







论文:Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
⭐⭐⭐⭐
Google DeepMind, ICLR 2024, arXiv:2310.06117
论文速读
该论文受到的启发是:人类再解决一个包含很多细节的具体问题时,先站在更高的层次上解决一些更加抽象的问题,可以拓展一个更宽阔的上下文环境,从而辅助解决这个具体的问题。
反应到 LLM 中,就是当问 LLM 一个具体的物理题目时,先让 LLM 解决一个更加高层次的抽象问题 这个问题背后用得到物理定律或法则是什么? ,然后再让 LLM 去解决那个包含了很多细节的具体的物理题目,可能效果就会更好,准确率更高。
因此,本论文提出了 Step-Back 的 prompting 思路,示例如下:
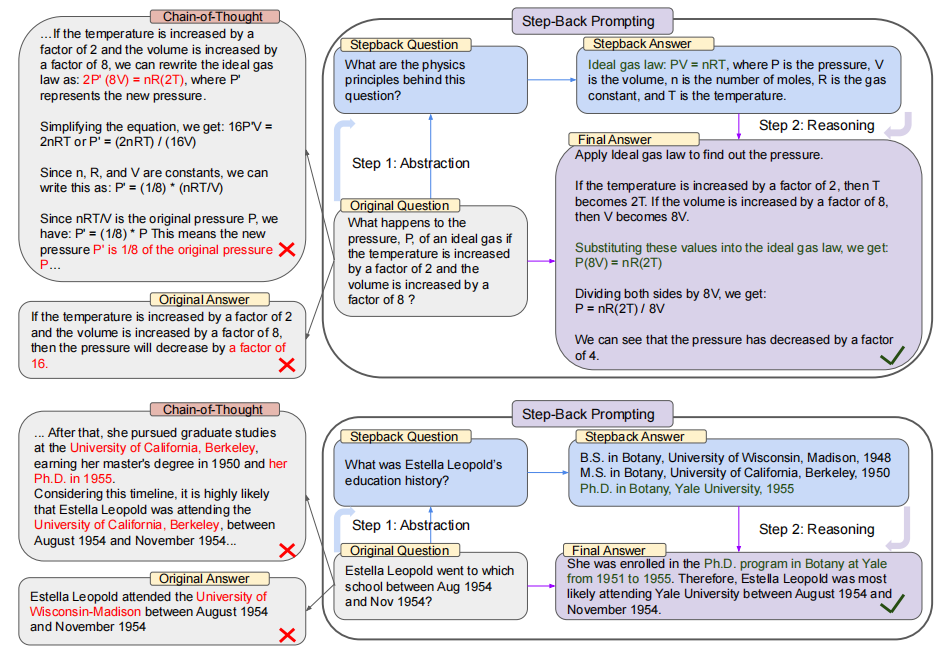
如上图所示,上半部分中,original question 是一个具体的物理问题,Step-Back Prompting 先让 LLM 进行抽象得到一个 StepBack Question,也就是“这个物理问题背后的物理定律是什么”,然后再去检索这个 StepBack Question 得到相关事实,然后基于以上信息去让 LLM 做 reasoning 得到 final answer。
简而言之,Step-Back Prompting 包含两个简单的步骤:
- Abstraction:先让 LLM 根据 original question 提出一个更高层次概念的 step-back question,并检索这个 step-back question 的相关事实
- Reasoning:基于高层次概念或原则的事实,LLM 就可以去推理原始问题的解决方案了。
分析讨论
StepBack Prompting 思路中的“抽象”通过去除不相关的细节和提炼高级概念或原则来指导具体问题的解决。
通过实验分析,abstraction 对于 LLM 来说是一个简单的任务,通过一些 few-shot exemplar 即可使用 in-context learning 来学会,但 reasoning 对于 LLM 来说仍然是最难学会的任务,在多个 error cases 上做分析,推理仍然是主要的错误来源。

















 2260
2260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









