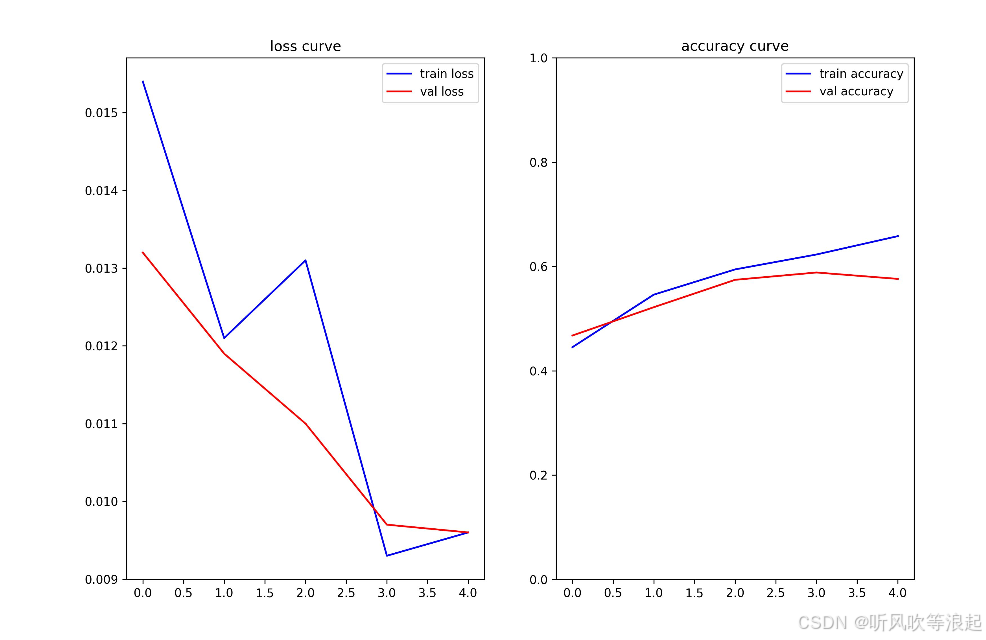
- 绘制训练/验证的损失和准确率曲线
- 生成混淆矩阵
- 计算并绘制ROC曲线和PR曲线
- 可视化数据集分布
-
测试功能:可选地加载测试集进行最终评估,保存测试结果。
该脚本设计完整,包含了从数据准备到模型评估的完整流程,并提供了丰富的可视化功能,便于分析模型性能。
2. 工具函数与模型定义utils.py
utils.py包含了系统的主要工具函数和模型定义,是train和qt推理的基础支持模块。
主要组成部分:
-
注意力机制模块:
ChannelAttention:通道注意力模块,学习不同通道的重要性SpatialAttention:空间注意力模块,学习空间位置的重要性CBAM:结合通道和空间注意力的混合模块
-
多尺度特征融合:
MultiScaleFusion类实现了自顶向下的多尺度特征融合策略,增强模型对不同尺度特征的捕捉能力。 -
核心模型定义:
SwinTransformerWithCBAM类将Swin Transformer与CBAM注意力机制结合:- 使用预训练的Swin Transformer作为主干网络
- 在各阶段输出后添加CBAM模块
- 实现多尺度特征融合
- 自定义分类头
-
工具函数:
- 数据预处理(
data_trans) - 数据集加载(
get_data) - 训练和评估函数(
train_one_epoch,evaluate) - 混淆矩阵计算(
ConfusionMatrix) - 各种可视化函数(损失曲线、ROC曲线等)
- Focal Loss实现
- 数据预处理(
-
辅助功能:
- 目录创建(
mkdir) - 设备获取(
get_device) - 信息保存(
save_info) - 数据集分布可视化(
plot_dataset_distribution)
- 目录创建(
该文档提供了模型的核心实现和各种辅助工具,设计上注重模块化和可重用性,各组件可以方便地被其他脚本调用。
3. GUI界面应用infer_QT.py
infer_QT.py基于PyQt5实现了用户友好的图形界面,使训练好的模型可以方便地用于实际图像分类任务。
主要特点:
-
模型封装:
ImageClassifier类封装了模型加载和预测功能:- 从文件加载训练好的模型权重
- 加载类别标签映射文件
- 实现图像预处理和预测接口
-
GUI设计:
- 主窗口(
MainWindow)包含图像显示区、结果展示区和控制按钮 - 响应式布局,适应不同窗口大小
- 现代简洁的界面风格
- 状态栏显示操作状态
- 主窗口(
-
功能实现:
- 文件对话框选择图像
- 图像显示与自适应缩放
- 模型预测与结果显示(支持多类别概率展示)
- 错误处理和状态反馈
-
用户体验优化:
- 清晰的界面分区
- 操作状态反馈
- 美观的样式设计
- 详细的识别结果展示
该GUI应用使非技术用户也能方便地使用训练好的模型进行图像分类,提高了系统的实用性和易用性。
2.自动驾驶地面路况识别
数据集如下:

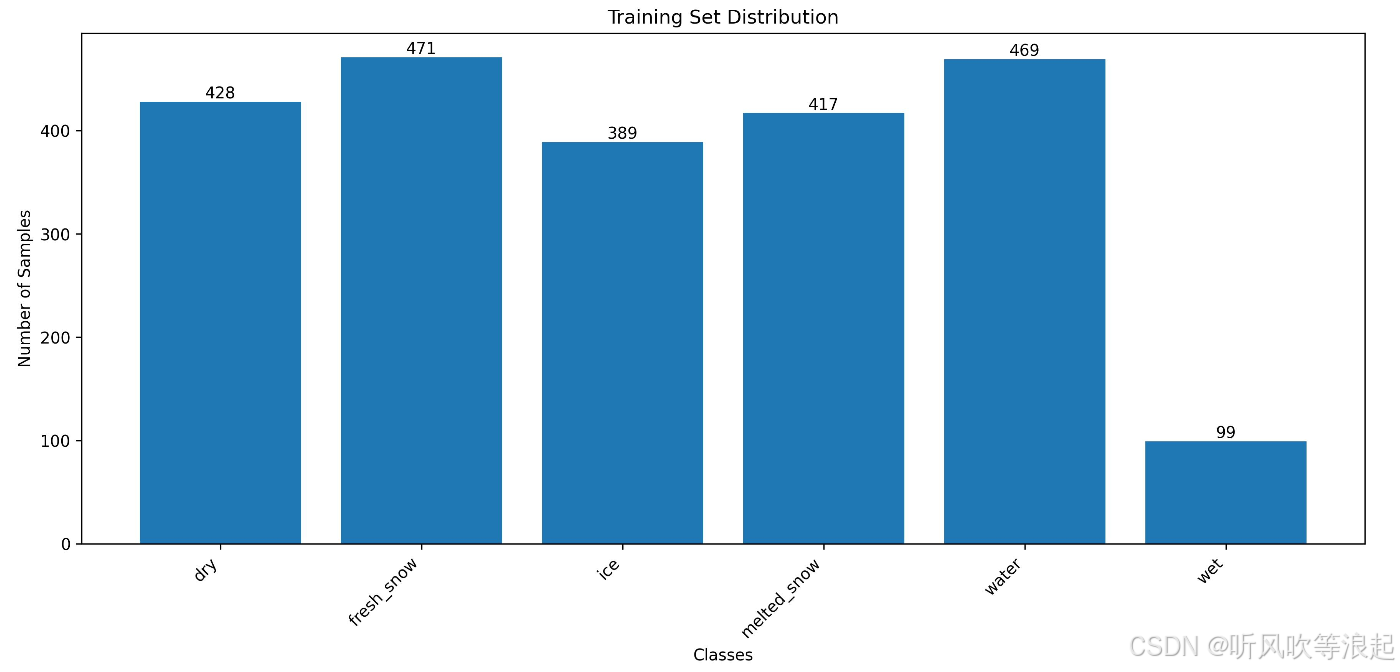
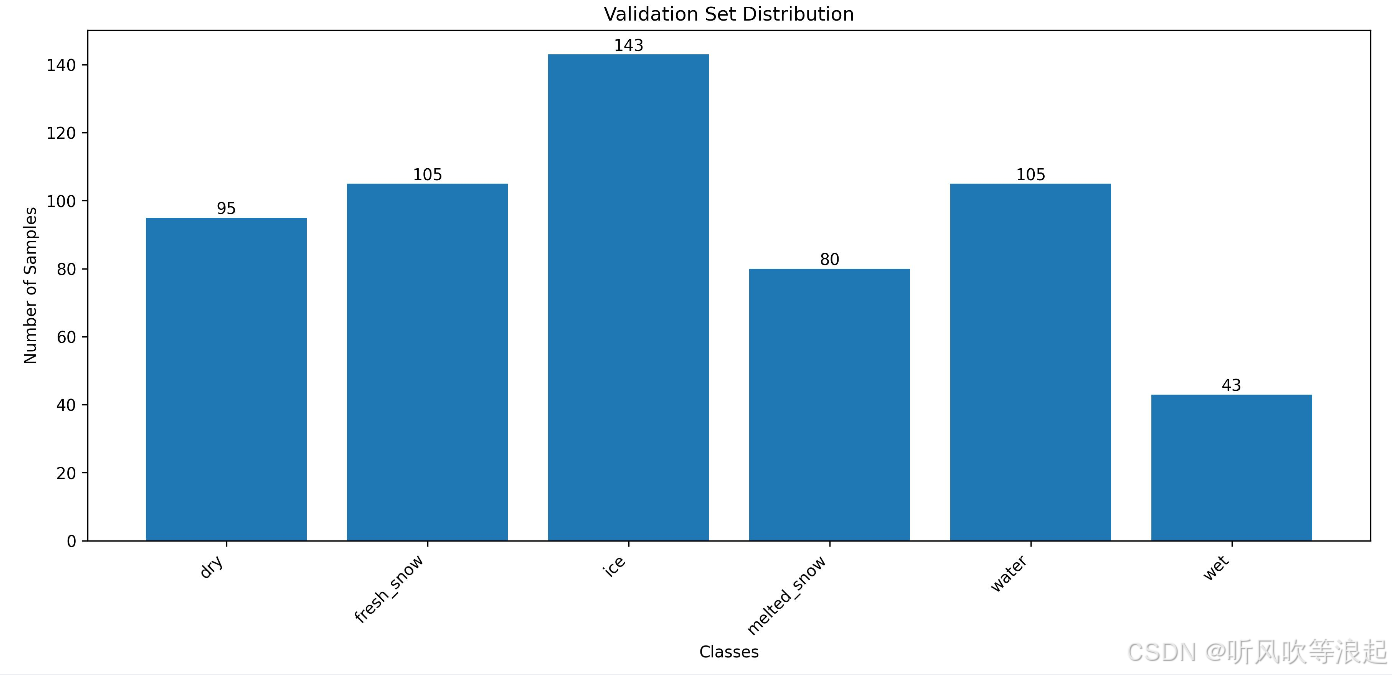
训练集和验证集的样本数量:【代码自动生成】
json标签:【代码自动生成】
{
"0": "dry",
"1": "fresh_snow",
"2": "ice",
"3": "melted_snow",
"4": "water",
"5": "wet"
}3.训练过程
参数如下:其实都很好理解的,就是常见的调参,这里不多介绍了
parser.add_argument("--model", default='swin-vit', type=str,help='swin-vit')
parser.add_argument("--pretrained", default=False, type=bool) # 采用官方权重
parser.add_argument("--batch-size", default=16, type=int)
parser.add_argument("--epochs", default=5, type=int)
parser.add_argument("--optim", default='Adam', type=str,help='SGD,Adam,AdamW') # 优化器选择
parser.add_argument('--lr', default=0.0001, type=float)
parser.add_argument('--lrf',default=0.0001,type=float) # 最终学习率 = lr * lrf
parser.add_argument('--save_ret', default='runs', type=str) # 保存结果
parser.add_argument('--data_train',default='./data/train',type=str) # 训练集路径
parser.add_argument('--data_val',default='./data/val',type=str)
# 测试集
parser.add_argument("--data-test", default=True, type=bool, help='if exists test sets')数据集的文件摆放,有测试集的话,设置为true,代码会自动测试【参考readme文件】
--data--train--- 训练集的图像
--data--val--- 验证集的图像
--data--test--- 测试集的图像(如果有的话)
这里的loss采用focal loss:
class FocalLoss(nn.Module):
def __init__(self, alpha=0.25, gamma=2.0, reduction='mean'):
# 增大 gamma 会更强调难分类样本
# 调整 alpha 可以平衡不同类别的权重
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
def forward(self, inputs, targets):
ce_loss = F.cross_entropy(inputs, targets, reduction='none')
pt = torch.exp(-ce_loss)
focal_loss = self.alpha * (1-pt)**self.gamma * ce_loss
if self.reduction == 'mean':
return focal_loss.mean()
elif self.reduction == 'sum':
return focal_loss.sum()
else:
return focal_loss
训练日志:这里进行简单训练
Namespace(batch_size=16, data_test=True, data_train='./data/train', data_val='./data/val', epochs=5, lr=0.0001, lrf=0.0001, model='swin-vit', optim='Adam', pretrained=False, save_ret='runs')
Using device is: cuda
Using dataloader workers is : 8
trainSet number is : 2273 valSet number is : 571
model output is : 6
SwinTransformerWithCBAM(
(swin): SwinTransformer(
(features): Sequential(
(0): Sequential(
(0): Conv2d(3, 128, kernel_size=(4, 4), stride=(4, 4))
(1): Permute()
(2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
)
(1): Sequential(
(0): SwinTransformerBlock(
(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=128, out_features=384, bias=True)
(proj): Linear(in_features=128, out_features=128, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.0, mode=row)
(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=128, out_features=512, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=512, out_features=128, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(1): SwinTransformerBlock(
(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=128, out_features=384, bias=True)
(proj): Linear(in_features=128, out_features=128, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.021739130434782608, mode=row)
(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=128, out_features=512, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=512, out_features=128, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
)
(2): PatchMerging(
(reduction): Linear(in_features=512, out_features=256, bias=False)
(norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(3): Sequential(
(0): SwinTransformerBlock(
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=256, out_features=768, bias=True)
(proj): Linear(in_features=256, out_features=256, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.043478260869565216, mode=row)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=1024, out_features=256, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(1): SwinTransformerBlock(
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=256, out_features=768, bias=True)
(proj): Linear(in_features=256, out_features=256, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.06521739130434782, mode=row)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=256, out_features=1024, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=1024, out_features=256, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
)
(4): PatchMerging(
(reduction): Linear(in_features=1024, out_features=512, bias=False)
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(5): Sequential(
(0): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.08695652173913043, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(1): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.10869565217391304, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(2): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.13043478260869565, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(3): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.15217391304347827, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(4): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.17391304347826086, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(5): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.1956521739130435, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(6): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.21739130434782608, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(7): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.2391304347826087, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(8): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.2608695652173913, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(9): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.2826086956521739, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(10): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.30434782608695654, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(11): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.32608695652173914, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(12): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.34782608695652173, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(13): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.3695652173913043, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(14): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.391304347826087, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(15): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.41304347826086957, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(16): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.43478260869565216, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(17): SwinTransformerBlock(
(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=512, out_features=1536, bias=True)
(proj): Linear(in_features=512, out_features=512, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.45652173913043476, mode=row)
(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=512, out_features=2048, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=2048, out_features=512, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
)
(6): PatchMerging(
(reduction): Linear(in_features=2048, out_features=1024, bias=False)
(norm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
)
(7): Sequential(
(0): SwinTransformerBlock(
(norm1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.4782608695652174, mode=row)
(norm2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=1024, out_features=4096, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
(1): SwinTransformerBlock(
(norm1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(attn): ShiftedWindowAttention(
(qkv): Linear(in_features=1024, out_features=3072, bias=True)
(proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(stochastic_depth): StochasticDepth(p=0.5, mode=row)
(norm2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(0): Linear(in_features=1024, out_features=4096, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.0, inplace=False)
(3): Linear(in_features=4096, out_features=1024, bias=True)
(4): Dropout(p=0.0, inplace=False)
)
)
)
)
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(permute): Permute()
(avgpool): AdaptiveAvgPool2d(output_size=1)
(flatten): Flatten(start_dim=1, end_dim=-1)
(head): Linear(in_features=1024, out_features=1000, bias=True)
)
(cbam1): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(128, 8, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(8, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
(cbam2): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(256, 16, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(16, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
(cbam3): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(512, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(32, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
(cbam4): CBAM(
(ca): ChannelAttention(
(avg_pool): AdaptiveAvgPool2d(output_size=1)
(max_pool): AdaptiveMaxPool2d(output_size=1)
(fc1): Conv2d(1024, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(relu1): ReLU()
(fc2): Conv2d(64, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(sigmoid): Sigmoid()
)
(sa): SpatialAttention(
(conv): Conv2d(2, 1, kernel_size=(7, 7), stride=(1, 1), padding=(3, 3), bias=False)
(sigmoid): Sigmoid()
)
)
(multi_scale_fusion): MultiScaleFusion(
(lateral_convs): ModuleList(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(3): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
)
(fusion_convs): ModuleList(
(0-3): 4 x Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(avgpool): AdaptiveAvgPool2d(output_size=1)
(head): Linear(in_features=256, out_features=6, bias=True)
)
[INFO] Register count_convNd() for <class 'torch.nn.modules.conv.Conv2d'>.
[INFO] Register count_normalization() for <class 'torch.nn.modules.normalization.LayerNorm'>.
[INFO] Register zero_ops() for <class 'torch.nn.modules.container.Sequential'>.
[INFO] Register count_linear() for <class 'torch.nn.modules.linear.Linear'>.
[INFO] Register zero_ops() for <class 'torch.nn.modules.dropout.Dropout'>.
[INFO] Register count_adap_avgpool() for <class 'torch.nn.modules.pooling.AdaptiveAvgPool2d'>.
[INFO] Register zero_ops() for <class 'torch.nn.modules.pooling.AdaptiveMaxPool2d'>.
[INFO] Register zero_ops() for <class 'torch.nn.modules.activation.ReLU'>.
Total parameters is:90.80 M
Train parameters is:90797102
Flops:12872.67 M
use optim is : Adam
开始训练...
train: 100%|██████████| 143/143 [01:32<00:00, 1.54it/s, accuracy=0.445, loss=0.174]
valid: 100%|██████████| 36/36 [00:29<00:00, 1.21it/s, accuracy=0.468, loss=0.0589]
[epoch:0/5]
train loss:0.0154 train accuracy:0.4452
val loss:0.0132 val accuracy:0.4676
train: 100%|██████████| 143/143 [01:31<00:00, 1.57it/s, accuracy=0.546, loss=0.121]
valid: 100%|██████████| 36/36 [00:29<00:00, 1.21it/s, accuracy=0.522, loss=0.0504]
train: 0%| | 0/143 [00:00<?, ?it/s][epoch:1/5]
train loss:0.0121 train accuracy:0.5460
val loss:0.0119 val accuracy:0.5219
train: 100%|██████████| 143/143 [01:28<00:00, 1.62it/s, accuracy=0.594, loss=0.442]
valid: 100%|██████████| 36/36 [00:29<00:00, 1.24it/s, accuracy=0.574, loss=0.0512]
train: 0%| | 0/143 [00:00<?, ?it/s][epoch:2/5]
train loss:0.0131 train accuracy:0.5944
val loss:0.0110 val accuracy:0.5744
train: 100%|██████████| 143/143 [01:27<00:00, 1.63it/s, accuracy=0.623, loss=0.0327]
valid: 100%|██████████| 36/36 [00:28<00:00, 1.24it/s, accuracy=0.588, loss=0.0539]
train: 0%| | 0/143 [00:00<?, ?it/s][epoch:3/5]
train loss:0.0093 train accuracy:0.6230
val loss:0.0097 val accuracy:0.5884
train: 100%|██████████| 143/143 [01:27<00:00, 1.63it/s, accuracy=0.658, loss=0.202]
valid: 100%|██████████| 36/36 [00:29<00:00, 1.23it/s, accuracy=0.576, loss=0.0476]
[epoch:4/5]
train loss:0.0096 train accuracy:0.6582
val loss:0.0096 val accuracy:0.5762
训练结束!!!
best epoch: 4
100%|██████████| 143/143 [00:37<00:00, 3.82it/s]
100%|██████████| 36/36 [00:25<00:00, 1.42it/s]
roc curve: 100%|██████████| 36/36 [00:25<00:00, 1.43it/s]
train finish!
验证集上表现最好的epoch为: 4
通过网络在测试集上进行测试
valid: 0%| | 0/19 [00:00<?, ?it/s]6
['dry', 'fresh_snow', 'ice', 'melted_snow', 'water', 'wet']
valid: 100%|██████████| 19/19 [00:04<00:00, 4.13it/s, accuracy=0.543, loss=0.0382]
{'accuracy': 0.5427631578768828, 'dry': {'Precision': 0.5663, 'Recall': 0.7966, 'Specificity': 0.8531, 'F1 score': 0.662}, 'fresh_snow': {'Precision': 0.6481, 'Recall': 0.9211, 'Specificity': 0.9286, 'F1 score': 0.7609}, 'ice': {'Precision': 0.1429, 'Recall': 0.0435, 'Specificity': 0.9535, 'F1 score': 0.0667}, 'melted_snow': {'Precision': 0.6456, 'Recall': 0.8226, 'Specificity': 0.8843, 'F1 score': 0.7234}, 'water': {'Precision': 0.4054, 'Recall': 0.4478, 'Specificity': 0.8143, 'F1 score': 0.4255}, 'wet': {'Precision': 0.0, 'Recall': 0.0, 'Specificity': 1.0, 'F1 score': 0.0}, 'mean precision': 0.40138333333333326, 'mean recall': 0.5052666666666666, 'mean specificity': 0.9056333333333333, 'mean f1 score': 0.43975000000000003}
测试集的结果保存在---->test_results.json训练生成的文件:
{
"train parameters": {
"model version": "swin-vit",
"pretrained": false,
"batch_size": 16,
"epochs": 5,
"optim": "Adam",
"lr": 0.0001,
"lrf": 0.0001,
"save_folder": "runs"
},
"dataset": {
"trainset number": 2273,
"valset number": 571,
"number classes": 6
},
"model": {
"total parameters": 90797102,
"train parameters": 90797102,
"flops": 12872672746.0
},
"epoch:0": {
"train info": {
"accuracy": 0.4452265728093039,
"dry": {
"Precision": 0.3983,
"Recall": 0.4486,
"Specificity": 0.8428,
"F1 score": 0.422
},
"fresh_snow": {
"Precision": 0.4553,
"Recall": 0.6815,
"Specificity": 0.7869,
"F1 score": 0.5459
},
"ice": {
"Precision": 0.3458,
"Recall": 0.2134,
"Specificity": 0.9167,
"F1 score": 0.2639
},
"melted_snow": {
"Precision": 0.6075,
"Recall": 0.8129,
"Specificity": 0.882,
"F1 score": 0.6953
},
"water": {
"Precision": 0.2683,
"Recall": 0.1642,
"Specificity": 0.8836,
"F1 score": 0.2037
},
"wet": {
"Precision": 0.0,
"Recall": 0.0,
"Specificity": 0.9995,
"F1 score": 0.0
},
"mean precision": 0.3458666666666666,
"mean recall": 0.3867666666666667,
"mean specificity": 0.8852500000000001,
"mean f1 score": 0.3551333333333333,
"train loss": 0.0154
},
"valid info": {
"accuracy": 0.46760070051720487,
"dry": {
"Precision": 0.4667,
"Recall": 0.7368,
"Specificity": 0.8319,
"F1 score": 0.5714
},
"fresh_snow": {
"Precision": 0.401,
"Recall": 0.7905,
"Specificity": 0.7339,
"F1 score": 0.5321
},
"ice": {
"Precision": 0.5301,
"Recall": 0.3077,
"Specificity": 0.9089,
"F1 score": 0.3894
},
"melted_snow": {
"Precision": 0.5929,
"Recall": 0.8375,
"Specificity": 0.9063,
"F1 score": 0.6943
},
"water": {
"Precision": 0.1667,
"Recall": 0.0286,
"Specificity": 0.9678,
"F1 score": 0.0488
},
"wet": {
"Precision": 0.0,
"Recall": 0.0,
"Specificity": 1.0,
"F1 score": 0.0
},
"mean precision": 0.35956666666666665,
"mean recall": 0.4501833333333333,
"mean specificity": 0.8914666666666666,
"mean f1 score": 0.37266666666666665,
"val loss": 0.0132
}
},
"epoch:1": {
"train info": {
"accuracy": 0.5459744830596306,
"dry": {
"Precision": 0.5168,
"Recall": 0.5748,
"Specificity": 0.8753,
"F1 score": 0.5443
},
"fresh_snow": {
"Precision": 0.6277,
"Recall": 0.8662,
"Specificity": 0.8657,
"F1 score": 0.7279
},
"ice": {
"Precision": 0.4167,
"Recall": 0.2185,
"Specificity": 0.9368,
"F1 score": 0.2867
},
"melted_snow": {
"Precision": 0.678,
"Recall": 0.8585,
"Specificity": 0.9084,
"F1 score": 0.7576
},
"water": {
"Precision": 0.347,
"Recall": 0.307,
"Specificity": 0.8498,
"F1 score": 0.3258
},
"wet": {
"Precision": 0.0,
"Recall": 0.0,
"Specificity": 1.0,
"F1 score": 0.0
},
"mean precision": 0.4310333333333334,
"mean recall": 0.47083333333333327,
"mean specificity": 0.906,
"mean f1 score": 0.44038333333333335,
"train loss": 0.0121
},
"valid info": {
"accuracy": 0.5218914185547829,
"dry": {
"Precision": 0.6087,
"Recall": 0.5895,
"Specificity": 0.9244,
"F1 score": 0.5989
},
"fresh_snow": {
"Precision": 0.5611,
"Recall": 0.9619,
"Specificity": 0.8305,
"F1 score": 0.7088
},
"ice": {
"Precision": 0.4222,
"Recall": 0.1329,
"Specificity": 0.9393,
"F1 score": 0.2022
},
"melted_snow": {
"Precision": 0.6228,
"Recall": 0.8875,
"Specificity": 0.9124,
"F1 score": 0.732
},
"water": {
"Precision": 0.3643,
"Recall": 0.4857,
"Specificity": 0.809,
"F1 score": 0.4163
},
"wet": {
"Precision": 0.0,
"Recall": 0.0,
"Specificity": 1.0,
"F1 score": 0.0
},
"mean precision": 0.42985000000000007,
"mean recall": 0.5095833333333334,
"mean specificity": 0.9026000000000001,
"mean f1 score": 0.4430333333333334,
"val loss": 0.0119
}
},
"epoch:2": {
"train info": {
"accuracy": 0.594368675756294,
"dry": {
"Precision": 0.5344,
"Recall": 0.6893,
"Specificity": 0.8607,
"F1 score": 0.602
},
"fresh_snow": {
"Precision": 0.6926,
"Recall": 0.8896,
"Specificity": 0.8968,
"F1 score": 0.7788
},
"ice": {
"Precision": 0.5,
"Recall": 0.2751,
"Specificity": 0.9432,
"F1 score": 0.3549
},
"melted_snow": {
"Precision": 0.728,
"Recall": 0.8921,
"Specificity": 0.9251,
"F1 score": 0.8017
},
"water": {
"Precision": 0.4041,
"Recall": 0.3369,
"Specificity": 0.8708,
"F1 score": 0.3675
},
"wet": {
"Precision": 0.0,
"Recall": 0.0,
"Specificity": 1.0,
"F1 score": 0.0
},
"mean precision": 0.4765166666666667,
"mean recall": 0.5138333333333334,
"mean specificity": 0.9161000000000001,
"mean f1 score": 0.48415,
"train loss": 0.0131
},
"valid info": {
"accuracy": 0.5744308231072779,
"dry": {
"Precision": 0.491,
"Recall": 0.8632,
"Specificity": 0.8214,
"F1 score": 0.626
},
"fresh_snow": {
"Precision": 0.8333,
"Recall": 0.7143,
"Specificity": 0.9678,
"F1 score": 0.7692
},
"ice": {
"Precision": 0.4762,
"Recall": 0.6993,
"Specificity": 0.743,
"F1 score": 0.5666
},
"melted_snow": {
"Precision": 0.7071,
"Recall": 0.875,
"Specificity": 0.9409,
"F1 score": 0.7821
},
"water": {
"Precision": 0.2,
"Recall": 0.0095,
"Specificity": 0.9914,
"F1 score": 0.0181
},
"wet": {
"Precision": 0.0,
"Recall": 0.0,
"Specificity": 1.0,
"F1 score": 0.0
},
"mean precision": 0.4512666666666667,
"mean recall": 0.5268833333333334,
"mean specificity": 0.9107500000000001,
"mean f1 score": 0.4603333333333333,
"val loss": 0.011
}
},
"epoch:3": {
"train info": {
"accuracy": 0.6229652441679588,
"dry": {
"Precision": 0.5638,
"Recall": 0.785,
"Specificity": 0.8591,
"F1 score": 0.6563
},
"fresh_snow": {
"Precision": 0.7576,
"Recall": 0.8429,
"Specificity": 0.9295,
"F1 score": 0.798
},
"ice": {
"Precision": 0.5523,
"Recall": 0.3393,
"Specificity": 0.9432,
"F1 score": 0.4204
},
"melted_snow": {
"Precision": 0.7421,
"Recall": 0.9041,
"Specificity": 0.9294,
"F1 score": 0.8151
},
"water": {
"Precision": 0.4286,
"Recall": 0.371,
"Specificity": 0.8714,
"F1 score": 0.3977
},
"wet": {
"Precision": 0.0,
"Recall": 0.0,
"Specificity": 1.0,
"F1 score": 0.0
},
"mean precision": 0.5074,
"mean recall": 0.5403833333333333,
"mean specificity": 0.9221,
"mean f1 score": 0.5145833333333333,
"train loss": 0.0093
},
"valid info": {
"accuracy": 0.5884413309879433,
"dry": {
"Precision": 0.5714,
"Recall": 0.8,
"Specificity": 0.8803,
"F1 score": 0.6666
},
"fresh_snow": {
"Precision": 0.7293,
"Recall": 0.9238,
"Specificity": 0.9227,
"F1 score": 0.8151
},
"ice": {
"Precision": 0.561,
"Recall": 0.3217,
"Specificity": 0.9159,
"F1 score": 0.4089
},
"melted_snow": {
"Precision": 0.6607,
"Recall": 0.925,
"Specificity": 0.9226,
"F1 score": 0.7708
},
"water": {
"Precision": 0.3874,
"Recall": 0.4095,
"Specificity": 0.8541,
"F1 score": 0.3981
},
"wet": {
"Precision": 0.0,
"Recall": 0.0,
"Specificity": 1.0,
"F1 score": 0.0
},
"mean precision": 0.4849666666666666,
"mean recall": 0.5633333333333334,
"mean specificity": 0.9159333333333334,
"mean f1 score": 0.5099166666666667,
"val loss": 0.0097
}
},
"epoch:4": {
"train info": {
"accuracy": 0.6581610206746231,
"dry": {
"Precision": 0.5916,
"Recall": 0.7921,
"Specificity": 0.8732,
"F1 score": 0.6773
},
"fresh_snow": {
"Precision": 0.8298,
"Recall": 0.9108,
"Specificity": 0.9512,
"F1 score": 0.8684
},
"ice": {
"Precision": 0.6278,
"Recall": 0.3599,
"Specificity": 0.9559,
"F1 score": 0.4575
},
"melted_snow": {
"Precision": 0.7451,
"Recall": 0.9113,
"Specificity": 0.93,
"F1 score": 0.8199
},
"water": {
"Precision": 0.4622,
"Recall": 0.4435,
"Specificity": 0.8659,
"F1 score": 0.4527
},
"wet": {
"Precision": 0.0,
"Recall": 0.0,
"Specificity": 1.0,
"F1 score": 0.0
},
"mean precision": 0.54275,
"mean recall": 0.5696,
"mean specificity": 0.9293666666666667,
"mean f1 score": 0.5459666666666667,
"train loss": 0.0096
},
"valid info": {
"accuracy": 0.5761821365923611,
"dry": {
"Precision": 0.5652,
"Recall": 0.8211,
"Specificity": 0.8739,
"F1 score": 0.6695
},
"fresh_snow": {
"Precision": 0.7252,
"Recall": 0.9048,
"Specificity": 0.9227,
"F1 score": 0.8051
},
"ice": {
"Precision": 0.6078,
"Recall": 0.2168,
"Specificity": 0.9533,
"F1 score": 0.3196
},
"melted_snow": {
"Precision": 0.7087,
"Recall": 0.9125,
"Specificity": 0.9389,
"F1 score": 0.7978
},
"water": {
"Precision": 0.3514,
"Recall": 0.4952,
"Specificity": 0.794,
"F1 score": 0.4111
},
"wet": {
"Precision": 0.0,
"Recall": 0.0,
"Specificity": 1.0,
"F1 score": 0.0
},
"mean precision": 0.49305,
"mean recall": 0.5584000000000001,
"mean specificity": 0.9138000000000001,
"mean f1 score": 0.5005166666666666,
"val loss": 0.0096
}
}
}
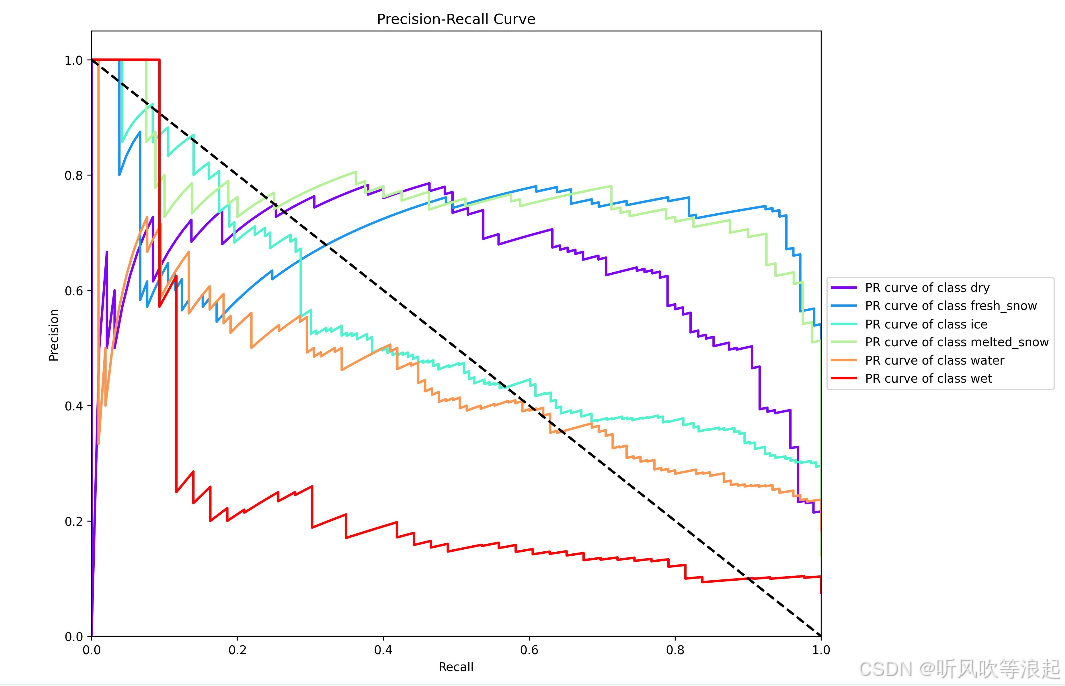
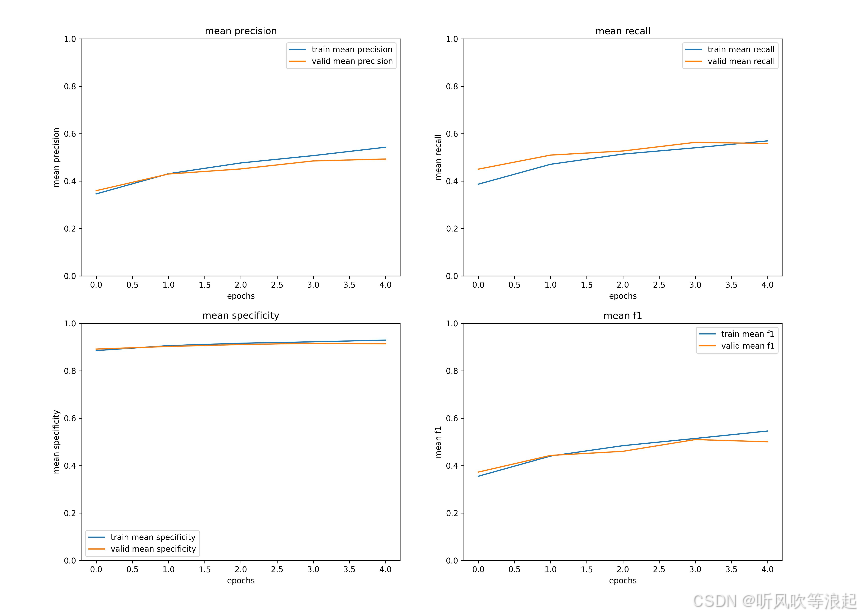
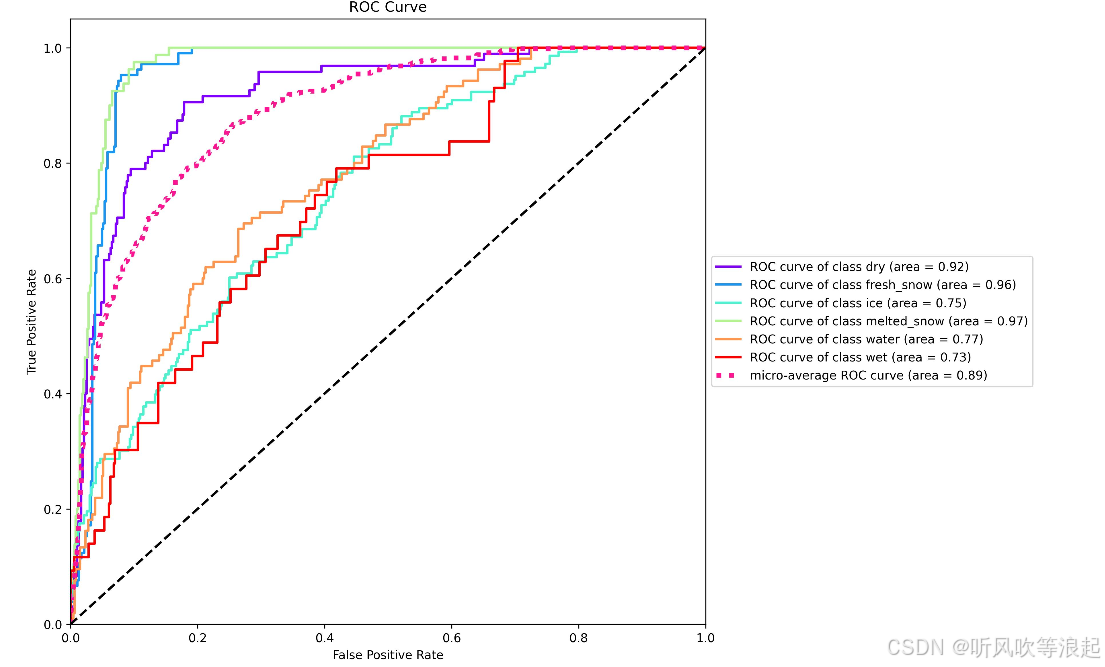
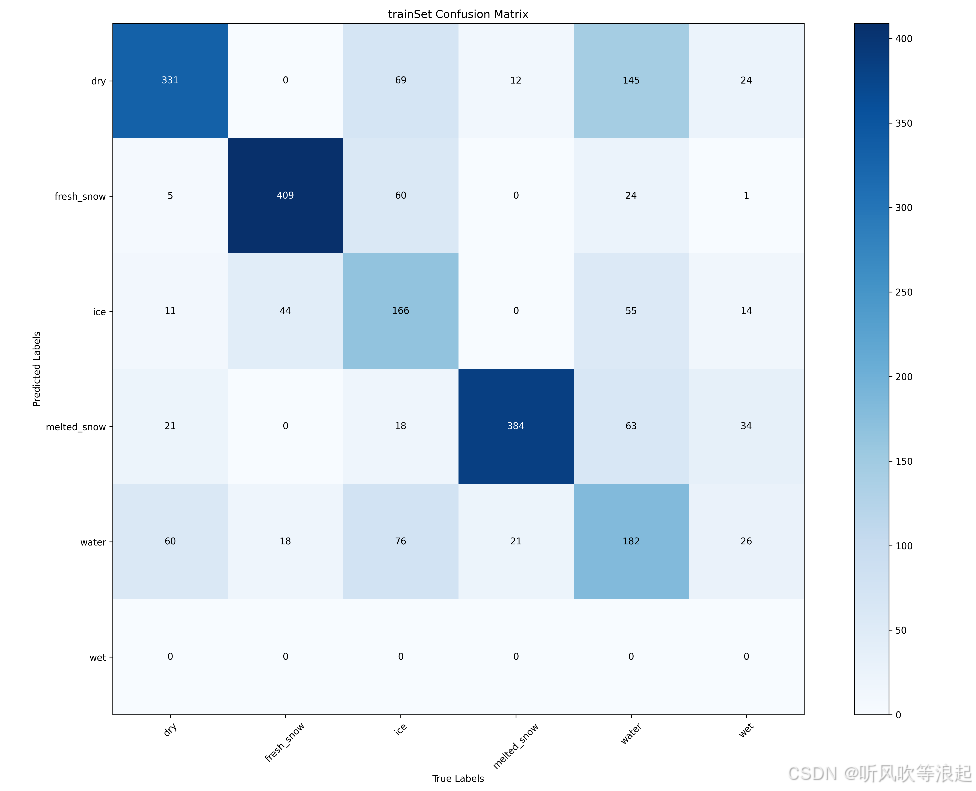
这些都是代码自动生成的,摆放好数据集即可:

4.推理
这里使用QT推理:
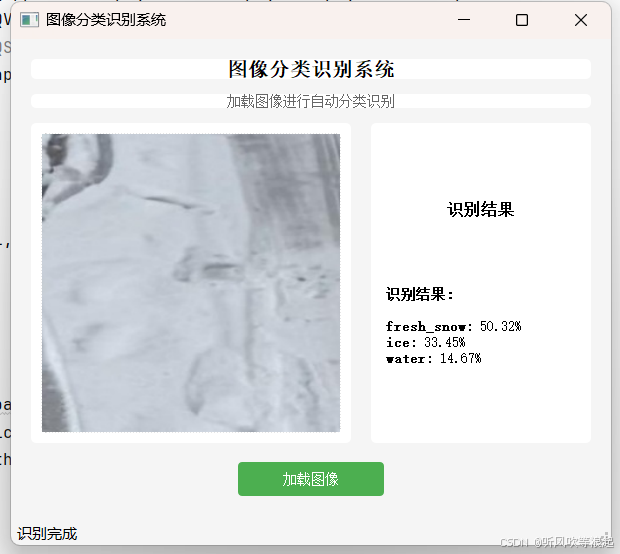
5.下载
下载地址:Swin-Transformer+CBAM+多尺度特征融合+Focalloss改进:自动驾驶路面信息分类资源-CSDN文库
关于神经网络的改进,可以关注本人专栏:AI 改进系列_听风吹等浪起的博客-CSDN博客



















 816
816

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











