







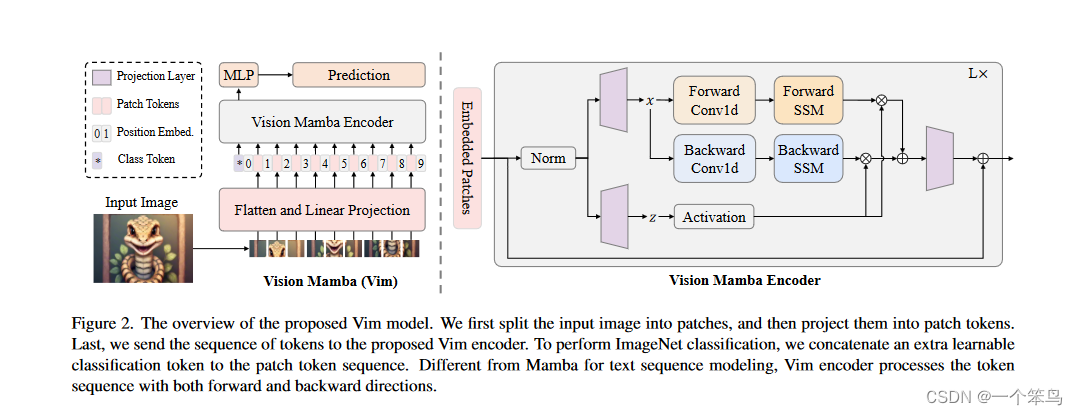
结构图:
小结:文章
致力于解决计算机视觉领域中,特别是在处理高分辨率图像时,Transformer架构存在的计算效率和内存使用上的限制问题。尽管Transformer在视觉表示学习上取得了显著成果,但由于自注意力机制在处理长距离依赖时具有二次时间复杂度和较高的内存消耗,使得在大规模高分辨率图像理解任务上面临挑战。
创新点在于:
-
提出了一种名为“Vision Mamba”(Vim)的新颖视觉骨干网络结构,该结构纯粹基于双向状态空间模型(SSM),尤其是借鉴了Mamba模型的硬件感知设计。Vim摒弃了自注意力机制,利用带有位置嵌入的双向选择性状态空间对视觉上下文进行有效压缩建模,并通过位置嵌入提供空间信息以增强位置敏感性识别能力。
-
Vim是首个纯SSM基线模型成功应用于密集预测任务,如语义分割、目标检测和实例分割等,并且与现有的典型视觉Transformer模型DeiT相比,在ImageNet分类任务上表现出更高的性能,同时在处理大尺寸图像时速度更快,GPU内存占用更少。例如,对于分辨率为1248×1248的图像,Vim在批量化特征提取时比DeiT快2.8倍,并节省了86.8%的GPU内存。
-
通过将Mamba中高效的状态空间模型方法引入计算机视觉,Vim不仅保留了Transformer风格模型对大规模无监督预训练和多模态应用友好的优点,而且克服了处理长序列时的计算和内存约束,为下一代视觉基础模型提供了可能的后端结构。


















 2389
2389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











