







看这一篇就够了。本文内含YOLOv11网络结构图 + yaml配置文件详细解读与说明 + 训练教程 + 训练参数设置+参数解析说明等一些有关YOLOv11的内容!
YOLOv8v10v11专栏限时199元订阅链接:
限时199元去b站关注:AI缝合怪订阅YOLOv8v10v11 创新改进高效涨点+持续改进500多篇
(订阅的小伙伴,终身免费享有后续YOLOv12或是其他版本的改进专栏)
目录
一、YOLOv11简介
YOLOv11是由Ultralytics公司开发的新一代目标检测算法,它在之前YOLO版本的基础上进行了显著的架构和训练方法改进。整合了改进的模型结构设计、增强的特征提取技术和优化的训练方法。真正让YOLO11脱颖而出的是它令人印象深刻的速度、准确性和效率的结合,使其成为Ultralytics迄今为止创造的最强大的型号之一。通过改进设计,YOLO11提供了更好的特征提取,这是从图像中识别重要模式和细节的过程,即使在具有挑战性的场景中,也可以更准确地捕捉复杂的方面。
YOLO11m在COCO数据集上实现了更高的平均精度(mAP)得分,同时使用的参数比YOLOv8m少22%,使其在不牺牲性能的情况下计算更轻。这意味着它提供了更准确的结果,同时运行效率更高。最重要的是,YOLO11带来了更快的处理速度,推理时间比YOLOv10快约2%,使其成为实时应用程序的理想选择。
本文详细介绍YOLOv11的网络结构,YOLOv11网络主要包含Backbone、Neck和Head 3个部分。
-
Backbone采用C3k2f模块,通过Bottleneck Block、SPPF和C2PSA模块提升特征提取能力。
-
Neck颈部网络位于主干网络和头部网络之间,它的作用是进行特征融合和增强。
-
Head头部网络是目标检测模型的决策部分,负责产生最终的检测结果。
YOLOv11整体网络结构图
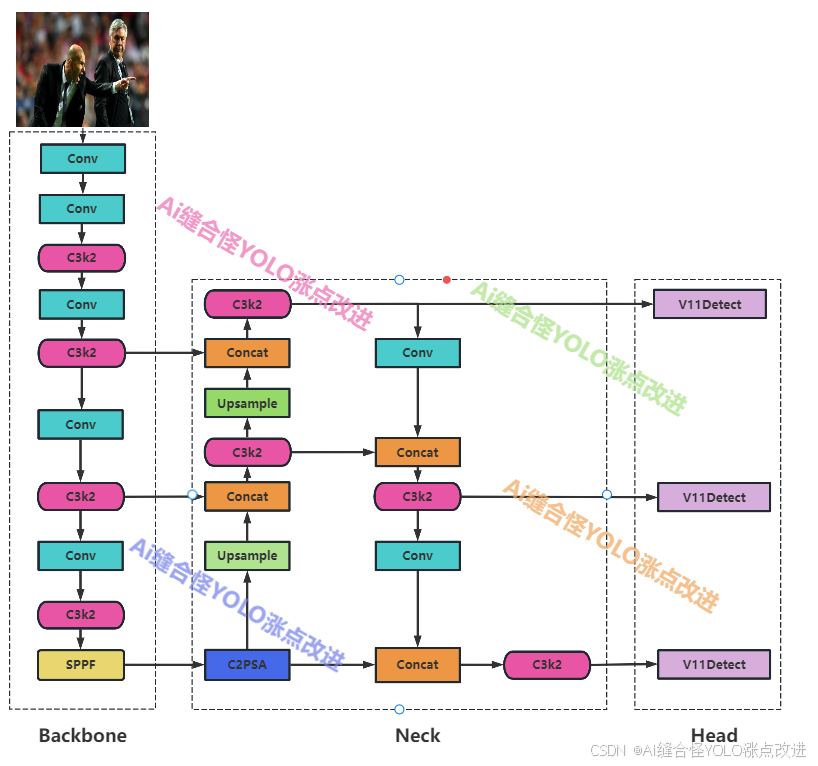
YOLOv11的网络结构主要由以下三个大部分组成
Backbone
Backbone部分负责特征提取,采用了一系列卷积和反卷积层,同时使用了残差连接和瓶颈结构来减小网络的大小并提高性能。YOLOv11使用C3K2块来处理主干不同阶段的特征提取。较小的3x3内核允许更有效的计算,同时保留模型捕获图像中基本特征的能力。YOLOv11主干的核心是C3K2块,它是早期版本中引入的CSP(跨阶段部分)瓶颈的演变。C3K2模块通过分割特征图并应用一系列较小的内核卷积(3x3)来优化网络中的信息流,这比较大的内核卷积更快,计算成本更低。通过处理较小的独立特征图并在几次卷积后合并它们,C3K2模块与YOLOv8的C2f模块相比,使用更少的参数来改进特征表示。
C2PSA块使用两个PSA(部分空间注意力)模块,它们在特征图的不同分支上操作,然后连接起来,类似于C2F块结构。这种设置确保模型专注于空间信息,同时保持计算成本和检测精度之间的平衡。C2PSA模块通过在提取的特征上应用空间注意力来细化模型选择性地关注感兴趣区域的能力。这使得YOLOv11在精确检测需要精细对象细节的场景中优于YOLOv8等以前的版本。
此外,Backbone部分还包括一些常见的改进技术,如缝合一些卷积模块,注意力模块,替换主干网络等改进,以进一步增强特征提取的能力。后续会更新大量相关部分改进点。
Neck
Neck颈部网络位于主干网络和头部网络之间,它的作用是进行特征融合和增强。后续会更新大量相关部分改进点。
Head
Head头部网络是目标检测模型的决策部分,负责产生最终的检测结果。后续会更新大量相关部分改进点。
二、yolov11.yaml配置文件进行详细讲解
配置文件主要分为三个部分: 参数部分【Parameters】,主干部分【backone】,头部部分【head】。下面分别对这几个部分进行详细说明。
关于YOLOv11网络的配置文件yolov11.yaml的详细内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.1 参数部分【Parameters】
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
-
nc: 80指的是数据集中的类别数量。 -
scales:代表模型尺寸,分了n,s,m,l,x这5个不同大小的尺寸,参数量依次从小到大。 -
[depth, width, max_channels]:分别表示网络模型的深度因子、网络模型的宽度因子、最大通道数。 -
depth深度因子的作用:表示模型中重复模块的数量或层数的缩放比例。这里主要用来调整C3k2模块中的子模块Bottelneck重复次数。比如主干中第一个C3k2模块的number系数是3,我们使用0.5x3并且向上取整就等于1了,这就代表第一个C3k2模块中Bottelneck只重复一次; -
width宽度因子的作用:表示模型中通道数(即特征图的深度)的缩放比例,如果某个层原本有64个通道,而width设置为0.5,则该层的通道数变为32。比如使用yolov11n.yaml文件,参数为[0.50, 0.25, 1024]。第一个Conv模块的输出通道数写的是64,但是实际上这个通道数并不是64,而是使用宽度因子0.25x64得到的最终结果16;同理,C3k2模块的输出通道虽然在yaml文件上写的是128,但是在实际使用时依然要乘上宽度因子0.25,那么第一个C3k2模块最终的到实际通道数就是0.25x128 = 32。如下图所示,其他的依次类推。 -
max-channels:表示每层最大通道数。每层的通道数会与这个参数进行一个对比,如果特征图通道数大于这个数,那就取max_channels的值。
2.2 主干部分【backbone】
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10主干部分有四个参数[from, number, module, args] ,解释如下:
-
from:这个参数代表从哪一层获得输入,-1就表示从上一层获得输入,[-1, 6]就表示从上一层和第6层这两层获得输入。第一层比较特殊,这里第一层上一层 没有输入,from默认-1就好了。 -
number:这个参数表示模块重复的次数,如果为2则表示该模块重复3次,这里并不一定是这个模块的重复次数,也有可能是这个模块中的子模块重复的次数。对于C3k2模块来说,这个number就代表C3k2中Bottelneck或是C3k模块重复的次数。 -
module:这个就代表你这层使用的模块的名称,比如你第一层使用了Conv模块,第三层使用了C3k2模块。 -
args:表示这个模块需要传入的参数,第一个参数均表示该层的输出通道数。对于第一层conv参数【64,3,2】:64代表输出通道数,3代表卷积核大小k,2代表stride步长。每层输入通道数,默认是上一层的输出通道数。
其他说明:各层注释中的P1/2表示该层特征图缩放为输入图像尺寸的1/2,是第1特征层;P2/4表示该层特征图缩放为输入图像尺寸的1/4,是第2特征层;其他的依次类推。
2.3 头部【head】
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
头部分有四个参数[from, number, module, args] ,解释如下:
-
from:这个参数代表从哪一层获得输入,-1就表示从上一层获得输入,[-1, 6]就表示从上一层和第6层这两层获得输入。第一层比较特殊,这里第一层上一层 没有输入,from默认-1就好了。 -
number:这个参数表示模块重复的次数,如果为2则表示该模块重复3次,这里并不一定是这个模块的重复次数,也有可能是这个模块中的子模块重复的次数。对于C3k2模块来说,这个number就代表C3k2中Bottelneck或是C3k模块重复的次数。 -
module:这个就代表你这层使用的模块的名称,比如你第一层使用了Conv模块,第三层使用了C3k2模块。 -
args:表示这个模块需要传入的参数,第一个参数均表示该层的输出通道数。对于第一层conv参数【64,3,2】:64代表输出通道数,3代表卷积核大小k,2代表stride步长。每层输入通道数,默认是上一层的输出通道数。 -
这部分主要多出4个操作C2PSA
,nn.Upsample、Concat、Detect,解释如下: -
C2PSA注意力机制:C2PSA块使用两个PSA(部分空间注意力)模块,它们在特征图的不同分支上操作,然后连接起来,类似于C2F块结构。这种设置确保模型专注于空间信息,同时保持计算成本和检测精度之间的平衡。C2PSA模块通过在提取的特征上应用空间注意力来细化模型选择性地关注感兴趣区域的能力。
-
nn.Upsample:表示上采样,将特征图大小进行翻倍操作。比如将大小为20X20的特征图,变为40X40的特征图大小。 -
Concat:代表拼接操作,将相同大小的特征图,通道进行拼接,要求是特征图大小一致,通道数可以不相同。例如[-1, 6]:-1代表上一层,6代表第六层(从第0层开始数),将上一层与第6层进行concat拼接操作。 -
Detect的from有三个数:15,18,21,这三个就是最终网络的输出特征图,分别对应P3,P4,P5。
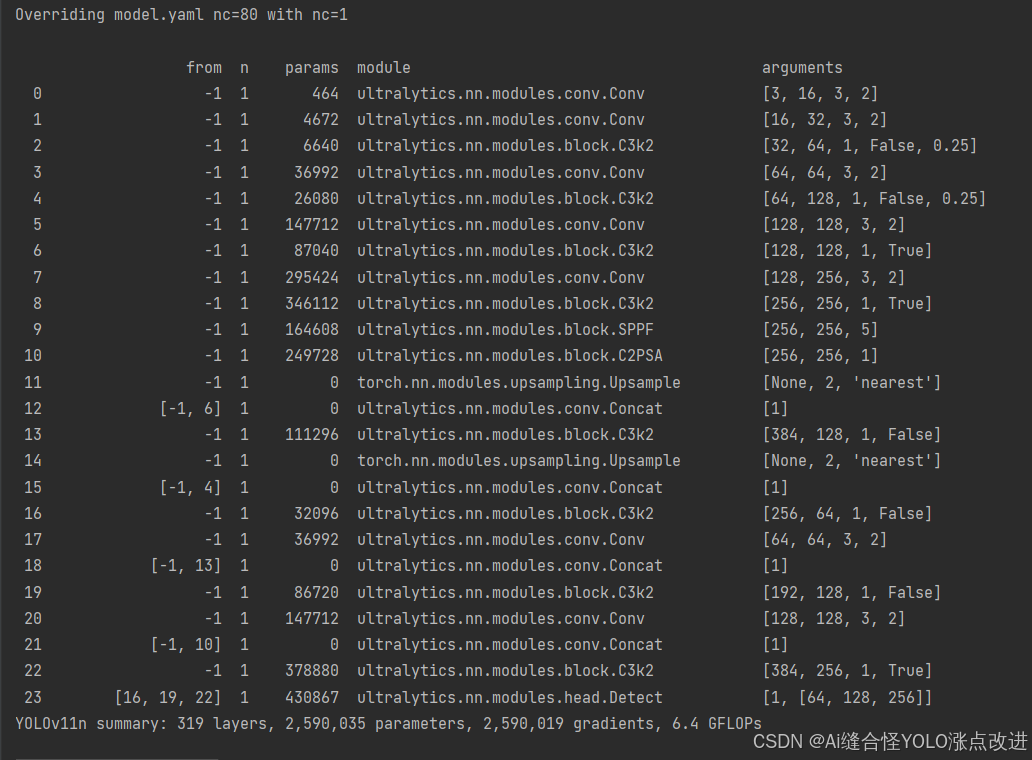
模型训练时打印出的结构参数如下,下图为yolov11n.yaml打印信息:
三、YOLOv11模型训练参数详细解析
关于yolov11的训练参数该如何设置。接下来对yolov11的相关训练参数和使用方法进行了详细说明。希望对大家有所帮助!
3.1 YOLOv11模型训练代码
YOLOv11目标检测模型训练时使用的代码如下:
from ultralytics import YOLO
# 加载官方预训练模型
model = YOLO("yolov11n.pt",task="detect")
# 模型训练
results = model.train(data="data.yaml", epochs=100, batch=4)YOLOv11图像分割模型训练时使用的代码如下:
from ultralytics import YOLO
# 加载官方预训练模型
model = YOLO("yolov11n.pt",task="segment")
# 模型训练
results = model.train(data="data.yaml", epochs=100, batch=4)YOLOv11模型训练脚本train.py代码如下:
from ultralytics import YOLO as YOLO
import warnings
warnings.filterwarnings('ignore')
# 模型配置文件
model_yaml_path = r'E:\yolo\ultralytics-main\yolov11\ultralytics\cfg\models\addv11\yolov11n.yaml'
#数据集配置文件
data_yaml_path = r'E:\yolo\ultralytics-main\yolov11\datasets\data.yaml'
if __name__ == '__main__':
model = YOLO(model_yaml_path)
#训练模型
results = model.train(data=data_yaml_path,
imgsz=640,
epochs=30,
batch=4,
workers=0,
amp=False, # 如果出现训练损失为Nan可以关闭amp
project='runs/V11train',
name='exp',
)
3.2 模型大小选择
model = YOLO("yolov11n.pt") 表示使用的是v8n模型来训练。如果想使用其他大小的模型,只需要把n改为其他大小的对应字母即可。例如:
model = YOLO("yolov11s.pt")
model = YOLO("yolov11m.pt")
model = YOLO("yolov11l.pt")
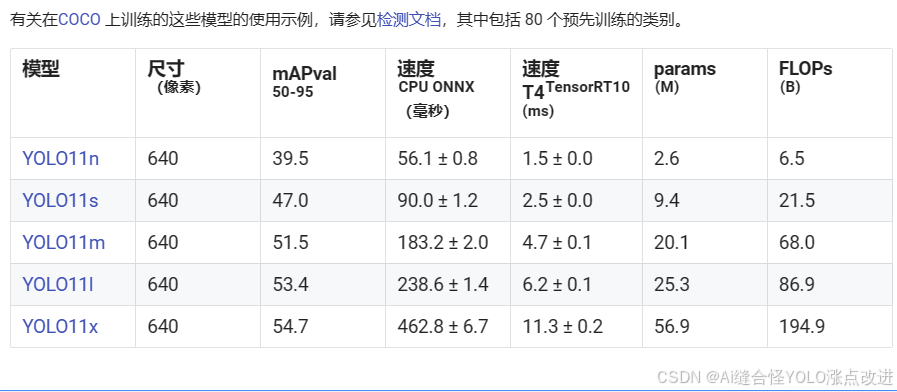
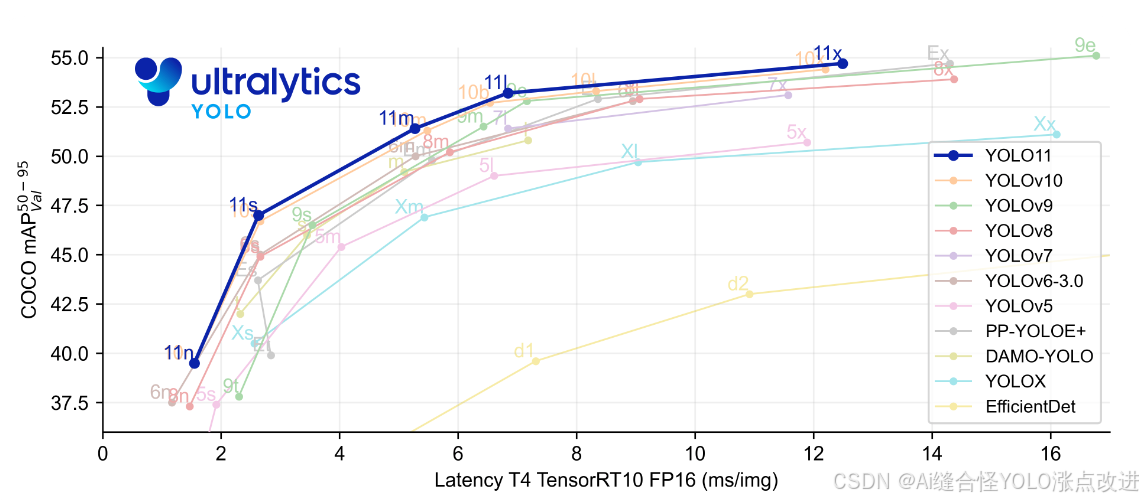
model = YOLO("yolov11x.pt")不同模型参数大小如下,v11n是参数量最小的模型。一般情况下,模型越大,最终模型的性能效果也会越好。可根据自己实际需求选择相应的模型大小进行训练。
3.3 训练参数设置
通过运行model.train(data="data.yaml", epochs=100, batch=4)训练v11模型,其中(data="data.yaml", epochs=100, batch=4)是训练设置的参数,没有添加的训练参数都是使用的默认值。官方其实给出了很多其他相关参数,详细说明见下文。
如果我们需要自己修改其他训练参数,只需要在train后面的括号中加入相应的参数和具体值即可。
例如加上模型训练优化器参数optimizer,其默认值是auto。
可设置的值为:SGD, Adam, AdamW, NAdam, RAdam, RMSProp。常用SGD或者AdamW。
我们可以直接将其设置为SGD,写法如下:
# 模型训练,添加模型优化器设置
results = model.train(data="data.yaml", epochs=100, batch=4, optimizer='SGD')3.4 训练参数说明
YOLOv11 模型的训练设置包括训练过程中使用的各种超参数和配置。这些设置会影响模型的性能、速度和准确性。关键的训练设置包括批量大小、学习率、动量和权重衰减。此外,优化器、损失函数和训练数据集组成的选择也会影响训练过程。对这些设置进行仔细的调整和实验对于优化性能至关重要。以下是官方给出了训练可设置参数和说明:
| 参数 | 默认值 | 说明 |
|---|---|---|
model | None | 指定用于训练的模型文件。接受指向 .pt 预训练模型或 .yaml 配置文件。对于定义模型结构或初始化权重至关重要。 |
data | None | 数据集配置文件的路径(例如 coco8.yaml).该文件包含特定于数据集的参数,包括训练数据和验证数据的路径、类名和类数。 |
epochs | 100 | 训练总轮数。每个epoch代表对整个数据集进行一次完整的训练。调整该值会影响训练时间和模型性能。 |
time | None | 最长训练时间(小时)。如果设置了该值,则会覆盖 epochs 参数,允许训练在指定的持续时间后自动停止。对于时间有限的训练场景非常有用。 |
patience | 100 | 在验证指标没有改善的情况下,提前停止训练所需的epoch数。当性能趋于平稳时停止训练,有助于防止过度拟合。 |
batch | 16 | 批量大小,有三种模式:设置为整数(例如,' Batch =16 '), 60% GPU内存利用率的自动模式(' Batch =-1 '),或指定利用率分数的自动模式(' Batch =0.70 ')。 |
imgsz | 640 | 用于训练的目标图像尺寸。所有图像在输入模型前都会被调整到这一尺寸。影响模型精度和计算复杂度。 |
save | True | 可保存训练检查点和最终模型权重。这对恢复训练或模型部署非常有用。 |
save_period | -1 | 保存模型检查点的频率,以 epochs 为单位。值为-1 时将禁用此功能。该功能适用于在长时间训练过程中保存临时模型。 |
cache | False | 在内存中缓存数据集图像 (True/ram)、磁盘 (disk),或禁用它 (False).通过减少磁盘 I/O 提高训练速度,但代价是增加内存使用量。 |
device | None | 指定用于训练的计算设备:单个 GPU (device=0)、多个 GPU (device=0,1)、CPU (device=cpu),或苹果芯片的 MPS (device=mps). |
workers | 8 | 加载数据的工作线程数(每 RANK 多 GPU 训练)。影响数据预处理和输入模型的速度,尤其适用于多 GPU 设置。 |
project | None | 保存训练结果的项目目录名称。允许有组织地存储不同的实验。 |
name | None | 训练运行的名称。用于在项目文件夹内创建一个子目录,用于存储训练日志和输出结果。 |
exist_ok | False | 如果为 True,则允许覆盖现有的项目/名称目录。这对迭代实验非常有用,无需手动清除之前的输出。 |
pretrained | True | 决定是否从预处理模型开始训练。可以是布尔值,也可以是加载权重的特定模型的字符串路径。提高训练效率和模型性能。 |
optimizer | 'auto' | 为训练模型选择优化器。选项包括 SGD, Adam, AdamW, NAdam, RAdam, RMSProp 等,或 auto 用于根据模型配置进行自动选择。影响收敛速度和稳定性 |
verbose | False | 在训练过程中启用冗长输出,提供详细日志和进度更新。有助于调试和密切监控培训过程。 |
seed | 0 | 为训练设置随机种子,确保在相同配置下运行的结果具有可重复性。 |
deterministic | True | 强制使用确定性算法,确保可重复性,但由于对非确定性算法的限制,可能会影响性能和速度。 |
single_cls | False | 在训练过程中将多类数据集中的所有类别视为单一类别。适用于二元分类任务,或侧重于对象的存在而非分类。 |
rect | False | 可进行矩形训练,优化批次组成以减少填充。这可以提高效率和速度,但可能会影响模型的准确性。 |
cos_lr | False | 利用余弦学习率调度器,根据历时的余弦曲线调整学习率。这有助于管理学习率,实现更好的收敛。 |
close_mosaic | 10 | 在训练完成前禁用最后 N 个epoch的马赛克数据增强以稳定训练。设置为 0 则禁用此功能。 |
resume | False | 从上次保存的检查点恢复训练。自动加载模型权重、优化器状态和历时计数,无缝继续训练。 |
amp | True | 启用自动混合精度 (AMP) 训练,可减少内存使用量并加快训练速度,同时将对精度的影响降至最低。 |
fraction | 1.0 | 指定用于训练的数据集的部分。允许在完整数据集的子集上进行训练,这对实验或资源有限的情况非常有用。 |
profile | False | 在训练过程中,可对ONNX 和TensorRT 速度进行剖析,有助于优化模型部署。 |
freeze | None | 冻结模型的前 N 层或按索引指定的层,从而减少可训练参数的数量。这对微调或迁移学习非常有用。 |
lr0 | 0.01 | 初始学习率(即 SGD=1E-2, Adam=1E-3) .调整这个值对优化过程至关重要,会影响模型权重的更新速度。 |
lrf | 0.01 | 最终学习率占初始学习率的百分比 = (lr0 * lrf),与调度程序结合使用,随着时间的推移调整学习率。 |
momentum | 0.937 | 用于 SGD 的动量因子,或用于 Adam 优化器的 beta1,用于将过去的梯度纳入当前更新。 |
weight_decay | 0.0005 | L2 正则化项,对大权重进行惩罚,以防止过度拟合。 |
warmup_epochs | 3.0 | 学习率预热的历元数,学习率从低值逐渐增加到初始学习率,以在早期稳定训练。 |
warmup_momentum | 0.8 | 热身阶段的初始动力,在热身期间逐渐调整到设定动力。 |
warmup_bias_lr | 0.1 | 热身阶段的偏置参数学习率,有助于稳定初始历元的模型训练。 |
box | 7.5 | 损失函数中边框损失部分的权重,影响对准确预测边框坐标的重视程度。 |
cls | 0.5 | 分类损失在总损失函数中的权重,影响正确分类预测相对于其他部分的重要性。 |
dfl | 1.5 | 分布焦点损失权重,在某些YOLO 版本中用于精细分类。 |
pose | 12.0 | 姿态损失在姿态估计模型中的权重,影响着准确预测姿态关键点的重点。 |
kobj | 2.0 | 姿态估计模型中关键点对象性损失的权重,平衡检测可信度与姿态精度。 |
label_smoothing | 0.0 | 应用标签平滑,将硬标签软化为目标标签和标签均匀分布的混合标签,可以提高泛化效果。 |
nbs | 64 | 用于损耗正常化的标称批量大小。 |
overlap_mask | True | 决定在训练过程中分割掩码是否应该重叠,适用于实例分割任务。 |
mask_ratio | 4 | 分割掩码的下采样率,影响训练时使用的掩码分辨率。 |
dropout | 0.0 | 分类任务中正则化的丢弃率,通过在训练过程中随机省略单元来防止过拟合。 |
val | True | 可在训练过程中进行验证,以便在单独的数据集上对模型性能进行定期评估。 |
plots | False | 生成并保存训练和验证指标图以及预测示例图,以便直观地了解模型性能和学习进度。 |
常用的几个训练参数是: 数据集配置文件data、训练轮数epochs、训练批次大小batch、训练使用的设备device,模型优化器optimizer、初始学习率lr0。
以上便是关于YOLOv11模型详细说明,看到这里的小伙伴,相信你一定对yolov11模型有了一定的认识啦。
四、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8v10v11改进有效涨点专栏,本专栏后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,本专栏会持续更新500+创新改进点,大家尽早关注有效涨点专栏,带着大家快速高效发论文!如果大家觉得本文能帮助到你了,订阅本专栏,关注后续更多的更新~
YOLOv8v10v11专栏限时199元订阅链接:
限时199元去b站关注:AI缝合怪订阅YOLOv8v10v11 创新改进高效涨点+持续改进500多篇
(订阅的小伙伴,终身免费享有后续YOLOv12或是其他版本的改进专栏)

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









