







 文章探讨了在医疗影像诊断中应用差异隐私(DP)训练AI模型的效果。研究发现,即使在严格的隐私保护下,AI模型的诊断准确性和公平性仅轻微下降,证明了在保护患者隐私的同时,仍能保持良好的诊断性能和公平对待不同患者群体的能力。
文章探讨了在医疗影像诊断中应用差异隐私(DP)训练AI模型的效果。研究发现,即使在严格的隐私保护下,AI模型的诊断准确性和公平性仅轻微下降,证明了在保护患者隐私的同时,仍能保持良好的诊断性能和公平对待不同患者群体的能力。
Private, fair and accurate: Training large-scale, privacy-preserving AI models in medical imaging
摘要
- 由于医疗数据高度敏感,因此需要采取特殊措施来确保其得到保护。
- 隐私保护的黄金标准是在模型训练中引入差分隐私(DP)。
- 先前的工作表明DP对模型的准确性和公平性有负面影响,这在医学上是不可接受的,是广泛使用隐私保护技术的主要障碍。
- 在这项工作中,我们评估了用于胸片诊断的AI模型的隐私保护训练在准确性和公平性方面与非隐私训练的效果。
- 使用了一个大数据集(N = 193311)的高质量临床胸片,这些数据是由经验丰富的放射科医生回顾性收集和手动标记的。
- 非私有cnn在所有标签上的平均AUROC得分为0.90±0.04,而隐私预算为ε = 7.89的DP cnn的AUROC为0.87±0.04,即与非私有训练相比,性能仅下降2.6%。
- 隐私保护训练不会放大对年龄、性别或合并症的歧视。我们的研究表明,在现实生活临床数据集具有挑战性的现实情况下,诊断深度学习模型的隐私保护训练是可能的,具有出色的诊断准确性和公平性。
引言
用于医疗应用的人工智能(AI)系统的发展代表着一种微妙的权衡:
一方面,诊断模型必须提供高准确性和确定性,同时公平公正地对待不同的患者群体。
另一方面,临床医生和研究人员必须遵守伦理和法律的规定。对数据用于模型训练的患者的责任。
特别是,当诊断模型发布给意图无法验证的第三方时,必须小心确保患者隐私不受损害。隐私泄露可能会发生,例如通过数据重构、属性推断或成员推断攻击共享模型。
联邦学习已被提出作为解决其中一些问题的工具。然而,很明显,训练数据可以从联邦系统中进行分段逆向工程,使它们与集中式学习一样容易受到上述攻击。因此,显然需要正式的隐私保护方法来保护那些数据被用于训练诊断AI模型的患者。这方面的黄金标准是差异隐私(DP)
DP是一个包含一系列技术的正式框架,允许分析人员从敏感数据集中获得见解,同时保证保护其中的单个数据点。因此,DP是数据处理系统的一种属性,它规定在敏感数据集上的计算结果必须大致相同,无论数据集中是否包含或排除任何单个个体。形式上,一个随机算法(机制)M: X→Y满足(ε, δ)-DP,如果对数据库D, D0∈X的所有对在一行中不同,且所有S⊆Y,则如下所示:
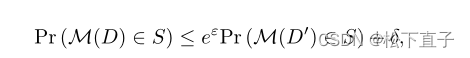
保证M的随机性,当D和D0交换时同样有效
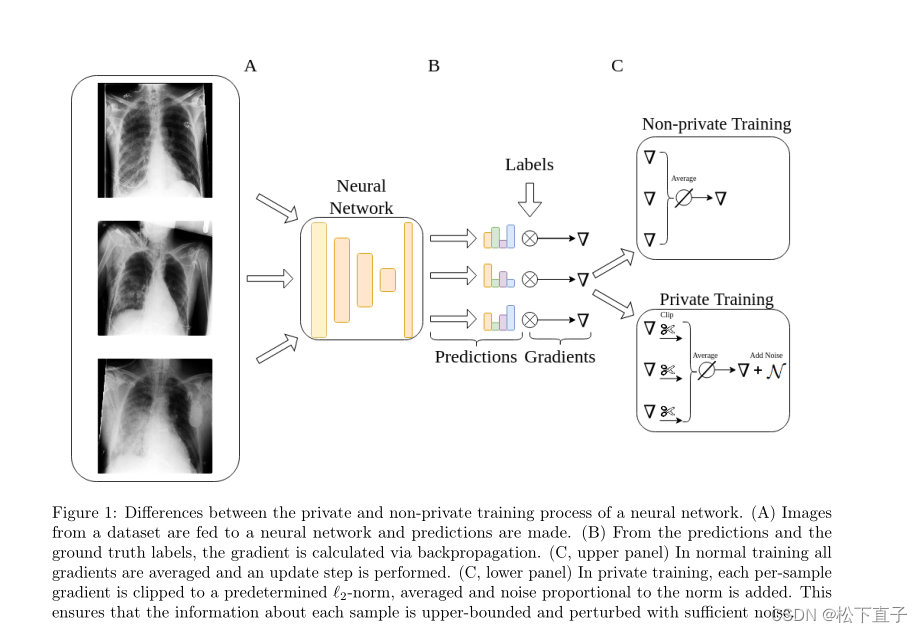
应用于神经网络训练,DP所需的随机化是通过在每个数据点被裁剪到’ l2范数后,对每个数据点计算的损失函数梯度添加校准的高斯噪声来确保其大小被约束。通过指定噪声方差和训练步数,可以直观地总结出总隐私支出,以ε和δ-值的形式从输入数据“飞”到模型的信息量,这些值表示所谓的隐私预算。ε和δ值越小,隐私保障越强。定量隐私保证可以通过复杂算法的多次迭代(组合)计算,例如用于训练神经网络的算法,这是DP所独有的。这个过程通常被称为privacy accounting
尽管使用DP进行训练提供了针对隶属度推断和重建攻击的正式(和经验)保护,其强度与所选择的隐私级别成正比,但DP的使用也产生了两个基本的权衡。第一种是“隐私-效用权衡”,即当需要更强的隐私保障时,诊断准确性会降低。另一个问题是隐私和公平之间的权衡。直观地说,AI模型在训练数据中对代表性不足的患者群体的学习比例较少,这一事实被DP放大了(DP进一步限制了关于他们的信息流),导致模型预测或诊断中的人口统计学差异。在敏感的应用程序(如医疗应用程序)中,这两种权衡都很微妙,因为错误的诊断或歧视特定的患者群体是不可接受的
上述考虑概述了准确性、公平性和隐私之间的基本紧张关系,这种紧张关系存在于医疗应用的不同隐私模型的训练中。到目前为止,这些权衡只在基准数据集中进行了评估,如CIFAR-10或ImageNet。因此,我们认为保护隐私的机器学习的广泛使用需要在现实环境中进行测试。在当前的研究中,我们对这一主题进行了首次深入调查。具体而言,我们利用了一个由放射科医生标记的放射图像组成的大型临床数据库,该数据库以前曾用于训练专家级诊断AI模型,但没有以任何方式对私人培训进行策划或预处理。这反映了临床机构可用的数据集类型。在这种情况下,我们然后研究在训练高级计算机视觉架构时隐私效用和隐私公平的权衡程度。我们的主要贡献可以总结如下:
- 我们研究了差异私有深度学习在大型重症监护病房胸片数据库多标签分类中的诊断准确性分支。我们发现,通过在公共数据集上使用迁移学习和仔细选择架构,与非私有训练相比,准确性的降低可以忽略不计。
- 我们调查了在关键人口统计学特征(如性别、年龄和共同发病率)方面差异性私人学习的公平性影响。我们发现,尽管不同的私人学习有着温和的公平影响-与非私人训练相比,它不会引入显著的区别问题


















 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











