







 Y-Net是一种双编码器网络,专门设计用于医学图像分割,特别是光学相干断层扫描(OCT)图像。网络包含空间特征编码器和频域特征编码器,利用傅立叶变换在频域中捕获全局信息,然后与空间信息结合,提升分割性能。通过不同比例的融合策略,网络能够适应性地结合两种域的特征,优化分割结果。
Y-Net是一种双编码器网络,专门设计用于医学图像分割,特别是光学相干断层扫描(OCT)图像。网络包含空间特征编码器和频域特征编码器,利用傅立叶变换在频域中捕获全局信息,然后与空间信息结合,提升分割性能。通过不同比例的融合策略,网络能够适应性地结合两种域的特征,优化分割结果。
Y-Net: A Spatiospectral Dual-Encoder Network for Medical Image Segmentation
- YNet,这是一种将频域特征与图像域相结合的架构,以提高OCT图像的分割性能。
- 引入两个分支,一个用于光谱特征,另一个用于空间域特征
代码链接
本文方法
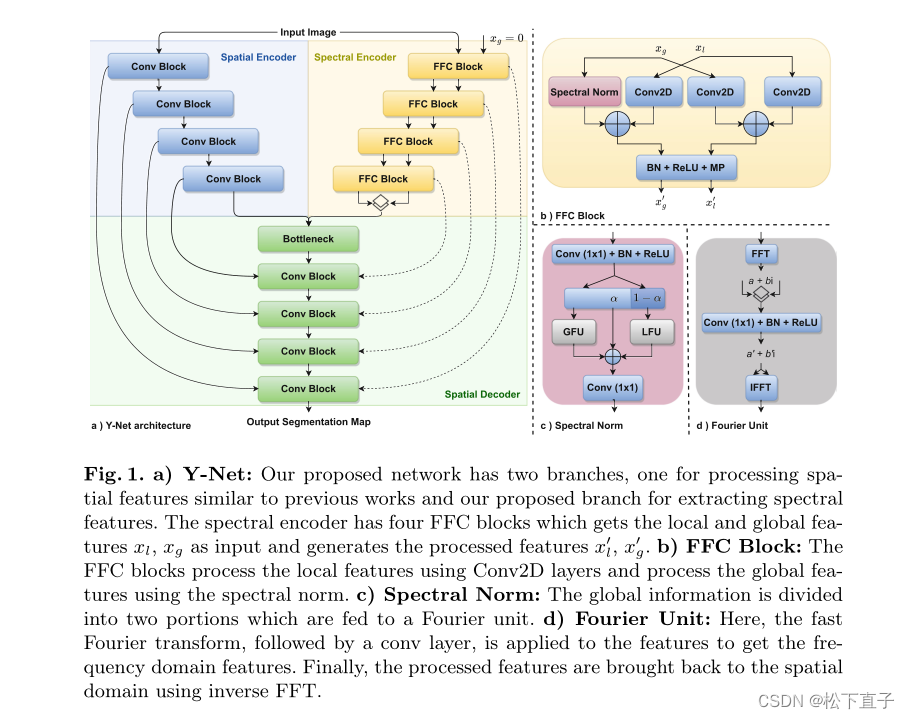
Y-Net:我们提出的网络有两个分支,一个用于处理类似于先前工作的空间特征,另一个用于提取光谱特征。频谱编码器具有四个FFC块,其获得局部和全局特征xl、xg作为输入,并生成处理后的特征
FFC块:FFC块使用Conv2D层处理局部特征,并使用谱范数处理全局特征
谱范数:全局信息被分为两部分,这两部分被馈送到傅立叶单元
傅立叶单元:在这里,将快速傅立叶变换,然后是conv层,应用于特征以获得频域特征。最后,使用逆FFT将处理后的特征带回空间域
损失函数
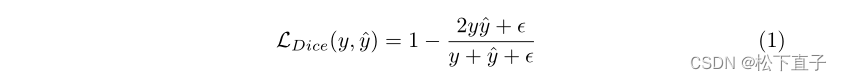
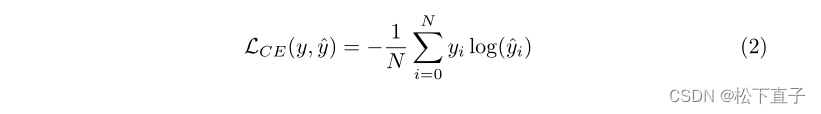
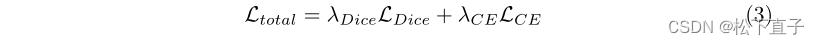
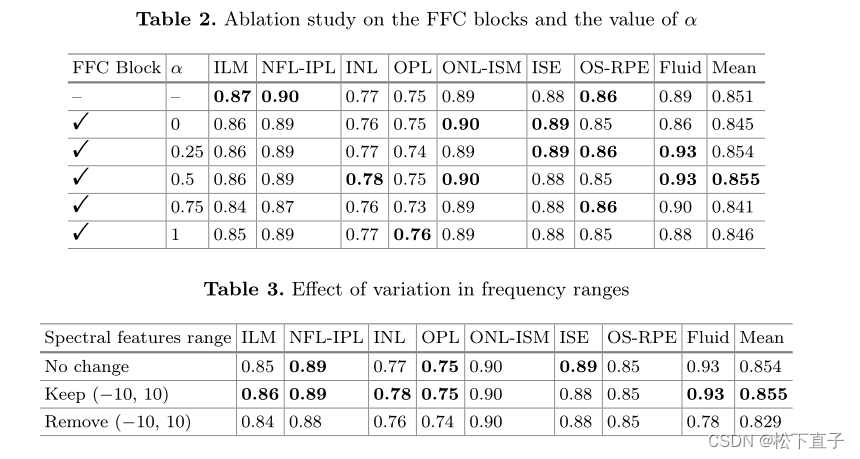
实验结果
代码
这里只看整个网络前向传播代码
def forward(self, x):
batch = x.shape[0]
enc1 = self.encoder1(x)# 普通卷积
enc2 = self.encoder2(self.pool1(enc1))
enc3 = self.encoder3(self.pool2(enc2))
enc4 = self.encoder4(self.pool3(enc3))
enc4_2 = self.pool4(enc4)
if self.ffc:##采用傅里叶变换
enc1_f = self.encoder1_f(x)
enc1_l, enc1_g = enc1_f
if self.ratio_in == 0:
enc2_f = self.encoder2_f((self.pool1_f(enc1_l), enc1_g))
elif self.ratio_in == 1:
enc2_f = self.encoder2_f((enc1_l, self.pool1_f(enc1_g)))
else:
enc2_f = self.encoder2_f((self.pool1_f(enc1_l), self.pool1_f(enc1_g)))
enc2_l, enc2_g = enc2_f
if self.ratio_in == 0:
enc3_f = self.encoder3_f((self.pool2_f(enc2_l), enc2_g))
elif self.ratio_in == 1:
enc3_f = self.encoder3_f((enc2_l, self.pool2_f(enc2_g)))
else:
enc3_f = self.encoder3_f((self.pool2_f(enc2_l), self.pool2_f(enc2_g)))
enc3_l, enc3_g = enc3_f
if self.ratio_in == 0:
enc4_f = self.encoder4_f((self.pool3_f(enc3_l), enc3_g))
elif self.ratio_in == 1:
enc4_f = self.encoder4_f((enc3_l, self.pool3_f(enc3_g)))
else:
enc4_f = self.encoder4_f((self.pool3_f(enc3_l), self.pool3_f(enc3_g)))
enc4_l, enc4_g = enc4_f
if self.ratio_in == 0:
enc4_f2 = self.pool1_f(enc4_l)
elif self.ratio_in == 1:
enc4_f2 = self.pool1_f(enc4_g)
else:
enc4_f2 = self.catLayer((self.pool4_f(enc4_l), self.pool4_f(enc4_g)))
else:
enc1_f = self.encoder1_f(x)
enc2_f = self.encoder2_f(self.pool1_f(enc1_f))
enc3_f = self.encoder3_f(self.pool2_f(enc2_f))
enc4_f = self.encoder4_f(self.pool3_f(enc3_f))
enc4_f2 = self.pool4(enc4_f)
if self.cat_merge:
a = torch.zeros_like(enc4_2)
b = torch.zeros_like(enc4_f2)
enc4_2 = enc4_2.view(torch.numel(enc4_2), 1)
enc4_f2 = enc4_f2.view(torch.numel(enc4_f2), 1)
bottleneck = torch.cat((enc4_2, enc4_f2), 1)
bottleneck = bottleneck.view_as(torch.cat((a, b), 1))
else:
bottleneck = torch.cat((enc4_2, enc4_f2), 1)
bottleneck = self.bottleneck(bottleneck)
dec4 = self.upconv4(bottleneck)
if self.ffc and self.skip_ffc:
enc4_in = torch.cat((enc4, self.catLayer((enc4_f[0], enc4_f[1]))), dim=1)
dec4 = torch.cat((dec4, enc4_in), dim=1)
dec4 = self.decoder4(dec4)
dec3 = self.upconv3(dec4)
enc3_in = torch.cat((enc3, self.catLayer((enc3_f[0], enc3_f[1]))), dim=1)
dec3 = torch.cat((dec3, enc3_in), dim=1)
dec3 = self.decoder3(dec3)
dec2 = self.upconv2(dec3)
enc2_in = torch.cat((enc2, self.catLayer((enc2_f[0], enc2_f[1]))), dim=1)
dec2 = torch.cat((dec2, enc2_in), dim=1)
dec2 = self.decoder2(dec2)
dec1 = self.upconv1(dec2)
enc1_in = torch.cat((enc1, self.catLayer((enc1_f[0], enc1_f[1]))), dim=1)
dec1 = torch.cat((dec1, enc1_in), dim=1)
elif self.skip_ffc:
enc4_in = torch.cat((enc4, enc4_f), dim=1)
dec4 = torch.cat((dec4, enc4_in), dim=1)
dec4 = self.decoder4(dec4)
dec3 = self.upconv3(dec4)
enc3_in = torch.cat((enc3, enc3_f), dim=1)
dec3 = torch.cat((dec3, enc3_in), dim=1)
dec3 = self.decoder3(dec3)
dec2 = self.upconv2(dec3)
enc2_in = torch.cat((enc2, enc2_f), dim=1)
dec2 = torch.cat((dec2, enc2_in), dim=1)
dec2 = self.decoder2(dec2)
dec1 = self.upconv1(dec2)
enc1_in = torch.cat((enc1, enc1_f), dim=1)
dec1 = torch.cat((dec1, enc1_in), dim=1)
else:
dec4 = torch.cat((dec4, enc4), dim=1)
dec4 = self.decoder4(dec4)
dec3 = self.upconv3(dec4)
dec3 = torch.cat((dec3, enc3), dim=1)
dec3 = self.decoder3(dec3)
dec2 = self.upconv2(dec3)
dec2 = torch.cat((dec2, enc2), dim=1)
dec2 = self.decoder2(dec2)
dec1 = self.upconv1(dec2)
dec1 = torch.cat((dec1, enc1), dim=1)
dec1 = self.decoder1(dec1)
return self.softmax(self.conv(dec1))


















 2484
2484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











