







论文:Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks
⭐⭐⭐⭐
TMLR 2023
Code:Program-of-Thoughts | GitHub
论文速读
文章提出了 PoT Prompting 方法,PoT 可以看作是 CoT(Chain-of-Thoughts)的改进,该方法通过生成 Python 程序代码来表达推理步骤,并通过 Python 解释器来执行这些代码从而完成计算,从而提高了数值推理任务的准确性和效率。论文在数学推理数据集和金融数据集上进行了实验,发现 PoT 比 CoT 更擅长解决这些复杂的计算推理问题。
文章展示了两种 PoT 方法:
- Few-shot PoT prompting:通过 in-context learning 的思路,给出几个 exemplars(QA 示例)让 LLM 学会去生成代码
- Zero-shot PoT prompting:直接通过文字提示的方法,让 LLM 去生成代码
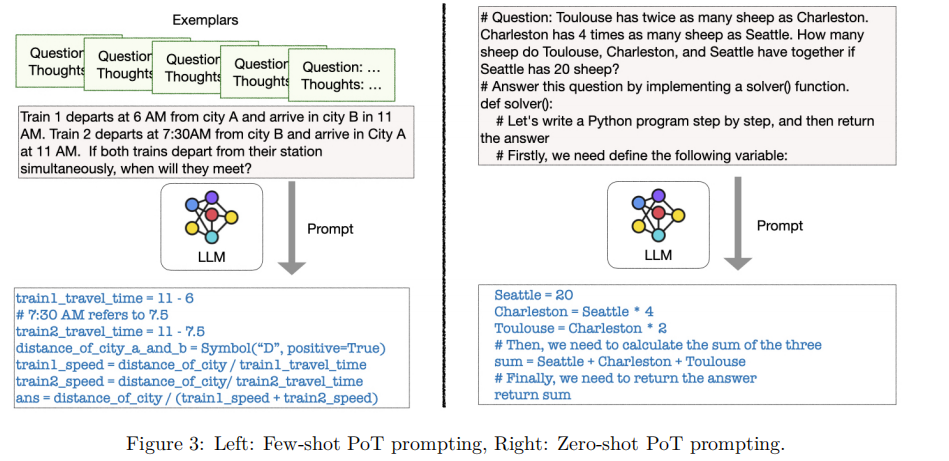
上图是两种 PoT 思路的示例,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4311
4311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









